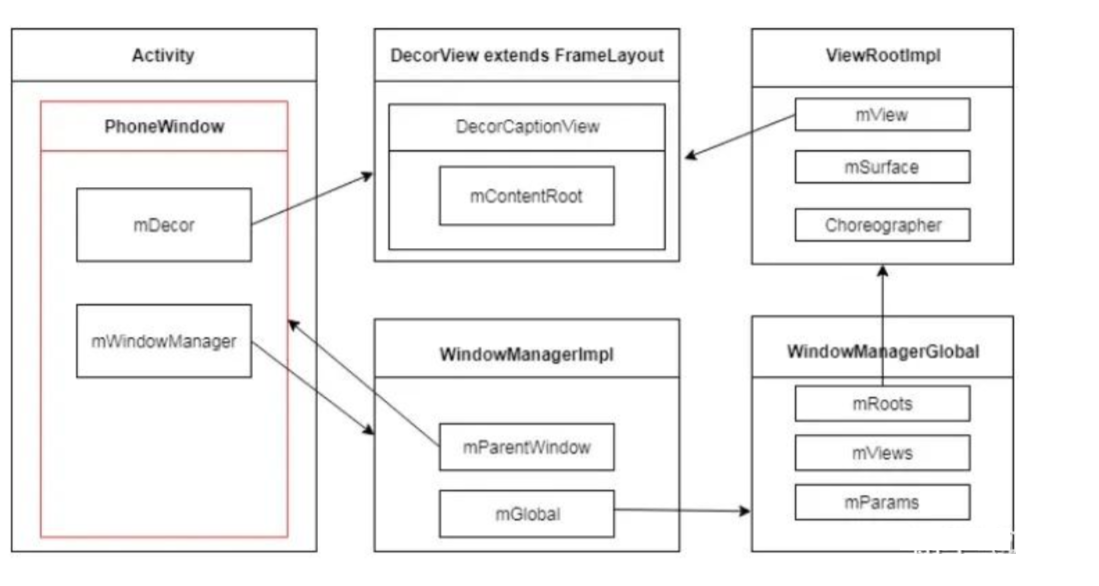
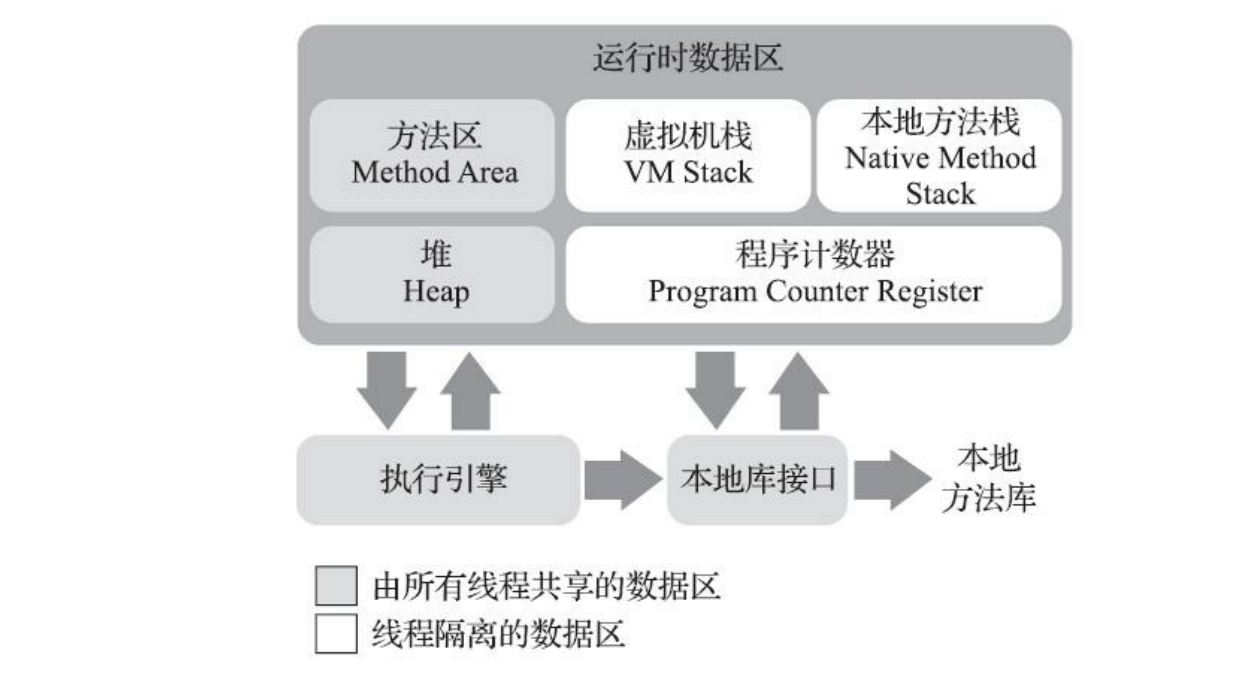
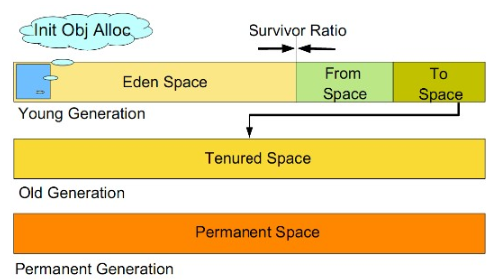
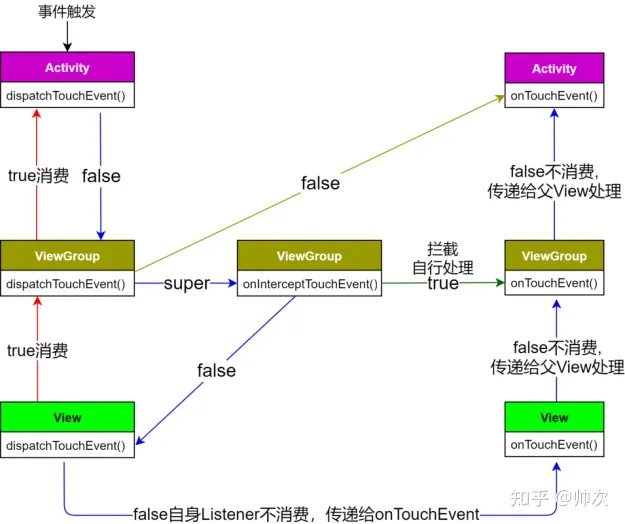
去年学习了整个Android平台的JNI实现流程以及基础类型,引用,多线程,核心指针和JavaVM的相关知识。
Android JNI开发
现在从架构层面,了解一下底层的运行,调用链路。
主要分析目标是 Android 平台。先简单回顾一下 JNI 的开发流程和动态库的生成流程。
首先,理解 JNI (Java Native Interface) 的核心作用至关重要。JNI 并不是一种编程语言,而是一套规范 (Specification) 。它定义了:
JVM (Java Virtual Machine) 如何调用 Native 代码: 包括函数命名约定、参数传递、返回值处理等。Native 代码如何与 JVM 交互: 比如创建 Java 对象、调用 Java 方法、访问 Java 字段、抛出 Java 异常等。数据类型映射: Java 类型(int, String, Object 等)与 C/C++ 类型(jint, jstring, jobject 等)之间的转换规则。这套规范保证了不同 JVM 实现(如 Android 的 ART/Dalvik)和不同操作系统(Linux/Windows/macOS)上的 Java 代码都能以相同的方式与 Native 代码交互。
so 动态库生成 一个典型的 JNI 项目模组结构是下面这样的:
现在很多原生C++项目都采用CMake工具来构建编译系统,android平台开发 JNI 也是。CMake 本身并不是一个编译工具,而是一个跨平台的、开源的自动化构建系统。它不直接编译你的代码,而是根据你的 CMakeLists.txt 文件来生成特定平台和编译工具(如 Makefiles、Ninja 或 Visual Studio 项目文件)的构建脚本。
想象一下,如果你的项目需要在 Windows、Linux、macOS 甚至 Android 上编译,每种平台可能有不同的编译器和构建工具。手动为每种环境编写构建脚本会非常复杂且容易出错。CMake 就是为了解决这个问题而生,它提供了一套统一的语法来描述你的项目。
CMakeLists.txt CMakeLists.txt 文件是什么呢?它是一个构建系统的配置文件。 形象地来概括,CMakeLists.txt 就是你告诉 CMake “我的项目长这样,你需要用这些源文件,链接这些库,编译成这种类型(可执行文件或库),并且用这些特殊的编译选项” 的说明书。它极大地简化了跨平台项目的构建管理。
它的主要作用包括 定义项目结构和属性 , 管理依赖和库 , 设置编译选项和宏 , 查找外部包和组件 , 配置和生成构建文件 , 定义安装规则 。
例如:
# CMake 最低版本要求
cmake_minimum_required ( VERSION 3.10.2)
# 定义项目名称
project ( "my_native_lib" )
# 查找 Android Log 库
find_library ( log-lib log)
# 添加一个共享库目标,命名为 "my_native_lib"
# 并指定它的源文件
add_library ( # 添加一个库
my_native_lib # 库的名称
SHARED # 共享库
src/main/cpp/native-lib.cpp ) # 源文件路径
# 链接日志库到你的目标库中
target_link_libraries ( # 指定需要链接的库
my_native_lib # 你的目标库
${ log-lib } ) # Android Log 库
# 可选:设置 C++ 标准
set ( CMAKE_CXX_STANDARD 17)
set ( CMAKE_CXX_STANDARD_REQUIRED TRUE)
# 可选:添加包含目录
target_include_directories ( my_native_lib PUBLIC
src/main/cpp/include)
在这个例子中:
project() 定义了项目的名称。find_library() 查找了 Android NDK 提供的 log 库。add_library() 定义了一个名为 my_native_lib 的共享库 ,并指定了它的源文件 native-lib.cpp。这是在 Android 上生成 .so 文件的关键。target_link_libraries() 将 log-lib 链接到 my_native_lib 中,这样你的 C++ 代码就可以使用 __android_log_print 等函数了。set(CMAKE_CXX_STANDARD 17) 设置了 C++ 编译标准为 C++17。构建流程 动态库的构建流程本质上是 C++ 代码编译和链接的特定于 Android 平台的实现,主要依赖于 Android NDK (Native Development Kit) 。NDK 是一套工具集,让你能够在 Android 平台上使用 C/C++ 等原生语言开发应用。它包含了下面这些组件:
Clang (LLVM): 用于编译 C/C++ 代码的编译器。Linker (ld): 链接器,用于生成 .so 文件。GCC (已逐渐被 Clang 替代): 另一种编译器。Standard C/C++ Libraries: 如 libc++ 或 gnustl (旧版本)。Android Specific APIs: 比如 android/log.h(用于日志输出)和 jni.h(用于 JNI 接口)。构建系统: 目前主流都是使用 CMake 。我们使用NDK来构建C++代码的目标是生成一个.so文件,这个文件可以在Android平台上被加载和调用。这个过程又分为哪些阶段?
C++ 代码编译 C++ 是一种编译型语言 ,这意味着你的源代码在执行之前必须经过一个或多个阶段的转换。这个过程通常包括以下几个主要步骤。
1. 预处理 (Preprocessing) 预处理器 (preprocessor) 会处理源代码中以 # 开头的指令,这些指令被称为预处理指令 。常见的预处理操作包括:
头文件包含 (#include <file> 或 #include "file"): 将指定文件的内容插入到当前文件中。这就像把多个代码片段拼接起来。宏替换 (#define): 将宏定义替换为对应的文本。例如,#define PI 3.14159 会将代码中所有的 PI 替换为 3.14159。条件编译 (#ifdef, #ifndef, #if, #else, #endif): 根据判断条件,选择性地编译或忽略代码块。这在针对不同平台或配置编译代码时非常有用。预处理阶段的输出是一个纯 C++ 源文件 ,其中所有的预处理指令都已经被处理完毕,宏也已经展开,并且包含了所有引用的头文件内容。
2. 编译 (Compilation) 预处理后的源文件(通常以 .i 或 .ii 结尾,但在实际开发中你可能很少直接看到)会被编译器 (compiler) 处理。编译器的主要任务是将 C++ 源代码翻译成汇编代码 (assembly code) 。
在这个阶段,编译器会执行以下工作:
词法分析 (Lexical Analysis): 将源代码分解成一系列的词法单元 (tokens) ,如关键字、标识符、运算符、常量等。语法分析 (Syntax Analysis): 根据 C++ 语法规则,将词法单元组织成一个抽象语法树 (Abstract Syntax Tree - AST) 。如果代码存在语法错误,编译器会在这里报错。语义分析 (Semantic Analysis): 检查代码的语义正确性,例如类型匹配、变量声明和初始化、函数调用是否正确等。中间代码生成 (Intermediate Code Generation): 将 AST 转换为一种更接近机器语言但仍然独立于具体机器的中间表示 (Intermediate Representation - IR) ,这有助于后续的优化。代码优化 (Code Optimization): 对中间代码进行各种优化,以提高程序的执行效率、减少代码大小。这可能包括死代码消除、常量折叠、循环优化等。目标代码生成 (Target Code Generation): 将优化后的中间代码转换成特定处理器架构的汇编代码 。编译阶段的输出是一个或多个汇编文件 (通常以 .s 结尾)。
3. 汇编 (Assembly) 汇编器 (assembler) 的作用是将汇编代码翻译成机器代码 (machine code) ,也就是由二进制指令组成的目标文件 (object file) 。目标文件通常以 .o (Linux/macOS) 或 .obj (Windows) 结尾。
目标文件包含:
编译后的机器指令。 数据(全局变量、静态变量)。 符号表:记录了程序中定义和引用的函数、变量等符号的信息。 调试信息(如果开启了调试选项)。 此时的目标文件是独立的编译单元,它可能包含对其他文件或库中定义的函数和变量的引用(这些引用被称为未解析的符号 )。
4. 链接 (Linking) 链接是整个编译过程的最后一个阶段,由链接器 (linker) 完成。链接器的主要任务是将一个或多个目标文件以及程序所需要的库文件组合在一起 ,生成一个可执行文件或一个共享库(如 .so 文件在 Android 上)。
链接器会完成以下工作:
符号解析 (Symbol Resolution): 解决目标文件中所有未解析的符号引用。例如,如果你的代码调用了 printf 函数,链接器会在标准库中找到 printf 的实现,并将这个引用解析到实际的函数地址。重定位 (Relocation): 调整代码和数据段的地址。因为每个目标文件都是独立编译的,它们内部的地址都是相对地址。链接器会将它们合并到一个统一的地址空间中,并修正所有需要调整的地址。库链接 (Library Linking): 静态链接 (Static Linking): 将所有需要的库代码直接复制到可执行文件中。优点是可执行文件独立,不依赖外部库;缺点是文件较大,且库更新时需要重新编译链接。动态链接 (Dynamic Linking) / 共享链接 (Shared Linking): 可执行文件只包含对共享库(如 .so 文件)的引用,而不是实际的代码。在程序运行时,操作系统的动态链接器/加载器 会加载这些共享库。优点是可执行文件较小,多个程序可以共享同一个库实例,节省内存,且库更新时无需重新编译程序;缺点是依赖外部库,如果库缺失或版本不兼容,程序可能无法运行。Android NDK 开发中通常使用动态链接生成 .so 文件。链接阶段的输出是一个可执行文件 (如 Linux 上的 a.out 或 Windows 上的 .exe 文件)或者一个共享库 (如 Linux/Android 上的 .so 文件,Windows 上的 .dll 文件)。
Gradle 构建过程 在 Android Studio 中,我们通常不需要手动调用 CMake 或 ndk-build。Android Gradle Plugin 会为你自动化这些任务。例如我们配置了:
android {
// ...
defaultConfig {
// ...
externalNativeBuild {
cmake {
// 指向 CMakeLists.txt 的路径
path file ( 'src/main/cpp/CMakeLists.txt' )
}
// 或者 ndkBuild { path file('src/main/cpp/Android.mk') }
}
ndk {
abiFilters 'armeabi-v7a' , 'arm64-v8a' , 'x86' // 指定需要构建的 ABI
}
}
// ...
}
当我们 Sync 项目时,Gradle 会检查 externalNativeBuild 配置。当你点击 “Build” 或 “Run” 时,Gradle 会执行下面这些操作:
根据 build.gradle 中配置的 ABI (abiFilters),为每个目标架构调用相应的 NDK 工具链。 调用 CMake 或 ndk-build: 你的 CMakeLists.txt 或 Android.mk 文件会被解析。编译 (Compilation): NDK 工具链中的 Clang 编译器将你的 C++ 源代码编译成对应架构的汇编代码,然后汇编成目标文件 (.o 文件)。链接 (Linking): NDK 工具链中的链接器将这些目标文件与 NDK 提供的系统库(如 liblog.so)和你的其他依赖库链接起来。最终,它会生成对应每个 ABI 的 .so 动态库文件libnative-lib.so)。打包到 APK: APK 文件本身是一个 ZIP 格式的归档文件。生成的 .so 文件会被 Gradle 打包到 APK 的特定目录下,通常是 lib/<ABI>/,例如 lib/arm64-v8a/libnative-lib.so。Java虚拟机如何运行的C++代码 JVM (或者说Android平台的Dalvik或者Art)本身并不能提供运行环境,直接 运行 C++ 代码。相反,它通过一套协调机制 来将执行权交给操作系统和底层的 CPU,由它们来执行 C++ 代码。这个协调机制其实就是 JNI (Java Native Interface) 。
JNI 的桥梁作用 JVM 并不理解 C++ 代码,它只运行字节码(Java 代码编译后的中间产物)。当你调用了一个 native 方法时,JVM 知道这个方法不是由 Java 实现的,而是由外部的本地代码提供。
JNI 规范了 Java 类型和 C++ 类型之间的映射(例如 int 对应 jint,String 对应 jstring),以及 Java 方法签名如何转换为 C++ 函数名。并且提供了一套 C 函数接口(通过 JNIEnv* 指针),允许 C++ 代码反过来操作 Java 对象、调用 Java 方法、访问 Java 字段等。
当你调用 System.loadLibrary("mylib"); 时,发生的事情远不止简单地把文件读进内存:
操作系统层面的加载 JVM 会请求操作系统(在 Android 上是 Linux 内核)的动态链接器 (Dynamic Linker) 来加载这个 .so 共享库文件。
动态链接器首先会在文件系统中找到 libmylib.so。然后将 .so 文件的内容 内存映射 (Memory Map) 到当前进程的虚拟地址空间。这并不是把整个文件一次性读入 RAM,而是建立一种映射关系,只有当程序真正访问到某个内存页时,才会从磁盘加载对应的页到物理内存。
映射完成后,执行解析符号。这是关键一步。.so 文件内部有一个符号表 (Symbol Table) ,记录了它所包含的函数(如 Java_com_example_MyClass_myNativeMethod)和变量的名称及其在文件内的相对地址。同时,它也记录了自身所依赖的外部函数(如 printf、__android_log_print 等)的名称。动态链接器会查找这些外部依赖,在其他已经加载的系统库(如 libc.so、liblog.so)中找到它们的实际内存地址,并更新 .so 库内部的重定位表 (Relocation Table) ,将对外部函数的引用替换为它们的实际地址。
最后,如果你的 .so 库中定义了 JNI_OnLoad 函数,动态链接器在加载并完成基本解析后,会通知 JVM 。JVM 随后会调用这个 JNI_OnLoad 函数。你可以在这里执行动态注册,将 Java 方法直接映射到 C++ 函数的内存地址,或者进行其他初始化工作。
Java 方法与 Native 函数的绑定 在调用 native 方法之前,JVM 需要知道这个方法对应的 C++ 函数的具体入口点(也就是它在内存中的地址)。
静态注册: 如果你没有使用 JNI_OnLoad 进行动态注册,那么当 JVM 第一次遇到一个 native 方法的调用时,它会:根据 JNI 的命名规则(Java_包名_类名_方法名)构造一个字符串。 在已经加载的 .so 库的符号表 中查找这个字符串对应的函数。 一旦找到,JVM 就会将这个 Java 方法与其对应的 C++ 函数的内存地址绑定 (Binding) 起来。这样,后续再次调用这个 Java 方法时,就可以直接跳转到那个 C++ 函数的地址,无需再次查找。 动态注册: 如果你在 JNI_OnLoad 中使用了 RegisterNatives,那么绑定工作在库加载时就已经完成了。JVM 会直接获得 Native 函数的地址,效率更高,且不依赖于严格的命名约定。JNI 调用过程 当 JVM 首次尝试调用一个 native 方法时,它需要知道这个 Java 方法对应的 Native 函数在 .so 库中的具体地址。这种寻址过程就是根据上文提到的符号表 来查找。
静态注册时,JVM 会根据 JNI 的命名约定 来查找 Native 函数。直接在已加载的 .so 库的符号表中查找符合命名规范的函数。这个查找过程在第一次调用该 Native 方法时发生,并将 Java 方法与 Native 函数的地址进行绑定 (Binding) 。后续再次调用时,就可以直接跳转到 Native 函数的地址,提高了效率。如果找不到对应的函数,会抛出 UnsatisfiedLinkError。
动态注册是通过 JNI_OnLoad 函数,具体的是 RegisterNatives JNI 函数手动将 Java 方法和 Native 函数进行关联。这种方式可以不遵循 JNI 的严格命名约定,Native 函数名可以更简洁。可以批量注册多个方法更高效。还有助于防止函数名过长导致某些旧系统(如 Windows)上的问题。
参数传递与栈帧 当 Java 代码调用 Native 方法时:
保存 Java 运行上下文: JVM 第一步会保存当前 Java 方法的执行上下文(如局部变量、操作数栈状态等)。JNIEnv 指针: JVM 会将一个 JNIEnv* 指针作为第一个参数传递给 Native 函数。这个指针提供了访问 JVM 功能的接口。JObject/JClass 参数: 对于非静态 Native 方法,jobject 参数代表调用该方法的 Java 对象的引用。 对于静态 Native 方法,jclass 参数代表调用该方法的 Java 类的引用。 参数转换: Java 基本类型(如 int, boolean)会直接映射到对应的 JNI 类型(jint, jboolean)。对于 Java 对象类型(如 String, Object),JNI 会传递一个 jobject 或其子类型的引用。这些引用是指向 JVM 内部 Java 对象的指针。切换栈帧: JVM 的执行流会从 Java 栈帧切换到 Native 栈帧。CPU 会开始执行 Native .so 文件中的机器码。Native 代码执行和返回 JVM 将执行流程跳转 到 Native C++ 函数在内存中的起始地址。此时,CPU 开始执行 .so 库中的 C++ 机器码。JVM 不再直接“运行”C++ 代码,而是将控制权交给了 CPU,由 CPU 直接执行预编译好的机器指令。
Native C++ 代码在运行时,可以直接使用 JNIEnv 指针来与 JVM 进行交互。例如:
env->NewStringUTF(): 从 C 字符串创建 Java String 对象。env->GetStringUTFChars(): 将 Java String 转换为 C 字符串。env->CallIntMethod(): 调用 Java 对象的某个 int 类型返回值的成员方法。env->ThrowNew(): 在 Java 层抛出异常。当 Native 函数执行完毕并通过 return 语句返回结果时。Native 函数返回的 C/C++ 类型结果会被 JNI 自动转换回对应的 Java 类型 。
然后要恢复 Java 上下文,执行流会从 Native 栈帧切换回 Java 栈帧 。如果 Native 代码中设置了待抛出的 Java 异常,JVM 会在返回后立即抛出该异常。如果无异常,Java 调用方会接收到 Native 方法的返回值,并继续其后续操作。
内存管理与垃圾回收 一个重要的底层细节是内存管理:
Java 堆: Java 对象存储在 Java 堆上,由 JVM 的垃圾回收器管理。Native 堆: C/C++ 代码可以通过 malloc/free 或 new/delete 在 Native 堆上分配内存。这部分内存不受 JVM 垃圾回收器的管理,需要 Native 代码自己负责释放,否则会导致内存泄漏。JNI 引用: 当 Native 代码获取到 Java 对象的引用时(jobject, jstring, jbyteArray 等),这些引用被称为 局部引用 (Local Reference) 。它们在 Native 方法返回后会自动被 JVM 释放。如果你需要在 Native 方法返回后继续持有这些引用,你需要将它们提升为 全局引用 (Global Reference) ,并手动管理其生命周期。背景 最近在做AI大模型对接的一些功能,调用完chat接口返回结果之后,发现豆包和Kimi等客户端都有语音播报功能,并且这些大厂经过一系列调优,可以实现很好听的音色和节奏停顿的效果。
那个人开发者可不可以在系统自带的免费语音助手的基础上做一个tts(Text To Speech)的播报呢?
调查发现Google已经有相关的接口了,并且尝试使用魅族20Pro手机成功实现了语音播报效果,记录一下使用过程。
TextSpeech TextSpeech 是Android平台的文字转语音的接口,可以将文本合成为语音,可以支持立即播放,或者存储为音频文件。
初始化实例 创建实例需要传入两个参数,一个Context,一个连接的监听器,监听器会在初始化完成后回调。
/**
* The constructor for the TextToSpeech class, using the default TTS engine.
* This will also initialize the associated TextToSpeech engine if it isn't already running.
*
* @param context
* The context this instance is running in.
* @param listener
* The {@link TextToSpeech.OnInitListener} that will be called when the
* TextToSpeech engine has initialized. In a case of a failure the listener
* may be called immediately, before TextToSpeech instance is fully constructed.
*/
public TextToSpeech ( Context context , OnInitListener listener ) {
this ( context , listener , null );
}
播放停止与释放 就播放功能来说,使用起来非常简单,只需要创建一个TextSpeech对象,然后调用speak方法即可。
方法签名:
public int speak ( final CharSequence text ,
final int queueMode ,
final Bundle params ,
final String utteranceId ) {
return runAction (( ITextToSpeechService service ) -> {
Uri utteranceUri = mUtterances . get ( text );
if ( utteranceUri != null ) {
return service . playAudio ( getCallerIdentity (), utteranceUri , queueMode ,
getParams ( params ), utteranceId );
} else {
return service . speak ( getCallerIdentity (), text , queueMode , getParams ( params ),
utteranceId );
}
}, ERROR , "speak" );
}
参数说明: text:要转换的文本 queueMode:播放模式,有三种:QUEUE_ADD、QUEUE_FLUSH、QUEUE_MODE_DEFAULT params:参数,包括语音的语言、音调、语速等 utteranceId:唯一标识,用于区分不同的语音
停止时调用该对象的 stop() 方法,使用完毕退出时,需要调用 shutdown() 方法来释放引擎所使用的原生资源。我猜会这里会占用系统的多媒体编解码器连接,使用完需要及时释放防止其他app播放多媒体资源出错。
工具类完整代码 使用object实现单例,全局共享,在viewmodel里初始化,给界面提供接口。
object SpeechUtils {
private lateinit var textToSpeech : TextToSpeech
private const val TAG = "SpeechUtils"
private const val TEST_IDENTIFIER = "test"
private const val TEST_HELLO = "Hi, How are you? I'm fine. Thank you. And you?"
private var isConnected = false
val ttsConnectedListener = TextToSpeech . OnInitListener { status ->
Log . d ( TAG , "OnInitListener status: $status" )
isConnected = status == TextToSpeech . SUCCESS
}
fun init () {
textToSpeech = TextToSpeech ( appContext , ttsConnectedListener )
}
fun speak ( text : String = TEST_HELLO , locale : Locale = Locale . US ) {
Log . d ( TAG , "==========>speak<=========" )
if ( isConnected ) {
textToSpeech . language = locale
textToSpeech . speak (
text ,
TextToSpeech . QUEUE_ADD ,
null ,
TEST_IDENTIFIER
)
} else {
Log . d ( TAG , "==========>TTS is not connected!<=========" )
}
}
fun stop () {
textToSpeech . stop ()
}
fun shutdown () {
textToSpeech . shutdown ()
}
}
Viewmodel代码:
class MainStateHolder (
private val retroService : RetroService ,
private val ktorClient : KtorClient ,
) : ViewModel () {
companion object {
const val TAG = "MainStateHolder"
const val TOKEN_KEY = "token"
const val USER_NAME_KEY = "user_name"
}
init {
SpeechUtils . init ()
}
// ...
fun speak ( text : String , locale : Locale ) {
SpeechUtils . speak ( text , locale )
}
fun stopSpeech (){
SpeechUtils . stop ()
}
override fun onCleared () {
super . onCleared ()
ktorClient . release ()
SpeechUtils . shutdown ()
}
}
界面使用时,服务器返回值时调用播放,页面取消组合时,调用stop停止。同时,加入LifeCycle感知,在Activity退到后台,也调用停止接口:
@Composable
fun MyServerPage (
mainStateHolder : MainStateHolder ,
lifecycleOwner : LifecycleOwner = LocalLifecycleOwner . current ,
onBackStack : () -> Unit ,
) {
BasePage ( "个人服务器测试" , onCickBack = onBackStack ) {
LaunchedEffect ( Unit ) {
mainStateHolder . getMyServerResponse ()
}
val myResponse = mainStateHolder . myServerResponseStateFlow . collectAsState (). value
LaunchedEffect ( myResponse ) {
if ( myResponse . isNotEmpty ()) {
mainStateHolder . speak ( myResponse , Locale . US )
}
}
Box (
modifier = Modifier . fillMaxSize (),
contentAlignment = androidx . compose . ui . Alignment . Center
) {
Text ( text = myResponse )
}
DisposableEffect ( lifecycleOwner ) {
Log . i ( "MyServerPage" , "MyServerPage ${lifecycleOwner.lifecycle.currentState}" )
val observer = LifecycleEventObserver { _ , event ->
if ( event == Lifecycle . Event . ON_STOP ) {
// 当 Activity 退到后台时,Lifecycle 会触发 ON_STOP 事件
mainStateHolder . stopSpeech ()
}
}
lifecycleOwner . lifecycle . addObserver ( observer )
onDispose {
mainStateHolder . stopSpeech ()
lifecycleOwner . lifecycle . removeObserver ( observer )
}
}
}
}
后续尝试使用付费版本的本地引擎,集成aar到本地进行调用,达到更好的播放效果。使用方式应该都是按照原生的接口设计。
官方文档 [Google官方JNI文档]
项目例程 [stepheneasyshot/JniDemo]
基本开发流程 Android Studio 编译原生库的默认构建工具是 CMake。由于很多现有项目都使用 ndk-build 构建工具包,因此 Android Studio 也支持 ndk-build。不过,如果您要创建新的原生库,则应使用 CMake。新的接口开发全部使用cmake来构建,相比之前的ndk-build的配置方式,使用cmake可以省略掉.h文件声明和android.mk文件来辅助构建,只需要一个CMakeList.txt即可。
开发流程:
Java/Kotlin代码里创建好需要的native方法,注意在Cpp文件中对方法名有明确要求。 package com.stephen.jnitest
object JniUtils {
fun init () {
System . loadLibrary ( "jni-test" )
}
external fun hello (): String
}
创建Native代码文件,即C/C++文件 #include <jni.h>
#include <string>
#include <android/log.h>
#define LOG_TAG "Stephen JNI TEST"
extern "C" JNIEXPORT jstring JNICALL
Java_com_stephen_jnitest_JniUtils_hello (
JNIEnv * env , jobject ) {
const char * hello = "Hello from C++" ;
__android_log_print ( ANDROID_LOG_DEBUG , LOG_TAG ,
"This is my first time using android log in C++" );
__android_log_print ( ANDROID_LOG_DEBUG , LOG_TAG , "Hello String: [%s]" , hello );
return env -> NewStringUTF ( hello );
}
创建CmakeLists.txt脚本文件 cmake_minimum_required(VERSION 3.18.1)
project("jni-test")
add_library(jni-test SHARED
jni-test.cpp)
# Include libraries needed for lib
target_link_libraries(jni-test
android
log)
在gradle里配置构建脚本的路径 android {
externalNativeBuild {
cmake {
path = file ( "src/main/cpp/CMakeLists.txt" )
}
}
}
文件结构如下:
以上是在一个android library里进行的开发,完成后可以打包aar对外提供。
CMakeList写法 Google原生的提示模板:
# Sets the minimum version of CMake required to build your native library.
# This ensures that a certain set of CMake features is available to
# your build.
cmake_minimum_required ( VERSION 3.4.1)
# Specifies a library name, specifies whether the library is STATIC or
# SHARED, and provides relative paths to the source code. You can
# define multiple libraries by adding multiple add_library() commands,
# and CMake builds them for you. When you build your app, Gradle
# automatically packages shared libraries with your APK.
add_library ( # Specifies the name of the library.
native-lib
# Sets the library as a shared library.
SHARED
# Provides a relative path to your source file(s).
src/main/cpp/native-lib.cpp )
第一 addLibrary 需要制定库的名称,第二可以选择配置为静态库还是动态库方式,第三是源文件。
添加原生依赖库 向 CMake 构建脚本添加 find_library() 命令以找到 NDK 库并将其路径存储为一个变量。您可以使用此变量在构建脚本的其他部分引用 NDK 库。 比如引用Android原生的日志库:
find_library ( # Defines the name of the path variable that stores the
# location of the NDK library.
log-lib
# Specifies the name of the NDK library that
# CMake needs to locate.
log )
# Links your native library against one or more other native libraries.
target_link_libraries ( # Specifies the target library.
native-lib
# Links the log library to the target library.
${ log-lib } )
也可以使用 add_library() ,直接添加原生代码当作依赖,以下命令可以指示 CMake 将 android_native_app_glue.c(负责管理 NativeActivity 生命周期事件和触控输入)构建至静态库,并将其与 native-lib 关联:
add_library ( app-glue
STATIC
${ ANDROID_NDK } /sources/android/native_app_glue/android_native_app_glue.c )
# You need to link static libraries against your shared native library.
target_link_libraries ( native-lib app-glue ${ log-lib } )
添加头文件 在Android Studio中使用CMake添加头文件,你需要在 CMakeLists.txt 文件中使用 include_directories() 指令。这个指令告诉 CMake 在编译时需要包含哪些目录来搜索头文件。
例如,如果你有一个头文件目录位于 app/src/main/cpp/include ,你可以在 CMakeLists.txt 中添加如下指令:
include_directories ( include)
这行代码会告诉CMake在编译时需要包含 app/src/main/cpp/include 目录下的所有头文件。
完整的CMakeLists.txt示例如下:
cmake_minimum_required ( VERSION 3.18.1)
project ( "terminal-channel" )
add_library ( terminal-channel SHARED
common.cpp
process.cpp
termExec.cpp)
include_directories ( include)
target_link_libraries ( terminal-channel
android
log)
# 添加预构建库
add_library ( imported-lib
SHARED
IMPORTED )
# 然后,您需要使用 set_target_properties() 命令指定库的路径:
add_library ( ...)
set_target_properties ( # Specifies the target library.
imported-lib
# Specifies the parameter you want to define.
PROPERTIES IMPORTED_LOCATION
# Provides the path to the library you want to import.
imported-lib/src/${ ANDROID_ABI } /libimported-lib.so )
Android ABI 不同的 Android 设备使用不同的 CPU,而不同的 CPU 支持不同的指令集。CPU 与指令集的每种组合都有专属的应用二进制接口 (ABI)。ABI 包含以下信息:
可使用的 CPU 指令集(和扩展指令集)。 运行时内存存储和加载的字节顺序。Android 始终是 little-endian。 在应用和系统之间传递数据的规范(包括对齐限制),以及系统调用函数时如何使用堆栈和寄存器。 可执行二进制文件(例如程序和共享库)的格式,以及它们支持的内容类型。Android 始终使用 ELF。如需了解详情,请参阅 ELF System V 应用二进制接口。 如何重整 C++ 名称。如需了解详情,请参阅 Generic/Itanium C++ ABI。 armeabi-v7a ,此 ABI 适用于 32 位 ARM CPU。它包括 Thumb-2 和 Neon。
arm64-v8a ,此 ABI 适用于 64 位 ARM CPU。
x86 ,此 ABI 适用于支持通常称为“x86”“i386”或“IA-32”的指令集的 CPU。
x86_64 ,此 ABI 适用于支持通常称为“x86-64”的指令集的 CPU。
gradle配置 默认情况下,Gradle(无论是通过 Android Studio 使用,还是从命令行使用)会针对所有非弃用 ABI 进行构建。要限制应用支持的 ABI 集,请使用 abiFilters。例如,要仅针对 64 位 ABI 进行构建,请在 build.gradle 中设置以下配置:
android {
defaultConfig {
ndk {
abiFilters 'arm64-v8a', 'x86_64'
}
}
}
Native方法声明解析 以之前的 ndk-build 的方式声明的头文件为例:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class HelloJNI */
#ifndef _Included_HelloJNI
#define _Included_HelloJNI
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: HelloJNI
* Method: sayHello
* Signature: ()V
*/
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello ( JNIEnv * , jobject );
#ifdef __cplusplus
}
#endif
#endif
extern “C” 是告诉 C++ 编译器以 C 的方式来编译这个函数,以方便其他 C 程序链接和访问该函数。
C 和 C++ 有着不同的命名协议,因为 C++ 支持函数重载,用了不同的命名协议来处理重载的函数。在 C 中函数是通过函数名来识别的,而在 C++ 中,由于存在函数的重载问题,函数的识别方式通过函数名,函数的返回类型,函数参数列表三者组合来完成的。
因此两个相同的函数,经过C,C++编绎后会产生完全不同的名字。
所以,如果把一个用 C 编绎器编绎的目标代码和一个用 C++ 编绎器编绎的目标代码进行链接,就会出现链接失败的错误。
JNIEnv :JNIEnv 内部提供了很多函数,方便我们进行 JNI 编程。jobject :指向 “this” 的 Java 对象jclass :如果 java 中的 native 函数是 static 的,那第二个参数是 jclass ,代表了 java 中的 Class 类。JNIEXPORT 、 JNICALL 两个宏在 linux 平台的定义如下:// 该声明的作用是保证在本动态库中声明的方法 , 能够在其他项目中可以被调用
#define JNIEXPORT __attribute__ ((visibility ("default")))
// 一个空定义
#define JNICALL
JNI_ONLOAD 原生库 您可以使用标准 API 从共享库加载原生代码 System.loadLibrary() 。
事实上,旧版 Android 的 PackageManager 中存在导致安装和使原生库更新不可靠。 ReLinker 项目提供了解决此问题和其他原生库加载问题的解决方法。
从静态类调用 System.loadLibrary(或 ReLinker.loadLibrary) 初始化函数。参数是 “未修饰” 是的库名称 因此,要加载 libfubar.so ,您需要传入 “fubar”。
如果您只有一个类具有原生方法,则调用 System.loadLibrary() 位于该类的静态初始化程序中。否则,您应该从 Application 进行该调用,这样您就知道始终会加载该库,并且始终会提前加载。运行时可以通过两种方式找到您的原生方法。您可以请使用 RegisterNatives 注册它们;也可以让运行时动态查询它们和dlsym。
RegisterNatives 的优势在于,您可以提前还可以检查这些符号是否存在导出除 JNI_OnLoad 之外的任何内容。这样做的好处是让运行时因为它需要编写的代码略少一些。
如需使用 RegisterNatives,请执行以下操作:
提供 JNIEXPORT jint JNI_OnLoad(JavaVM* vm, void* reserved) 函数。 在 JNI_OnLoad 中,使用 RegisterNatives 注册所有原生方法。 使用 -fvisibility=hidden 进行构建,以便仅使用您的 JNI_OnLoad 。这样可以生成更快、更小的代码,并避免 与加载到您的应用中的其他库发生冲突(但创建的堆栈轨迹没有多大用处) (如果您的应用在原生代码中崩溃)。
JNI_OnLoad方法 Java JNI 有两种加载方法,一种是通过 javah ,获取一组带签名函数,然后实现这些函数。这种方法很常用,也是官方推荐的方法。还有一种就是 JNI_OnLoad 方法。
当Android的VM(Virtual Machine)执行到C组件(即*so档)里的 System.loadLibrary() 函数时,首先会去执行C组件里的 JNI_OnLoad() 函数。它的用途有二:
告诉 安卓虚拟机 此 C 组件使用哪一个 JNI 版本。如果你的 *.so 里没有提供 JNI_OnLoad() 函数,VM会默认该 *.so 档是使用最老的 JNI 1.1 版本。由于新版的JNI做了许多扩充,如果需要使用JNI的新版功能,例如 JNI 1.4 的 java.nio.ByteBuffer ,就必须借由 JNI_OnLoad() 函数来告知虚拟机。 由于虚拟机执行到 System.loadLibrary() 函数时,就会立即调用 JNI_OnLoad() ,所以 C 组件的开发者可以通过 JNI_OnLoad() 来进行 C 组件内的初期值之设定。 JNI_OnLoad 方法的内容比较固定:
JNIEXPORT jint JNI_OnLoad ( JavaVM * vm , void * reserved ) {
JNIEnv * env ;
if ( vm -> GetEnv ( reinterpret_cast < void **> ( & env ), JNI_VERSION_1_6 ) != JNI_OK ) {
return JNI_ERR ;
}
// Find your class. JNI_OnLoad is called from the correct class loader context for this to work.
jclass c = env -> FindClass ( "com/example/app/package/MyClass" );
if ( c == nullptr ) return JNI_ERR ;
// Register your class' native methods.
static const JNINativeMethod methods [] = {
{ "nativeFoo" , "()V" , reinterpret_cast < void *> ( nativeFoo )},
{ "nativeBar" , "(Ljava/lang/String;I)Z" , reinterpret_cast < void *> ( nativeBar )},
};
int rc = env -> RegisterNatives ( c , methods , sizeof ( methods ) / sizeof ( JNINativeMethod ));
if ( rc != JNI_OK ) return rc ;
return JNI_VERSION_1_6 ;
}
数据类型 基础数据类型 Java 类型 JNI 类型 C/C++ 类型 boolean jboolean unsigned char byte jbyte signed char char jchar unsigned short short jshort signed short int jint int long jlong long float jfloat float double jdouble double
以上基础类型可以随意互相转换,直接使用。
Kotlin:
external fun add ( a : Int , b : Int ): Int
external fun calChar ( charater : Char ): Char
C++:
extern "C" JNIEXPORT jint JNICALL
Java_com_stephen_jnitest_JniUtils_add ( JNIEnv * env , jobject , jint a , jint b ) {
return a + b ;
}
extern "C" JNIEXPORT jchar JNICALL
Java_com_stephen_jnitest_JniUtils_calChar ( JNIEnv * env , jobject , jchar a ) {
return a + 1 ;
}
引用类型 jni.h 中定义的非基本数据类型称为引用类型。
Java 类型 JNI 引用类型 类型描述 java.lang.Object jobject 表示任何Java的对象 java.lang.String jstring Java的String字符串类型的对象 java.lang.Class jclass Java的Class类型对象 java.lang.Throwable jthrowable Java的Throwable类型 byte[] jbyteArray Java byte型数组 Object[] jobjectArray Java任何对象的数组 boolean[] jbooleanArray Java boolean型数组 char[] jcharArray Java char型数组 short[] jshortArray Java short型数组 int[] jintArray Java int型数组 long[] jlongArray Java long型数组 float[] jfloatArray Java float型数组 double[] jdoubleArray Java double型数组
这些数据类型在使用时需要互相转换。一般的 native 方法中主要做了这么几件事:
接收 JNI 类型的参数 参数类型转换,JNI 类型转换为 Native 类型 执行 Native 代码 创建一个 JNI 类型的返回对象,将结果拷贝到这个对象并返回结果 字符串 为了在 C/C++ 中使用 Java 字符串,需要先将 Java 字符串转换成 C 字符串。用 GetStringChars 函数可以将 Unicode 格式的 Java 字符串转换成 C 字符串,用 GetStringUTFChars 函数可以将 UTF-8 格式的 Java 字符串转换成 C 字符串。这些函数的第三个参数均为 isCopy,它让调用者确定返回的 C 字符串地址指向副本还是指向堆中的固定对象。
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello__Ljava_lang_String_2 ( JNIEnv * env , jobject jobj , jstring str ) {
//jstring -> char*
jboolean isCopy ;
//GetStringChars 用于 unicode 编码
//GetStringUTFChars 用于 utf-8 编码
const char * cStr = env -> GetStringUTFChars ( str , & isCopy );
if ( nullptr == cStr ) {
return nullptr ;
}
if ( JNI_TRUE == isCopy ) {
cout << "C 字符串是 java 字符串的一份拷贝" << endl ;
} else {
cout << "C 字符串指向 java 层的字符串" << endl ;
}
cout << "C/C++ 层接收到的字符串是 " << cStr << endl ;
//通过JNI GetStringChars 函数和 GetStringUTFChars 函数获得的C字符串在原生代码中
//使用完之后需要正确地释放,否则将会引起内存泄露。
env -> ReleaseStringUTFChars ( str , cStr );
string outString = "Hello, JNI" ;
// char* 转换为 jstring
return env -> NewStringUTF ( outString . c_str ());
}
其中,isCopy 是一个指向 jboolean 类型变量的指针。调用该函数时,JNI 实现会把是否复制的信息存储在 isCopy 指向的变量中。
isCopy的比对结果过为:
JNI_TRUE :意味着获取的 C 字符串是 Java 字符串的一份拷贝。这表明 JNI 实现分配了新的内存来存储 Java 字符串的副本,在原生代码中使用完这个 C 字符串后,必须调用 ReleaseStringUTFChars 函数释放内存,不然会造成内存泄漏。JNI_FALSE :表示获取的 C 字符串直接指向 Java 层的字符串,JNI 实现没有创建副本。虽然此时不需要释放额外的内存,但仍要调用 ReleaseStringUTFChars 函数,以此告知 JNI 实现原生代码已经用完该字符串isCopy 变量主要用于调试和性能分析。一般来说,在实际开发中,不管 isCopy 的值是什么,都要调用 ReleaseStringUTFChars 函数来确保资源被正确释放。
字符串的其他常用操作函数 GetStringUTFChars/ReleaseStringUTFChars
Java 默认使用 UTF-16 编码,而 C/C++ 默认使用 UTF-8 编码。
UTF-8:适合网络传输、存储包含大量 ASCII 字符的文本,兼容性好,节省空间。 UTF-16:适合在 Java、Windows 等内部使用 16 位字符表示的系统中处理字符串,处理 BMP 内字符简单高效。 GetStringUTFChars 可以把一个 jstring 指针(指向 JVM 内部的 UTF-16 字符序列)转换成一个 UTF-8 编码的 C 风格字符串。
// 参数说明:
// * this: JNIEnv 指针
// * string: jstring类型(Java 传递给本地代码的字符串指针)
// * isCopy: 它的取值可以是 JNI_TRUE (值为1)或者为 JNI_FALSE (值为0)。如果值为 JNI_TRUE,表示返回 JVM 内部源字符串的一份拷贝,并为新产生的字符串分配内存空间。如果值为 JNI_FALSE,表示返回 JVM 内部源字符串的指针,意味着可以通过指针修改源字符串的内容,不推荐这么做,因为这样做就打破了 Java 字符串不能修改的规定。但我们在开发当中,并不关心这个值是多少,通常情况下这个参数填 NULL 即可。
const char * ( * GetStringUTFChars )( JNIEnv * , jstring , jboolean * ); //C环境中的定义
const char * GetStringUTFChars ( jstring string , jboolean * isCopy ) //C++环境中的定义
{ return functions -> GetStringUTFChars ( this , string , isCopy ); }
调用完 GetStringUTFChars 之后不要忘记安全检查,因为 JVM 可能需要为新诞生的字符串分配内存空间,当内存空间不够分配的时候,会导致调用失败,失败后 GetStringUTFChars 会返回 NULL,并抛出一个 OutOfMemoryError 异常。
JNI的异常和 Java 中的异常处理流程是不一样的,Java 遇到异常如果没有捕获,程序会立即停止运行。而 JNI 遇到未决的异常不会改变程序的运行流程,也就是程序会继续往下走,这样后面针对这个字符串的所有操作都是非常危险的,因此,我们需要用 return 语句跳过后面的代码,并立即结束当前方法。
// 参数说明:
// this: JNIEnv 指针
// string: 指向一个 jstring 变量,即是要释放的本地字符串的来源。在当前环境下指向 Java 中传递过来的 String 字符串对应的 JNI 数据类型 jstring
// utf:将要释放的C/C++本地字符串。即我们调用GetStringUTFChars获取的数据的存储指针。
void ( * ReleaseStringUTFChars )( JNIEnv * , jstring , const char * ); //C中的定义
void ReleaseStringUTFChars ( jstring string , const char * utf ) //C++中的定义
{ functions -> ReleaseStringUTFChars ( this , string , utf ); }
ReleaseStringUTFChars 函数用于通知虚拟机 jstring 在 jvm 中对应的内存已经不使用了,可以清除了。
GetStringChars/ReleaseStringChars
GetStringChars 返回字符串 string 对应的 UTF-16 字符数组的指针。在内存不足时抛出 OutOfMemoryError 异常。 ReleaseStringChars 通知虚拟机平台释放 chars 所引用的相关资源,以免造成内存泄漏。参数 chars 是一个指针,可通过 GetStringChars() 从 string 获得。
const jchar * ( GetStringChars )( JNIEnv env , jstring string , jboolean * isCopy );
void ReleaseStringChars ( JNIEnv * env , jstring string , const jchar * chars );
NewStringUTF
利用C风格字符串创建一个新的 java.lang.String 字符串对象。这个新创建的字符串会自动转换成 Java 支持的 UTF-16 编码。在内存不足时抛出 OutOfMemoryError 异常。
// 参数说明
// this: JNIEnv 指针
// bytes: 指向一个char * 变量,即要返回给 Java 层的 C/C++ 中字符串。
jstring ( * NewStringUTF )( JNIEnv * , const char * ); //C环境中定义
jstring NewStringUTF ( const char * bytes ) //C++环境中的定义
{ return functions -> NewStringUTF ( this , bytes ); }
NewString
利用 UTF-16 字符数组构造新的 java.lang.String 对象。在内存不足时抛出 OutOfMemoryError 异常。
jstring ( NewString )( JNIEnv env , const jchar * unicodeChars , jsize size );
GetStringUTFLength
返回字符串的 UTF-8 编码的长度,即 C 风格字符串的长度。
jsize ( GetStringUTFLength )( JNIEnv env , jstring string );
GetStringLength
返回字符串的 UTF-16 编码的长度,即 Java 字符串长度
const jchar * ( GetStringChars )( JNIEnv env , jstring string , jboolean * isCopy );
GetStringCritical/ReleaseStringCritical
此前提到的 Get/ReleaseStringChars 和 Get/ReleaseStringUTFChars 这对函数返回的源字符串会后分配内存,如果有一个字符串内容相当大,有 1M 左右,而且只需要读取里面的内容打印出来,用这两对函数就有些不太合适了。
此时用 Get/ReleaseStringCritical 可直接返回源字符串的指针应该是一个比较合适的方式。不过这对函数有一个很大的限制,在这两个函数之间的本地代码不能调用任何会让线程阻塞或等待 JVM 中其它线程的本地函数或 JNI 函数。因为通过 GetStringCritical 得到的是一个指向 JVM 内部字符串的直接指针,获取这个直接指针后会导致暂停 GC 线程,当 GC 被暂停后,如果其它线程触发 GC 继续运行的话,都会导致阻塞调用者。所以在Get/ReleaseStringCritical 这对函数中间的任何本地代码都不可以执行导致阻塞的调用或为新对象在 JVM 中分配内存,否则,JVM 有可能死锁。
另外,一定要记住检查是否因为内存溢出而导致它的返回值为 NULL,因为 JVM 在执行 GetStringCritical 这个函数时,仍有发生数据复制的可能性,尤其是当 JVM 内部存储的数组不连续时,为了返回一个指向连续内存空间的指针,JVM 必须复制所有数据。
与 GetStringUTFChars 相同, GetStringCritical 也可能在内存不足时抛出 OutOfMemoryError 异常。
GetStringRegion/GetStringUTFRegion
分别表示获取 UTF-16 和 UTF-8 编码字符串指定范围内的内容。 这对函数会把源字符串复制到一个预先分配的缓冲区内。
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello__Ljava_lang_String_2 ( JNIEnv * env , jobject jobj , jstring str ) {
char buff [ 128 ];
jsize len = env -> GetStringUTFLength ( str ); // 获取 utf-8 字符串的长度
// 将虚拟机平台中的字符串以 utf-8 编码拷入C缓冲区,该函数内部不会分配内存空间
env -> GetStringUTFRegion ( str , 0 , len , buff );
}
小结 对于小字符串来说,GetStringRegion 和 GetStringUTFRegion 这两对函数是最佳选择,因为缓冲区可以被编译器提前分配,而且永远不会产生内存溢出的异常。当你需要处理一个字符串的一部分时,使用这对函数也是不错。因为它们提供了一个开始索引和子字符串的长度值。另外,复制少量字符串的消耗也是非常小的。 使用 GetStringCritical 和 ReleaseStringCritical 这对函数时,必须非常小心。一定要确保在持有一个由 GetStringCritical 获取到的指针时,本地代码不会在 JVM 内部分配新对象,或者做任何其它可能导致系统死锁的阻塞性调用。 获取 Unicode 字符串和长度,使用 GetStringChars 和 GetStringLength 函数。获取 UTF-8 字符串的长度,使用 GetStringUTFLength 函数。 创建 Unicode 字符串,使用NewString,创建UTF-8使用 NewStringUTF 函数。 通过 GetStringUTFChars、GetStringChars、GetStringCritical 获取字符串,这些函数内部会分配内存,必须调用相对应的 ReleaseXXXX 函数释放内存。 数组 JNIEXPORT jdoubleArray JNICALL Java_HelloJNI_sumAndAverage ( JNIEnv * env , jobject obj , jintArray inJNIArray ) {
//类型转换 jintArray -> jint*
jboolean isCopy ;
jint * inArray = env -> GetIntArrayElements ( inJNIArray , & isCopy );
if ( JNI_TRUE == isCopy ) {
cout << "C 层的数组是 java 层数组的一份拷贝" << endl ;
} else {
cout << "C 层的数组指向 java 层的数组" << endl ;
}
if ( nullptr == inArray ) return nullptr ;
//获取到数组长度
jsize length = env -> GetArrayLength ( inJNIArray );
jint sum = 0 ;
for ( int i = 0 ; i < length ; ++ i ) {
sum += inArray [ i ];
}
jdouble average = ( jdouble ) sum / length ;
//释放数组
env -> ReleaseIntArrayElements ( inJNIArray , inArray , 0 ); // release resource
//构造返回数据,outArray 是指针类型,需要 free 或者 delete 吗?要的
jdouble outArray [] = { sum , average };
jdoubleArray outJNIArray = env -> NewDoubleArray ( 2 );
if ( NULL == outJNIArray ) return NULL ;
//向 jdoubleArray 写入数据
env -> SetDoubleArrayRegion ( outJNIArray , 0 , 2 , outArray );
return outJNIArray ;
}
使用时需要特别注意item对象的创建与释放。
JNI 中的数组分为基本类型数组和对象数组,它们的处理方式是不一样的,基本类型数组中的所有元素都是 JNI 的基本数据类型,可以直接访问。而对象数组中的所有元素是一个类的实例或其它数组的引用 ,和字符串操作一样,不能直接访问 Java 传递给 JNI 层的数组,必须选择合适的 JNI 函数来访问和设置 Java 层的数组对象。
引用数组 一维数组
JNIEXPORT jobjectArray JNICALL Java_com_xxx_jni_JNIArrayManager_operateStringArrray
( JNIEnv * env , jobject object , jobjectArray objectArray_in )
{
//获取到长度信息
jsize size = env -> GetArrayLength ( objectArray_in );
/*******获取从JNI传过来的String数组数据**********/
for ( int i = 0 ; i < size ; i ++ )
{
jstring string_in = ( jstring ) env -> GetObjectArrayElement ( objectArray_in , i );
char * char_in = env -> GetStringUTFChars ( str , nullptr );
}
/***********从JNI返回String数组给Java层**************/
jclass clazz = env -> FindClass ( "java/lang/String" );
jobjectArray objectArray_out ;
const int len_out = 5 ;
objectArray_out = env -> NewObjectArray ( len_out , clazz , NULL );
char * char_out [] = { "Hello," , "world!" , "JNI" , "is" , "fun" };
jstring temp_string ;
for ( int i = 0 ; i < len_out ; i ++ )
{
temp_string = env -> NewStringUTF ( char_out [ i ]) ;
env -> SetObjectArrayElement ( objectArray_out , i , temp_string );
}
return objectArray_out ;
}
二维数组
JNIEXPORT jobjectArray JNICALL Java_com_xxx_jni_JNIArrayManager_operateTwoIntDimArray ( JNIEnv * env , jobject object , jobjectArray objectArray_in )
{
/********** 解析从Java得到的int型二维数组 **********/
int i , j ;
const int row = env -> GetArrayLength ( objectArray_in ); //获取二维数组的行数
jarray array = ( jarray ) env -> GetObjectArrayElement ( objectArray_in , 0 );
const int col = env -> GetArrayLength ( array ); //获取二维数组每行的列数
//根据行数和列数创建int型二维数组
jint intDimArrayIn [ row ][ col ];
for ( i = 0 ; i < row ; i ++ )
{
array = ( jintArray ) env -> GetObjectArrayElement ( objectArray_in , i );
//操作方式一,这种方法会申请natvie memory内存
jint * coldata = env -> GetIntArrayElements (( jintArray ) array , NULL );
for ( j = 0 ; j < col ; j ++ ) {
intDimArrayIn [ i ] [ j ] = coldata [ j ]; //取出JAVA类中int二维数组的数据,并赋值给JNI中的数组
}
//操作方式二,赋值,这种方法不会申请内存
// env->GetIntArrayRegion((jintArray)array, 0, col, (jint*)&intDimArrayIn[i]);
env -> ReleaseIntArrayElements (( jintArray ) array , coldata , 0 );
}
/**************创建一个int型二维数组返回给Java**************/
const int row_out = 2 ; //行数
const int col_out = 2 ; //列数
//获取数组的class
jclass clazz = env -> FindClass ( "[I" ); //一维数组的类
//新建object数组,里面是int[]
jobjectArray intDimArrayOut = env -> NewObjectArray ( row_out , clazz , NULL );
int tmp_array [ row_out ][ col_out ] = { { 0 , 1 }, { 2 , 3 } };
for ( i = 0 ; i < row_out ; i ++ )
{
jintArray intArray = env -> NewIntArray ( col_out );
env -> SetIntArrayRegion ( intArray , 0 , col_out , ( jint * ) & tmp_array [ i ]);
env -> SetObjectArrayElement ( intDimArrayOut , i , intArray );
}
return intDimArrayOut ;
}
GetArrayLength
jsize ( GetArrayLength )( JNIEnv env , jarray array );
返回数组中的元素个数
NewObjectArray
jobjectArray NewObjectArray ( JNIEnv * env , jsize length , jclass elementClass , jobject initialElement );
构建 JNI 引用类型的数组,它将保存类 elementClass 中的对象。所有元素初始值均设为 initialElement,一般使用 NULL 就好。如果系统内存不足,则抛出 OutOfMemoryError 异常。
GetObjectArrayElement和SetObjectArrayElement
jobject GetObjectArrayElement ( JNIEnv * env , jobjectArray array , jsize index )
返回 jobjectArray 数组的元素,通常是获取 JNI 引用类型数组元素。如果 index 不是数组中的有效下标,则抛出ArrayIndexOutOfBoundsException 异常。
void SetObjectArrayElement ( JNIEnv * env , jobjectArray array , jsize index , jobject value )
设置 jobjectArray 数组中 index 下标对象的值。如果 index 不是数组中的有效下标,则会抛出 ArrayIndexOutOfBoundsException 异常。如果 value 的类不是数组元素类的子类,则抛出 ArrayStoreException 异常。
New<PrimitiveType>Array 函数集
NativeTypeArray New<PrimitiveType>Array (JNIEnv* env, jsize size)
用于构造 JNI 基本类型数组对象。
在实际应用中把 PrimitiveType 替换为某个实际的基本类型数据类型,然后再将 NativeType 替换成对应的 JNI Native Type 即可,具体的:
函数名 返回类型
NewBooleanArray() jbooleanArray
NewByteArray() jbyteArray
NewCharArray() jcharArray
NewShortArray() jshorArray
NewIntArray() jintArray
NewLongArray() jlongArray
NewFloatArray() jfloatArray
NewDoubleArray() jdoubleArray
Get/ReleaseArrayElements函数集
NativeType* Get<PrimitiveType>ArrayElements(JNIEnv *env, NativeTypeArray array, jboolean *isCopy)
该函数用于将 JNI 数组类型转换为 JNI 基本数据类型数组,在实际使用过程中将 PrimitiveType 替换成某个实际的基本类型元素访问函数,然后再将NativeType替换成对应的 JNI Native Type 即可:
函数名 转换前类型 转换后类型
GetBooleanArrayElements() jbooleanArray jboolean*
GetByteArrayElements() jbyteArray jbyte*
GetCharArrayElements() jcharArray jchar*
GetShortArrayElements() jshortArray jshort*
GetIntArrayElements() jintArray jint*
GetLongArrayElements() jlongArray jlong*
GetFloatArrayElements() jfloatArray jfloat*
GetDoubleArrayElements() jdoubleArray jdouble*
void Release < PrimitiveType > ArrayElements ( JNIEnv * env , NativeTypeArray array , NativeType * elems , jint mode );
该函数用于通知 JVM,数组不再使用,可以清理先关内存了。在实际使用过程中将 PrimitiveType 替换成某个实际的基本类型元素访问函数,然后再将 NativeType 替换成对应的 JNI Native Type 即可:
函数名 NativeTypeArray NativeType
ReleaseBooleanArrayElements() jbooleanArray jboolean
ReleaseByteArrayElements() jbyteArray jbyte
ReleaseCharArrayElements() jcharArray jchar
ReleaseShortArrayElements() jshortArray jshort
ReleaseIntArrayElements() jintArray jint
ReleaseLongArrayElements() jlongArray jlong
ReleaseFloatArrayElements() jfloatArray jfloat
ReleaseDoubleArrayElements() jdoubleArray
jdoubleGet/Set<PrimitiveType>ArrayRegion
void Set < PrimitiveType > ArrayRegion ( JNIEnv * env , NativeTypeArray array , jsize start , jsize len , NativeType * buf );
该函数用于将基本类型数组某一区域复制到 JNI 数组类型中。在实际使用过程中将 PrimitiveType 替换成某个实际的基本类型元素访问函数,然后再将 NativeType 替换成对应的 JNI Native Type 即可:
函数名 NativeTypeArray NativeType
SetBooleanArrayRegion() jbooleanArray jboolean
SetByteArrayRegion() jbyteArray jbyte
SetCharArrayRegion() jcharArray jchar
SetShortArrayRegion() jshortArray jshort
SetIntArrayRegion() jintArray jint
SetLongArrayRegion() jlongArray jlong
SetFloatArrayRegion() jfloatArray jfloat
SetDoubleArrayRegion() jdoubleArray jdouble
防止 Native 内存泄漏 JNI 层作为 Java 层和 Native 层之间相交互的中间层,它兼具 Native 层和 Java 层的某些特性,尤其在对引用对象的创建和回收上。
和 C++ 里的 new 操作符可以创建一个对象类似,JNI 层可以利用 JNI NewObject 等函数创建一个 Java 意义的对象(引用型对象)。这个被 New 出来的对象是局部(Local) 型的引用对象。 JNI 层可通过 DeleteLocalRef 释放 Local 型的引用对象(等同于Java 层中设置持有这个对象的变量的值为 null)。如果不调用 DeleteLocalRef 的话,根据 JNI 规范,Local 型对象在 JNI 函数返回后,也会由虚拟机根据垃圾回收的逻辑进行标记和回收。 除了 Local 型对象外,JNI 层借助JNI Global 相关函数可以将一个 Local 型引用对象转换成一个全局(Global) 型对象。而 Global 型对象的回收只能先由程序显式地调用 Global 相关函数进行删除,然后,虚拟机才能借助垃圾回收机制回收它们。 引用类型针对的是除开基本类型的 JNI 类型,比如 jstring, jclass ,jobject 等。JNI 类型是 java 层与 c 层的中间类型,java 层与 c 层都需要管理他。我们可以将 JNI 引用类型理解为 Java 意义的对象。
JNI 类型根据使用的方式可分为:
局部引用 什么是局部引用? 通过 JNI 接口从 Java 传递下来或者通过 NewLocalRef 和各种 JNI 接口(FindClass、NewObject、GetObjectClass和NewCharArray等)创建的引用称为局部引用。
局部引用的特点? 在函数为执行完毕前,局部引用会阻止 GC 回收所引用的对象 局部引用不能在本地函数中跨函数使用,不能跨线程使用,当然也不能直接缓存起来使用 函数返回后(未返回局部引用的情况下),局部引用所引用的对象会被 JVM 自动释放,也可在函数结束前通过 DeleteLocalRef 函数手动释放 如果 c 函数返回了一个局部引用数据,在 java 层,该类型会转换为对应的 java 类型。当 java 层不存在该对象的引用时,gc 就会回收该对象 释放局部引用 局部引用在本地方法执行完会被自动回收,但是有些场景最好是我们手动回收一次。
JNI 会将创建的局部引用都存储在一个局部引用表中,如果这个表超过了最大容量限制,就会造成局部引用表溢出,使程序崩溃。经测试,Android上的 JNI 局部引用表最大数量是 512 个。当我们在实现一个本地方法时,可能需要创建大量的局部引用,如果没有及时释放,就有可能导致 JNI 局部引用表的溢出,所以,在不需要局部引用时就立即调用 DeleteLocalRef 手动删除。 在编写 JNI 工具函数时,工具函数在程序当中是公用的,被谁调用你是不知道的。其内部的局部引用在使用完成后应该立即释放,避免过多的内存占用。 如果你的本地函数不会返回。比如一个接收消息的函数,里面有一个死循环,用于等待别人发送消息过来 while(true) { if (有新的消息) { 处理之。。。。} else { 等待新的消息。。。}} 。如果在消息循环当中创建的引用你不显示删除,很快将会造成JVM局部引用表溢出。 局部引用使用完了就删除,而不是要等到函数结尾才释放,局部引用会阻止所引用的对象被 GC 回收。比如你写的一个本地函数中刚开始需要访问一个大对象,因此一开始就创建了一个对这个对象的引用,但在函数返回前会有一个大量的非常复杂的计算过程,而在这个计算过程当中是不需要前面创建的那个大对象的引用的。但是,在计算的过程当中,如果这个大对象的引用还没有被释放的话,会阻止 GC 回收这个对象,内存一直占用者,造成资源的浪费。所以这种情况下,在进行复杂计算之前就应该把引用给释放了,以免不必要的资源浪费。 言而总之,当一个局部引用不在使用后,立即将其释放,以避免不必要的内存浪费。 本地方法中局部引用的数量 JNI 的规范指出,JVM 要确保每个 Native 方法至少可以创建 16 个局部引用,经验表明,16 个局部引用已经足够平常的使用了。 但是,如果要与 JVM 中的对象进行复杂的交互计算,就需要创建更多的局部引用了,这时就需要使用 EnsureLocalCapacity 来确保可以创建指定数量的局部引用,如果创建成功返回 0 ,返回返回小于 0 ,如下代码示例:
// Use EnsureLocalCapacity
int len = 20 ;
if ( env -> EnsureLocalCapacity ( len ) < 0 ) {
// 创建失败,out of memory
}
for ( int i = 0 ; i < len ; ++ i ) {
jstring jstr = env -> GetObjectArrayElement ( arr , i );
// 处理 字符串
// 创建了足够多的局部引用,这里就不用删除了,显然占用更多的内存
}
确保可以创建了足够的局部引用数量,所以在循环处理局部引用时可以不进行删除了,但是显然会消耗更多的内存空间了。
循环中的局部引用,有更好的做法:
PushLocalFrame 与 PopLocalFrame 是两个配套使用的函数对。它们可以为局部引用创建一个指定数量内嵌的空间,在这个函数对之间的局部引用都会在这个空间内,直到释放后,所有的局部引用都会被释放掉,不用再担心每一个局部引用的释放问题了。
// Use PushLocalFrame & PopLocalFrame
for ( int i = 0 ; i < len ; ++ i ) {
if ( env -> PushLocalFrame ( len )) { // 创建指定数据的局部引用空间
//out ot memory
}
jstring jstr = env -> GetObjectArrayElement ( arr , i );
// 处理字符串
// 期间创建的局部引用,都会在 PushLocalFrame 创建的局部引用空间中
// 调用 PopLocalFrame 直接释放这个空间内的所有局部引用
env -> PopLocalFrame ( NULL );
}
使用 PushLocalFrame & PopLocalFrame 函数对,就可以在期间放心地处理局部引用,最后统一释放掉。
全局引用 全局引用可以跨方法、跨线程使用,直到它被手动释放才会失效。同局部引用一样,也会阻止它所引用的对象被 GC 回收。与局部引用不一样的是,函数执行完后,GC 也不会回收全局引用指向的对象。与局部引用创建方式不同的是,只能通过 NewGlobalRef 函数创建。
static jclass cls_string = NULL ;
if ( cls_string == NULL ) {
jclass local_cls_string = ( * env ) -> FindClass ( env , "java/lang/String" );
if ( cls_string == NULL ) {
return NULL ;
}
// 将java.lang.String类的Class引用缓存到全局引用当中
cls_string = ( * env ) -> NewGlobalRef ( env , local_cls_string );
// 删除局部引用
( * env ) -> DeleteLocalRef ( env , local_cls_string );
// 再次验证全局引用是否创建成功
if ( cls_string == NULL ) {
return NULL ;
}
}
当我们的本地代码不再需要一个全局引用时,应该马上调用 DeleteGlobalRef 来释放它。如果不手动调用这个函数,即使这个对象已经没用了,JVM 也不会回收这个全局引用所指向的对象。
弱全局引用 弱全局引用使用 NewGlobalWeakRef 创建,使用 DeleteGlobalWeakRef 释放。下面简称弱引用。与全局引用类似,弱引用可以跨方法、线程使用。但与全局引用很重要不同的一点是,弱引用不会阻止 GC 回收它引用的对象。
static jclass myCls2 = NULL ;
if ( myCls2 == NULL )
{
jclass myCls2Local = ( * env ) -> FindClass ( env , "mypkg/MyCls2" );
if ( myCls2Local == NULL )
{
return ; /* 没有找到mypkg/MyCls2这个类 */
}
myCls2 = NewWeakGlobalRef ( env , myCls2Local );
if ( myCls2 == NULL )
{
return ; /* 内存溢出 */
}
}
... /* 使用myCls2的引用 */
引用之间的比较 IsSameObject 用来判断两个引用是否指向相同的对象。还可以用 isSameObject 来比较弱全局引用所引用的对象是否被 GC 了,返回 JNI_TRUE 则表示回收了,JNI_FALSE 则表示未被回收。
env -> IsSameObject ( obj1 , obj2 ) // 比较两个引用是否指向相同的对象
env -> IsSameObject ( obj , NULL ) // 比较局部引用或者全局引用是否为 NULL
env -> IsSameObject ( wobj , NULL ) // 比较弱全局引用所引用对象是否被 GC 回收
一些疑问:如果 C 层返回给 java 层一个全局引用,这个全局引用何时可以被 GC 回收? 我认为不会被 GC 回收,造成内存泄漏。 所以 JNI 函数如果要返回一个对象,我们应该使用局部引用作为返回值。
描述符 描述符即 JVM 对类,数据,方法等,在Native层的标记方式。
类描述符 在 JNI 的 Native 方法中,我们要使用 Java 中的对象怎么办?即在 C/C++ 中怎么找到 Java 中的类,这就要使用到 JNI 开发中的类描述符了 JNI 提供的函数中有个 FindClass() 就是用来查找 Java 类的,其参数必须放入一个类描述符字符串,类描述符一般是类的完整名称(包名+类名) 一个 Java 类对应的描述符,就是类的全名,其中符号 . 要换成 / :
// 完整类名: java.lang.String
// 对应类描述符: java/lang/String
jclass intArrCls = env -> FindClass ( “ java / lang / String ” )
jclass clazz = FindClassOrDie ( env , "android/view/Surface" );
域描述符 域描述符是 JNI 中对 Java 数据类型的一种表示方法。在 JVM 虚拟机中,存储数据类型的名称时,是使用指定的描述符来存储,而不是我们习惯的 int,float 等。
虽然有类描述符,但是类描述符里并没有说明基本类型和数组类型如何表示,所以在 JNI 中就引入了域描述符的概念。
接着我们通过一个表格来了解域描述符的定义:
类型标识 Java数据类型 Z boolean B byte C char S short I int J long F float D double L包名/类名; 各种引用类型 V void [ 数组 方法 (参数)返回值
接着我们来看几个例子:
Java类型: java.lang.String
JNI 域描述符:Ljava/lang/String; //注意结尾有分号
Java类型: int[]
JNI域描述符: [I
Java类型: float[]
JNI域描述符: [F
Java类型: String[]
JNI域描述符: [Ljava/lang/String;
Java类型: Object[]
JNI域描述符: [Ljava/lang/Object;
Java类型: int[][]
JNI域描述符: [[I
Java类型: float[][]
JNI域描述符: [[F
方法描述符 方法描述符是 JVM 中对函数(方法)的标记方式,看几个例子就能基本掌握其命名特点了:
Java 方法 方法描述符
String fun() ()Ljava/lang/String;
int fun(int i, Object object) (ILjava/lang/Object;)I
void fun(byte[] bytes) ([B)V
int fun(byte data1, byte data2) (BB)I
void fun() ()V
JavaVM JavaVM(Java Virtual Machine)是 Java 程序的运行环境,负责执行 Java 字节码。
在 JNI 开发中,JavaVM 是一个关键的组件,它提供了许多与 Java 运行环境相关的功能,比如加载类、创建对象等。还有管理Java线程,调用Java方法,访问Java对象等。
JavaVM有以下特点:
JavaVM 是一个结构体,用于描述 Java 虚拟机。 一个 JVM 中只有一个 JavaVM 对象。在 Android 平台上,一个 Java 进程只能有一个 ART 虚拟机,也就是说一个进程只有一个 JavaVM 对象。 JavaVM 可以在进程中的各线程间共享。 JavaVM实例通常是应用启动时自动创建,在 JNI 开发中,通常需要先获取 JavaVM 接口指针。这可以在 JNI_OnLoad 函数中完成。在动态注册的方式中,JNI_OnLoad 是一个由 JNI 库提供的函数,当 Java 虚拟机加载本地库(包含 JNI 代码的库)时会调用这个函数。
#include <jni.h>
JNIEXPORT jint JNICALL JNI_OnLoad ( JavaVM * vm , void * reserved ) {
JNIEnv * env ;
// 验证版本
if ( vm -> GetEnv (( void ** ) & env , JNI_VERSION_1_6 ) != JNI_OK ) {
return - 1 ;
}
// 保存JavaVM指针,方便后续使用
static JavaVM * savedVm = vm ;
return JNI_VERSION_1_6 ;
}
也可以通过 JNIEnv 的函数获取到 JavaVM:
JavaVM * gJavaVM ;
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello ( JNIEnv * env , jobject obj )
{
env -> GetJavaVM ( & gJavaVM );
return ( * env ) -> NewStringUTF ( env , "Hello from JNI !" );
}
JNIEnv JNIEnv 即 Java Native Interface Environment,Java 本地编程接口环境。 JNIEnv 内部定义了很多函数用于简化我们的 JNI 编程。
JNI 把 Java 中的所有对象或者对象数组当作一个 C 指针传递到本地方法中,这个指针指向 JVM 中的内部数据结构(对象用jobject来表示,而对象数组用jobjectArray或者具体是基本类型数组),而内部的数据结构在内存中的存储方式是不可见的,我们只能从 JNIEnv 指针指向的函数表中选择合适的 JNI 函数来操作JVM 中的数据结构。
C 在 C 语言中, JNIEnv 是一个指向 JNINativeInterface_ 结构体的指针。 JNINativeInterface_ 结构体中定义了非常多的函数指针,这些函数用于简化我们的 JNI 编程。C 语言中,JNIEnv 中函数的使用方式如下:
//JNIEnv * env
// env 的实际类型是 JNINativeInterface_**
( * env ) -> NewStringUTF ( env , "Hello from JNI !" );
C++ 在 C++ 代码中,JNIEnv 是一个 JNIEnv_ 结构体。JNIEnv_ 结构体中同样定义了非常多的成员函数,这些函数用于简化我们的 JNI 编程。C++ 语言中,JNIEnv 中函数的使用方式如下:
//JNIEnv * env
// env 的实际类型是 JNIEnv_*
env -> NewstringUTF ( "Hello from JNI ! " );
可以将其看成每个线程的独立的工具类,方便进行一系列的操作,简化JNI编程。 使用时要区分单线程和多线程的场景。
单线程 可以直接通过JNI方法传入的参数拿到指针对象来使用:
// 第一个参数就是 JNIEnv
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello ( JNIEnv * env , jobject obj )
{
return ( * env ) -> NewStringUTF ( env , "Hello from JNI !" );
}
多线程 JNIEnv 是一个线程作用域的变量,不能跨线程传递,不同线程的 JNIEnv 彼此独立。多线程使用之前需要先声明一个指针,再将其和线程绑定,指向这个线程自己的JniEnv实例所在的位置。使用完毕之后再解绑定。
//定义全局变量
//JavaVM 是一个结构体,用于描述 Java 虚拟机,后面会讲
JavaVM * gJavaVM ;
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello ( JNIEnv * env , jobject obj )
{
//线程不允许共用env环境变量,但是JavaVM指针是整个jvm共用的,所以可以通过下面的方法保存JavaVM指针,在线程中使用
env -> GetJavaVM ( & gJavaVM );
return ( * env ) -> NewStringUTF ( env , "Hello from JNI !" );
}
//假设这是一个工具函数,可能被多个线程调用
void util_xxx ()
{
JNIEnv * env ;
//从全局的JavaVM中获取到环境变量
gJavaVM -> AttachCurrentThread ( & env , NULL );
//就可以使用 JNIEnv 了
//最后需要做清理操作
gJavaVM -> DetachCurrentThread ();
}
一些函数:
函数名 功能 FindClass 用于获取类 GetObjectClass 通过对象获取这个类 NewGlobalRef 创建 obj 参数所引用对象的新全局引用 NewObject 构造新 Java 对象 NewString 利用 Unicode 字符数组构造新的 java.lang.String 对象 NewStringUTF 利用 UTF-8 字符数组构造新的 java.lang.String 对象 New<Type>Array 创建类型为Type的数组对象 Get<Type>Field 获取类型为Type的字段 Set<Type>Field 设置类型为Type的字段的值 GetStatic<Type>Field 获取类型为Type的static的字段 SetStatic<Type>Field 设置类型为Type的static的字段的值 Call<Type>Method 调用返回类型为Type的方法 CallStatic<Type>Method 调用返回值类型为Type的static方法
相关的函数不止上面的这些,这些函数的介绍和使用方法。我们可以在开发过程中参考官方文档: Oracle官方JNI文档
Native 访问 Java 层 访问成员变量 访问一个类成员基本分为三步:
获取到类对应的 jclass 对象(对应于 Java 层的 Class 对象),jclss 是一个局部引用,使用完后记得使用 DeleteLocalRef 以避免局部引用表溢出。 获取到需要访问的类成员的 jfieldID,jfieldID 不是一个 JNI 引用类型,是一个普通指针,指针指向的内存又 JVM 管理,我们无需在使用完后执行 free 清理操作 根据被访问对象的类型,使用 GetxxxField 和 SetxxxField 来获得/设置成员变量的值 Java:
//定义一个被访问的类
public class TestJavaClass {
private String mString = "Hello JNI, this is normal string !" ;
private static int mStaticInt = 0 ;
}
//定义两个 native 方法
public native void accessJavaFiled ( TestJavaClass testJavaClass );
public native void accessStaticField ( TestJavaClass testJavaClass );
C++:
//访问成员变量
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_accessJavaFiled ( JNIEnv * env , jobject thiz , jobject test_java_class ) {
jclass clazz ;
jfieldID mString_fieldID ;
//获得 TestJavaClass 的 jclass 对象
// jclass 类型是一个局部引用
clazz = env -> GetObjectClass ( test_java_class );
if ( clazz == NULL ) {
return ;
}
//获得 mString 的 fieldID
mString_fieldID = env -> GetFieldID ( clazz , "mString" , "Ljava/lang/String;" );
if ( mString_fieldID == NULL ) {
return ;
}
//获得 mString 的值
jstring j_string = ( jstring ) env -> GetObjectField ( test_java_class , mString_fieldID );
//GetStringUTFChars 分配了内存,需要使用 ReleaseStringUTFChars 释放
const char * buf = env -> GetStringUTFChars ( j_string , NULL );
//修改 mString 的值
char * buf_out = "Hello Java, I am JNI!" ;
jstring temp = env -> NewStringUTF ( buf_out );
env -> SetObjectField ( test_java_class , mString_fieldID , temp );
//jfieldID 不是 JNI 引用类型,不用 DeleteLocalRef
// jfieldID 是一个指针类型,其内存的分配与回收由 JVM 负责,不需要我们去 free
//free(mString_fieldID);
//释放内存
env -> ReleaseStringUTFChars ( j_string , buf );
//释放局部引用表
env -> DeleteLocalRef ( j_string );
env -> DeleteLocalRef ( clazz );
}
//访问静态成员变量
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_accessStaticField ( JNIEnv * env , jobject thiz ,
jobject test_java_class ) {
jclass clazz ;
jfieldID mStaticIntFiledID ;
clazz = env -> GetObjectClass ( test_java_class );
if ( clazz == NULL ) {
return ;
}
mStaticIntFiledID = env -> GetStaticFieldID ( clazz , "mStaticInt" , "I" );
//获取静态成员
jint mInt = env -> GetStaticIntField ( clazz , mStaticIntFiledID );
//修改静态成员
env -> SetStaticIntField ( clazz , mStaticIntFiledID , 10086 );
env -> DeleteLocalRef ( clazz );
}
调用Java方法 Native 访问一个 Java 方法基本分为三步:
获取到类对应的 jclass 对象(对应于 Java 层的 Class 对象),jclss 是一个局部引用,使用完后记得使用 DeleteLocalRef 以避免局部引用表溢出。 获取到需要访问的方法的 jmethodID,jmethodID 不是一个 JNI 引用类型,是一个普通指针,指针指向的内存由 JVM 管理,我们无需在使用完后执行 free 清理操作 接着就可以调用 CallxxxMethod/CallStaticxxxMethod 来调用对于的方法,xxx 是方法的返回类型。 Java:
//等待被 native 层访问的 java 类
public class TestJavaClass {
//......
private void myMethod () {
Log . i ( "JNI" , "this is java myMethod" );
}
private static void myStaticMethod () {
Log . d ( "JNI" , "this is Java myStaticMethod" );
}
}
//本地方法
public native void accessJavaMethod ();
public native void accessStaticMethod ();
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_accessJavaMethod ( JNIEnv * env , jobject thiz ) {
//获取 TestJavaClass 对应的 jclass
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
//构造函数 id
jmethodID java_construct_method_id = env -> GetMethodID ( clazz , "<init>" , "()V" );
if ( java_construct_method_id == NULL ) {
return ;
}
//创建一个对象
jobject object_test = env -> NewObject ( clazz , java_construct_method_id );
if ( object_test == NULL ) {
return ;
}
//获得 methodid
jmethodID java_method_id = env -> GetMethodID ( clazz , "myMethod" , "()V" );
if ( java_method_id == NULL ) {
return ;
}
//调用 myMethod 方法
env -> CallVoidMethod ( object_test , java_method_id );
//清理临时引用吧
env -> DeleteLocalRef ( clazz );
env -> DeleteLocalRef ( object_test );
}
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_accessStaticMethod ( JNIEnv * env , jobject thiz ) {
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
jmethodID static_method_id = env -> GetStaticMethodID ( clazz , "myStaticMethod" , "()V" );
if ( NULL == static_method_id )
{
return ;
}
env -> CallStaticVoidMethod ( clazz , static_method_id );
env -> DeleteLocalRef ( clazz );
}
异常处理 JNIEnv 内部函数抛出的异常 很多 JNIEnv 中的函数都会抛出异常,处理方法大体上是一致的:
返回值与特殊值(一般是 NULL)比较,知晓函数是否发生异常 如果发生异常立即 return jvm 会将异常抛给 java 层,我们可以在 java 层通过 try catch 机制捕获异常 JAVA:
public native void exceptionTest ();
//调用
try {
exceptionTest ();
} catch ( Exception e ) {
e . printStackTrace ();
}
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_exceptionTest ( JNIEnv * env , jobject thiz ) {
//查找的类不存在,返回 NULL;
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/xxx" );
if ( clazz == NULL ) {
return ; //return 后,jvm 会向 java 层抛出 ClassNotFoundException
}
}
// result:
java . lang . ClassNotFoundException : Didn ' t find class "com.yuandaima.myjnidemo.xxx" Native 回调 Java 层方法,被回调的方法抛出异常
Native 回调 Java 层方法,被回调的方法抛出异常。这样情况下一般有两种解决办法:
Java 层 Try catch 本地方法,这是比较推荐的办法。 Native 层处理异常,异常处理如果和 native 层相关,可以采用这种方式Native层不处理异常,Java层来处理异常 java:
//执行这个方法会抛出异常
private static int exceptionMethod () {
return 20 / 0 ;
}
//native 方法,在 native 中,会调用到 exceptionMethod() 方法
public native void exceptionTest ();
// MainActivity中调用是加上try-catch:
//Java 层调用
try {
exceptionTest ();
} catch ( Exception e ) {
//这里处理异常
//一般是打 log 和弹 toast 通知用户
e . printStackTrace ();
}
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_exceptionTest ( JNIEnv * env , jobject thiz ) {
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
//调用 java 层会抛出异常的方法
jmethodID static_method_id = env -> GetStaticMethodID ( clazz , "exceptionMethod" , "()I" );
if ( NULL == static_method_id ) {
return ;
}
//直接调用,发生 ArithmeticException 异常,传回 Java 层
env -> CallStaticIntMethod ( clazz , static_method_id );
env -> DeleteLocalRef ( clazz );
}
Native来处理异常 有的异常需要在 Native 处理,这里又分为两类:
异常在 Native 层就处理完了 异常在 Native 层处理了,还需要返回给 Java 层,Java 层继续处理 java:
//执行这个方法会抛出异常
private static int exceptionMethod () {
return 20 / 0 ;
}
//native 方法,在 native 中,会调用到 exceptionMethod() 方法
public native void exceptionTest ();
//Java 层调用
try {
exceptionTest ();
} catch ( Exception e ) {
//这里处理异常
//一般是打 log 和弹 toast 通知用户
e . printStackTrace ();
}
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_exceptionTest ( JNIEnv * env , jobject thiz ) {
jthrowable mThrowable ;
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
jmethodID static_method_id = env -> GetStaticMethodID ( clazz , "exceptionMethod" , "()I" );
if ( NULL == static_method_id ) {
return ;
}
env -> CallStaticIntMethod ( clazz , static_method_id );
//检测是否有异常发生
if ( env -> ExceptionCheck ()) {
//获取到异常对象
mThrowable = env -> ExceptionOccurred ();
//这里就可以根据实际情况处理异常了
//.......
//打印异常信息堆栈
env -> ExceptionDescribe ();
//清除异常信息
//如果,异常还需要 Java 层处理,可以不调用 ExceptionClear,让异常传递给 Java 层
env -> ExceptionClear ();
//如果调用了 ExceptionClear 后,异常还需要 Java 层处理,我们可以抛出一个新的异常给 Java 层
jclass clazz_exception = env -> FindClass ( "java/lang/Exception" );
env -> ThrowNew ( clazz_exception , "JNI抛出的异常!" );
env -> DeleteLocalRef ( clazz_exception );
}
env -> DeleteLocalRef ( clazz );
env -> DeleteLocalRef ( mThrowable );
}
引用类型的内存分析 Java 程序使用的内存 从逻辑上可以分为两个部分:
Java Memory 就是我们的 Java 程序使用的内存,通常从逻辑上区分为栈和堆。方法中的局部变量通常存储在栈中,引用类型指向的对象一般存储在堆中。Java Memory 由 JVM 分配和管理,JVM 中通常会有一个 GC 线程,用于回收不再使用的内存。
Java 程序的执行依托于 JVM ,JVM 一般使用 C/C++ 代码编写,需要根据 Native 编程规范去操作内存。如:C/C++ 使用 malloc()/new 分配内存,需要手动使用 free()/delete 回收内存。这部分内存我们称为 Native Memory。
Java 中的对象对应的内存,由 JVM 来管理,他们都有自己的数据结构。当我们通过 JNI 将一个 Java 对象传递给 Native 程序时,Native 程序要操作这块内存时(即操作这个对象),就需要了解这个数据结构,显然这有点麻烦了,所以 JVM 的设计者在 JNIenv 中定义了很多函数(NewStringUTF,FindClass,NewObject 等)来帮你操作和构造这些对象。同时也提供了引用类型(jobject、jstring、jclass、jarray、jintArray等)来引用这些对象。
明确引用类型的范围 引用类型是指针,指向的是 Java 中的对象在 JVM 中对应的内存。引用类型的定义如下:
#ifdef __cplusplus
class _jobject {};
class _jclass : public _jobject {};
class _jthrowable : public _jobject {};
class _jstring : public _jobject {};
class _jarray : public _jobject {};
class _jbooleanArray : public _jarray {};
class _jbyteArray : public _jarray {};
class _jcharArray : public _jarray {};
class _jshortArray : public _jarray {};
class _jintArray : public _jarray {};
class _jlongArray : public _jarray {};
class _jfloatArray : public _jarray {};
class _jdoubleArray : public _jarray {};
class _jobjectArray : public _jarray {};
typedef _jobject * jobject ;
typedef _jclass * jclass ;
typedef _jthrowable * jthrowable ;
typedef _jstring * jstring ;
typedef _jarray * jarray ;
typedef _jbooleanArray * jbooleanArray ;
typedef _jbyteArray * jbyteArray ;
typedef _jcharArray * jcharArray ;
typedef _jshortArray * jshortArray ;
typedef _jintArray * jintArray ;
typedef _jlongArray * jlongArray ;
typedef _jfloatArray * jfloatArray ;
typedef _jdoubleArray * jdoubleArray ;
typedef _jobjectArray * jobjectArray ;
#else
struct _jobject ;
typedef struct _jobject * jobject ;
typedef jobject jclass ;
typedef jobject jthrowable ;
typedef jobject jstring ;
typedef jobject jarray ;
typedef jarray jbooleanArray ;
typedef jarray jbyteArray ;
typedef jarray jcharArray ;
typedef jarray jshortArray ;
typedef jarray jintArray ;
typedef jarray jlongArray ;
typedef jarray jfloatArray ;
typedef jarray jdoubleArray ;
typedef jarray jobjectArray ;
#endif
不是以上类型的指针就不是 JNI 引用类型,比如容易混淆的 jmethod jfield 都不是 JNI 引用类型。
JNI 引用类型是指针,但是和 C/C++ 中的普通指针不同,C/C++ 中的指针需要我们自己分配和回收内存(C/C++ 使用 malloc()/new 分配内存,需要手动使用 free()/delete 回收内存)。JNI 引用不需要我们分配和回收内存,这部分工作由 JVM 完成。我们额外需要做的工作是在 JNI 引用类型使用完后,将其从引用表中删除,防止引用表满了。
局部引用 通过 JNI 接口从 Java 传递下来或者通过 NewLocalRef 和各种 JNI 接口(FindClass、NewObject、GetObjectClass和NewCharArray等)创建的引用称为局部引用。
当从 Java 环境切换到 Native 环境时,JVM 分配一块内存用于创建一个 Local Reference Table,这个 Table 用来存放本次 Native Method 执行中创建的所有局部引用(Local Reference)。每当在 Native 代码中引用到一个 Java 对象时,JVM 就会在这个 Table 中创建一个 Local Reference。比如,我们调用 NewStringUTF() 在 Java Heap 中创建一个 String 对象后,在 Local Reference Table 中就会相应新增一个 Local Reference。
对于开发者来说,Local Reference Table 是不可见的,Local Reference Table 的内存不大,所能存放的 Local Reference 数量也是有限的(在 Android 中默认最大容量是512个)。在开发中应该及时使用 DeleteLocalRef() 删除不必要的 Local Reference,不然可能会出现溢出错误。
很多人会误将 JNI 中的 Local Reference 理解为 Native Code 的局部变量。这是错误的:
局部变量存储在线程堆栈中,而 Local Reference 存储在 Local Ref 表中。 局部变量在函数退栈后被删除,而 Local Reference 在调用 DeleteLocalRef() 后才会从 Local Ref 表中删除,并且失效,或者在整个 Native Method 执行结束后被删除。 可以在代码中直接访问局部变量,而 Local Reference 的内容无法在代码中直接访问,必须通过 JNI function 间接访问。JNI function 实现了对 Local Reference 的间接访问,JNI function 的内部实现依赖于具体 JVM。 全局引用 Global Reference 是通过 JNI 函数 NewGlobalRef() 和 DeleteGlobalRef() 来创建和删除的。Global Reference 具有全局性,可以在多个 Native Method 调用过程和多线程中使用。
使用 Global reference时,当 native code 不再需要访问 Global reference 时,应当调用 JNI 函数 DeleteGlobalRef() 删除 Global reference 和它引用的 Java 对象。否则 Global Reference 引用的 Java 对象将永远停留在 Java Heap 中,从而导致 Java Heap 的内存泄漏。
弱全局引用 弱全局引用使用 NewWeakGlobalRef() 和 DeleteWeakGlobalRef() 进行创建和删除,它与 Global Reference 的区别在于该类型的引用随时都可能被 GC 回收。
对于 Weak Global Reference 而言,可以通过 isSameObject() 将其与 NULL 比较,看看是否已经被回收了。如果返回 JNI_TRUE,则表示已经被回收了,需要重新初始化弱全局引用。
Weak Global Reference 的回收时机是不确定的,有可能在前一行代码判断它是可用的,后一行代码就被 GC 回收掉了。为了避免这类事情发生,JNI官方给出了正确的做法,通过 NewLocalRef() 获取 Weak Global Reference,避免被GC回收。
JNI性能优化 Java 程序中,调用一个 Native 方法相比调用一个 Java 方法要耗时很多,我们应该减少 JNI 方法的调用,同时一次 JNI 调用尽量完成更多的事情。对于过于耗时的 JNI 调用,应该放到后台线程调用。 Native 程序要访问 Java 对象的字段或调用它们的方法时,本机代码必须调用 FindClass()、GetFieldID()、GetStaticFieldID、GetMethodID() 和 GetStaticMethodID() 等方法,返回的 ID 不会在 JVM 进程的生存期内发生变化。但是,获取字段或方法的调用有时会需要在 JVM 中完成大量工作,因为字段和方法可能是从超类中继承而来的,这会让 JVM 向上遍历类层次结构来找到它们。为了提高性能,我们可以把这些 ID 缓存起来,用内存换性能。 缓存java字段,方法ID java:
public class TestJavaClass {
//......
private void myMethod () {
Log . i ( "JNI" , "this is java myMethod" );
}
//......
}
public native void cacheTest ();
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_cacheTest ( JNIEnv * env , jobject thiz ) {
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
static jmethodID java_construct_method_id = NULL ;
static jmethodID java_method_id = NULL ;
//实现缓存的目的,下次调用不用再获取 methodid 了
if ( java_construct_method_id == NULL ) {
//构造函数 id
java_construct_method_id = env -> GetMethodID ( clazz , "<init>" , "()V" );
if ( java_construct_method_id == NULL ) {
return ;
}
}
//调用构造函数,创建一个对象
jobject object_test = env -> NewObject ( clazz , java_construct_method_id );
if ( object_test == NULL ) {
return ;
}
//相同的手法,缓存 methodid
if ( java_method_id == NULL ) {
java_method_id = env -> GetMethodID ( clazz , "myMethod" , "()V" );
if ( java_method_id == NULL ) {
return ;
}
}
//调用 myMethod 方法
env -> CallVoidMethod ( object_test , java_method_id );
env -> DeleteLocalRef ( clazz );
env -> DeleteLocalRef ( object_test );
}
主要是通过一个全局变量保存 methodid,这样只有第一次调用 native 函数时,才会调用 GetMethodID 去获取,后面的调用都使用缓存起来的值了。这样就避免了不必要的调用,提升了性能。
静态初始化 java:
static {
System . loadLibrary ( "myjnidemo" );
initIDs ();
}
public static native void initIDs ();
C++:
//定义用于缓存的全局变量
static jmethodID java_construct_method_id2 = NULL ;
static jmethodID java_method_id2 = NULL ;
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_initIDs ( JNIEnv * env , jclass clazz ) {
jclass clazz2 = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
//实现缓存的目的,下次调用不用再获取 methodid 了
if ( java_construct_method_id2 == NULL ) {
//构造函数 id
java_construct_method_id2 = env -> GetMethodID ( clazz2 , "<init>" , "()V" );
if ( java_construct_method_id2 == NULL ) {
return ;
}
}
if ( java_method_id2 == NULL ) {
java_method_id2 = env -> GetMethodID ( clazz2 , "myMethod" , "()V" );
if ( java_method_id2 == NULL ) {
return ;
}
}
}
手法和使用时缓存是一样的,只是缓存的时机变了。如果是动态注册的 JNI 还可以在 Onload 函数中来执行缓存操作。
多线程Demo JNI 环境下,进行多线程编程,有以下两点是需明确的:
JNIEnv 是一个线程作用域的变量,不能跨线程传递,每个线程都有自己的 JNIEnv 且彼此独立 局部引用不能在本地函数中跨函数使用,不能跨线程使用,当然也不能直接缓存起来使用 java:
public void javaCallback ( int count ) {
Log . e ( TAG , "onNativeCallBack : " + count );
}
public native void threadTest ();
C++:
static int count = 0 ;
JavaVM * gJavaVM = NULL ; //全局 JavaVM 变量
jobject gJavaObj = NULL ; //全局 Jobject 变量
jmethodID nativeCallback = NULL ; //全局的方法ID
//这里通过标志位来确定 两个线程的工作都完成了再执行 DeleteGlobalRef
//当然也可以通过加锁实现
bool main_finished = false ;
bool background_finished = false ;
static void * native_thread_exec ( void * arg ) {
LOGE ( TAG , "nativeThreadExec" );
LOGE ( TAG , "The pthread id : %d \n " , pthread_self ());
JNIEnv * env ;
//从全局的JavaVM中获取到环境变量
gJavaVM -> AttachCurrentThread ( & env , NULL );
//线程循环
for ( int i = 0 ; i < 5 ; i ++ ) {
usleep ( 2 );
//跨线程回调Java层函数
env -> CallVoidMethod ( gJavaObj , nativeCallback , count ++ );
}
gJavaVM -> DetachCurrentThread ();
background_finished = true ;
if ( main_finished && background_finished ) {
env -> DeleteGlobalRef ( gJavaObj );
LOGE ( TAG , "全局引用在子线程销毁" );
}
return (( void * ) 0 );
}
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_threadTest ( JNIEnv * env , jobject thiz ) {
//创建全局引用,方便其他函数或线程使用
gJavaObj = env -> NewGlobalRef ( thiz );
jclass clazz = env -> GetObjectClass ( thiz );
nativeCallback = env -> GetMethodID ( clazz , "javaCallback" , "(I)V" );
//保存全局 JavaVM,注意 JavaVM 不是 JNI 引用类型
env -> GetJavaVM ( & gJavaVM );
pthread_t id ;
if ( pthread_create ( & id , NULL , native_thread_exec , NULL ) != 0 ) {
return ;
}
for ( int i = 0 ; i < 5 ; i ++ ) {
usleep ( 20 );
//跨线程回调Java层函数
env -> CallVoidMethod ( gJavaObj , nativeCallback , count ++ );
}
main_finished = true ;
if ( main_finished && background_finished && ! env -> IsSameObject ( gJavaObj , NULL )) {
env -> DeleteGlobalRef ( gJavaObj );
LOGE ( TAG , "全局引用在主线程销毁" );
}
}
示例代码中,我们的子线程需要使用主线程中的 jobject thiz,该变量是一个局部引用,不能赋值给一个全局变量然后跨线程跨函数使用,我们通过 NewGlobalRef 将局部引用装换为全局引用并保存在全局变量 jobject gJavaObj 中,在使用完成后我们需要使用 DeleteGlobalRef 来释放全局引用,因为多个线程执行顺序的不确定性,我们使用了标志位来确保两个线程所有的工作完成后再执行释放操作。
C++线程安全 Memory Order 为什么需要 Memory Order 如果不使用任何同步机制(例如 mutex 或 atomic),在多线程中读写同一个变量,那么,程序的结果是难以预料的。主要原因有一下几点:
简单的读写不是原子操作 CPU 可能会调整指令的执行顺序 在 CPU cache 的影响下,一个 CPU 执行了某个指令,不会立即被其它 CPU 看见 非原子操作给多线程编程带来的影响 原子操作说的是,一个操作的状态要么就是未执行,要么就是已完成,不会看见中间状态。
下面看一个非原子操作给多线程编程带来的影响:
int64_t i = 0; // global variable
Thread-1: Thread-2:
i++; std::cout << i;
C++ 并不保证 i++ 是原子操作。从汇编的角度看,读写内存的操作一般分为三步:
将内存单元读到 cpu 寄存器 修改寄存器中的值 将寄存器中的值回写入对应的内存单元 进一步,有的 CPU Architecture, 64 位数据(int64_t)在内存和寄存器之间的读写需要两条指令。
这就导致了 i++ 操作在 cpu 的角度是一个多步骤的操作。所以 Thread-2 读到的可能是一个中间状态。
指令的执行顺序调整给多线程编程带来的影响 为了优化程序的执行性能,编译器和 CPU 可能会调整指令的执行顺序。为阐述这一点,下面的例子中,让我们假设所有操作都是原子操作:
int x = 0; // global variable
int y = 0; // global variable
Thread-1: Thread-2:
x = 100; while (y != 200) {}
y = 200; std::cout << x;
如果 CPU 没有乱序执行指令,那么 Thread-2 将输出 100。然而,对于 Thread-1 来说,x = 100; 和 y = 200; 这两个语句之间没有依赖关系,因此,Thread-1 允许调整语句的执行顺序:
Thread-1:
y = 200;
x = 100;
在这种情况下,Thread-2 将输出 0 或 100。
CPU CACHE 对多线程程序的影响 CPU cache 也会影响到程序的行为。下面的例子中,假设从时间上来讲,A 操作先于 B 操作发生:
int x = 0; // global variable
Thread-1: Thread-2:
x = 100; // A std::cout << x; // B
尽管从时间上来讲,A 先于 B,但 CPU cache 的影响下,Thread-2 不能保证立即看到 A 操作的结果,所以 Thread-2 可能输出 0 或 100。
同步机制 对于 C++ 程序来说,解决以上问题的办法就是使用同步机制,最常见的同步机制就是 std::mutex和 std::atomic。从性能角度看,通常使用 std::atomic 会获得更好的性能。 C++ 提供了四种 memory ordering :
Relaxed ordering Release-Acquire ordering Release-Consume ordering Sequentially-consistent ordering Relaxed ordering 在这种模型下,std::atomic 的 load() 和 store() 都要带上 memory_order_relaxed 参数。Relaxed ordering 仅仅保证 load() 和 store() 是原子操作,除此之外,不提供任何跨线程的同步。 先看看一个简单的例子:
std::atomic<int> x = 0; // global variable
std::atomic<int> y = 0; // global variable
Thread-1: Thread-2:
//A // C
r1 = y.load(memory_order_relaxed); r2 = x.load(memory_order_relaxed);
//B // D
x.store(r1, memory_order_relaxed); y.store(42, memory_order_relaxed);
执行完上面的程序,可能出现 r1 == r2 == 42。理解这一点并不难,因为编译器允许调整 C 和 D 的执行顺序。如果程序的执行顺序是 D -> A -> B -> C,那么就会出现 r1 == r2 == 42。 如果某个操作只要求是原子操作,除此之外,不需要其它同步的保障,就可以使用 Relaxed ordering。程序计数器是一种典型的应用场景:
#include <cassert>
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std :: atomic < int > cnt = { 0 };
void f ()
{
for ( int n = 0 ; n < 1000 ; ++ n ) {
cnt . fetch_add ( 1 , std :: memory_order_relaxed );
}
}
int main ()
{
std :: vector < std :: thread > v ;
for ( int n = 0 ; n < 10 ; ++ n ) {
v . emplace_back ( f );
}
for ( auto & t : v ) {
t . join ();
}
assert ( cnt == 10000 ); // never failed
return 0 ;
}
Release-Acquire ordering 在这种模型下,store() 使用 memory_order_release,而 load() 使用 memory_order_acquire。这种模型有两种效果,第一种是可以限制 CPU 指令的重排: 在 store() 之前的所有读写操作,不允许被移动到这个 store() 的后面。 在 load() 之后的所有读写操作,不允许被移动到这个 load() 的前面。 除此之外,还有另一种效果:假设 Thread-1 store() 的那个值,成功被 Thread-2 load() 到了,那么 Thread-1 在 store() 之前对内存的所有写入操作,此时对 Thread-2 来说,都是可见的。 下面的例子阐述了这种模型的原理:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std :: atomic < bool > ready { false };
int data = 0 ;
void producer ()
{
data = 100 ; // A
ready . store ( true , std :: memory_order_release ); // B
}
void consumer ()
{
while ( ! ready . load ( std :: memory_order_acquire )){} // C
assert ( data == 100 ); // never failed // D
}
int main ()
{
std :: thread t1 ( producer );
std :: thread t2 ( consumer );
t1 . join ();
t2 . join ();
return 0 ;
}
让我们分析一下这个过程: 首先 A 不允许被移动到 B 的后面。 同样 D 也不允许被移动到 C 的前面。 当 C 从 while 循环中退出了,说明 C 读取到了 B store()的那个值,此时,Thread-2 保证能够看见 Thread-1 执行 B 之前的所有写入操作(也即是 A)。
Release-Consume ordering 在这种模型下,store() 使用 memory_order_release,而 load() 使用 memory_order_consume。这种模型有两种效果,第一种是可以限制 CPU 指令的重排: 在 store() 之前的与原子变量相关的所有读写操作,不允许被移动到这个 store() 的后面。 在 load() 之后的与原子变量相关的所有读写操作,不允许被移动到这个 load() 的前面。 除此之外,还有另一种效果:假设 Thread-1 store() 的那个值,成功被 Thread-2 load() 到了,那么 Thread-1 在 store() 之前对与原子变量相关的内存的所有写入操作,此时对 Thread-2 来说,都是可见的。 下面的例子阐述了这种模型的原理:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std :: atomic < std :: string *> ptr ;
int data ;
void producer ()
{
std :: string * p = new std :: string ( "Hello" ); //A
data = 42 ;
//ptr依赖于p
ptr . store ( p , std :: memory_order_release ); //B
}
void consumer ()
{
std :: string * p2 ;
while ( ! ( p2 = ptr . load ( std :: memory_order_consume ))) //C
;
// never fires: *p2 carries dependency from ptr
assert ( * p2 == "Hello" ); //D
// may or may not fire: data does not carry dependency from ptr
assert ( data == 42 );
}
int main ()
{
std :: thread t1 ( producer );
std :: thread t2 ( consumer );
t1 . join (); t2 . join ();
}
让我们分析一下这个过程: 首先 A 不允许被移动到 B 的后面。 同样 D 也不允许被移动到 C 的前面。 data 与 ptr 无关,不会限制他的重排序 当 C 从 while 循环中退出了,说明 C 读取到了 B store()的那个值,此时,Thread-2 保证能够看见 Thread-1 执行 B 之前的与原子变量相关的所有写入操作(也即是 A)。
Sequentially-consistent ordering Sequentially-consistent ordering 是缺省设置,在 Release-Acquire ordering 限制的基础上,保证了所有设置了 memory_order_seq_cst 标志的原子操作按照代码的先后顺序执行。
常见问题解答:为什么我会收到 UnsatisfiedLinkError? 在处理原生代码时,经常可以看到如下所示的失败消息:
java.lang.UnsatisfiedLinkError: Library foo not found
在某些情况下,正如字面意思所说——找不到库。在 出现此库但无法被 dlopen 打开的其他情况,以及您可在异常的详情消息中找到失败详情。 您可能遇到“找不到库”异常的常见原因如下:
库不存在或应用无法访问。使用 adb shell ls -l,检查其是否存在 和权限。 库不是使用 NDK 构建的。这可能会导致 对设备上不存在的函数或库的依赖关系。 其他类的 UnsatisfiedLinkError 失败消息如下所示:
java.lang.UnsatisfiedLinkError: myfunc
at Foo.myfunc(Native Method)
at Foo.main(Foo.java:10)
在 logcat 中,您将看到以下内容:
W/dalvikvm( 880): No implementation found for native LFoo;.myfunc ()V
这意味着,运行时尝试查找匹配方法, 失败。造成此问题的一些常见原因如下:
库未加载。检查 logcat 输出, 库加载消息 名称或签名不匹配,因此找不到该方法。本次通常由以下原因引起:对于延迟方法查找,无法声明 C++ 函数 包含 extern "C" 和适当的可见性 (JNIEXPORT)。请注意,在投放 Ice Cream 之前, Sandwich 中,JNIEXPORT 宏不正确,因此请使用带有旧的jni.h将无法使用。 您可以使用 arm-eabi-nm 查看符号在库中显示的符号;如果它们 损坏(诸如_Z15Java_Foo_myfuncP7_JNIEnvP7_jclass之类的内容) 而不是 Java_Foo_myfunc),或者如果符号类型是 小写“t”而不是大写的“T”,则需要调整声明。 对于显式注册,在输入方法签名。请确保您传递到 与日志文件中的签名匹配。 记住 B 为 byte 和 Z 为 boolean 。签名中的类名称组成部分以 L 开头,以 ; 结尾,使用 / 分隔软件包 / 类名称,然后使用 $ 来分隔 内部类名称(比如 Ljava/util/Map$Entry;)。 使用 javah 自动生成 JNI 标头可能会有帮助可以避免一些问题。
常见问题解答:为什么 FindClass 找不到我的类? (以下建议的大部分内容同样适用于找不到方法的问题 包含 GetMethodID、GetStaticMethodID 或字段 使用 GetFieldID 或 GetStaticFieldID。) 确保类名称字符串的格式正确无误。JNI 类 名称以软件包名称开头,并用正斜线分隔 例如 java/lang/String。如果您要查找数组类, 您需要以适当数量的方括号开头还必须使用 L 封装类和 ; 这样的一个一维数组, String 为 [Ljava/lang/String;。 如果您要查找内部类,请使用 $ 而不是 . 。一般来说, 对 .class 文件使用 javap 是查找类的内部名称。
如果要启用代码缩减,请确保配置要保留的代码。正在配置适当的保留规则非常重要,因为代码压缩器可能会从别处移除类、方法 或仅通过 JNI 使用的字段。
如果类名称没有问题,则可能是因为您遇到了类加载器 问题。FindClass想要在与代码关联的类加载器。它会检查调用堆栈,如下所示:
Foo.myfunc(Native Method)
Foo.main(Foo.java:10)
最顶层的方法是 Foo.myfunc。FindClass 查找与 Foo 关联的 ClassLoader 对象 类并使用该类。
采用这种方法通常会完成您想要执行的操作。如果您 自行创建线程(可能通过调用 pthread_create) ,然后使用 AttachCurrentThread 附加该映像)。现在 不是来自应用的堆栈帧。 如果您从此线程调用 FindClass, JavaVM 将在“system”下启动类加载器,而不是 与您的应用关联,因此尝试查找特定于应用的类将失败。
您可以通过以下几种方法来解决此问题:
FindClass JNI_OnLoad,并缓存类引用以供日后使用 。执行过程中进行的任何 FindClass 调用 JNI_OnLoad 将使用与 调用 System.loadLibrary 的函数(这是 特殊规则,以方便执行库初始化)。 如果您的应用代码要加载库,请FindClass 将使用正确的类加载器。 将类的实例传递到 方法是声明原生方法接受 Class 参数 然后传入 Foo.class。 在某处缓存对 ClassLoader 对象的引用 然后直接发出 loadClass 调用。这需要 不费吹灰之力 常见问题解答:如何使用原生代码共享原始数据? 您可能会发现自己需要访问大量 来自受管理代码和原生代码的原始数据的缓冲区。常见示例包含对位图或声音样本的操纵。有两个基本方法。 您可以将数据存储在 byte[] 中。这样可让系统 通过托管代码进行访问。而在原生广告方面访问相应数据,而无需复制数据。在一些实现,GetByteArrayElements 和 GetPrimitiveArrayCritical 将返回指向 托管堆中的原始数据,但在其他情况下,系统会分配缓冲区 并复制数据 另一种方法是将数据存储在直接字节缓冲区中。这些可使用 java.nio.ByteBuffer.allocateDirect 创建,或 JNI NewDirectByteBuffer 函数。不同于普通 字节缓冲区,因此存储空间不会在托管堆上分配,并且可以 始终直接从原生代码中访问(获取 与 GetDirectBufferAddress 相关联)。取决于 已实现字节缓冲区访问,从托管代码访问数据可能会非常慢 选择使用哪种方法取决于以下两个因素:
大部分数据访问是通过使用 Java 编写的代码进行的吗 还是用 C/C++ 开发? 如果数据最终传递到系统 API,以 应该在其中吗?(例如,如果数据最终传递到函数,它接受一个 byte[] 值,直接 ByteBuffer 可能不太明智。) 如果这两种方法不分伯仲,请使用直接字节缓冲区。为他们提供的支持 直接内置在 JNI 中,性能应该会在未来版本中得到改进。 模块名词解释 一种常见架构
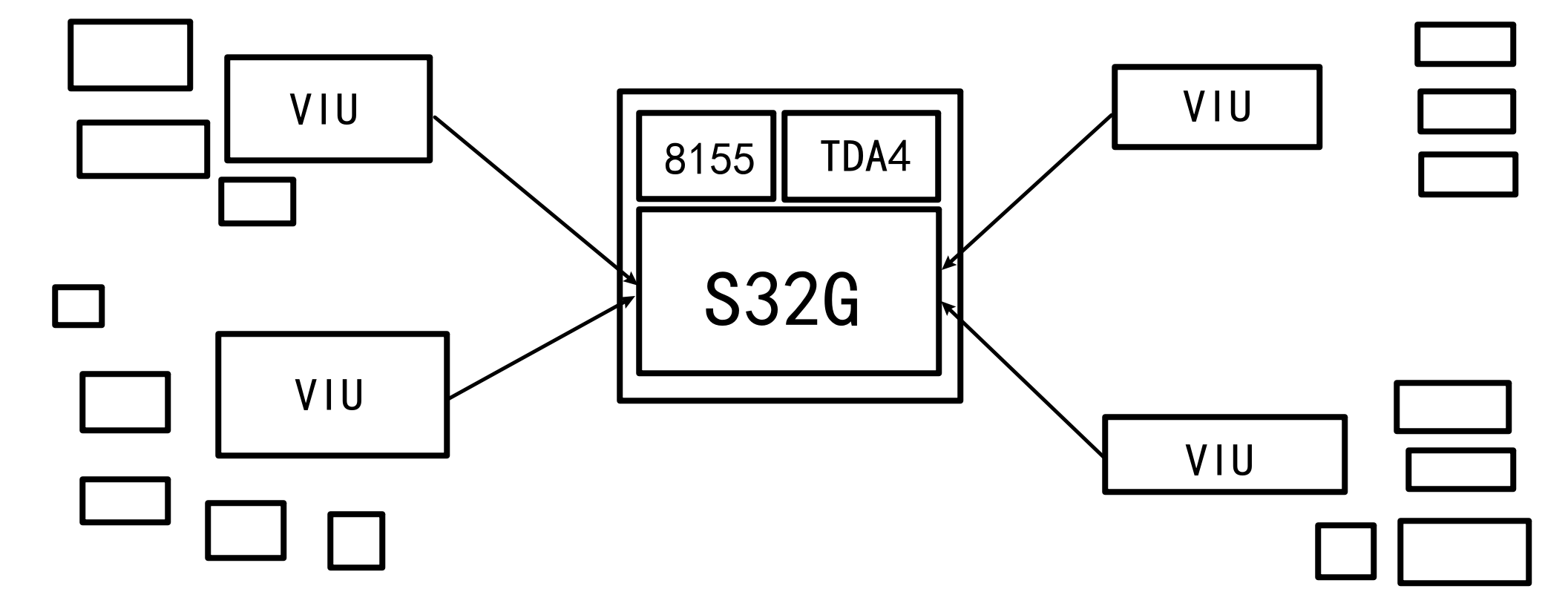
VIU 汽车电子系统中的一个重要组成部分,它是一种称为“车辆信息单元”的设备,也被称为“车辆智能单元”,是车辆智能化的核心部件之一。VIU是英文Vehicle Information Unit的缩写,其主要功能是收集车辆的各种信息并进行处理。
VIU由众多不同的传感器、执行器和微控制器组成,它们单独或联合工作,从不同的方面监测和分析车辆的各项数据。传感器可以感知发动机状态、温度、湿度、油压、燃油消耗量等各类参数,执行器则能够控制发动机、座椅、车门等车辆各部分,微控制器则负责控制各种数据从传输到处理。
S32G 在域控制器中,网关处理器的作用不容忽视,其作为域控制器的中心枢纽,负责安全和功能域(如动力传动、底盘与安全、车身控制、信息娱乐和ADAS等)之间互联并处理异构车载网络中的数据。S32G采用M核+A核多核异构架构,兼顾实时应用以及高算力应用场景,并且具有ASIL D的功能安全等级,集成了低延迟通信引擎LLCE,数据包转发引擎PFE,硬件安全引擎HSE等独立内核,非常适合作为主控制器,整合传统网关,BCM,VCU等多个ECU控制逻辑。
S32G M核基于AUTOSAR CP, 可以处理CAN/LIN信号,系统启动,电源管理,健康管理,车控等对实时性要求较高的应用,以及多种安全策略和功能处理策略。 S32G A核运行Linux或者QNX,满足对于处理多路千兆以太网、大数据收集与分析、整车OTA、数据存储、远程诊断等功能,可部署多种通信协议和相关学习算法。M核和A核之间既可以采用核间通信IPCF,交换延迟要求非常低的数据,也可以通过PFE共享以太网接口,实现高吞吐量数据交换需求。
其内部有如下模块:
整车域控制组件:集成网关、车窗控制、灯光控制等功能模块; 动力域控制组件:集成整车控制器、电池管理系统、热管理系统等功能模块; 底盘域控制组件:集成智能控制悬挂、电子驻车单元等系统功能模块; 车载中央计算机:可协调各个域控单元组件有序工作; 更多应用场景可根据客户实际需求进行功能组件的组合。 可以说其为整车的核心控制器,身兼中央网关信号中转和重要逻辑处理等多个角色。
TDA4 TDA4是德州仪器推出的一款高性能、超异构的多核SoC,拥有ARM Cortex-R5F、ARM Cortex-A72、C66以及C71内核,可以部署AUTOSAR CP系统、HLOS(Linux或QNX)、图像处理以及深度学习等功能模块,从而满足ADAS对实时性、高运算能力、环境感知及深度学习等方面的需求。
TDA4凭借着出色的运算能力、有竞争性的价格,赢得了越来越多汽车主机厂以及零部件供应商的青睐。
这款智能驾驶处理芯片,计算效率高,工具链成熟,但是算力低,行泊一体将导致其想要完善的能力所带来的要求也极高。
8155 相当于手机的高通855芯片,属于高端旗舰级别,事实上诞生于2019年的高通8155其实就是基于855手机芯片“魔改”而来的,当时高通855芯片在业内也算是领先水平,该芯片多应用在各品牌的旗舰级手机上,因此基于855打造的车规级8155性能也不会差。2019年所发布的8155芯片,至今除了特斯拉的AMD主机级锐龙芯片以外,仍然是天花板级别的存在,其稳定性、可靠性也能够经得起时间的考验,这也是为什么如今众多车企都选择高通骁龙8155。业内一般方案为quick unix系统上套安卓虚拟机的方案,以更稳定的qnx系统来作为硬件直接交互的角色,并且仪表显示等重要模块是运行在qnx系统上的应用,而Android系统由于其不稳定性,更适合作为系统和车控设置项、娱乐信息屏幕的承载系统。
不同电器架构上层共性 一个车控功能,链路从对应的底层控制器到座舱控制器的网络拓扑随着项目的电器架构而变化,一般分为两种情况:
分布式架构,各个控制器彼此独立,使用CAN总线进行通信; 集中式架构,一般有一个域控制器作为中心网络中转的角色,各个控制器都通过域控制器进行通信。 不管底层架构如何,当信号到了座舱域的8155或者8295控制器之后,信号的链路就是一致的了,网络层到硬件抽象层,再到系统FW的CarService层,最后通过Binder接口给到应用层。
信号的上下行流程 车控信号的上下行流程一般分为以下几个步骤:
用户手动操作控件之后,应用下发对应的setter接口,调用request信号。 座舱域的控制器将信号转发出去; 目的控制器接收之后,做出对应处理,将操作的结果通过另一个广播信号或者setter的同一个信号返回上去 座舱域的控制器将底层的反馈,回调给应用层。 而应用需要做的一般有下面几件事:
界面初始化根据获取的初始值来刷新界面; 点击控件可以下发信号; 操作完毕之后,要根据反馈的信号来刷新页面; 用户离手一段时间后(2s或者3s),需要主动获取一次开关的状态,刷新开关状态。即回弹逻辑,防止实际执行失败,却传达了执行成功的信息。 不同UI控件信号处理规范 Switch开关类 开关一般用于各个设置项,比如氛围灯,智驾功能,蓝牙,网络开关等。
Switch有切换时下发指令和显示开关状态的需求。
下发指令只能通过用户手动点击触发,不可自行发送信号; 状态显示有主动获取与被动接收通知之分,主动获取常见的策略是在点击之后若干秒后,去获取当前的功能信号状态,进而刷新开关状态。被动接收通知为长期监听。 底层因某些错误发出置灰信号,或者功能在某种条件下自动打开或关闭,都需要及时地反馈到界面的switch上。注意这种主动和被动的更新常常是冲突的,处理不好会导致开关快速闪动。
变种类switch,严格来说是Button,具有非此即彼,互斥状态的控件。比如可能设计成一个高亮色块,通过不同颜色图标来表示开关此时的状态,往往还需要更改开关的文字描述,例:
下游执行快 若座舱域的下游控制器可以做到快速切换,只是信号链路传输慢,可以在用户每次点击开关后,都直接往下发设置信号。单次点击一般没有问题,主要分析快速多次点击这种容易出问题的场景。 快速点击期间都移除掉信号监听removeCallbacks,也不进行状态的主动获取刷新 。
在快速点击时期结束,用户手指最后一次点击若干秒后,主动获取一次开关状态,这种情况下,开关状态一般和最后一次点击下发的值是同步的,不会有回弹现象。
并且在主动获取之后,重新加上开关的被动监听刷新机制。即可以支持快速接收并执行指令的,上层芯片可以只管发,处理好自己的UI就行。
下游执行慢 如果该功能是控制器执行速度慢,可以在开关的快速点击期间,只跟随用户操作变动Switch的UI,不往下发setter信号,在最后一次点击结束后,过几百ms,再往下游控制器发送setter信号,快速点击期间,车控信号被动的监听也是移除的,在主动获取状态刷新UI之后,再加上状态监听。
例如下面是500ms防抖的设置方法,两次点击间隔500ms以内,会移除掉上一次的逻辑,只有快速点击完成后,过500ms,才会继续执行逻辑。
switch . setOnCheckedChangeListener { buttonView , isChecked ->
mHandler . removeCallbacks ( signalRunnable )
mHandler . postDelayed ( signalRunnable , 500L )
SignalUtil . sendSignal ()
}
即不可快速自由切换的功能的,上层芯片需要过滤点击事件,尽量将一次抖动流程里只发最后一帧信号。
以上两种是用户体验较好的方案,可以支持快速点击,只取最后一次点击使其生效。
加入点击限制 除了防抖,还可以使用点击限制,在点击后的若干时间内,直接使开关除能,不再接收点击事件,在此期间加入置灰或者加载loading的样式提示此开关暂时不可用。
这种纯粹的点击限制,在用户体验上不是特别好,最好加入说明文案等。适合比较复杂的功能,像底层ECU执行时间特别长(2s以上),并且多次频繁下发值有可能导致其出错的场景。
val switchEnableRunnable = Runnable { switch . isEnabled = true }
switch . setOnCheckedChangeListener { buttonView , isChecked ->
switch . isEnabled = false
mHandler . removeCallbacks ( switchEnableRunnable )
mHandler . postDelayed ( switchEnableRunnable , 2000L )
SignalUtil . sendSignal ()
}
RadioGroup 类控件 这类控件组,往往是同一个功能,走同一个信号接口,有两个以上的待选项,可以选取不同参数的功能。比如 驾驶模式 选择的控件。
这类控件的处理方式和上述 switch 开关类控件类似。
执行时间长的需要限制点击下发,某段时间内只允许一次点击; 信号链路长的功能,可以不限制点击,只限制回调刷新UI。在快速点击过程中,信号是即点即发,直到快速点击后的若干秒内,UI控件不响应回调数据的变化,在防抖动流程结束后,主动获取一次状态,并重新添加上回调监听更新UI的逻辑。防止刷新时的循环设置 RadioGroup加入 checkchanged 监听,可以监听开关项变化。但是由信号被动刷新时,也会触发这个回调,如果在这个里面设置的信号下发和埋点计算逻辑,就会重复计算。
甚至有时候时间差恰到好处的话,会导致两个开关项之间循环设置,不断跳动。
mRgMainBlowFace . setOnCheckedChangeListener (( group , checkedId ) -> {
// 发送set信号
SignalUtil . sendSignal ();
// 埋点计算
ReportUtil . report ();
});
可以对RadioGroup进行封装,对OnCheckedChangeListener加入一个本地变量来保存,加入一个 updateChecked 方法替代原来的刷新方案,在这个 update 方法里,先把 checkListener 给移除掉,再改变选中项的状态,操作完毕再把回调加回去。
public class RadioGroupEx extends RadioGroup {
private RadioGroup . OnCheckedChangeListener mCheckedChangeListener ;
public RadioGroupEx ( Context context ) {
super ( context );
}
public RadioGroupEx ( Context context , AttributeSet attrs ) {
super ( context , attrs );
}
public void setOnCheckedChangeListener ( @Nullable RadioGroup . OnCheckedChangeListener listener ) {
this . mCheckedChangeListener = listener ;
super . setOnCheckedChangeListener ( listener );
}
public void updateChecked ( int checkedId ) {
super . setOnCheckedChangeListener (( RadioGroup . OnCheckedChangeListener ) null );
this . check ( checkedId );
super . setOnCheckedChangeListener ( this . mCheckedChangeListener );
}
}
持续调节自定义View类 首先重温一下点击事件分发与消耗机制:
当一个点击事件产生后,它的传递过程遵循如下顺序: Activity -> Window -> View,即事件总是先传递给Activity,Activity再传递给Window,最后Window再传递给顶级View。
顶级View接收到事件后,就会按照事件分发机制去分发事件。考虑一种情况,如果一个View的 onTouchEvent 返回false,那么它的父容器的onTouchEvent将会被调用,依此类推。
如果所有的元素都不处理这个事件,那么这个事件将会最终传递给Activity处理,即Activity的 onTouchEvent 方法会被调用。
这种长按持续调节的交互方式,需要手动实现控件的ontouch方法,并监听手势滑动轨迹,在 Action MOVE 回调方法里实时更新自己的UI,并且持续性地发送信号。
插入,ontouch方法和onTouchEvent方法:
boolean onTouch(View v, MotionVent event)
触摸事件发送到视图时调用(v:视图,event:触摸事件)
返回true:事件被完全消耗(即,从down事件开始,触发move,up所有的事件)
返回fasle:事件未被完全消耗(即,只会消耗掉down事件)
boolean onTouchEvent(MotionEvent event)
触摸屏幕时调用
返回值,同上
注意:
1、onTouch优先级比onTouchEvent高
2、如果button设置了onTouchListener监听,onTouch方法返回了true,就不会调用这个button的Click事件
下面是一个复写 OnTouchListener 的例子:
mCushionTouch . setOnTouchListener (( view , motionEvent ) -> {
if ( motionEvent . getAction () == MotionEvent . ACTION_DOWN ) {
}
if ( motionEvent . getAction () == MotionEvent . ACTION_MOVE ) {
// DO YOUR WORK
// UPDATE UI & SEND SIGNAL
return true ;
}
});
这种控件,在车控领域,一般用在座椅位置和空调风向的调节上,需要其既能响应用户手动滑动,来更新界面UI样式,又可以根据底层反馈更新。
在手动调节时,同样的,为了避免界面显示错乱,需要在touch调节时移除回调更新UI的逻辑,以用户手动调节的位置为最高优先级,调节完成后若干时间后,获取状态更新UI,再重新添加上回调去监听更新的逻辑。注意界面首次调节的起始点必须是当前的位置,不可出现跳动现象。
滑动条SeekBar类 这一类控件常被用来作为 进度条 展示,也具有 手动调节 的功能。
一般是亮度,音量,充放电电量等具有一定调节范围的设置项。它有三个回调方法,分别是onProgressChanged,onStartTrackingTouch,onStopTrackingTouch,代表调节时,按下时,抬起时。
其中 onProgressChanged 的回调相当之快,除非有动态变化显示的需求,否则不建议在这里处理逻辑,或者在这里的逻辑加上防抖限制,一定时间内只调用一次。曾经我在这里调用埋点方法,利用系统服务处理网络上传请求,导致系统崩溃黑屏。后续改到停止调节时上传,一次touch操作只会传一次。
这类调节条的更新逻辑与其他控件类似,在下发方案上主要分两类:
需求上实时调节的,比如氛围灯颜色,音量,亮度,在跟手时硬件即响应变化,用户体验比较好,这种需要在onProgressChanged回调里进行信号的发送。 不需要实时调节的,是那种无法直观观察到变化的设置项,比如车辆充放电截止电量,能动回收百分比,各种灵敏度等,这就推荐在手指抬起或者按下时调用一次,不处理变化中的逻辑。 以上两种方案有一个共同的更新逻辑,就是在快速调节(滑动or快速点击)中,不响应底层数据反馈,避免进度条乱跳,在设置后一段时间内,主动获取状态,并重新加上数据监听被动更新。
signalSeekbar . setOnSeekBarChangeListener ( new SeekBar . OnSeekBarChangeListener () {
@Override
public void onProgressChanged ( SeekBar seekBar , int i , boolean b ) {
}
@Override
public void onStartTrackingTouch ( SeekBar seekBar ) {
}
@Override
public void onStopTrackingTouch ( SeekBar seekBar ) {
}
});
有步长的Seekbar体验优化 比如设置某个信号,底层只能接受像5,15,25等5的倍数的信号值。而将seekbar的步长设置为5,在滑动时会有明显的卡顿感。
所以为了丝滑调节,可以设置默认步长1,采用整除回乘的算法来将区间数据处理成需要的数据,比如32整除5为6,再乘5就是30。
至于快速调节过程中可能出现的回调闪烁问题,则采用防抖或者节流算法来减少频次,再控制一下回调刷新UI的逻辑,即可实现体验最优的seekbar滑动调节信号收发。
Android图片加载体系 在 Android 中,加载并显示一张图片文件(如 JPEG、PNG)到屏幕上,核心机制是 Bitmap -> Drawable -> ImageView 的配合使用。
Bitmap 存储图片在内存中的实际像素数据(如 RGB 值)。Drawable 属于抽象层,代表可绘制对象,是所有可绘制内容的抽象基类,作为 Bitmap 与 View 之间的桥梁,管理 Bitmap 的绘制状态和尺寸信息。ImageView负责将 Drawable 对象的内容绘制到屏幕上,并处理用户交互。
配合加载一张图片文件的完整流程 当一张图片文件(例如 image.jpg)从磁盘或网络被加载,直到最终显示在 ImageView 中,主要分为以下三个步骤:
步骤 1: 图片数据解码成 Bitmap(数据准备) 图片文件本身是经过压缩的(如 JPEG),不能直接显示。这一步的任务是将压缩数据解压并解码成原始像素数据 。
解码: 使用 BitmapFactory 或 ImageDecoder 等 API,将 image.jpg 文件读取为字节流。生成 Bitmap: 解码器根据字节流,在内存(RAM)中开辟一块空间,将图片的像素数据填充进去,创建出 Bitmap 对象。内存占用: 此时 Bitmap 占用的内存大小 = 图片像素宽 × 图片像素高 × 每个像素占用的字节数(如 ARGB_8888 模式下占 4 字节)。关键代码: BitmapFactory.decodeFile(path) 或 ImageDecoder.decodeBitmap(source)
步骤 2: Bitmap 封装成 Drawable(状态管理) Bitmap 纯粹是像素数据,而 Android 的 View 系统需要一个可绘制对象 (Drawable) 来进行绘制和状态管理。
封装: Bitmap 对象会被封装到一个具体的 Drawable 子类中,最常见的是 BitmapDrawable。提供信息: BitmapDrawable 获得了 Bitmap 像素信息后,还添加了绘制所需的额外信息,比如:固有的宽高 (getIntrinsicWidth/getIntrinsicHeight): 来源于 Bitmap 的像素尺寸。不透明度、颜色过滤、状态(选中/按下等): 允许在绘制时对 Bitmap 进行调整和控制。关键代码(底层): BitmapDrawable drawable = new BitmapDrawable(resources, bitmap);
步骤 3: ImageView 绘制 Drawable(视图呈现) ImageView 是最终的显示容器,它负责将 Drawable 的内容呈现在屏幕上。
设置 Drawable: 通过 imageView.setImageDrawable(drawable) 或 imageView.setImageBitmap(bitmap)(内部会自动封装成 BitmapDrawable)将 Drawable 对象交给 ImageView。计算尺寸: ImageView 会根据自身的布局参数(如 layout_width、layout_height)和 scaleType(如 centerCrop、fitCenter)来决定如何缩放和裁剪内部的 Drawable。触发绘制: 在 ImageView 的 onDraw() 方法中,它会调用 Drawable.draw(canvas) 方法,让 Drawable 将其内部的 Bitmap 绘制到 ImageView 的画布(Canvas)上,最终呈现在屏幕上。关键代码(上层): imageView.setImageBitmap(bitmap) 或在 XML 中使用 android:src="@drawable/..."。
Coil Coil (全称 Co routine I mage L oader) 是一个专为 Android 打造的现代化图片加载库,它之所以被认为是高效的,主要得益于其现代化的架构和多项针对性的优化。
以下是 Coil 优化的主要方面:
1. 核心架构优化 (基于 Kotlin 协程) 这是 Coil 最核心的优化点。Coil 的名字就来源于此。它完全基于 Kotlin 协程 (Coroutines) 来执行所有的异步操作(如网络请求、磁盘I/O、图片解码)。
相比于传统的线程池或 AsyncTask,协程更加轻量级。它们可以挂起 (suspend) 而不阻塞线程,从而用更少的线程处理大量的并发请求。这减少了线程切换的开销,提高了吞吐量,并且能非常简单地实现请求的取消和管理。
2. 内存优化 Coil 在内存管理上做了大量工作,以避免 OutOfMemoryError 并保持应用流畅:
图像降采样 (Downsampling): Coil的第一次解码只读取图片的原始宽高(不分配内存)。根据原始宽高和目标 ImageView 的宽高,计算出最佳的inSampleSize采样率。再带着计算出的inSampleSize进行第二次解码,将缩小的 Bitmap 加载到内存。Bitmap 池化 (Bitmap Pooling): Coil 会复用 Bitmap 对象。当一个 Bitmap 不再需要显示时,它会被放回一个“池”中,而不是立即被垃圾回收 (GC)。当需要加载新图片时,Coil 会尝试从池中获取一个可复用的 Bitmap,而不是重新分配内存。这大大减少了 GC 的频率,从而减少了 UI 卡顿。内存缓存 (Memory Cache): 使用 LruCache(最近最少使用算法)在内存中快速缓存已经加载的图片。如果同一张图片被再次请求,Coil 会直接从内存中读取,实现即时加载。自动大小调整 (Automatic Sizing for Compose): 在 Jetpack Compose 中使用时,AsyncImage 能够自动检测 Composable 的约束(大小),并请求一个最优尺寸的图片。3. 网络与磁盘 I/O 优化 Coil 将网络请求和磁盘缓存完全委托给了 OkHttp,将文件I/O委托给了 Okio。
OkHttp 是目前 Android 上最高效、最主流的网络库,它内置了连接池、gzip压缩、HTTP/2 支持和强大的磁盘缓存系统。Okio 则提供了非常高效的缓冲I/O操作。Coil 无需“重复造轮子”,直接站在了巨人的肩膀上。
利用 OkHttp 的磁盘缓存,实现网络图片的持久化存储,下次请求时(即使应用重启)也能快速加载。新版本的 Coil 支持遵循服务器的 Cache-Control 响应头,实现更智能的网络缓存策略。
4. 请求与生命周期管理 Coil 自动与 androidx.lifecycle 库集成。它会观察 Activity、Fragment 或 Composable 的生命周期。当组件进入 onStop 或 onDestroy 状态时,Coil 会自动取消相关的图片加载请求,这避免了无效的计算、内存占用和潜在的内存泄漏。
如果短时间内有多个地方请求同一张图片(例如在 RecyclerView 中),Coil 只会发起一次加载任务,并将结果分发给所有请求方。
支持设置图片加载的优先级,确保关键图片(如屏幕内的图片)优先于非关键图片(如屏幕外的图片)加载。
5. 轻量级与现代 API 相比于 Glide 和 Fresco,Coil 的库体积和方法数都更小,有助于减小 APK 大小。其API 设计简洁易用,充分利用了 Kotlin 的语言特性(如扩展函数、lambda 等)。与 Glide 不同,Coil 不使用注解处理器,这可以轻微加快应用的编译速度。
总结来说,Coil 的最大优化在于它全面拥抱了 Kotlin 协程和 OkHttp/Okio 这一现代化技术栈 ,并在此基础上实现了一套高效的内存管理(降采样、Bitmap池化)和智能的请求生命周期控制。
当初学者熟悉软件在该平台上的运行机制,开始大量写代码之后,在软件项目的架构设计上应该符合 SOLID 原则。
SOLID 是 Robert C. Martin(“Uncle Bob”) 提出的一组五个基本原则的首字母缩写,旨在帮助开发者设计更易于理解、维护和扩展的软件系统:
Single Responsibility Principle (单一职责原则)
Open/Closed Principle (开闭原则)
Liskov Substitution Principle (里氏替换原则)
Interface Segregation Principle (接口隔离原则)
Dependency Inversion Principle (依赖反转原则)
其中的依赖反转原则是指:
高层模块不应该依赖低层模块,两者都应该依赖其抽象。抽象不应该依赖细节,细节应该依赖抽象。
简单来说,就是我们在设计系统时,不应该让高层组件直接依赖于低层组件的具体实现,而是应该让它们都依赖于抽象(例如接口或抽象类)。
什么是依赖? 在软件开发中,“依赖”指的是一个对象需要另一个对象来完成其功能。比如,一个 Car 对象可能需要一个 Engine 对象才能启动和运行。这时,我们可以说 Car 依赖 Engine。
传统的做法是,Car 对象在自己的内部创建或查找 Engine 对象:
class Car {
private Engine engine ;
public Car () {
this . engine = new Engine (); // Car 自己创建了 Engine 对象
}
public void start () {
engine . ignite ();
System . out . println ( "Car started!" );
}
}
这种也叫直接依赖,其问题在于:
紧耦合: 如果低层模块的实现细节发生变化,高层模块也可能需要修改。 测试困难: 在测试高层模块时,你不得不依赖真实的低层模块,这使得单元测试变得复杂且效率低下。你无法轻易地替换一个模拟的数据访问层。 可扩展性差: 增加新的低层实现会影响到所有依赖它的高层模块。 什么是依赖注入? 依赖注入的核心思想是:一个对象不应该自己创建或查找它所依赖的对象,而是应该由外部(通常是一个“注入器”或“容器”)提供这些依赖。 依赖反转是我们的设计目标,依赖注入就是实现的路径。
在 Car 和 Engine 的例子中,如果使用依赖注入,Car 就不再负责创建 Engine,而是等待外部把 Engine “注入”进来。结合Kotlin的构造函数写法, Car 类可以写成下面这种简洁的形式:
class Car ( val engine : Engine ) {
public void start () {
engine . ignite ();
System . out . println ( "Car started!" );
}
}
这种设计方案有哪些好处呢?
首先最明显的就是 解耦 ,对象不再需要关心它所依赖对象的创建细节,它们只需要知道如何使用这些依赖。这使得代码更灵活,更容易修改和扩展。
其次是 可测试性 和 可维护性 提高了。更有利于单元测试,同时当外部的依赖发生变化时,只需要修改创建和提供依赖的部分,而不需要修改所有依赖该对象的代码。
还可以 提高代码复用性 ,独立的对象可以更容易地在不同的场景和组件中重用。
在 Android 端的依赖注入设计理念,整体的发展方向是从最初的手动管理到功能强大的自动化框架。
在早期的 Android 开发中,并没有成熟的 DI 框架。通常采用直接创建依赖示例的方式,后面又出现了由策略模式驱动的服务定位器的形式来提供依赖。
手动实例化 这是最直接的方式,在一个类中直接 new 出它所需要的依赖。多了之后导致代码紧耦合,难以测试和维护,特别是当依赖链很深时,修改一个地方可能需要改动很多地方。服务定位器 这个模式会引入一个中央注册表(或单例)来存储和提供依赖。类需要依赖时,就向这个注册表“请求”对应的实例。优点: 相对于手动实例化,服务定位器提供了一定程度的解耦,因为消费者不再直接创建依赖。问题: 仍然存在隐藏依赖。你不知道一个类需要哪些依赖,除非查看其实现。难以追踪对象生命周期,并且测试时替换模拟对象不够优雅。它更像是“查找依赖”而不是“注入依赖”。Dagger 1:初次尝试编译时注入 在 2012 年左右,Square 公司推出了 Dagger 。这是 Android 平台第一个真正意义上的依赖注入框架,并且它采用了编译时 代码生成的方式。
没有运行时的反射开销,带来了性能优势。它使用了 注解处理器 在编译阶段生成注入代码。
但是 Dagger 的配置和使用相对复杂,尤其是对于大型项目而言,编写和维护大量的模块 (Module) 和组件 (Component) 样板代码 成为一个挑战。
Dagger 2:性能与可扩展性的飞跃 2015 年,Google 接手 Dagger 项目并发布了全新的 Dagger 2 。Dagger 2 是对 Dagger 1 的彻底重写,它秉承了 Dagger 1 的 编译时生成 的特性,但在设计理念和实现上有了重大改进。
Dagger 2 在编译时生成代码,这些代码负责实例化对象并提供它们的依赖。这意味着在运行时没有反射开销,性能非常高。它通过注解处理器来分析你的代码,生成一个 依赖图 ,然后根据这个图生成相应的 Java 代码。它生成的是直接的 Java 代码,模拟了你在手写工厂类和提供器时的行为,从而在性能上达到了极致。
运行 Dagger 2 示例需要添加 Dagger 依赖并配置注解处理器。在 Android 项目中,通常在 build.gradle 文件中配置。比如使用Kotlin的话,需要在 build.gradle 中配置 kapt 插件:
plugins {
id 'com.android.application'
id 'org.jetbrains.kotlin.android'
id 'kotlin-kapt' // 配置 Kotlin 注解处理器插件
}
Dagger 2 在使用时需要定义模块和组件。
定义依赖接口和实现: // repository/UserRepository.java
interface UserRepository {
void saveUser ( String username );
}
// repository/DatabaseUserRepository.java
class DatabaseUserRepository implements UserRepository {
@Override
public void saveUser ( String username ) {
System . out . println ( "Saving user " + username + " to database." );
}
}
定义提供依赖的 Module: import dagger.Module ;
import dagger.Provides ;
import javax.inject.Singleton ; // Dagger 2 提供的作用域注解
// di/AppModule.java
@Module
public class AppModule {
@Provides // 提供 UserRepository 实例
@Singleton // 将 UserRepository 定义为单例
UserRepository provideUserRepository () {
return new DatabaseUserRepository ();
}
}
定义注入器 Component: import dagger.Component ;
import javax.inject.Singleton ;
// di/AppComponent.java
@Singleton // AppComponent 也是单例作用域
@Component ( modules = AppModule . class ) // 关联 AppModule
public interface AppComponent {
// 定义注入方法,MyPresenter 可以通过这个方法被注入依赖
void inject ( MyPresenterWithDagger presenter );
}
在需要注入的类中使用 @Inject: import javax.inject.Inject ;
// presenter/MyPresenterWithDagger.java
class MyPresenterWithDagger {
@Inject // 声明需要注入 UserRepository
UserRepository userRepository ;
public MyPresenterWithDagger () {
// Dagger 2 会在调用 inject(this) 后自动填充 userRepository
}
public void registerUser ( String username ) {
userRepository . saveUser ( username );
System . out . println ( "User " + username + " registered." );
}
}
在 Application 或 Main 方法中初始化和使用: // main/MainDagger2.java
public class MainDagger2 {
public static void main ( String [] args ) {
// ✨ 构建 Dagger 组件,这个 DaggerAppComponent 是 Dagger 2 编译时生成的
AppComponent component = DaggerAppComponent . builder (). build ();
MyPresenterWithDagger presenter = new MyPresenterWithDagger ();
// ✨ 执行注入操作,Dagger 会找到 @Inject 标注的字段并填充依赖
component . inject ( presenter );
presenter . registerUser ( "Alice" );
}
}
Dagger 2 具有如下优点:
极高性能: 纯粹的编译时生成代码,运行时无反射开销,性能极佳。类型安全: 编译时即可发现依赖错误,将运行时崩溃降到最低。强大的模块化能力: 提供了 @Module、@Provides、@Component、@Subcomponent、@Scope 等丰富的注解,可以精细地控制依赖的提供和生命周期。Dagger 2 推出之后,很快成为 Android 平台最主流、最强大的 DI 框架。
它解决了大规模项目中的依赖管理难题,但也继承了其复杂性,仍然需要开发者投入大量时间学习和配置。
Hilt:Google 官方简化 Dagger 2020 年,Google 推出了 Hilt ,这是构建在 Dagger 2 之上 的 Android 官方推荐的依赖注入库。Hilt 的主要目标是简化 Dagger 在 Android 应用中的使用 。大量减少项目中为了实现依赖注入而创建的重复的样板代码。
值得一提的是,在Google官方开源的旨在展示最新Android技术的开源项目—— NowInAndroid 中,就使用了Hilt来实现依赖注入。
Hilt 的核心思想是通过提供一套 标准化的 Android 组件绑定 (例如 @AndroidEntryPoint、@ApplicationContext、@ActivityContext 等),以及预定义的作用域,极大地 减少了 Dagger 所需的样板代码 和手动配置。
Hilt 基于注解实现,针对每个需要被注入的属性,Hilt 都会基于 KAPT/KSP 在编译期间查找它的注入源头,并生成一对一的注入方法。
添加依赖和插件:
// project/build.gradle
buildscript {
dependencies {
classpath 'com.google.dagger:hilt-android-gradle-plugin:2.51.1' // 检查最新版本
}
}
// app/build.gradle
plugins {
id 'kotlin-kapt' // 或 id 'androidx.navigation.safeargs.kotlin' 如果使用 kotlin
id 'com.google.dagger.hilt.android'
}
dependencies {
implementation 'com.google.dagger:hilt-android:2.51.1'
kapt 'com.google.dagger:hilt-compiler:2.51.1'
// ... 其他依赖
}
在 Application 类上添加 @HiltAndroidApp:
import android.app.Application
import dagger.hilt.android.HiltAndroidApp
// di/MyApplication.kt
@HiltAndroidApp // Hilt 的入口点,触发代码生成
class MyApplication : Application () {
// 通常不需要在这里写额外的代码,Hilt 会自动管理组件
}
定义依赖接口和实现 (与 Dagger 类似):
// repository/UserRepository.kt
interface UserRepository {
fun saveUser ( username : String )
}
// repository/DatabaseUserRepository.kt
// Hilt 可以在构造函数上直接使用 @Inject 来告知如何创建实例
import javax.inject.Inject
import javax.inject.Singleton
@Singleton // Hilt 也支持 Dagger 的作用域注解
class DatabaseUserRepository @Inject constructor () : UserRepository { // 🚀 构造函数注入的标志
override fun saveUser ( username : String ) {
println ( "Saving user $username to database." )
}
}
注意: 如果 DatabaseUserRepository 的构造函数没有参数,或者其参数都可以被 Hilt 自动提供,那么可以直接使用 @Inject constructor()。对于第三方库或接口,仍然需要使用 @Module 和 @Provides。
定义 Hilt 模块(针对接口或外部类):
import dagger.Binds
import dagger.Module
import dagger.hilt.InstallIn
import dagger.hilt.components.SingletonComponent
import javax.inject.Singleton
// di/AppModule.kt
@Module
@InstallIn ( SingletonComponent :: class ) // 🚀 指定模块安装到哪个 Hilt 组件(例如 Application 级别)
abstract class AppModule { // 使用 abstract class 可以更高效地绑定接口
@Binds // 🚀 绑定接口到具体实现
@Singleton
abstract fun bindUserRepository ( impl : DatabaseUserRepository ): UserRepository
}
在 Android 组件上使用 @AndroidEntryPoint 和 @Inject:
import androidx.appcompat.app.AppCompatActivity
import android.os.Bundle
import dagger.hilt.android.AndroidEntryPoint
import javax.inject.Inject
// activity/MainActivity.kt
@AndroidEntryPoint // 🚀 标记这是一个 Hilt 入口点,Hilt 会为它生成组件并注入依赖
class MainActivity : AppCompatActivity () {
@Inject // 🚀 自动注入 UserRepository 实例
lateinit var userRepository : UserRepository
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
setContentView ( R . layout . activity_main )
userRepository . saveUser ( "Charlie" )
println ( "User Charlie saved from MainActivity." )
}
}
Hilt具有如下优点:
集成度高: 与 Android 框架组件(Activity, Fragment, ViewModel, Service 等)无缝集成,自动生成 Dagger 组件。易用性: 显著降低了 Dagger 的学习曲线和使用门槛。Google 官方支持: 作为官方推荐的 DI 解决方案,Hilt 在未来的发展和维护上更有保障。保留 Dagger 优势: 依然是编译时注入,拥有 Dagger 的高性能和类型安全。Hilt 迅速成为 Android DI 的“新宠”,尤其适合新项目和希望简化 Dagger 配置的现有项目。在 nowinandroid 中使用,也代表了它是当前官方认为的 Android 依赖注入的最佳实践。
Koin:运行时注入的轻量级选择 随着 Kotlin 在 Android 领域的崛起,又出现了一些纯 Kotlin 编写的 DI 框架。其中,Koin 在 2017 年左右脱颖而出。
Koin 采取了与 Dagger 完全不同的策略,它是一个运行时 依赖注入框架,不使用注解处理器,而是利用 Kotlin 的 DSL(领域特定语言)来声明依赖。Koin 在运行时通过 Kotlin 的 DSL 解析依赖关系,不依赖反射或注解处理器,避免了 Dagger 的编译时代码生成复杂性,启动速度更快。
Koin 除了使用上轻量化,还具有以下优点:它的配置简单,学习曲线平缓,几乎没有样板代码。与 Kotlin 语言特性无缝集成,代码简洁。由于没有注解处理,编译速度通常比 Dagger 更快。
同时,Koin 由于运行时生成的特点,如果有些依赖配置出错,只有在运行时才可以发现 。
Koin 采用 Kotlin DSL,不需要注解处理器。
步骤:
定义依赖接口和实现 (与 Dagger 类似): // repository/UserRepository.kt
interface UserRepository {
fun saveUser ( username : String )
}
// repository/DatabaseUserRepository.kt
class DatabaseUserRepository : UserRepository {
override fun saveUser ( username : String ) {
println ( "Saving user $username to database." )
}
}
定义 Koin 模块: import org.koin.dsl.module
// di/appModule.kt
val appModule = module {
// single 表示单例,get() 会自动解析并提供所需的依赖
single < UserRepository > { DatabaseUserRepository () }
}
定义需要依赖的类: import org.koin.core.component.KoinComponent
import org.koin.core.component.inject
// presenter/MyPresenterWithKoin.kt
class MyPresenterWithKoin : KoinComponent { // 实现 KoinComponent 接口
// 🚀 通过 inject() 委托属性来获取依赖
private val userRepository : UserRepository by inject ()
fun registerUser ( username : String ) {
userRepository . saveUser ( username )
println ( "User $username registered." )
}
}
在 Application 或 Main 方法中启动 Koin: import org.koin.core.context.startKoin
import org.koin.core.context.stopKoin
// main/MainKoin.kt
fun main () {
// ✨ 启动 Koin 上下文,并加载模块
startKoin {
modules ( appModule )
}
val presenter = MyPresenterWithKoin ()
presenter . registerUser ( "Bob" )
stopKoin () // 清理 Koin 上下文
}
Koin 的核心优势在于 简洁性 和 Kotlin 原生支持,通过 DSL 和运行时解析降低了 DI 的学习成本,适合追求开发效率的项目。但对于超大型应用或对性能极度敏感的场景,可能需要权衡其运行时解析的开销。如果你正在使用 Kotlin 开发 Android 或后端服务,Koin 是一个值得尝试的轻量级 DI 方案。
现如今,Kotlin Multiplatform 跨平台的迅速发展,Koin 也推出了其跨平台版本,在 Android,IOS,Desktop和 web 端 的Kotlin跨平台项目里,都可以助力开发者实现依赖注入,支持功能的快速开发。
初始化 整体的冷启动流程在这篇文章有详细记录:
【Android进阶】APP冷启动流程解析
Activity Window View初始加载 Activity、Window 和 View 这三者是构成安卓应用用户界面的核心。
这三者之间的层级和协作关系:
Activity (活动) :是安卓应用的四大组件之一,是用户交互的直接入口。它本身并不负责视图的绘制,而是作为窗口(Window)的容器,并管理界面的生命周期(例如,创建、暂停、销毁等)。你可以把它想象成一个舞台的管理者或导演。Window (窗口) :每个 Activity 都包含一个 Window 对象,通常是 PhoneWindow 的实例。Window 才是真正代表一个“窗口”的概念。它负责承载界面元素,并将这些元素传递给 WindowManager 进行显示。你可以把它看作是舞台本身,所有的布景(View)都在这个舞台上。View (视图) :是所有 UI 控件(如 Button, TextView)的基类。它负责在屏幕上绘制具体的内容,并处理用户的触摸事件。一个 Window 内部通常包含一个复杂的 View 树(View Hierarchy),最顶层的 View 被称为 DecorView。你可以把 View 看作是舞台上的演员和布景。总结来说,Activity 持有一个 Window,而 Window 持有一个 View 树(以 DecorView 为根)。Activity 负责逻辑控制和生命周期管理,Window 负责承载和管理视图,而 View 负责最终的绘制和事件处理。
初始化时机与关键周期事件 Activity 对象的初始化发生在 ActivityThread 中,通过 performLaunchActivity() 方法完成。在这个过程中,系统会通过反射调用 Activity 的无参构造函数来创建 Activity 实例。紧接着,系统会调用 Activity 的 attach() 方法,在这个方法内部,Activity 会创建一个 PhoneWindow 实例,从而将 Activity 和 Window 关联起来。
attach 时期 attach() 方法并不是 Activity 生命周期的一部分,开发者通常不需要也不应该 重写它。它是框架在内部用于初始化 Activity 的一个关键步骤。
提供 Context :attach() 的最重要职责是关联一个 Context 对象。在调用 attach() 之前,Activity 实例内部的 mBase (Context) 是 null 的。调用之后,Activity 才拥有了上下文,从而能够执行诸如 getResources()、getSystemService()、getPackageName() 等操作。没有 Context,Activity 几乎什么都做不了。创建 Window :在 attach() 方法内部,Activity 会创建一个 PhoneWindow 的实例,并赋值给成员变量 mWindow。这意味着在 onCreate() 被调用之前,Activity 已经有了一个关联的窗口对象。这就是为什么你可以在 onCreate() 里立即调用 setContentView() 的原因,因为 setContentView() 实际上是调用了 mWindow.setContentView()。关联其他组件 :除了 Context 和 Window,attach() 还会将 Activity 与其他一些重要的系统组件关联起来,例如 Application 对象、Instrumentation 等。// Activity.java window的创建与初始化
final void attach ( Context context , ActivityThread aThread ,
Instrumentation instr , IBinder token , int ident ,
Application application , Intent intent , ActivityInfo info ,
...) {
// 创建PhoneWindow实例
mWindow = new PhoneWindow ( this , window );
// 设置Window回调
mWindow . setCallback ( this );
// 设置Window管理器
mWindow . setWindowManager (...);
}
onCreate 时期onCreate() 是我们熟知的 Activity 生命周期的第一个回调方法。它是开发者进行 Activity 初始化的主要入口。
最常见的操作就是调用 setContentView(R.layout.activity_main),这一步依赖于在 attach() 中创建好的 Window 对象。
// PhoneWindow的setContentView方法
public void setContentView ( int layoutResID ) {
// 1. 检查是否有DecorView,没有则创建
if ( mContentParent == null ) {
installDecor ();
} else {
// 如果已有内容视图,则移除
mContentParent . removeAllViews ();
}
// 2. 将布局inflate到mContentParent中
mLayoutInflater . inflate ( layoutResID , mContentParent );
// 3. 通知Activity内容已改变
final Callback cb = getCallback ();
if ( cb != null && ! isDestroyed ()) {
cb . onContentChanged ();
}
}
mContentParent 实例通常是一个 FrameLayout 对象。用于容纳内容视图,这一步就是将 R.layout.main 对应的视图结构,作为子视图添加(addView())到这个 mContentParent(即 FrameLayout)中。
onResume() 时期Activity和窗口创建完成后, ActivityThread 调用 handleResumeActivity 来执行其 onResume() 流程,在 Activity 的 onResume() 周期回调之后,执行 makeVisible() 。
然后 WindowManager 执行 addView 动作,开启视图绘制逻辑,创建 ViewRootImpl 对象,并调用其 setView 方法。
public void addView (...) {
// 创建ViewRootImpl对象
root = new ViewRootImpl ( view . getContext (), display );
...
try {
// 执行ViewRootImpl的setView函数
root . setView ( view , wparams , panelParentView , userId );
} catch ( RuntimeException e ) {
...
}
}
setView() 源码:
/*frameworks/base/core/java/android/view/ViewRootImpl.java*/
public void setView ( View view , WindowManager . LayoutParams attrs , View panelParentView ,
int userId ) {
synchronized ( this ) {
if ( mView == null ) {
mView = view ;
}
...
// 开启绘制硬件加速,初始化RenderThread渲染线程运行环境
enableHardwareAcceleration ( attrs );
...
// 1.触发绘制动作
requestLayout ();
...
inputChannel = new InputChannel ();
...
// 2.Binder调用访问系统窗口管理服务WMS接口,实现addWindow添加注册应用窗口的操作,并传入inputChannel用于接收触控事件
res = mWindowSession . addToDisplayAsUser ( mWindow , mSeq , mWindowAttributes ,
getHostVisibility (), mDisplay . getDisplayId (), userId , mTmpFrame ,
mAttachInfo . mContentInsets , mAttachInfo . mStableInsets ,
mAttachInfo . mDisplayCutout , inputChannel ,
mTempInsets , mTempControls );
...
// 3.创建WindowInputEventReceiver对象,实现应用窗口接收触控事件
mInputEventReceiver = new WindowInputEventReceiver ( inputChannel ,
Looper . myLooper ());
...
// 4.设置DecorView的mParent为ViewRootImpl
view . assignParent ( this );
...
}
}
setView() 方法中,ViewRootImpl 会将传入的 View(即 DecorView)与窗口管理器(WindowManager)关联起来,并设置必要的参数。随后,ViewRootImpl 会调用 requestLayout() 来请求布局更新,这会触发后续的测量、布局和绘制流程。
关于绘制三大步主要涉及不同的View和ViewGroup的测量布局规则不同,细节也可以看冷启动文章。
UI刷新流程 Choreographer 编舞者介绍 Choreographer 是 Android 框架中一个至关重要的系统服务 ,它主要负责协调动画、输入事件和 UI 绘制操作的计时,确保这些操作都在每一次屏幕硬件刷新信号(Vsync) 到来时同步进行。
简单来说,Choreographer的核心作用是实现流畅的、与屏幕刷新同步的 UI 渲染 。
核心作用:同步 Vsync 信号 Choreographer 最主要的作用是将应用程序的渲染操作(如绘制、动画计算)与显示屏的垂直同步信号(Vertical Synchronization,简称 Vsync)对齐 。
Vsync 信号是显示硬件发出的一个周期性信号,表示屏幕已经完成了当前帧的显示,可以开始接收下一帧的数据。 在大多数设备上,Vsync 信号的频率是 $60Hz$,意味着每 $16.67$ 毫秒($1000ms / 60$ 帧)发生一次。
在 没有 Choreographer 协调的情况下 ,如果应用在屏幕刷新到一半时提交了新的帧数据,就会导致屏幕的上下部分显示两帧不同的内容,形成视觉上的“撕裂”现象(Tearing)。
Choreographer 确保应用的绘制操作只在 Vsync 信号到来后才开始执行,并且在下一个 Vsync 信号到来之前完成,从而彻底消除画面撕裂 。
如果应用程序在 16.67ms 内没有完成 Measure、Layout 和 Draw 的全部过程,它就会错过当前的 Vsync 信号,导致该帧无法及时显示,用户就会感觉到“卡顿”或“丢帧”(Jank)。
Choreographer 的职责是提供一个清晰的计时框架,让开发者能明确知道自己有多少时间来完成渲染。它为所有需要基于时间同步的操作(如动画、滚动)提供了一个统一、可靠的时间源(Vsync 时间),确保它们以相同的节奏进行。
还可以将在一个短时间内发生的多个 View.invalidate() 请求合并起来,只在下一个 Vsync 周期内统一执行一次 Measure/Layout/Draw,避免不必要的重复渲染,优化性能。
Choreographer工作流程详解 当您执行一个需要更新 UI 的操作(例如调用 $View.invalidate()$ 或启动一个动画)时,Choreographer 的工作流程如下:
注册回调: 应用层(如 ViewRootImpl 或 Animator)会向 Choreographer 注册一个回调。等待 Vsync: Choreographer 收到注册请求后,不会立即执行,而是等待系统下一次 Vsync 信号的到来。Vsync 信号到达: 当 Vsync 信号到来时,Choreographer 会被唤醒。执行回调: Choreographer 会在当前这一帧的处理周期内,按照预定的优先级顺序依次执行已注册的各类回调:CALLBACK_INPUT: 处理输入事件(如触摸)。CALLBACK_ANIMATION: 执行动画计算(如 $ValueAnimator$ 的值更新)。CALLBACK_TRAVERSAL (最重要): 执行 View 树的“遍历”($Measure$、 $Layout$、 $Draw$)操作,即完成 UI 的实际渲染。CALLBACK_COMMIT: 提交绘制结果到 SurfaceFlinger。所有的操作在一个 Vsync 周期(16.67ms)内完成,并将新的图像数据提交给显示系统,等待下一次 Vsync 信号到来时显示。
View.invalidate() 刷新流程 整个渲染流水线通常可以分为以下几个核心阶段:触发 (Invalidate) 、同步 (Sync/Vsync) 、绘制 (Draw) 、提交 (Issue Commands) 、光栅化 (Rasterization) 和 显示 (Display) 。
1. 触发与同步阶段 当 View 的内容发生变化,需要重绘时,调用此方法。它不会立即重绘,而是将 View 标记为“脏 (dirty)”。 invalidate() 最终会将重绘请求传递给 ViewRootImpl。ViewRootImpl 会调度一个重绘操作 (通过 Choreographer.postCallback),等待下一个 Vsync 信号。
设备屏幕以固定的刷新率(如 60Hz)定时发出垂直同步信号 (Vsync)。Choreographer 收到 Vsync 信号。
同步 (Sync) 阶段开始后ViewRootImpl 会执行 traversal。包括 Measure 和 Layout 以确定 View 的位置。还有动画任务计算动画的下一帧属性值。
2. 绘制阶段 (CPU 生成 DisplayList) 系统从根 View 开始递归调用 draw() 方法。但在硬件加速开启时 ,这个 draw() 不再是直接绘制像素,而是记录 绘制操作。
每个 View 的 draw() 方法会将绘制命令(如 “画一个矩形”、”画一个 Bitmap” 等)记录到它自己的 DisplayList 中。DisplayList 是一种可重用的,优化的渲染操作序列。这一步由 Android 的渲染引擎 (在旧版本是 OpenGL ES,新版本是 Vulkan/Skia) 在 CPU 上完成。
3. 提交与传输阶段 (CPU/GPU 协同) 当所有 View 的 DisplayList 都生成后,这些列表会被交给 RenderThread (渲染线程) ,这是一个独立于主线程的线程。RenderThread 会处理 DisplayList,并将所需的资源(例如,新解码的 Bitmap )从 CPU 内存传输到 GPU 内存,作为 纹理 (Texture) 。这是 CPU 和 GPU 内存之间的同步操作。RenderThread 将 DisplayList 中的高级绘制命令,转换为底层的图形 API 命令,即 Draw Calls (通常是 OpenGL ES 或 Vulkan API 调用),并将这些命令排队等待 GPU 执行。
4. 光栅化与处理阶段 (GPU 工作为主) 光栅化 (Rasterization) 阶段开始 :GPU 从队列中取出 Draw Calls。光栅化是将向量图形指令(如绘制一个三角形)转换为屏幕上的像素颜色值的过程。 GPU 利用其强大的并行计算能力,对 Draw Calls 中引用的纹理进行采样、应用着色器 (Shader) 程序(如顶点着色器和片段着色器)来确定每个像素的最终颜色。 GPU 将处理完成的像素数据写入到它控制的 帧缓冲区 (Frame Buffer) 中。通常有前后两个缓冲区(双缓冲机制)。
5. 显示阶段 (系统级工作) 当一帧完全渲染到“后缓冲区”后,RenderThread 会调用 swapBuffers()SurfaceFlinger (系统级的窗口合成器)该帧已准备好。
SurfaceFlinger 是一个系统服务,它负责收集所有可见窗口(应用、状态栏、导航栏等)的最新帧缓冲区,并根据它们的 Z-order、位置和透明度,将它们合成到最终的屏幕缓冲区中。这个合成过程本身也可以由 GPU 加速完成。
在下一个 Vsync 信号到来时,显示硬件 (Display Hardware)从最终的合成缓冲区读取数据,并将图像电流发送到屏幕,最终用户才能看到更新后的内容。
JVM内存模型
程序计数器:一小块区域, 线程私有 。记录了每个线程的代码执行到了哪一行,各种循环,判断都是通过这个区域存的数值来走的。Java多线程是时间分片,各个线程在一段时间内占用这个核来执行任务,这个线程切换到另一个线程,其恢复的依据也是计数器的值。 虚拟机栈:周期与线程相同,也是 线程私有 。每个方法执行时,都会创建一个栈帧, 栈帧里面存储方法内的局部变量表,方法出口等等信息 。每个方法执行到退出的过程,就是一个个的方法栈帧入栈出栈的过程。这个区域有两个异常,如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;如果JVM允许动态扩展,当栈扩展时无法申请到足够的内存会抛出 OutOfMemoryError 异常。 本地方法栈:和虚拟机栈作用一样,但是服务于 本地的Native方法 。同样会抛出上面的两种异常。 Java堆:最大的一块,所有 线程共享 的数据。几乎所有的对象实例都在这里保存。Java堆是垃圾收集器管理的内存区域。Java堆可以处于物理上不连续的内存空间中,可以选择固定大小或可扩展。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出 OutOfMemoryError 异常。 方法区: 线程共享 。用于存储已被虚拟机加载的 对象类型信息、常量、静态变量、即时编译器编译后的代码缓存 等数据。对其要求比较宽松,几乎不用考虑垃圾回收,但是回收也是有必要的,主要针对常量的回收和类型卸载。如果方法区无法满足新的内存分配需求时,将抛出 OutOfMemoryError 异常。运行时常量池,其是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。运行期间也可以将新的常量放入池中。 类加载流程 父子类加载的具体流程
加载阶段父类优先:当加载一个类时,JVM会先检查其父类是否已加载 递归加载:如果父类未被加载,则会递归加载父类及其父类,直到Object类 子类后加载:所有父类加载完成后,才开始加载子类 准备阶段父类优先:为父类的静态变量分配内存并设置默认值 子类后处理:然后为子类的静态变量分配内存并设置默认值 初始化阶段父类优先:执行父类的静态代码块和静态变量赋值 子类后处理:然后执行子类的静态代码块和静态变量赋值 实例化时的加载顺序 当创建子类实例时,加载顺序如下:
父类静态成员和静态块(只在第一次加载类时执行一次) 子类静态成员和静态块(只在第一次加载类时执行一次) 父类实例变量初始化 父类构造代码块 父类构造函数 子类实例变量初始化 子类构造代码块 子类构造函数 代码示例
class Parent {
static {
System . out . println ( "Parent静态代码块" );
}
{
System . out . println ( "Parent构造代码块" );
}
public Parent () {
System . out . println ( "Parent构造函数" );
}
}
class Child extends Parent {
static {
System . out . println ( "Child静态代码块" );
}
{
System . out . println ( "Child构造代码块" );
}
public Child () {
System . out . println ( "Child构造函数" );
}
}
public class Test {
public static void main ( String [] args ) {
new Child ();
}
}
输出:
Parent静态代码块 Child静态代码块 Parent构造代码块 Parent构造函数 Child构造代码块 Child构造函数
设计模式 见另一篇详细文章: 设计模式
垃圾回收流程 JVM 根搜索算法(GC ROOT Tracing) Java中采用了该算法来判断对象是否是存活的,也叫可达性分析。
通过一系列名为 GC Roots 的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论来说就是从GC Roots到这个对象不可达)时,则证明对象是不可用的,即该对象是“死去”的,同理,如果有引用链相连,则证明对象可以,是“活着”的。
哪些可以作为GC Roots的对象呢?Java 语言中包含了如下几种:
1)虚拟机栈(栈帧中的本地变量表)中的引用的对象。
2)方法区中的类静态属性引用的对象。
3)方法区中的常量引用的对象。
4)本地方法栈中JNI(即一般说的Native方法)的引用的对象。
5)运行中的线程
6)由引导类加载器加载的对象
7)GC控制的对象
回收流程 现代商用虚拟机基本都采用分代收集算法 来进行垃圾回收,当然这里的分代算法是一种混合算法,不同时期采用不同的算法来回收。
由于不同的对象的生命周期不一样,分代的垃圾回收策略正式基于这一点。因此,不同生命周期的对象可以采取不同的回收算法,以便提高回收效率。该算法包含三个区域:年轻代(Young Generation)、年老代(Old Generation)、持久代(Permanent Generation) 。
年轻代(Young Generation) 所有新生成的对象首先都是放在年轻代中。年轻代的目标就是尽可能快速地回收哪些生命周期短的对象。
新生代内存按照8:1:1的比例分为一个Eden区和两个survivor(survivor0,survivor1)区。
Eden区,字面意思翻译过来,就是伊甸区,人类生命开始的地方。当一个实例被创建了,首先会被存储在该区域内,大部分对象在Eden区中生成。 Survivor区,幸存者区,字面理解就是用于存储幸存下来对象。 回收时机:
一开始都在Eden区里,当Eden快满了就触发回收,之后,先将Eden区还存活的对象复制到一个Survivor0区,然后清空Eden区。 当这个Survivor0区也存放满了后,则将Eden和Survivor0区中存活对象都复制到另外一个survivor1区,然后清空Eden和这个Survivor0区,此时的Survivor0区就也是空的了。 然后将Survivor0区和Survivor1区交换,即保持Servivor1为空,如此往复。 这种回收算法也叫 复制算法 ,即将存活对象复制到另一个区域,然后尽可能清空原来的区域。
新生代发生的GC也叫做 Minor GC ,MinorGC发生频率比较高,不一定等Eden区满了才会触发。
为什么设置两个survivor区域?
如果只有一个eden区和一个survivor区,那么假设场景,当发生ygc后,存活对象从eden迁移到survivor,这样看好像没什么问题,很棒,但是假设eden满了,这个时候要进行ygc,那么发现此时,eden和survivor都保存有存活对象,那么你是不是要对这两个区域进行gc,找出存活对象,那么你想想是不是难度很大,还容易造成碎片,如果你使用复制算法,那么难度很大,那么耗时很长。如果你使用标记清除算法,那么很容易造成内存碎片。
所以如果存在两个survivor区,那么工作就非常的轻松,只需要在eden区和其中一个survivor(b1)找出存活对象,一次性放到另一个空的survivor(b2),然后再直接清除eden区和survivor(b1),这样效率是不是就很快了。
年轻代往老年代转移的条件
有一个JVM参数 -XX:PretenureSizeThreshold ,默认值是0,表示任何情况都先把对象分配给Eden区。若设置为1048576字节,也就是1M。则表示当创建的对象大于1M时,就会直接把这个对象放入到老年区,就根本不会经过新生区了。这么做的原因: 大对象在经历复制算法进行GC的时候会降低性能 。 如果新生区中的某个对象 经历了15次GC 后,还是没有被回收掉,那么它就会被转入老年区。 如果当Survivor1区不足以存放Eden区和Survivor0的存活对象时,就将存活对象 直接放到年老代 。 如果年老代也满了,就会触发一次Major GC(即Full GC),即新生代和年老代都进行回收。
年老代(Old Generation) 在新生代中经历了多次GC后仍然存活的对象,就会被放入到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
年老代比新生代内存大很多(大概比例2:1?),当年老代中存满时触发Major GC,即Full GC,Full GC发生频率比较低,年老代对象存活时间较长,存活率比较高。
一开始对象都是任意分布的,在经历完垃圾回收之后,就会标记出哪些是存活对象,哪些是垃圾对象,然后就会把这些存活的对象在内存中进行整理移动,尽量都挪到一边去靠在一起,然后再把垃圾对象进行清除,这样做的好处就是避免了垃圾回收后产生的大片内存碎片。
即此处采用的叫 Compacting 算法,由于该区域比较大,而且通常对象生命周期比较长,compaction需要一定的时间,所以这部分的GC时间比较长。较为耗时,比复制算法慢10倍;
所以如果系统频繁出现Full GC,会严重影响系统性能,出现卡顿。所以JVM优化的一大问题就是减少Full GC频率。
持久代(Permanent Generation) 持久代用于存放静态文件,如Java类、方法等,该区域比较稳定,对GC没有显著影响。这一部分也被称为运行时常量,有的版本说JDK1.7后该部分从方法区中移到GC堆中,有的版本却说,JDK1.7后该部分被移除,有待考证。
DVM & Art 这两个虚拟机的垃圾回收见另一篇详细文章:
【Android进阶】JVM&DVM&ART虚拟机对比
强引用、弱引用、软引用、虚引用 强引用是最常见的引用类型,通过new创建的对象默认都是强引用。只要强引用存在,垃圾回收器永远不会回收 被引用的对象。可能导致内存泄漏(当对象不再需要但仍有引用指向它时),使用场景为普通对象创建,需要长期持有的对象。
弱引用通过WeakReference类创建,当垃圾回收器执行时,无论内存是否足够 ,都会回收 被弱引用引用的对象。使用场景为缓存对象,当对象不再需要时,可以被垃圾回收器回收。一般为临时缓存,主要防止内存泄漏。
软引用通过SoftReference类创建,当内存不足时 ,垃圾回收器会回收软引用引用的对象 。使用场景为内存敏感的对象,当内存不足时,可以被垃圾回收器回收。例如缓存对象,图片缓存等。
虚引用通过PhantomReference类创建,虚引用不会影响对象的生命周期,主要用于跟踪对象被垃圾回收器回收的状态 。使用场景为对象被垃圾回收器回收时的回调。
内存泄漏常见场景 见性能优化篇: 【Android性能优化】内存
线程间通信 如何实现多线程安全?synchronized 和 ReentrantLock 的区别? 线程池 见另一篇文章: 【通用开发】Java线程池
安卓设备开机流程 作为应用开发,除了SystemUI和Launcher外,我们更多关注的是应用层的启动流程。对于系统启动稍作了解即可。
【Android进阶】Android设备开机流程
冷启动流程 见另一篇文章: 【Android进阶】APP冷启动流程解析
Handler & 消息处理机制 【Android进阶】Handler消息机制的上下层设计与流程详解
Activity & Window 初始化 在 Android 中,Activity 和 Window 通过一系列紧密的协作关系绑定在一起,共同构成用户界面的基础架构。以下是它们的绑定机制详细分析:
基本关系框架 Activity
└── PhoneWindow (Window的唯一实现)
└── DecorView (顶级View)
└── 内容区域(包含开发者设置的布局)
绑定过程的关键步骤 Activity创建时初始化Window,在Activity的attach()方法中完成初始绑定:
// Activity.java
final void attach ( Context context , ActivityThread aThread ,
Instrumentation instr , IBinder token , int ident ,
Application application , Intent intent , ActivityInfo info ,
...) {
// 创建PhoneWindow实例
mWindow = new PhoneWindow ( this , window );
// 设置Window回调
mWindow . setCallback ( this );
// 设置Window管理器
mWindow . setWindowManager (...);
}
Window的创建时机 在Activity的attach()方法中创建,实际类型是PhoneWindow(Window的唯一实现类),与Activity生命周期绑定,一个Activity对应一个Window。
关键绑定点说明 绑定点 说明 mWindow.setCallback(this) 将Activity设置为Window的回调接口,用于接收Window的各种事件通知 mWindow.setWindowManager() 建立与WindowManager的连接,用于管理Window的显示位置和状态 setContentView() 通过Window将视图层级与Activity关联,开发者设置的布局最终会添加到DecorView中
Activity → Window 的通信 主要通过直接调用Window的方法:
// Activity中调用Window方法的示例
public void setContentView ( int layoutResID ) {
getWindow (). setContentView ( layoutResID );
initWindowDecorActionBar ();
}
//通过Window.Callback接口回调:
// Window.Callback接口主要方法
public interface Callback {
boolean dispatchKeyEvent ( KeyEvent event );
boolean dispatchTouchEvent ( MotionEvent event );
void onContentChanged ();
void onWindowFocusChanged ( boolean hasFocus );
// ...
}
Activity实现了这个接口:
// Activity.java
public class Activity extends ContextThemeWrapper
implements Window . Callback , ... {
// 实现回调方法
public boolean dispatchTouchEvent ( MotionEvent ev ) {
// 处理触摸事件
}
}
视图层级绑定 通过setContentView()建立视图绑定关系:
Activity . setContentView ()
public void setContentView ( int layoutResID ) {
getWindow (). setContentView ( layoutResID );
}
PhoneWindow . setContentView ()
Activity与Window的生命周期关键交互点 onCreate() Window已创建但视图未显示 通常在这里调用setContentView() onStart()/onResume() Window开始变得可见 ViewRootImpl建立连接 onAttachedToWindow() View被附加到Window时回调 可以获取真实的宽高参数 onWindowFocusChanged() Window获得/失去焦点时回调 标志真正的用户交互开始/结束 设计原理分析 这种绑定机制实现了以下设计目标,职责分离:
Activity负责业务逻辑和生命周期 Window负责视图管理和系统交互 布局膨胀(Layout Inflation)流程分析 布局膨胀是将XML布局文件转换为实际的View对象 层次结构的过程。
基本流程概述
布局文件解析:将XML文件转换为可处理的节点结构 View对象创建:根据XML标签创建对应的View实例 属性应用:将XML属性设置到View对象上 层次构建:递归处理子View,构建完整的View树 核心类与组件
LayoutInflater:执行膨胀过程的核心类 XmlPullParser:用于解析XML布局文件 AttributeSet:表示XML属性集合的接口 初始化LayoutInflater
LayoutInflater inflater = LayoutInflater . from ( context );
// 或
LayoutInflater inflater = ( LayoutInflater )
context . getSystemService ( Context . LAYOUT_INFLATER_SERVICE );
inflate()方法调用
public View inflate ( @LayoutRes int resource , @Nullable ViewGroup root ) {
return inflate ( resource , root , root != null );
}
实际膨胀过程
public View inflate ( XmlPullParser parser , ViewGroup root , boolean attachToRoot ) {
synchronized ( mConstructorArgs ) {
// 1. 解析XML
final AttributeSet attrs = Xml . asAttributeSet ( parser );
// 2. 临时存储结果View
View result = root ;
try {
// 3. 查找根节点
int type ;
while (( type = parser . next ()) != XmlPullParser . START_TAG &&
type != XmlPullParser . END_DOCUMENT ) {
// 跳过非开始标签
}
// 4. 获取根元素名称
final String name = parser . getName ();
// 5. 处理特殊标签
if ( TAG_MERGE . equals ( name )) {
// 处理<merge>标签
rInflate ( parser , root , attrs , false );
} else {
// 6. 创建根View
final View temp = createViewFromTag ( root , name , attrs );
// 7. 递归创建子View
rInflateChildren ( parser , temp , attrs );
// 8. 决定是否附加到root
if ( root != null && attachToRoot ) {
root . addView ( temp );
}
result = temp ;
}
} catch ( Exception e ) {
// 异常处理
}
return result ;
}
}
View创建过程(createViewFromTag)
View createViewFromTag ( View parent , String name , AttributeSet attrs ) {
// 1. 处理<blink>等特殊标签(已废弃)
if ( name . equals ( "blink" )) {
// ...
}
// 2. 尝试使用Factory创建View
View view ;
if ( mFactory2 != null ) {
view = mFactory2 . onCreateView ( parent , name , context , attrs );
} else if ( mFactory != null ) {
view = mFactory . onCreateView ( name , context , attrs );
} else {
view = null ;
}
// 3. 没有Factory则使用系统默认方式创建
if ( view == null ) {
try {
// 4. 处理带点号的全限定名
if (- 1 == name . indexOf ( '.' )) {
view = onCreateView ( parent , name , attrs );
} else {
view = createView ( name , null , attrs );
}
} catch ( Exception e ) {
// 异常处理
}
}
return view ;
}
递归膨胀子View(rInflate)
void rInflate ( XmlPullParser parser , View parent , AttributeSet attrs ,
boolean finishInflate ) {
// 1. 获取布局深度
final int depth = parser . getDepth ();
while ((( type = parser . next ()) != XmlPullParser . END_TAG ||
parser . getDepth () > depth ) && type != XmlPullParser . END_DOCUMENT ) {
if ( type != XmlPullParser . START_TAG ) {
continue ;
}
// 2. 获取当前标签名
final String name = parser . getName ();
// 3. 处理特殊标签
if ( TAG_REQUEST_FOCUS . equals ( name )) {
parseRequestFocus ( parser , parent );
} else if ( TAG_TAG . equals ( name )) {
parseViewTag ( parser , parent , attrs );
} else if ( TAG_INCLUDE . equals ( name )) {
// 处理<include>标签
parseInclude ( parser , parent , attrs );
} else if ( TAG_MERGE . equals ( name )) {
throw new InflateException ( "<merge> must be the root element" );
} else {
// 4. 创建普通View
final View view = createViewFromTag ( parent , name , attrs );
final ViewGroup viewGroup = ( ViewGroup ) parent ;
// 5. 递归处理子View
rInflateChildren ( parser , view , attrs );
// 6. 添加到父View
viewGroup . addView ( view );
}
}
}
性能优化相关
使用 AsyncLayoutInflater 进行异步加载(API 24+) 预加载常用布局并缓存 减少布局层级,避免不必要的嵌套 使用 merge 标签减少层级 自定义View问题:
确保实现了所有必要的构造函数 检查自定义属性是否正确定义和引用 理解布局膨胀流程有助于优化布局性能,解决布局相关问题,以及实现高级自定义功能 setContentView流程 setContentView 是 Android 开发中用于设置 Activity 界面布局的核心方法。以下是它的详细工作流程:
基本调用流程 Activity.setContentView(),这是开发者最常调用的入口方法,有多个重载版本:传入布局资源ID、View对象等 委托给 Window 对象,Activity 内部通过 getWindow().setContentView() 委托处理。Window 是抽象类,实际实现是 PhoneWindow PhoneWindow.setContentView(),这是真正的实现核心 PhoneWindow.setContentView() 主要步骤 public void setContentView ( int layoutResID ) {
// 1. 检查是否有DecorView,没有则创建
if ( mContentParent == null ) {
installDecor ();
} else {
// 如果已有内容视图,则移除
mContentParent . removeAllViews ();
}
// 2. 将布局inflate到mContentParent中
mLayoutInflater . inflate ( layoutResID , mContentParent );
// 3. 通知Activity内容已改变
final Callback cb = getCallback ();
if ( cb != null && ! isDestroyed ()) {
cb . onContentChanged ();
}
}
installDecor() 过程 这是创建窗口装饰的关键方法:
private void installDecor () {
if ( mDecor == null ) {
// 1. 创建DecorView
mDecor = generateDecor ();
// 配置DecorView属性
mDecor . setDescendantFocusability ( ViewGroup . FOCUS_AFTER_DESCENDANTS );
mDecor . setIsRootNamespace ( true );
}
if ( mContentParent == null ) {
// 2. 生成mContentParent(实际是ContentView的父容器)
mContentParent = generateLayout ( mDecor );
// 3. 设置其他窗口装饰元素
// 如标题栏、ActionBar等
}
}
generateLayout() 过程 这个方法根据窗口特性选择不同的窗口装饰布局:
根据主题风格选择基础布局(如 R.layout.screen_simple) 将选定的布局inflate到DecorView中 找到内容视图的容器(ID为android.R.id.content的FrameLayout) 返回这个内容容器作为mContentParent 重要注意事项
多次调用setContentView:后续调用会替换之前的内容视图,但DecorView不会重建 主题影响:窗口装饰布局的选择受Activity主题影响 性能考虑:inflate布局是相对耗时的操作,应优化布局文件 时机问题:必须在Activity.onCreate()之后调用,某些窗口特性需要在setContentView之前设置 异步inflate:Android 8.0+支持异步inflate(使用AsyncLayoutInflater) View绘制三部曲 创建Activity时,实际调用了ActivityThread的performLaunchActivity,这时候DecorView会被创建。
在handleResumeActivity时,DecorView会被Activity里的windowManager添加到PhoneWindow窗口中,实际是了ViewRootImpl的setView方法将DecorView传进去。
再之后会走到 ViewRootImpl 的 performTraversals 方法,真正开始ViewTree的工作流程。这个方法非常长,非常重要,这里面主要执行了3个方法,分别是performMeasure、performLayout和performDraw。
Measure 在Measure测量的时候,会用到一个MeasureSpec类,这个类内部的一个32位的int值,其中高2位代表了SpecMode,低30位则代表SpecSize。SpecMode指的是测量模式,SpecSize指的是测量大小 通过位运算来给这个常量的高2位赋值,有三个情况:
00—UNSPECIFIED:未指定模式,View想多大就多大,父容器不做限制,一般用于系统内部的测量。 11—- AT_MOST:最大模式,对应于wrap_comtent属性,子View的最终大小是父View指定的SpecSize值,并且子View的大小不能大于这个值。 01—–EXACTLY:精确模式,对应于 match_parent 属性和具体的数值,父容器测量出 View所需要的大小,也就是SpecSize的值。 每一个普通View都有一个 MeasureSpec 属性来对其进行测量。而对于DecorView来说,它的MeasureSpec由自身的LayoutParams和窗口的尺寸决定。
performMeasure这个方法里,会对一众的子ViewGroup和子View进行测量。
View的onMeasure方法:实际是看 getDefaultSize() 来解析其宽高的,注意对于View基类来说,为了扩展性,它的两个MeasureSpec,AT_MOST和EXACTLY处理是一样的,即其宽高直接取决于所设置的specSize,所以自定义View直接继承于View的情况下,要想实现wrap_content属性,就需要重写onMeasure方法,自己设置一个默认宽高值。
ViewGroup的Measure方法:它没有onMeasure,有一个 measureChildren() 方法:简单来说就是 根据自身的MeasureSpec 和 子元素的的LayoutParams属性 来得出的子元素的MeasureSpec 属性。有一点注意的是如果父容器的 MeasureSpec 属性为AT_MOST,子元素的LayoutParams属性为WRAP_CONTENT,最后计算出的子元素MeasureSpec为AT_MOST,相当于设置matchparent。
每一种ViewGroup的计算方式都不尽相同,像LinearLayout的就是单纯的在其方向上所有子元素的宽/高都加在一起。
Layout ViewGroup中的layout方法用来确定子元素的位置,View中的layout方法则用来确定自身的位置。
所以一般都是ViewGroup来计算子View的参数,并调用子控件的layout方法。
View的layout方法,其中分别传入 left,top,right,bottom 四个参数,表示其距离父布局的四个距离,再走到setFrame,最后到onLayout,这是一个空方法,由继承的类自己实现。
像LinearLayout,其各个子控件会按照顺序排布,childTop值越来越大,子View就会按照顺序排布,而不是叠到一起。
Draw 官方注释清楚地说明了每一步的做法,它们分别是:
(1)如果需要,则绘制背景。
(2)保存当前canvas层。
(3)绘制View的内容。
(4)绘制子View。
(5)如果需要,则绘制View的褪色边缘,这类似于阴影效果。
(6)绘制装饰,比如滚动条。
绘制背景drawBackGround的时候,如果有偏移值,就会在偏移之后的Canvas上绘制。
第三步onDraw和第四步dispatchDraw都是空实现,由子View自定。
像ViewGroup就重写了dispatchDraw方法,遍历子View去绘制,需要注意的是会检索是否有缓存,如果有会直接拿缓存来显示。
热门八股问题 onresume获取不到View的宽高,而View.post就可以拿到:
onCreate和onResume中无法获取View的宽高,是因为还没执行View的绘制流程。 view.post之所以能够拿到宽高,是因为在绘制之前,会将获取宽高的任务放到Handler的消息队列,等到View的绘制结束之后,便会执行。 三种动画 补间动画 核心特性
操作对象:作用于整个 View 动画类型:平移(Translate)、缩放(Scale)、旋转(Rotate)、透明度(Alpha) 资源定义:可通过 XML 或代码定义 视觉限制:只改变绘制位置,不改变实际属性 Animation anim = AnimationUtils . loadAnimation ( this , R . anim . slide_in );
view . startAnimation ( anim );
优缺点分析
简单易用,容易实现 动画效果简单 资源占用低 无法实现复杂的动画 无法精确控制动画效果 只改变绘制位置,不改变实际属性 属性动画 核心特性
操作对象:可作用于任何对象的任意属性 核心类:ValueAnimator、ObjectAnimator、AnimatorSet 高级功能:插值器、估值器、动画组合 真实改变:实际修改目标属性值 // 透明度动画
ObjectAnimator alphaAnim = ObjectAnimator . ofFloat ( view , "alpha" , 0 f , 1 f );
alphaAnim . setDuration ( 1000 );
alphaAnim . start ();
// 组合动画
AnimatorSet set = new AnimatorSet ();
set . playTogether (
ObjectAnimator . ofFloat ( view , "translationX" , 0 f , 100 f ),
ObjectAnimator . ofFloat ( view , "rotation" , 0 f , 360 f )
);
set . setDuration ( 500 ). start ();
优缺点分析
功能强大,可操作任何属性 动画效果更真实 支持复杂的动画组合 实现相对复杂 资源消耗较高 帧动画 帧动画(Frame Animation)是Android中最基础的动画类型之一,它通过快速切换一系列静态图片来产生动画效果,类似于传统电影或GIF动画的工作原理。
核心特性
逐帧播放:按顺序显示一系列图片 资源形式:通常使用多张PNG/JPG图片 实现方式:通过AnimationDrawable类实现 控制方式:可控制播放速度、循环次数等 性能优化建议 图片优化:
使用WebP格式替代PNG可减小体积 确保图片尺寸不过大 使用适当的压缩工具处理图片 避免重复创建AnimationDrawable实例 考虑使用单例模式管理常用动画 根据设备性能调整帧率 在Activity/Fragment不可见时停止动画 @Override
protected void onPause () {
super . onPause ();
if ( animation != null && animation . isRunning ()) {
animation . stop ();
}
}
事件分发 Android 的点击事件分发机制是一个典型的 责任链模式 ,事件从最外层的 ViewGroup 开始,沿着视图层级依次传递,直到被某个 View 消费为止。
事件分发三大核心方法 dispatchTouchEvent(MotionEvent event)onInterceptTouchEvent(MotionEvent event)onTouchEvent(MotionEvent event)完整分发流程 Activity 层级分发
// Activity.dispatchTouchEvent()
public boolean dispatchTouchEvent ( MotionEvent ev ) {
if ( ev . getAction () == MotionEvent . ACTION_DOWN ) {
onUserInteraction (); // 用户交互回调
}
if ( getWindow (). superDispatchTouchEvent ( ev )) {
return true ; // 被Window处理
}
return onTouchEvent ( ev ); // 最后由Activity处理
}
ViewGroup 层级分发,ViewGroup 的分发流程最为复杂: // ViewGroup.dispatchTouchEvent() 简化流程
public boolean dispatchTouchEvent ( MotionEvent ev ) {
// 1. 检查拦截
if ( onInterceptTouchEvent ( ev )) {
return super . dispatchTouchEvent ( ev ); // 转为View的处理流程
}
// 2. 遍历子View寻找能处理事件的View
for ( int i = childrenCount - 1 ; i >= 0 ; i --) {
View child = getChildAt ( i );
if ( child . dispatchTouchEvent ( ev )) {
mFirstTouchTarget = child ; // 记录触摸目标
return true ; // 事件已消费
}
}
// 3. 没有子View处理则自行处理
return super . dispatchTouchEvent ( ev );
}
View 层级处理 // View.dispatchTouchEvent()
public boolean dispatchTouchEvent ( MotionEvent event ) {
// 1. 先检查OnTouchListener
if ( mOnTouchListener != null && mOnTouchListener . onTouch ( this , event )) {
return true ;
}
// 2. 再调用onTouchEvent
return onTouchEvent ( event );
}
事件序列处理机制 一个完整的触摸事件通常包含:
ACTION_DOWN - 手指按下(必须处理) ACTION_MOVE - 手指移动(可能多次) ACTION_UP - 手指抬起 ACTION_CANCEL - 事件被取消 关键规则:
如果 View 不消费 ACTION_DOWN,后续事件不会传递给它 一旦某个 View 开始消费事件,整个事件序列都会交给它 父View可以通过 onInterceptTouchEvent 中途拦截事件 事件分发UML序列图:
[Activity] -> [Window] -> [DecorView] -> [RootViewGroup]
-> [ChildViewGroup] -> [TargetView]
自上而下传递询问是否拦截 自下而上传递询问是否处理 确定目标后直接传递给目标View 详细图解:
常见场景分析 场景1:点击按钮
Activity 收到事件,传递给 Window DecorView 的 ViewGroup 开始分发 遍历子View找到按钮View 按钮的 onTouchEvent 返回 true 消费事件 场景2:滑动冲突
// 解决滑动冲突示例:外部拦截法
@Override
public boolean onInterceptTouchEvent ( MotionEvent ev ) {
boolean intercepted = false ;
switch ( ev . getAction ()) {
case MotionEvent . ACTION_DOWN :
intercepted = false ; // 必须不拦截DOWN
break ;
case MotionEvent . ACTION_MOVE :
if ( 父容器需要当前事件 ) {
intercepted = true ;
} else {
intercepted = false ;
}
break ;
case MotionEvent . ACTION_UP :
intercepted = false ;
break ;
}
return intercepted ;
}
场景3:自定义事件处理
// 自定义View处理双击事件
private GestureDetector mGestureDetector ;
public MyView ( Context context ) {
mGestureDetector = new GestureDetector ( context , new GestureDetector . SimpleOnGestureListener () {
@Override
public boolean onDoubleTap ( MotionEvent e ) {
// 处理双击
return true ;
}
});
}
@Override
public boolean onTouchEvent ( MotionEvent event ) {
return mGestureDetector . onTouchEvent ( event );
}
性能优化建议 减少视图层级 - 层级越深,分发路径越长 避免过度拦截 - 只在必要时使用 onInterceptTouchEvent 使用 TouchDelegate - 扩大小View的点击区域 合理使用 requestDisallowInterceptTouchEvent - 子View阻止父View拦截 多点触控处理 Copy
@Override
public boolean onTouchEvent ( MotionEvent event ) {
int action = event . getActionMasked ();
int pointerIndex = event . getActionIndex ();
int pointerId = event . getPointerId ( pointerIndex );
switch ( action ) {
case MotionEvent . ACTION_POINTER_DOWN :
// 非第一个手指按下
break ;
case MotionEvent . ACTION_POINTER_UP :
// 非最后一个手指抬起
break ;
}
return true ;
}
两列表嵌套滑动 横向和纵向列表,滑动冲突解决。
例如横向列表内部嵌套了一个纵向列表,对外部ReccyclerView的onInterceptTouchEvent方法进行拦截,然后判断内部RecyclerView是否需要拦截,需要则拦截。
public class HorizontalRecyclerView extends RecyclerView {
private float startX , startY ;
public HorizontalRecyclerView ( Context context ) {
super ( context );
}
public HorizontalRecyclerView ( Context context , AttributeSet attrs ) {
super ( context , attrs );
}
@Override
public boolean onInterceptTouchEvent ( MotionEvent e ) {
switch ( e . getAction ()) {
case MotionEvent . ACTION_DOWN :
startX = e . getX ();
startY = e . getY ();
// 必须不拦截DOWN,否则子View无法收到后续事件
return false ;
case MotionEvent . ACTION_MOVE :
float endX = e . getX ();
float endY = e . getY ();
float distanceX = Math . abs ( endX - startX );
float distanceY = Math . abs ( endY - startY );
// 横向滑动距离大于纵向,且角度小于30度时拦截事件
if ( distanceX > distanceY && distanceX > ViewConfiguration . get ( getContext ()). getScaledTouchSlop ()) {
return true ; // 拦截事件,父RecyclerView处理
}
break ;
}
return super . onInterceptTouchEvent ( e );
}
}
AIDL & Binder基础原理 Android中的Binder和AIDL是实现跨进程通信(IPC)的关键机制。
Binder通信原理 架构组成
用户空间:应用程序和服务运行的地方,通过Binder提供的接口进行通信。 内核空间:包含Binder驱动,负责处理进程间的数据传递和同步。 Binder驱动:管理Binder操作的核心组件,处理通信请求,管理内存映射,确保数据正确传递。 工作流程
服务注册:服务端创建Binder对象并注册到ServiceManager,表明可接受请求。 客户端查找服务:客户端通过ServiceManager查询服务,获取服务端Binder代理对象。 建立通信通道:Binder在客户端和服务端之间建立通信通道,通过共享内存区域直接访问数据。 数据传输:客户端调用服务端接口方法,Binder将方法调用和参数打包成数据,通过共享内存传递给服务端,服务端处理后返回结果。 通信细节
基于内存映射:Binder通信基于内存映射(mmap)实现,通过映射内存区域,数据传输只需一次复制,提高性能。 线程池机制:服务端通过Binder线程池处理IPC请求,线程池动态扩展、复用线程,提升并发能力。 AIDL通信原理
定义与作用 AIDL(Android Interface Definition Language)是Android提供的一种用于定义跨进程通信接口的语言。 通过AIDL,可以定义客户端和服务端之间通信的接口和方法,实现跨进程调用。 工作流程
定义AIDL接口:创建AIDL文件,定义接口和方法。 实现AIDL接口:服务端实现AIDL接口,创建Binder对象,并在Service中返回该Binder对象。 客户端绑定服务:客户端通过bindService绑定服务,获取服务端返回的Binder代理对象。 调用接口方法:客户端通过Binder代理对象调用服务端的方法,Binder机制负责底层通信。 关键组件
Stub类:服务端实现的Binder类,继承自AIDL生成的Stub类。 Proxy类:客户端的Binder代理类,用于代理服务端的方法调用。 Parcel:用于封装和传输数据,支持多种数据类型,高效且轻量。 总结
Binder是Android跨进程通信的核心机制,通过内核驱动和内存映射实现高效通信。 AIDL是基于Binder实现的通信接口定义语言,简化了跨进程通信的开发流程,使客户端和服务端能够以面向对象的方式进行通信。 Service 的两种启动方式(startService 和 bindService)区别? BroadcastReceiver 的动态注册和静态注册区别? ContentProvider 的作用?如何实现跨进程数据共享? 插件化原理?如何实现热修复? 如果让你优化一个卡顿的页面,你会从哪些方面入手? 如何保证 App 的稳定性?(Crash 监控、异常捕获) 官方组件 ViewModel & Lifecycle onSaveInstanceState 存储数据原理 onSaveInstanceState 是 Android 中用于临时保存 Activity 或 Fragment 状态的重要机制,主要用于应对系统配置变更(如屏幕旋转)或系统资源回收 等情况。
当 Activity 可能被销毁时(如配置变更或后台回收),系统会调用 onSaveInstanceState(Bundle outState) 开发者可以重写此方法,将需要保存的状态数据存入提供的 Bundle 对象 当 Activity 重新创建时,系统会将保存的 Bundle 传递给 onCreate(Bundle savedInstanceState) 或 onRestoreInstanceState(Bundle savedInstanceState) 内部使用 ArrayMap 实现键值存储,支持基本数据类型、String、Parcelable 和 Serializable 对象,数据会被序列化为字节流 系统使用 Binder 事务缓冲区传输这些数据(大小限制约1MB) 数据临时保存在系统进程中,不是持久化存储,进程终止后数据会丢失 onSaveInstanceState 被调用的频率可能增加 ViewModel 存数据的原理 ViewModel 是 Android Jetpack 架构组件的一部分,它能在配置变更(如屏幕旋转)时保留数据,但在应用进程被完全终止时数据会丢失。
每个 Activity/Fragment 拥有一个 ViewModelStore 实例 ViewModelStore 内部使用 HashMap 存储 ViewModel 实例 配置变更时,ViewModelStore 被保留在内存中 ViewModel 的生命周期比创建它的 Activity/Fragment 更长 当 Activity 因配置变更销毁重建时,ViewModel 不会被清除,当 Activity 真正完成(finish())时,ViewModel 会被清除 底层实现原理 ViewModelProvider 工作机制:
// 获取 ViewModel 的简化流程
ViewModelProvider ( owner ). get ( MyViewModel: : class . java )
// 内部实现关键步骤:
1 . 检查 owner ( Activity / Fragment ) 的 ViewModelStore
2 . 如果不存在对应 ViewModel 实例 , 则通过 Factory 创建新实例
3 . 将新实例存入 ViewModelStore 的 HashMap
配置变更可以保存数据原理 配置变更场景:
当 Activity 因配置变更被销毁时,系统保留了一个特殊的”非配置实例” 这个非配置实例持有 ViewModelStore 新创建的 Activity 实例会获取前一个实例的 ViewModelStore ViewModeProvider 的作用 负责实例化 ViewModel 对象 确保不会重复创建相同的 ViewModel 实例 将 ViewModel 与特定的 Activity/Fragment 生命周期关联 确保 ViewModel 在配置变更时不会被销毁 与 ViewModelStore 协作管理 ViewModel 实例的存储 ViewModel 的工厂模式(ViewModelProvider.Factory)有什么作用 ViewModelProvider.Factory 是 ViewModelProvider 的工厂接口,用于创建 ViewModel 实例。
当 ViewModelProvider 找不到已存在的 ViewModel 实例时,会调用 Factory 的 create 方法创建新实例 可以通过实现 Factory 接口,根据不同的构造参数创建不同的 ViewModel 实例 可以通过依赖注入框架(如 Dagger、Hilt)来提供 Factory 的实现,实现 ViewModel 的依赖注入 可以通过自定义的 ViewModelFactory 来实现不同的 ViewModel 实例创建逻辑,如根据不同的参数创建不同的 ViewModel 实例 Lifecycle 工作机制 Lifecycle 是 Android Jetpack 架构组件的一部分,用于管理 Activity 和 Fragment 的生命周期。
每个 Activity/Fragment 都有一个 LifecycleRegistry 实例 LifecycleRegistry 内部维护了一个 LifecycleOwner 和 Lifecycle 的对应关系 当 Activity/Fragment 生命周期状态改变时,LifecycleRegistry 会通知所有的 LifecycleObserver LifecycleObserver 可以通过注解或手动注册来监听特定的生命周期事件 底层实现原理 LifecycleRegistry 工作机制:
// 生命周期状态变化时的简化流程
1 . 调用 LifecycleRegistry . markState ( Lifecycle . State . CREATED )
2 . 遍历所有 LifecycleObserver , 调用其对应的生命周期方法 ( 如 onStart () )
// 内部实现关键步骤:
1 . 维护一个 LifecycleOwner 和 Lifecycle 的对应关系
2 . 当 LifecycleOwner 生命周期状态改变时 , 遍历所有 LifecycleObserver , 调用其对应的生命周期方法
ViewModel如何感知生命周期 ViewModel 的生命周期感知主要依赖于以下组件协作:
ViewModelStoreOwner:Activity/Fragment 实现的接口,提供 ViewModelStore ViewModelStore:实际存储 ViewModel 实例的容器 LifecycleOwner:Activity/Fragment 提供的生命周期来源 Fragment共享viewmodel Fragment 间共享数据, 实际使用中,可以通过以下方式来实现:
// 多个 Fragment 通过 activity 获取同一个 ViewModel
val sharedViewModel = ViewModelProvider ( requireActivity ()). get ( SharedViewModel :: class . java )
LiveData & Flow 什么是 LiveData?它的主要特点是什么? LiveData 是一种可观察的数据持有者类,具有生命周期感知能力 特点:生命周期感知、自动更新UI、避免内存泄漏、数据始终保持最新状态 LiveData 与 RxJava/Observable 有什么区别? LiveData 是生命周期感知的,专为 Android 设计 RxJava 更强大但更复杂,需要手动管理订阅生命周期 LiveData 自动处理订阅和取消订阅 LiveData 的生命周期感知是如何实现的? 通过 LifecycleOwner 关联组件生命周期 在 STARTED 或 RESUMED 状态时激活观察者 在 DESTROYED 状态时自动移除观察者 LiveData 的观察者模式是如何工作的? 使用 Observer 接口注册观察者 数据变化时通知处于活跃状态的观察者 新观察者注册时会立即收到当前值 LiveData 的 setValue() 和 postValue() 有什么区别? setValue() 必须在主线程调用 postValue() 可以在后台线程调用,内部会切换到主线程 LiveData 如何保证数据不丢失? 新观察者注册时会立即收到最后一次的数据 配置更改时不会丢失数据(与 ViewModel 配合) 如何合并多个 LiveData 源? 使用 MediatorLiveData 可以观察多个 LiveData 源 将多个源添加为 MediatorLiveData 的源 在 Repository 层应该返回 LiveData 吗? 不建议,Repository 应保持框架无关性 建议返回 suspend 函数或 Flow,由 ViewModel 转换为 LiveData LiveData 在 View 和 ViewModel 之间如何分工? ViewModel 暴露 LiveData View(Activity/Fragment) 观察 LiveData 并更新UI 业务逻辑应放在 ViewModel 中 LiveData 与数据绑定(Data Binding)如何配合? 直接在布局文件中绑定 LiveData 需要设置生命周期所有者 binding.lifecycleOwner = this LiveData 与 StateFlow/SharedFlow 如何选择? LiveData 适合 Android UI 层,简单场景 StateFlow/SharedFlow 适合复杂数据流,跨平台逻辑层 LiveData 自动生命周期感知,Flow 需要手动收集 Room Navigation DataStore & SharedPreferences & MMKV SP 通过xml文件存储。 优点:
Android 原生支持,无需额外依赖 简单易用,API 直观 适合存储少量简单数据(键值对) 缺点:
同步API,可能导致主线程阻塞 不支持跨进程 没有类型安全 性能较差,特别是大数据量时 不支持异常处理,可能丢失数据 全量写入,即使只修改一个值也要重写整个文件 DataStore Google推荐的替代SharedPreferences的方案。
异步API(基于Kotlin协程/Flow) 类型安全(通过Protobuf) 更好的错误处理机制 不会阻塞UI线程 支持数据一致性保证 MMKV 腾讯开源的高性能KV存储框架。
基于内存映射,读写速度快 支持多种加密方式 支持多进程 自动增量更新,效率高 支持加密 支持多种数据类型 微信团队开发,经过大规模验证 内存映射技术 内存映射技术是一种将文件内容映射到内存中 的技术。
内存映射允许应用程序直接读写文件内容,而无需通过传统的文件读写操作 内存映射减少了文件读写的系统调用次数,提高了读写效率 内存映射将文件内容映射到内存中,减少了数据的拷贝操作,提高了数据访问速度 Lottie Lottie 通过 Android 的 Canvas API 逐帧绘制矢量图形 利用 View 的硬件加速层(通过 setLayerType(LAYER_TYPE_HARDWARE, null))提升性能 ValueAnimator:核心动画引擎,根据时间插值计算动画进度 JSONObject/JSONArray:解析 After Effects 导出的动画 JSON 文件 对包含位图资源的动画,使用 BitmapFactory 解码 在后台线程(通过 HandlerThread)解析动画 JSON 避免主线程阻塞,通过 Handler 将渲染结果同步到 UI 线程 使用 LruCache 缓存常用动画,避免重复解析 对非活跃动画采用弱引用策略减少内存占用 ViewBinding & DataBinding ViewBinding 是 Android 官方提供的一种类型安全的视图绑定机制,它通过在编译时生成绑定类来替代传统的 findViewById() 方法。
Android Gradle 插件会:
解析布局XML文件:处理所有包含 merge 或根标签的布局文件 生成绑定类:为每个布局文件生成对应的绑定类(如 ActivityMainBinding) 优化代码:移除未使用的绑定引用 运行时工作流程:
调用生成的 inflate() 方法 内部使用 LayoutInflater 加载布局 调用 bind() 方法进行视图绑定 对布局中的每个带有ID的视图执行一次 findViewById() 将找到的视图引用保存在绑定类的字段中 返回绑定类实例 优点:
类型安全:绑定类中包含所有视图的强类型引用 内部有缓存机制,避免重复查找 避免了 findViewById() 的调用,提高了性能 简化了代码编写,减少了错误 缺点:
编译时生成绑定类,可能会增加 APK 大小 对于复杂布局,可能会导致生成的绑定类过于庞大 DataBinding 是 Android 官方提供的数据绑定框架,它允许开发者以声明式方式将布局与数据源绑定,自动同步 UI 和数据变化。
编译过程会执行以下操作:
布局文件预处理,解析所有包含 layout 标签的 XML 文件. 将普通布局转换为 DataBinding 专用格式(添加绑定桥梁) 生成 BR 类(类似 R 类,用于绑定资源) 为每个绑定布局生成对应的绑定类(如 ActivityMainBindingImpl) 生成 ViewDataBinding 的子类 实现观察者模式和绑定逻辑 双向绑定实现:
<EditText android:text= "@={user.name}" />
设置文本变化监听器 数据变化时更新UI UI变化时更新数据源 Gson & Moshi & KotlinX Serialization Proguard Jetpack Compose 三方组件 RecyclerView 用途 大数据集合展示: RecyclerView适用于展示大量数据,通过ViewHolder的复用机制减少内存消耗。 复杂布局: 支持不同的LayoutManager,可以实现线性、网格、瀑布流等多种复杂布局。 滑动性能优化: 通过异步加载和局部刷新等手段,提升滑动的流畅度。 核心组件 Recycler:是构建自定义的布局管理器的核心帮助类,几乎干了所有的获取视图、缓存视图等和回收相关的活动。能让RecyclerView能快速的获取一个新视图来填充数据或者快速丢弃不再需要的视图。 Adapter:是所有数据的来源,负责提供数据并创建ViewHolders以及将数据绑定到ViewHolders上的重要组件,可以视为是recycler对外的工作的对接者 ViewHolder:存取状态信息,在recycler内部也对viewHolder进行了状态信息的存取(是否正在被改变,是否被删除或添加) LayoutManager:决定RecyclerView中Items的排列方式,包含了Item View的获取与回收;当数据集发生变化时,LayoutManager会自动调整子view的位置和大小,以保证RecyclerView的正常显示和性能。 RecyclerView的View缓存机制 ViewHolder模式: RecyclerView使用ViewHolder模式来缓存视图。当ItemView滑出屏幕时,对应的ViewHolder会被缓存,而不是立即销毁。当需要新的ItemView时,可以从缓存中获取ViewHolder,避免频繁的View创建和销毁。 Recycler池: RecyclerView通过Recycler池来管理缓存的ViewHolder。Recycler池中维护了一个可回收的ViewHolder队列,通过这个池来快速获取可重用的ViewHolder。 复用机制: 当新的数据需要显示时,RecyclerView会调用Adapter的onBindViewHolder方法,将新的数据绑定到已存在的ViewHolder上,而不是创建新的View。 Scrap缓存: 在RecyclerView内部还有一个Scrap缓存,用于存储一些没有被完全废弃的ItemViews。这个缓存用于快速重用视图,减少了ViewHolder的创建和初始化时间。 Retrofit + Okhttp Retrofit的设计模式 动态代理机制 核心流程:
public < T > T create ( final Class < T > service ) {
return ( T ) Proxy . newProxyInstance (
service . getClassLoader (),
new Class <?>[] { service },
new InvocationHandler () {
@Override public Object invoke ( Object proxy , Method method , Object [] args ) {
// 将接口方法转换为HTTP请求
return loadServiceMethod ( method ). invoke ( args );
}
});
}
通过Java动态代理技术生成API接口的实现 方法调用时,将注解配置转换为HTTP请求参数 最终通过OkHttp执行实际网络请求 Java的动态代理是一种在运行时动态创建代理类和代理对象的能力。它不需要在编译时就知道具体的代理类,而是通过反射机制在程序运行过程中生成代理类和它的实例。
动态代理的优点
(1)解耦: 将横切关注点(如日志、事务、权限等)从业务逻辑中分离出来,提高了代码的内聚性和可维护性。(2)灵活性: 可以在运行时动态地为对象添加功能,无需修改原有代码。(3)复用性: 相同的代理逻辑可以应用于不同的接口和类。(4)AOP(面向切面编程)的基础: 许多AOP框架(如Spring AOP)底层都使用了动态代理来实现切面功能。
建造者模式 (Builder Pattern) 应用场景:Retrofit 实例的配置和创建
典型实现:
Retrofit retrofit = new Retrofit . Builder ()
. baseUrl ( "https://api.example.com/" )
. addConverterFactory ( GsonConverterFactory . create ())
. addCallAdapterFactory ( RxJava2CallAdapterFactory . create ())
. client ( okHttpClient )
. build ();
优势:
支持链式调用,配置灵活 隔离复杂对象的创建过程 保证构建过程的一致性 适配器模式 (Adapter Pattern) 应用场景:Call 到其他类型的转换
核心组件:
CallAdapter.Factory:适配器工厂基类
RxJavaCallAdapterFactory:将 Call 适配为 RxJava 的 Observable
CoroutineCallAdapterFactory:将 Call 适配为 Kotlin 协程的 suspend 函数
工作流程:
OkHttpCall --> CallAdapter.adapt() --> Observable/SuspendFunction/其他类型
工厂方法模式 (Factory Method Pattern) 应用场景:Converter 和 CallAdapter 的创建
实现示例:
public interface Converter . Factory {
// 根据类型创建转换器
Converter < ResponseBody , ?> responseBodyConverter (
Type type , Annotation [] annotations , Retrofit retrofit );
// 根据类型创建请求体转换器
Converter <?, RequestBody > requestBodyConverter (
Type type , Annotation [] annotations , Retrofit retrofit );
}
派生工厂:
GsonConverterFactory
MoshiConverterFactory
ScalarsConverterFactory
装饰者模式 (Decorator Pattern) 应用场景:OkHttpCall 的封装
实现方式:
final class OkHttpCall < T > implements Call < T > {
private final ServiceMethod < T , ?> serviceMethod ;
private final @Nullable Object [] args ;
// 装饰原始的OkHttp Call
private @Nullable okhttp3 . Call rawCall ;
}
作用:
在不改变原有 Call 接口的情况下增强功能 添加了缓存、线程切换等附加功能 策略模式 (Strategy Pattern) 应用场景:HTTP 请求方法的处理
实现体现:
每个 HTTP 注解(@GET/@POST 等)对应不同的请求策略 RequestBuilder 根据注解选择不同的参数处理方式 示例:
void parseMethodAnnotation ( Annotation annotation ) {
if ( annotation instanceof GET ) {
parseHttpMethodAndPath ( "GET" , (( GET ) annotation ). value ());
} else if ( annotation instanceof POST ) {
parseHttpMethodAndPath ( "POST" , (( POST ) annotation ). value ());
}
// 其他HTTP方法...
}
观察者模式 (Observer Pattern) 应用场景:通过 Callback 处理异步响应
典型实现:
call . enqueue ( new Callback < User >() {
@Override public void onResponse ( Call < User > call , Response < User > response ) {
// 成功回调
}
@Override public void onFailure ( Call < User > call , Throwable t ) {
// 失败回调
}
});
责任链模式 (Chain of Responsibility) 应用场景:OkHttp 的拦截器体系
Retrofit 中的集成:
OkHttpClient client = new OkHttpClient . Builder ()
. addInterceptor ( new LoggingInterceptor ())
. addNetworkInterceptor ( new StethoInterceptor ())
. build ();
处理流程:
请求 → 拦截器1 → 拦截器2 → ... → 拦截器N → 服务器
响应 ← 拦截器N ← ... ← 拦截器2 ← 拦截器1 ←
设计模式综合应用示例
// 建造者模式创建Retrofit实例
Retrofit retrofit = new Retrofit . Builder ()
. baseUrl ( BASE_URL )
. client ( new OkHttpClient . Builder () // 装饰者模式增强OkHttpClient
. addInterceptor ( new HttpLoggingInterceptor ()) // 责任链模式
. build ())
. addConverterFactory ( new GsonConverterFactory ()) // 工厂方法模式
. build ();
// 动态代理模式创建API实例
GitHubService service = retrofit . create ( GitHubService . class );
// 适配器模式将Call转换为RxJava Observable
Observable < List < Repo >> observable = service . listRepos ( "user" );
// 观察者模式处理响应
observable . subscribe ( new Observer < List < Repo >>() {
@Override public void onSubscribe ( Disposable d ) {}
@Override public void onNext ( List < Repo > repos ) {
// 处理数据
}
@Override public void onError ( Throwable e ) {
// 错误处理
}
});
Retrofit 通过精心组合这些经典设计模式,实现了简单易用与强大功能之间的完美平衡,成为 Android 网络请求的事实标准。理解这些设计模式有助于开发者更好地使用和扩展 Retrofit。
OKhttp的优势 拦截器机制: OkHttp通过拦截器链来处理请求和响应。每个拦截器可以在请求或响应被处理前或后进行自定义操作。 连接池: OkHttp使用连接池来管理HTTP连接,减少了创建和销毁连接的开销。 缓存机制: OkHttp支持缓存机制,通过缓存策略来控制是否使用缓存。 异步请求: OkHttp支持异步请求,通过回调或协程来处理请求结果。 支持HTTPS: OkHttp支持HTTPS协议,通过SSL/TLS加密来保护数据安全。 支持GZIP压缩: OkHttp支持GZIP压缩,通过压缩请求和响应数据来减少网络传输的数据量。 HTTP 和 HTTPS 的区别?HTTPS 的加密流程? Ktor Ktor 是 JetBrains 推出的异步网络框架,支持全栈开发(客户端+服务端),基于 Kotlin 协程设计,100% Kotlin 原生支持 。而且随着KMP技术发展,Ktor也已经支持跨平台网络请求。
核心特性:
协程优先:所有API设计为挂起函数 轻量级:模块化设计,按需引入组件 多平台支持:Android、iOS、JVM、JavaScript、Native 插件化架构:通过安装(install)功能扩展能力 和Retrofit对比
协程支持:Ktor 支持 Kotlin 协程,简化异步编程 功能丰富:Ktor 提供了更多的功能,如文件上传、WebSocket、服务器端渲染等 跨平台支持:Ktor 支持跨平台开发,如 Android、iOS、JVM、JavaScript、Native 社区活跃:Ktor 社区活跃,有丰富的文档和示例 CIO引擎 对比OkHttp:
特性 CIO 引擎 OkHttp 引擎 实现语言 100% Kotlin Java + Kotlin 线程模型 协程事件循环 线程池 + NIO 内存占用 更低 (~1/3 of OkHttp) 较高 HTTP/2支持 需要手动启用 默认支持 WebSocket 基础支持 更成熟实现 平台支持 全平台 (包括Native) 仅JVM/Android DNS解析 纯Kotlin实现 依赖系统实现
Hilt & Dagger & Koin 依赖导入 依赖注入 依赖注入是一种设计模式,用于将对象的依赖从内部移到外部进行管理。它的主要好处包括:
解耦代码:通过接口或抽象类注入依赖,降低模块之间的耦合度。 提升测试性:可以使用 Mock 对象注入,方便单元测试。 易于维护:通过集中管理依赖关系,减少手动创建对象的复杂性。
三者简介 Dagger是一个用于管理依赖注入的框架,它通过编译时生成代码来实现依赖注入。 Hilt是一个用于简化Android依赖注入的框架,它基于Dagger,并提供了一些额外的功能,如简化依赖注入的配置。 Koin是一个轻量级的依赖注入框架,它支持Kotlin语言,并提供了一些额外的功能,如简化依赖注入的配置。 写法举例 Dagger
@Module
class NetworkModule {
@Provides
fun provideOkHttp (): OkHttpClient = OkHttpClient . Builder (). build ()
}
@Component ( modules = [ NetworkModule :: class ])
interface AppComponent {
fun inject ( activity : MainActivity )
}
// 在Application中初始化
class MyApp : Application () {
val appComponent = DaggerAppComponent . create ()
}
Hilt
@InstallIn(SingletonComponent::class)
object NetworkModule {
@Provides
@Singleton
fun provideOkHttp(): OkHttpClient = OkHttpClient.Builder().build()
}
@AndroidEntryPoint
class MainActivity : AppCompatActivity() {
@Inject lateinit var okHttpClient: OkHttpClient
}
// Application类需添加注解
@HiltAndroidApp
class MyApp : Application()
Koin
val appModule = module {
single { OkHttpClient . Builder (). build () }
}
class MyApp : Application () {
override fun onCreate () {
super . onCreate ()
startKoin {
androidContext ( this @MyApp )
modules ( appModule )
}
}
}
class MainActivity : AppCompatActivity () {
private val okHttpClient : OkHttpClient by inject ()
}
对比表格 概念 Dagger 2 Hilt Koin 工作原理 编译时代码生成 基于Dagger的预配置Android方案 运行时依赖解析 配置方式 手动创建Component/Module 注解驱动+预定义Android组件 DSL声明式配置 编译时间影响 显著(需kapt处理) 显著(继承自Dagger) 无 运行时性能 最佳(编译期解决依赖) 同Dagger 轻微开销(运行时解析)
Glide & Coil RxJava EventBus LeakCanary LeakCanary 是 Square 公司开发的一款 Android 内存泄漏检测工具,它能够自动检测应用中的内存泄漏并生成详细的泄漏轨迹报告。
LeakCanary 基于 Java 的 WeakReference(弱引用) 和 ReferenceQueue(引用队列) 机制 工作原理流程图:
graph TD
A[监控对象] --> B[创建KeyedWeakReference]
B --> C[添加到引用队列]
D[触发GC] --> E[检查引用队列]
E -->|对象仍在队列外| F[判定为泄漏]
E -->|对象进入队列| G[判定为已回收]
LeakCanary 默认监控以下Android组件:
销毁的Activity 销毁的Fragment 销毁的View 销毁的ViewModel 泄漏检测触发时机 Activity/Fragment销毁时:通过注册 Application.ActivityLifecycleCallbacks View/ViewModel销毁时:通过各自的销毁回调 手动监控:AppWatcher.objectWatcher.watch(myObject) 泄漏分析过程 当检测到可能的内存泄漏时,调用 Debug.dumpHprofData() 生成堆转储文件 使用 Shark 解析器分析堆转储(替代旧版HAHA) 查找泄漏对象的引用链 识别最短强引用路径(从GC Roots到泄漏对象) 排除系统类引用(过滤噪声) 核心优化技术 性能优化措施延迟检测:默认5秒后执行检测(等待主线程空闲) 采样分析:在Debug版本中全量分析,Release版本抽样 后台线程:所有分析操作在独立线程执行 准确性保障多次GC验证:确保对象真的无法被回收 引用链验证:确认泄漏路径的有效性 排除软/弱引用:只关注强引用泄漏 常见泄漏场景处理:
单例持有Context:改用Application Context Handler内存泄漏:使用静态Handler+WeakReference 匿名内部类持有:改为静态内部类 LeakCanary 通过巧妙的弱引用监控和堆转储分析技术,为Android开发者提供了简单高效的内存泄漏检测方案,极大提升了内存问题排查效率。
Kotlin lateinit 和 by lazy 的区别 lateinit(延迟初始化)
用于可变的 var 属性 必须显式初始化后才能访问 不能用于基本数据类型(Int, Boolean等) 编译时不检查初始化状态,运行时检查 by lazy(延迟加载)
用于不可变的 val 属性 首次访问时自动初始化 可以配置属性,自定义初始化逻辑 可以用于基本数据类型 实现原理 lateinit
编译时生成额外代码 获取时,自动检查初始化状态 生成一个访问器方法,用于获取属性 by lazy
使用委托模式 内部维护初始化状态和值 首次访问时,生成一个访问器方法 该方法内部使用 synchronized 确保线程安全 可以配置为非线程安全模式,提升速度 协程 见更全面的总结文章: Kotlin协程浅谈
apply & with & let & run Kotlin 提供了几个强大的作用域函数(scope functions),它们都用于在对象的上下文中执行代码块,但在使用方式和场景上有所不同。
函数 上下文对象引用 返回值 是否扩展函数 典型使用场景 let it Lambda 结果 是 非空对象处理、链式操作 run this Lambda 结果 是 对象配置、计算返回值 with this Lambda 结果 否 对象分组操作 apply this 对象本身 是 对象初始化 also it 对象本身 是 附加效果、日志记录
let // 安全调用非空对象
val length = nullableString ?. let {
println ( "Processing: $it" )
it . length // 返回值
} ?: 0
// 链式操作
user ?. let { it . copy ( name = "NewName" ) } ?. let ( :: print )
通过 it 引用对象 返回 lambda 表达式结果 常用于空安全检查 run val result = service . run {
port = 8080 // 直接访问属性
query () // 直接调用方法
// 最后一行作为返回值
}
// 替代构造器模式
val rectangle = Rectangle (). run {
width = 10
height = 20
area () // 返回面积
}
通过 this 引用对象(可省略) 返回 lambda 表达式结果 适合对象转换和计算 with val output = with ( StringBuilder ()) {
append ( "Hello" )
append ( " " )
append ( "World" )
toString () // 返回结果
}
非扩展函数 通过 this 引用对象 返回 lambda 表达式结果 适合对同一对象进行多次操作 apply val myView = TextView ( context ). apply {
text = "Hello"
textSize = 16f
setPadding ( 10 , 0 , 10 , 0 )
// 返回TextView对象本身
}
// 替代Builder模式
val intent = Intent (). apply {
action = "ACTION_VIEW"
data = Uri . parse ( "https://kotlinlang.org" )
}
通过 this 引用对象 返回对象本身 主要用于对象初始化 also val numbers = mutableListOf ( 1 , 2 , 3 ). also {
println ( "Before adding: $it" )
it . add ( 4 )
}. also {
println ( "After adding: $it" )
}
数据类 Kotlin编译时移动生成了hashcode equals toString copy等方法。
底层实现:编译器生成的数据类大致如下:
public final class User {
private final String name ;
private final int age ;
public User ( String name , int age ) {
this . name = name ;
this . age = age ;
}
@Override
public boolean equals ( Object o ) {
if ( this == o ) return true ;
if ( o == null || getClass () != o . getClass ()) return false ;
User user = ( User ) o ;
return age == user . age && name . equals ( user . name );
}
@Override
public int hashCode () {
return Objects . hash ( name , age );
}
@Override
public String toString () {
return "User{name='" + name + "', age=" + age + "}" ;
}
public User copy ( String name , int age ) {
return new User ( name , age );
}
public String component1 () {
return name ;
}
public int component2 () {
return age ;
}
}
附加功能:数据类支持解构声明,可以将对象的属性直接解构到多个变量中。 扩展函数原理 Kotlin 允许你为现有类添加新功能,而不需要继承这个类或使用装饰者模式。通过扩展函数,你可以直接在类外部为它添加新方法。 示例:
fun String . hello () = "Hello, $this"
println ( "World" . hello ()) // 输出: Hello, World
解析:
简化的语法:扩展函数可以让你对现有类添加自定义功能,而无需修改类的定义。比如上例中的hello()函数,并不是String类的内置方法,但你可以像调用内置方法一样使用它。 底层实现:扩展函数在编译时被转换为静态方法,类的实例作为第一个参数传递。 public static String hello ( String receiver ) {
return "Hello, " + receiver ;
}
Lambda 简化的语法:Lambda 表达式是一种简洁的函数表示形式,可以用更少的代码来表达相同的逻辑。它在 Kotlin 中被广泛用于集合操作、异步编程等场景。 底层实现:Lambda 表达式在编译时被转换为匿名函数类的实例。Kotlin 提供了一组函数接口,如 Function1、Function2,分别表示接受 1 个参数、2 个参数的函数。Function2 < Integer , Integer , Integer > sum = new Function2 < Integer , Integer , Integer >() {
@Override
public Integer invoke ( Integer a , Integer b ) {
return a + b ;
}
};
int result = sum . invoke ( 1 , 2 );
捕获变量:如果 Lambda 表达式在定义时捕获了外部变量,那么编译器会生成一个闭包类来封装这些变量。 When关键字 简化的语法:when 表达式比传统的 switch 语句更强大,它不仅可以匹配值,还可以匹配条件,甚至使用复杂的表达式。此外,它也可以返回一个结果。 底层实现:编译器会将 when 表达式转换为一系列条件检查(if-else 语句),或者在可能的情况下转换为 Java 字节码中的 switch 语句。 val result = when ( x ) {
1 -> "One"
2 -> "Two"
else -> "Unknown"
}
String result ;
if ( x == 1 ) {
result = "One" ;
} else if ( x == 2 ) {
result = "Two" ;
} else {
result = "Unknown" ;
}
?空安全 转换成Java实际就是一个null检查,如何配合?:操作符,就是三目运算符后面赋一个默认值
委托 在 Kotlin 中,委托(Delegation) 是一种强大的设计模式,它允许对象将部分功能委托给另一个辅助对象来实现。Kotlin 原生支持多种委托方式,主要分为以下几种:
类委托(Class Delegation) 通过 by 关键字,将类的接口实现委托给另一个对象,常用于 “装饰器模式” 或 “代理模式”。 示例:委托接口实现
interface Printer {
fun print ( message : String )
}
class DefaultPrinter : Printer {
override fun print ( message : String ) {
println ( "Default Printer: $message" )
}
}
// 委托给 printer 对象
class CustomPrinter ( private val printer : Printer ) : Printer by printer {
// 可以覆盖部分方法
override fun print ( message : String ) {
println ( "Before Printing..." )
printer . print ( message ) // 调用委托对象的方法
println ( "After Printing..." )
}
}
fun main () {
val defaultPrinter = DefaultPrinter ()
val customPrinter = CustomPrinter ( defaultPrinter )
customPrinter . print ( "Hello, Kotlin!" )
}
输出: Before Printing… Default Printer: Hello, Kotlin! After Printing…
适用场景:
增强或修改现有类的行为(如日志、缓存、权限控制)。 避免继承,使用组合代替。 属性委托(Property Delegation) Kotlin 提供标准库委托(如 lazy、observable),也可以自定义委托。 (1) lazy 延迟初始化
val lazyValue : String by lazy {
println ( "Computed only once!" )
"Hello"
}
fun main () {
println ( lazyValue ) // 第一次访问时计算
println ( lazyValue ) // 直接返回缓存值
}
输出: Computed only once! Hello Hello
(2) observable 监听属性变化
import kotlin.properties.Delegates
var observedValue : Int by Delegates . observable ( 0 ) { _ , old , new ->
println ( "Value changed from $old to $new" )
}
fun main () {
observedValue = 10 // 触发回调
observedValue = 20 // 再次触发
}
输出: Value changed from 0 to 10 Value changed from 10 to 20
(3) vetoable 可拦截修改
var positiveNumber : Int by Delegates . vetoable ( 0 ) { _ , old , new ->
new > 0 // 只有 new > 0 时才允许修改
}
fun main () {
positiveNumber = 10 // 允许
println ( positiveNumber ) // 10
positiveNumber = - 5 // 拒绝修改
println ( positiveNumber ) // 仍然是 10
}
(4) 自定义属性委托
class StringDelegate ( private var initValue : String ) {
operator fun getValue ( thisRef : Any ?, property : KProperty < * >): String {
println ( "Getting value: $initValue" )
return initValue
}
operator fun setValue ( thisRef : Any ?, property : KProperty < * >, value : String ) {
println ( "Setting value: $value" )
initValue = value
}
}
fun main () {
var text by StringDelegate ( "Default" )
println ( text ) // 调用 getValue
text = "New Value" // 调用 setValue
}
输出: Getting value: Default Default Setting value: New Value
字符串连接 编译后实际还是java的➕拼接
Object关键字 声明单例类、伴生对象(Companion Object)以及匿名对象。
object Singleton {
val name = "Kotlin Singleton"
}
class MyClass {
companion object {
val instance = MyClass ()
}
}
作用为单例类 生成静态内部实例,私有构造器,确保单例
public final class Singleton {
public static final Singleton INSTANCE = new Singleton ();
private Singleton () {
// private constructor
}
public String getName () {
return "Kotlin Singleton" ;
}
}
Pagination © 2024. All rights reserved. LICENSE | NOTICE | CHANGELOG
Powered by Hydejack v9.2.1