#include<iostream>
#include<bitset>usingnamespacestd;intmain(){bitset<8>b1(1);// 00000001b1<<=2;// 左移两位,变为 00000100cout<<"b1 after left shift by 2: "<<b1<<endl;return0;}
取反:
#include<iostream>
#include<bitset>usingnamespacestd;intmain(){bitset<8>b1(5);// 00000101cout<<"b1: "<<b1<<endl;cout<<"b1 after NOT: "<<~b1<<endl;// 11111010return0;}
SomeClass*ptrData=anObject.GetData();/*
Questions: Is object pointed by ptrData dynamically allocated using new?
If so, who calls delete? Caller or the called?
Answer: No idea!
*/ptrData->DoSomething();
在上述代码中,没有显而易见的方法获悉 ptrData 指向的内存:
是否是从堆中分配的,因此最终需要释放;
是否由调用者负责释放;
对象的析构函数是否会自动销毁该对象。
优势
智能指针可以自动管理动态分配的内存,避免内存泄漏和悬空指针等问题。
smart_pointer<SomeClass>spData=anObject.GetData();// Use a smart pointer like a conventional pointer!spData->Display();(*spData).Display();// Don't have to worry about de-allocation// (the smart pointer's destructor does it for you)
voidMakeFishSwim(FishaFish){aFish.swim();}...Carpcarp1;MakeFishSwim(carp1);// Slicing: only the Fish part of Carp is sent to MakeFishSwim() Tunatuna1;MakeFishSwim(tuna1);
destructive_copy_smartptr<SampleClass>smartPtr(newSampleClass());SomeFunc(smartPtr);// Ownership transferred to SomeFunc// Don't use smartPtr in the caller any more!
setiosflags 是 C++ <iomanip> 头文件中的一个函数,主要用于设置输出流的格式标志。这些格式标志决定了数据在输出时的显示方式,比如对齐方式、数字基数、是否显示正负号等。
对上面的代码进一步使用 setiosflags 函数,打印大写十六进制字母。
#include<iostream>
#include<iomanip>usingnamespacestd;intmain(){intnum=255;cout<<"Integer in hex using base notation: ";cout<<setiosflags(ios_base::hex|ios_base::showbase|ios_base::uppercase);cout<<"Hexadecimal: "<<num<<endl;return0;}
#include<iostream>usingnamespacestd;intmain(){intnum;cout<<"Enter an integer: ";cin>>num;cout<<"You entered: "<<num<<endl;doublepi;cout<<"Enter the value of Pi: ";cin>>pi;cout<<"You entered: "<<pi<<endl;charch1,ch2,ch3;cout<<"Enter three characters separated by spaces: ";cin>>ch1>>ch2>>ch3;cout<<"You entered: "<<ch1<<ch2<<ch3<<endl;return0;}
使用cin::get安全地读取字符
cin 让您能够将输入直接写入 int 变量,也可将输入直接写入 char 数组(C 风格字符串):
cout<<"Enter a line: "<<endl;charcharBuf[10]={0};// can contain max 10 charscin>>charBuf;// Danger: user may enter more than 10 chars
写入 C 风格字符串缓冲区时,务必不要超越缓冲区的边界,以免导致程序崩溃或带来安全隐患,这至关重要。因此,将输入读取到 char 数组(C 风格字符串)时,下面是一种更好的方法:
cout<<"Enter a line: "<<endl;charcharBuf[10]={0};cin.get(charBuf,9);// stop inserting at the 9th character
fstreammyFile;myFile.open("HelloFile.txt",ios_base::in|ios_base::out|ios_base::trunc);if(myFile.is_open())// check if open() succeeded{// do reading or writing heremyFile.close();}
#include<fstream>
#include<iostream>
#include<sstream>
#include<string>usingnamespacestd;intmain(){cout<<"Enter an integer: "<<endl;intinput=0;cin>>input;stringstreamconverterStream;converterStream<<input;stringinputStr;converterStream>>inputStr;cout<<"You entered: "<<inputStr<<endl;stringstreamanotherStream;anotherStream<<inputStr;intanotherInput=0;anotherStream>>anotherInput;cout<<"The integer value is: "<<anotherInput<<endl;return0;}
voidSomeFunc(){try{int*numPtr=newint;*numPtr=999;deletenumPtr;}catch(...)// ... catches all exceptions{cout<<"Exception in SomeFunc(), quitting"<<endl;}}
使用举例,用户输入为 -1 个整数预留空间:
#include<iostream>usingnamespacestd;intmain(){try{cout<<"Enter the size of the array: "<<endl;intsize=0;cin>>size;int*numPtr=newint[size];cout<<"the array size is: "<<size<<endl;}catch(...){cout<<"Exception in main(), quitting"<<endl;}return0;}
使用 catch(...) 可以捕获所有异常。在这个场景下,也可以指定 const std::bad_alloc& e 来专门捕获因为 new 失败引发的异常。
也可以先指定 const std::bad_alloc& e 来捕获异常,然后再使用 catch(...) 来捕获其他异常。确保万无一失。
#include<iostream>usingnamespacestd;intmain(){try{cout<<"Enter the size of the array: "<<endl;intsize=0;cin>>size;int*numPtr=newint[size];cout<<"the array size is: "<<size<<endl;}catch(std::bad_alloc&exp){cout<<"Exception encountered: "<<exp.what()<<endl;cout<<"Got to end, sorry!"<<endl;}catch(...){cout<<"Exception in main(), quitting"<<endl;}return0;}
输出:
Enter the size of the array:
-1
Exception encountered: std::bad_array_new_length
Got to end, sorry!
#include<iostream>usingnamespacestd;structStructA{StructA(){cout<<"StructA constructor"<<endl;}~StructA(){cout<<"StructA destructor"<<endl;}};structStructB{StructB(){cout<<"StructB constructor"<<endl;}~StructB(){cout<<"StructB destructor"<<endl;}};voidFunctionTwo(){StructAa;StructBb;cout<<"About to Throw an Exception"<<endl;throw"Exception in FunctionTwo()";}voidFunctionOne(){try{StructAa;StructBb;FunctionTwo();}catch(constchar*exp){cout<<"Exception encountered: "<<exp<<endl;cout<<"Exception Handled in FunctionOne(), not gonna pass to Caller"<<endl;}}intmain(){cout<<"About to call FunctionOne()"<<endl;try{FunctionOne();}catch(constchar*exp){cout<<"Exception encountered: "<<exp<<endl;}cout<<"Everything alright! About to exit main()"<<endl;return0;}
std::stringstr1="Hello, ";std::stringstr2="World!";std::stringstr3=str1+str2;// str3 now holds "Hello, World!"
std::stringstr1="Hello, ";std::stringstr2="World!";str1.append(str2);// str1 now holds "Hello, World!"
string中字符和子字符串的查找
可以使用find方法来查找字符或子字符串。
std::stringstr="Hello, World!";size_tpos=str.find("World");// pos now holds 7if(pos!=std::string::npos){std::cout<<"Found at position: "<<pos<<std::endl;}else{std::cout<<"Not found"<<std::endl;}
#include<iostream>
#include<vector>
#include<deque>usingnamespacestd;intmain(){vector<int>myVector={1,2,3,4,5};deque<int>myDeque={10,20,30,40,50};// 清空vectormyVector.clear();if(myVector.empty()){cout<<"Vector is empty."<<endl;}else{cout<<"Vector is not empty."<<endl;}// 清空dequemyDeque.clear();if(myDeque.empty()){cout<<"Deque is empty."<<endl;}else{cout<<"Deque is not empty."<<endl;}return0;}
要实例化模板 list,需要指定要在其中存储的对象类型,因此实例化 list 的语法类似于下面这样:
std::list<int>linkInts;// list containing integersstd::list<float>listFloats;// list containing floatsstd::list<Tuna>listTunas;// list containing objects of type Tuna
#include<iostream>
#include<list>usingnamespacestd;boolSortPredicate_Descending(constint&a,constint&b){returna>b;// 降序排序}intmain(){list<int>myList={40,10,30,20,50};// 默认升序排序myList.sort();cout<<"Sorted in ascending order: ";for(constauto&elem:myList){cout<<elem<<" ";}cout<<endl;// 降序排序myList.sort(SortPredicate_Descending);cout<<"Sorted in descending order: ";for(constauto&elem:myList){cout<<elem<<" ";}cout<<endl;return0;}
定义了函数 SortPredicate_Descending ,它是一个二元谓词,帮助 list 的 sort() 函数判断一个元素是否比另一个元素小。如果不是,则交换这两个元素的位置。换句话说,您告诉了 list 如何解释小于,就这里而言,小于的含义是第一个参数大于第二个参数。这个谓词仅在第一个值比第二个值大时返回 true。也就是说,使用该谓词时,仅当第一个元素(lsh)的数字值比第二个元素(rsh)大时,sort()才认为第一个元素比第二个元素小。基于这种解释,sort()交换元素的位置,以满足谓词指定的标准。
set 是 C++ 标准库中的一个关联容器,用于存储唯一的元素,自动排序。它基于红黑树实现,提供了快速的插入、删除和查找操作。
multiset 是 set 的一个变体,允许存储重复的元素。
set 的常用方法包括:
insert():插入元素。
erase():删除元素。
find():查找元素。
size():返回元素数量。
empty():检查是否为空。
clear():清空容器。
multiset 的常用方法与 set 类似,只是允许存储重复元素。
为了实现快速搜索,STL set 和 multiset 的内部结构像二叉树,这意味着将元素插入到 set 或 multiset时将对其进行排序,以提高查找速度。这还意味着不像 vector 那样可以使用其他元素替换给定位置的元素,位于 set 中特定位置的元素不能替换为值不同的新元素,这是因为 set 将把新元素同内部树中的其他元素进行比较,进而将其放在其他位置。
// used as a template parameter in set / multiset instantiationtemplate<typenameT>structSortDescending{booloperator()(constT&lhs,constT&rhs)const{return(lhs>rhs);}};
然后,在实例化 set 或 multiset 时指定该谓词,如下所示:
// a set and multiset of integers (using sort predicate)set<int,SortDescending<int>>setInts;multiset<int,SortDescending<int>>msetInts;
#include<iostream>
#include<set>usingnamespacestd;intmain(){multiset<int>myMultiset={1,2,2,2,3,4,5};// 计算元素3的数量intcount=myMultiset.count(2);cout<<"Count of 2 in set: "<<count<<endl;// 输出 3// 尝试计算一个不存在的元素count=myMultiset.count(6);cout<<"Count of 6 in set: "<<count<<endl;// 输出 0return0;}
autoelementFound=setInts.find(-1);// Check if found...if(elementFound!=setInts.end())cout<<"Element "<<*elementFound<<" found!"<<endl;elsecout<<"Element not found in set!"<<endl;
#include<iostream>
#include<set>
#include<string>usingnamespacestd;template<typenameT>voidDisplayContents(constT&container){for(autoelement=container.cbegin();element!=container.cend();element++){cout<<*element<<" ";}cout<<endl;}structContactItem{stringname;stringphone;stringdisplayAs;ContactItem(stringn,stringp):name(n),phone(p){displayAs=name+"("+phone+")";}booloperator<(constContactItem&other)const{returnname<other.name;}booloperator==(constContactItem&other)const{returnname==other.name;}// Used in DisplayContents via coutoperatorconstchar*()const{returndisplayAs.c_str();}};intmain(){set<ContactItem>setContacts;setContacts.insert(ContactItem("张三","123456"));setContacts.insert(ContactItem("李四","654321"));setContacts.insert(ContactItem("王五","112233"));DisplayContents(setContacts);cout<<"Enter a name you wish to delete: ";stringnameToDelete;getline(cin,nameToDelete);autocontactFound=setContacts.find(ContactItem(nameToDelete,""));if(contactFound!=setContacts.end()){setContacts.erase(contactFound);cout<<"Contact deleted."<<endl;}else{cout<<"Contact not found."<<endl;}DisplayContents(setContacts);return0;}
// A unary functiontemplate<typenameelementType>voidFuncDisplayElement(constelementType&element){cout<<element<<' ';};
该函数也可采用另一种表现形式,即其实现 包含在类或结构的operator() 中:
// Struct that can behave as a unary functiontemplate<typenameelementType>structDisplayElement{voidoperator()(constelementType&element)const{cout<<element<<' ';}};
// struct that behaves as a unary functiontemplate<typenameelementType>structDisplayElement{voidoperator()(constelementType&element)const{cout<<element<<' ';}};
#include<iostream>intmain(){intx=10;automy_lambda=[x](){// x 的值是 10std::cout<<"The value of x is: "<<x<<std::endl;};x=20;// 改变外部的 xmy_lambda();// 输出依然是 10return0;}
按值捕获所有变量:[=]
捕获 其所在作用域中 所有被 lambda 内部使用的局部变量。
同样是值复制,不会随外部变量变化。
#include<iostream>intmain(){inta=1,b=2;automy_lambda=[=](){// a 和 b 的值在 lambda 创建时被复制std::cout<<"The value of a is: "<<a<<std::endl;std::cout<<"The value of b is: "<<b<<std::endl;};a=3;// 改变外部的 amy_lambda();// 输出依然是 1 和 2return0;}
3. 按引用捕获 [&var] 或 [&]
按引用捕获单个变量:[&x]
x 的引用被传递到 lambda 内部。
这意味着 lambda 内部对 x 的任何修改都会影响到外部的 x。
当外部 x 的值改变时,lambda 内部也能看到最新的值。
#include<iostream>intmain(){intx=10;automy_lambda=[&x](){// 访问的是外部的 xx+=5;// 修改了外部的 xstd::cout<<"The value of x inside lambda is: "<<x<<std::endl;};my_lambda();// x 变为 15std::cout<<"The value of x outside lambda is: "<<x<<std::endl;// 输出 15return0;}
#include<iostream>intmain(){inta=1,b=2;// 默认按值捕获,但 b 按引用捕获automy_lambda=[=,&b](){// a 是值捕获,不能修改std::cout<<"The value of a is: "<<a<<std::endl;// b 是引用捕获,可以修改b=3;};my_lambda();std::cout<<"The value of b outside lambda is: "<<b<<std::endl;// 输出 3return0;}
autoelement=find(numsInVec.cbegin(),// Start of rangenumsInVec.cend(),// End of rangenumToFind);// Element to find// Check if find() succeededif(element!=numsInVec.cend())cout<<"Result: Value found!"<<endl;
autoevenNum=find_if(numsInVec.cbegin(),// Start of rangenumsInVec.cend(),// End of range[](intelement){return(element%2)==0;});if(evenNum!=numsInVec.cend())cout<<"Result: Value found!"<<endl;
// Unary predicate:template<typenameelementType>boolIsEven(constelementType&number){return((number%2)==0);// true, if even}...// Use the count_if algorithm with the unary predicate IsEven:size_tnumEvenNums=count_if(numsInVec.cbegin(),numsInVec.cend(),IsEven<int>);cout<<"Number of even elements: "<<numEvenNums<<endl;
使用举例:
#include<iostream>
#include<vector>
#include<algorithm>usingnamespacestd;template<typenameelementType>boolIsEven(constelementType&number){return((number%2)==0);// true, if even}intmain(){vector<int>numsInVec={1,2,3,4,5,6,7,8,9,10};size_tnumZeroes=count(numsInVec.cbegin(),numsInVec.cend(),0);cout<<"Number of instances of '0': "<<numZeroes<<endl;size_tnumEvenNums=count_if(numsInVec.cbegin(),numsInVec.cend(),IsEven<int>);cout<<"Number of even elements: "<<numEvenNums<<endl;return0;}
autorange=search(numsInVec.cbegin(),// Start range to search innumsInVec.cend(),// End range to search innumsInList.cbegin(),// start range to searchnumsInList.cend());// End range to search for
#include<iostream>
#include<vector>
#include<list>
#include<algorithm>usingnamespacestd;intmain(){vector<int>numsInVec={1,2,3,4,5,6,7,8,9,10,11};list<int>numsInList={9,10,11};list<int>numsInList2={9,10,11,12};autorange=search(numsInVec.cbegin(),// Start range to search innumsInVec.cend(),// End range to search innumsInList.cbegin(),// start range to searchnumsInList.cend());// End range to search for if(range!=numsInVec.cend()){cout<<"Range found at position: "<<distance(numsInVec.cbegin(),range)<<endl;}else{cout<<"Range not found"<<endl;}range=search(numsInVec.cbegin(),// Start range to search innumsInVec.cend(),// End range to search innumsInList2.cbegin(),// start range to searchnumsInList2.cend());// End range to search for if(range!=numsInVec.cend()){cout<<"Range found at position: "<<distance(numsInVec.cbegin(),range)<<endl;}else{cout<<"Range not found"<<endl;}return0;}
search_n() 使用举例:
#include<iostream>
#include<vector>
#include<algorithm>usingnamespacestd;intmain(){vector<int>numsInVec={1,2,3,9,9,9,9,10};autorange=search_n(numsInVec.cbegin(),// Start range to search innumsInVec.cend(),// End range to search in3,9);// End range to search forif(range!=numsInVec.cend()){cout<<"999 found at position: "<<distance(numsInVec.cbegin(),range)<<endl;}else{cout<<"Range not found"<<endl;}return0;}
#include<iostream>
#include<vector>
#include<string>
#include<algorithm>usingnamespacestd;template<typenameT>structDisplayAndCount{intcount=0;DisplayAndCount():count(0){}voidoperator()(constT&value){cout<<value<<" ";count++;}};intmain(){vector<int>numbers={1,2,3,4,5};DisplayAndCount<int>displayAndCount;displayAndCount=for_each(numbers.cbegin(),numbers.cend(),DisplayAndCount<int>());cout<<endl;cout<<"Count: "<<displayAndCount.count<<endl;stringtext="we are the world.";for_each(text.cbegin(),text.cend(),[](constchar&c){cout<<c<<" ";});cout<<endl;return0;}
stringstr("THIS is a TEst string!");transform(str.cbegin(),// start source rangestr.cend(),// end source rangestrLowerCaseCopy.begin(),// start destination range::tolower);// unary function
第二个版本接受一个二元函数,让 transform() 能够处理一对 来自两个不同范围的元素 :
// sum elements from two vectors and store result in a dequetransform(numsInVec1.cbegin(),// start of source range 1numsInVec1.cend(),// end of source range 1numsInVec2.cbegin(),// start of source range 2sumInDeque.begin(),// store result in a dequeplus<int>());// binary function plus
如果承载的容器大小不足,例如result长度设置为 3 会发生什么呢?经运行测试,在 result 装满之后没有自动扩容,也没有报错。
复制元素和删除元素
copy() 复制元素,copy 沿向前的方向将源范围的内容赋给目标范围:
autolastElement=copy(numsInList.cbegin(),// start source rangenumsInList.cend(),// end source rangenumsInVec.begin());// start dest range
copy_if() 是 C++11 新增的,仅在指定的一元谓词返回 true 时才复制元素:
// copy odd numbers from list into vectorcopy_if(numsInList.cbegin(),numsInList.cend(),lastElement,// copy position in dest range[](intelement){return((element%2)==1);});
// Remove all instances of '0', resize vector using erase()autonewEnd=remove(numsInVec.begin(),numsInVec.end(),0);numsInVec.erase(newEnd,numsInVec.end());
remove_if( )使用一个一元谓词,并将容器中满足该谓词的元素删除:
// Remove all odd numbers from the vector using remove_ifnewEnd=remove_if(numsInVec.begin(),numsInVec.end(),[](intnum){return((num%2)==1);});//predicatenumsInVec.erase(newEnd,numsInVec.end());// resizing
使用实例:
#include<iostream>
#include<vector>
#include<algorithm>usingnamespacestd;intmain(){vector<int>numsInVec={1,2,3,4,5,0,6,7,8,9,0};// Copy elements from numsInVec to another vectorvector<int>copiedVec(numsInVec.size());copy(numsInVec.begin(),numsInVec.end(),copiedVec.begin());cout<<"Copied Vector: ";for(constauto&num:copiedVec)cout<<num<<" ";cout<<endl;// Remove all instances of '0'autonewEnd=remove(numsInVec.begin(),numsInVec.end(),0);numsInVec.erase(newEnd,numsInVec.end());cout<<"After removing '0': ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;// Remove all odd numbersnewEnd=remove_if(numsInVec.begin(),numsInVec.end(),[](intnum){return(num%2)==1;});numsInVec.erase(newEnd,numsInVec.end());cout<<"After removing odd numbers: ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;return0;}
cout<<"Using 'std::replace' to replace value 5 by 8"<<endl;replace(numsInVec.begin(),numsInVec.end(),5,8);
replace_if( )需要一个用户指定的一元谓词,对于要替换的每个值,该谓词都返回 true:
cout<<"Using 'std::replace_if' to replace even values by -1"<<endl;replace_if(numsInVec.begin(),numsInVec.end(),[](intelement){return((element%2)==0);},-1);
使用示例:
#include<iostream>
#include<vector>
#include<algorithm>usingnamespacestd;intmain(){vector<int>numsInVec={1,2,3,4,5,6,7,8,9,10};cout<<"Original Vector: ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;// Replace value 5 with 8replace(numsInVec.begin(),numsInVec.end(),5,8);cout<<"After replacing 5 with 8: ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;// Replace even values with -1replace_if(numsInVec.begin(),numsInVec.end(),[](intelement){return(element%2)==0;},-1);cout<<"After replacing even values with -1: ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;return0;}
排序,有序搜索,去重
进行排序,可使用 STL 算法 sort( ):
sort(numsInVec.begin(),numsInVec.end());// ascending order
sort(numsInVec.begin(),numsInVec.end(),[](intlhs,intrhs){return(lhs>rhs);});// descending order
同样,在显示集合的内容前,需要删除重复的元素。要删除相邻的重复值,可使用 unique( ):
autonewEnd=unique(numsInVec.begin(),numsInVec.end());numsInVec.erase(newEnd,numsInVec.end());// to resize
要进行快速查找,可使用 STL 算法 binary_search( ),这种算法只能用于有序容器:
boolelementFound=binary_search(numsInVec.begin(),numsInVec.end(),2011);if(elementFound)cout<<"Element found in the vector!"<<endl;
使用实例:
#include<iostream>
#include<vector>
#include<algorithm>usingnamespacestd;intmain(){vector<int>numsInVec={5,3,8,1,2,2,7,4,6,5,5};cout<<"Original Vector: ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;// Sort the vector in ascending ordersort(numsInVec.begin(),numsInVec.end());cout<<"Sorted Vector (Ascending): ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;// Remove duplicatesautonewEnd=unique(numsInVec.begin(),numsInVec.end());numsInVec.erase(newEnd,numsInVec.end());cout<<"After removing duplicates: ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;// Search for an elementboolelementFound=binary_search(numsInVec.begin(),numsInVec.end(),4);if(elementFound)cout<<"Element 4 found in the vector!"<<endl;elsecout<<"Element 4 not found in the vector!"<<endl;return0;}
#include<iostream>
#include<vector>
#include<algorithm>usingnamespacestd;intmain(){vector<int>numsInVec={1,2,3,4,5,6,7,8,9,10};// Insert an element while maintaining orderintelementToInsert=5;autoinsertPos=lower_bound(numsInVec.begin(),numsInVec.end(),elementToInsert);numsInVec.insert(insertPos,elementToInsert);cout<<"After inserting "<<elementToInsert<<": ";for(constauto&num:numsInVec)cout<<num<<" ";cout<<endl;return0;}
#include<iostream>
#include<stack>
#include<vector>usingnamespacestd;intmain(){// Stack of integers using default deque containerstack<int>intStack;// Stack of strings using default deque containerstack<string>stringStack;// Stack of doubles using vector as the underlying containerstack<double,vector<double>>doubleStack;// initializing one stack to be a copy of anotherstack<int>intStackTwo(intStack);return0;}
#include<iostream>
#include<stack>usingnamespacestd;intmain(){stack<int>numsInStack;// Push elements onto the stackfor(inti=1;i<=5;++i){numsInStack.push(i);cout<<"Pushed: "<<i<<", Stack size: "<<numsInStack.size()<<endl;}// Access and pop elements from the stackwhile(!numsInStack.empty()){cout<<"Top element: "<<numsInStack.top()<<endl;numsInStack.pop();cout<<"Popped, Stack size: "<<numsInStack.size()<<endl;}return0;}
#include<iostream>
#include<queue>usingnamespacestd;intmain(){queue<int>numsInQ;// Enqueue elements into the queuefor(inti=1;i<=5;++i){numsInQ.push(i);cout<<"Enqueued: "<<i<<", Queue size: "<<numsInQ.size()<<endl;}// Access and dequeue elements from the queuewhile(!numsInQ.empty()){cout<<"Front element: "<<numsInQ.front()<<endl;numsInQ.pop();cout<<"Dequeued, Queue size: "<<numsInQ.size()<<endl;}return0;}
// Pre-processor directive#include<iostream>// Start of your programintmain(){// Tell the compiler what namespace to look inusingnamespacestd;/* Write to the screen using cout */cout<<"Hello World"<<endl;// Return a value to the OSreturn0;}
使用函数之前需要声明
#include<iostream>usingnamespacestd;// Function declarationintDemoConsoleOutput();intmain(){// Function callDemoConsoleOutput();return0;}// Function definitionintDemoConsoleOutput(){cout<<"This is a simple string literal"<<endl;cout<<"Writing number five: "<<5<<endl;cout<<"Performing division 10 / 5 = "<<10/5<<endl;cout<<"Pi when approximated is 22 / 7 = "<<22/7<<endl;cout<<"Pi actually is 22 / 7 = "<<22.0/7<<endl;return0;}
#include<iostream>usingnamespacestd;enumCardinalDirections{North=25,South,East,West};intmain(){cout<<"Displaying directions and their symbolic values"<<endl;cout<<"North: "<<North<<endl;cout<<"South: "<<South<<endl;cout<<"East: "<<East<<endl;cout<<"West: "<<West<<endl;CardinalDirectionswindDirection=South;cout<<"Variable windDirection = "<<windDirection<<endl;return0;}
#define pi 3.14286用来定义常量,已废弃
数组声明和访问元素
#include<iostream>usingnamespacestd;intmain(){intmyNumbers[5]={34,56,-21,5002,365};cout<<"First element at index 0: "<<myNumbers[0]<<endl;cout<<"Second element at index 1: "<<myNumbers[1]<<endl;cout<<"Third element at index 2: "<<myNumbers[2]<<endl;cout<<"Fourth element at index 3: "<<myNumbers[3]<<endl;cout<<"Fifth element at index 4: "<<myNumbers[4]<<endl;return0;}
#include<iostream>
#include<vector>usingnamespacestd;intmain(){vector<int>dynArray(3);dynArray[0]=365;dynArray[1]=-421;dynArray[2]=789;cout<<"Number of integers in array: "<<dynArray.size()<<endl;cout<<"Enter another element to insert"<<endl;intnewValue=0;cin>>newValue;dynArray.push_back(newValue);cout<<"Number of integers in array: "<<dynArray.size()<<endl;cout<<"Last element in array: ";cout<<dynArray[dynArray.size()-1]<<endl;return0;}
#include<iostream>
#include<string>usingnamespacestd;intmain(){stringgreetStrings("Hello std::string!");cout<<greetStrings<<endl;cout<<"Enter a line of text: "<<endl;stringfirstLine;getline(cin,firstLine);cout<<"Enter another: "<<endl;stringsecondLine;getline(cin,secondLine);cout<<"Result of concatenation: "<<endl;stringconcatString=firstLine+" "+secondLine;cout<<concatString<<endl;cout<<"Copy of concatenated string: "<<endl;stringaCopy;aCopy=concatString;cout<<aCopy<<endl;cout<<"Length of concat string: "<<concatString.length()<<endl;return0;}
函数值传递
默认情况下, 函数参数在作用域生效的是外部实参的拷贝 ,内部的操作不会影响原参数。
可以使用按引用传递的参数,在函数体内部也可以对外部传来的参数做修改。
#include<iostream>usingnamespacestd;constdoublePi=3.1416;// output parameter result by reference voidArea(doubleradius,double&result){result=Pi*radius*radius;}intmain(){cout<<"Enter radius: ";doubleradius=0;cin>>radius;doubleareaFetched=0;Area(radius,areaFetched);cout<<"The area is: "<<areaFetched<<endl;return0;}
#include<iostream>usingnamespacestd;intmain(){intage=30;int*pointsToInt=&age;cout<<"pointsToInt points to age now"<<endl;// Displaying the value of pointercout<<"pointsToInt = 0x"<<hex<<pointsToInt<<endl;intDogsAge=9;pointsToInt=&DogsAge;cout<<"pointsToInt points to DogsAge now"<<endl;cout<<"pointsToInt = 0x"<<hex<<pointsToInt<<endl;return0;}
#include<iostream>usingnamespacestd;intmain(){intage=30;intdogsAge=9;cout<<"Integer age = "<<age<<endl;cout<<"Integer dogsAge = "<<dogsAge<<endl;int*pointsToInt=&age;cout<<"pointsToInt points to age"<<endl;// Displaying the value of pointercout<<"pointsToInt = 0x"<<hex<<pointsToInt<<endl;// Displaying the value at the pointed locationcout<<"*pointsToInt = "<<dec<<*pointsToInt<<endl;pointsToInt=&dogsAge;cout<<"pointsToInt points to dogsAge now"<<endl;cout<<"pointsToInt = 0x"<<hex<<pointsToInt<<endl;cout<<"*pointsToInt = "<<dec<<*pointsToInt<<endl;return0;}
#include<iostream>usingnamespacestd;intmain(){// Request for memory space for an intint*pointsToAnAge=newint;// Use the allocated memory to store a numbercout<<"Enter your dog's age: ";cin>>*pointsToAnAge;// use indirection operator* to access value cout<<"Age "<<*pointsToAnAge<<" is stored at 0x"<<hex<<pointsToAnAge<<endl;deletepointsToAnAge;// release dynamically allocated memoryreturn0;}
不能将运算符 delete 用于任何包含地址的指针,而只能用于 new 返回的且未使用 delete 释放的指针。
#include<iostream>usingnamespacestd;intmain(){constintARRAY_LEN=5;// Static array of 5 integers, initializedintmyNumbers[ARRAY_LEN]={24,-1,365,-999,2011};// Pointer initialized to first element in arrayint*pointToNums=myNumbers;cout<<"Display array using pointer syntax, operator*"<<endl;for(intindex=0;index<ARRAY_LEN;++index)cout<<"Element "<<index<<" = "<<*(myNumbers+index)<<endl;cout<<"Display array using ptr with array syntax, operator[]"<<endl;for(intindex=0;index<ARRAY_LEN;++index)cout<<"Element "<<index<<" = "<<pointToNums[index]<<endl;return0;}
const指针
指针的主要功能是指向一个 变量的地址 ,理解为越靠近变量的限制性越高级。
const贴近变量名,不允许修改指针指向的地址,可以修改指向的变量。
#include<iostream>usingnamespacestd;intmain(){intage=30;intdogsAge=9;int*constpointsToAge=&age;cout<<"*pointsToAge = "<<*pointsToAge<<endl;// pointsToAge = &dogsAge; // error! can't change pointer value*pointsToAge=31;// ok! can change value pointed tocout<<"*pointsToAge = "<<*pointsToAge<<endl;return0;}
const远离变量名,在最前,不允许修改指向变量的值,指针可以指向其他地方。
#include<iostream>usingnamespacestd;intmain(){intage=30;intdogsAge=9;constint*pointsToAge=&age;cout<<"*pointsToAge = "<<*pointsToAge<<endl;// *pointsToAge = 31; // error! can't change value pointed topointsToAge=&dogsAge;// ok! can change pointer valuecout<<"*pointsToAge = "<<*pointsToAge<<endl;return0;}
#include<iostream>usingnamespacestd;voidCalcArea(constdouble*constptrPi,// const pointer to const dataconstdouble*constptrRadius,// i.e. no changes alloweddouble*constptrArea)// can change data pointed to,but not pointer{// check pointers for validity before using!if(ptrPi&&ptrRadius&&ptrArea)*ptrArea=(*ptrPi)*(*ptrRadius)*(*ptrRadius);}intmain(){constdoublePi=3.1416;cout<<"Enter radius of circle: ";doubleradius=0;cin>>radius;doublearea=0;CalcArea(&Pi,&radius,&area);cout<<"Area is = "<<area<<endl;return0;}
#include<iostream>usingnamespacestd;// remove the try-catch block to see this application crash intmain(){try{// Request a LOT of memory!int*pointsToManyNums=newint[0x1fffffff];// Use the allocated memory delete[]pointsToManyNums;}catch(bad_alloc){cout<<"Memory allocation failed. Ending program"<<endl;}return0;}
使用new(nothrow)
#include<iostream>usingnamespacestd;intmain(){// Request LOTS of memory space, use nothrow int*pointsToManyNums=new(nothrow)int[0x1fffffff];if(pointsToManyNums)// check pointsToManyNums != NULL{// Use the allocated memory delete[]pointsToManyNums;}elsecout<<"Memory allocation failed. Ending program"<<endl;return0;}
#include<iostream>usingnamespacestd;intmain(){intoriginal=30;cout<<"original = "<<original<<endl;cout<<"original is at address: "<<hex<<&original<<endl;int&ref1=original;cout<<"ref1 is at address: "<<hex<<&ref1<<endl;int&ref2=ref1;cout<<"ref2 is at address: "<<hex<<&ref2<<endl;cout<<"Therefore, ref2 = "<<dec<<ref2<<endl;return0;}
他们指向同一个地址。
引用的用处
函数参数,如果在合适的时机,按引用传递,可以省去变量复制的步骤,优化性能。
#include<iostream>usingnamespacestd;voidGetSquare(int&number){number*=number;}intmain(){cout<<"Enter a number you wish to square: ";intnumber=0;cin>>number;GetSquare(number);cout<<"Square is: "<<number<<endl;return0;}
intoriginal=30;constint&constRef=original;constRef=40;// Not allowed: constRef can’t change value in originalint&ref2=constRef;// Not allowed: ref2 is not constconstint&constRef2=constRef;// OK
#include<iostream>
#include<string>usingnamespacestd;classHuman{public:stringname;intage;voidIntroduceSelf(){cout<<"I am "+name<<" and am ";cout<<age<<" years old"<<endl;}};intmain(){// An object of class Human with attribute name as "Adam"HumanfirstMan;firstMan.name="Adam";firstMan.age=30;// An object of class Human with attribute name as "Eve"HumanfirstWoman;firstWoman.name="Eve";firstWoman.age=28;firstMan.IntroduceSelf();firstWoman.IntroduceSelf();}
使用指针运算符访问成员
如果对象是使用 new 在自由存储区中实例化的,或者有指向对象的指针,则可使用指针运算符 -> 来访问成员属性和方法:
#include<iostream>
#include<string>usingnamespacestd;classHuman{private:intage;stringname;public:Human(stringhumansName="Adam",inthumansAge=25):name(humansName),age(humansAge){cout<<"Constructed a human called "<<name;cout<<", "<<age<<" years old"<<endl;}};intmain(){Humanadam;Humaneve("Eve",18);return0;}
#include<iostream>
#include<string.h>usingnamespacestd;classMyString{private:char*buffer;public:MyString(constchar*initString)// Constructor{buffer=NULL;if(initString!=NULL){buffer=newchar[strlen(initString)+1];strcpy(buffer,initString);}}~MyString()// Destructor{cout<<"Invoking destructor, clearing up"<<endl;delete[]buffer;}intGetLength(){returnstrlen(buffer);}constchar*GetString(){returnbuffer;}};voidUseMyString(MyStringstr){cout<<"String buffer in MyString is "<<str.GetLength();cout<<" characters long"<<endl;cout<<"buffer contains: "<<str.GetString()<<endl;return;}intmain(){MyStringsayHello("Hello from String Class");UseMyString(sayHello);return0;}/**
String buffer in MyString is 23 characters long
buffer contains: Hello from String Class
Invoking destructor, clearing up
Invoking destructor, clearing up
<crash as seen in Figure 9.2>
*/
#include<iostream>
#include<string>usingnamespacestd;classPresident{private:President(){};// private default constructorPresident(constPresident&);// private copy constructorconstPresident&operator=(constPresident&);// assignment operatorstringname;public:staticPresident&GetInstance(){// static objects are constructed only oncestaticPresidentonlyInstance;returnonlyInstance;}stringGetName(){returnname;}voidSetName(stringInputName){name=InputName;}};intmain(){President&onlyPresident=President::GetInstance();onlyPresident.SetName("Abraham Lincoln");// uncomment lines to see how compile failures prohibit duplicates// President second; // cannot access constructor// President* third= new President(); // cannot access constructor// President fourth = onlyPresident; // cannot access copy constructor// onlyPresident = President::GetInstance(); // cannot access operator=cout<<"The name of the President is: ";cout<<President::GetInstance().GetName()<<endl;return0;}
将析构函数设为私有,就禁止在栈中实例化
只能通过 new 关键字,在自由存储区实例化
#include<iostream>usingnamespacestd;classMonsterDB{private:~MonsterDB(){};// private destructor prevents instances on stackpublic:staticvoidDestroyInstance(MonsterDB*pInstance){deletepInstance;// member can invoke private destructor}voidDoSomething(){}// sample member method};intmain(){MonsterDB*myDB=newMonsterDB();// on heapmyDB->DoSomething();// uncomment next line to see compile failure // delete myDB; // private destructor cannot be invoked// use static member to release memoryMonsterDB::DestroyInstance(myDB);return0;}
隐式转换和预防
Human类构造函数接受一个int类型作为参数。
这样的转换构造函数让您能够执行隐式转换:
HumananotherKid=11;// int converted to HumanDoSomething(10);// 10 converted to Human!
函数 DoSomething(Human person)被声明为接受一个 Human(而不是 int)参数!前面的代码为何可行呢?这是因为编译器知道 Human 类包含一个将整数作为参数的构造函数,进而替您执行了隐式转换:将您提供的整数作为参数发送给这个构造函数,从而创建一个Human 对象。
使用 explicit 关键字避免隐式转换:
#include<iostream>usingnamespacestd;classHuman{intage;public:// explicit constructor blocks implicit conversionsexplicitHuman(inthumansAge):age(humansAge){}};voidDoSomething(Humanperson){cout<<"Human sent did something"<<endl;return;}intmain(){Humankid(10);// explicit converion is OKHumananotherKid=Human(11);// explicit, OKDoSomething(kid);// OK// Human anotherKid = 11; // failure: implicit conversion not OK// DoSomething(10); // implicit conversion return0;}
this指针
当您在类成员方法中调用其他成员方法时,编译器将隐式地传递 this 指针—函数调用中不可见的参数:
classHuman{private:voidTalk(stringStatement){cout<<Statement;}public:voidIntroduceSelf(){Talk("Bla bla");// same as Talk(this, "Bla Bla")}};
在这里,方法 IntroduceSelf( )使用私有成员 Talk( )在屏幕上显示一句话。实际上,编译器将在调用Talk 时嵌入 this 指针,即:
#include<iostream>
#include<string>usingnamespacestd;classHuman{private:friendvoidDisplayAge(constHuman&person);stringname;intage;public:Human(stringhumansName,inthumansAge){name=humansName;age=humansAge;}};voidDisplayAge(constHuman&person){cout<<person.age<<endl;}intmain(){HumanfirstMan("Adam",25);cout<<"Accessing private member age via friend function: ";DisplayAge(firstMan);return0;}#include<iostream>#include<string>usingnamespacestd;classHuman{private:friendclassUtility;stringname;intage;public:Human(stringhumansName,inthumansAge){name=humansName;age=humansAge;}};classUtility{public:staticvoidDisplayAge(constHuman&person){cout<<person.age<<endl;}};intmain(){HumanfirstMan("Adam",25);cout<<"Accessing private member age via friend class: ";Utility::DisplayAge(firstMan);return0;}
盲猜用于共同实现某一功能的两个模块,比如混动车的燃油发动机给电动机供电。
struct结构体,和类类似,属性默认为公开
关键字 struct 来自 C 语言,在 C++编译器看来,它与类及其相似,差别在于程序员未指定时,默认的访问限定符(public 和 private)不同。因此,除非指定了,否则结构中的成员默认为公有的(而类成员默认为私有的);另外,除非指定了,否则结构以公有方式继承基结构(而类为私有继承)。
#include<iostream>usingnamespacestd;unionSimpleUnion{intnum;charalphabet;};structComplexType{enumDataType{Int,Char}Type;unionValue{intnum;charalphabet;Value(){}~Value(){}}value;};voidDisplayComplexType(constComplexType&obj){switch(obj.Type){caseComplexType::Int:cout<<"Union contains number: "<<obj.value.num<<endl;break;caseComplexType::Char:cout<<"Union contains character: "<<obj.value.alphabet<<endl;break;}}intmain(){SimpleUnionu1,u2;u1.num=2100;u2.alphabet='C';// Alternative using aggregate initialization:// SimpleUnion u1{ 2100 }, u2{ 'C' }; // Note that 'C' still initializes first / int membercout<<"sizeof(u1) containing integer: "<<sizeof(u1)<<endl;cout<<"sizeof(u2) containing character: "<<sizeof(u2)<<endl;ComplexTypemyData1,myData2;myData1.Type=ComplexType::Int;myData1.value.num=2017;myData2.Type=ComplexType::Char;myData2.value.alphabet='X';DisplayComplexType(myData1);DisplayComplexType(myData2);return0;}/**
sizeof(u1) containing integer: 4
sizeof(u2) containing character: 4
Union contains number: 2017
Union contains character: X
*/
换句话说,这个结构使用枚举来存储信息类型,并使用共用体来存储实际值。这是共用体的一种常见用法,例如,在 Windows 应用程序编程中常用的结构 VARIANT 就以这样的方式使用了共用体.
聚合初始化
#include<iostream>
#include<string>usingnamespacestd;classAggregate1{public:intnum;doublepi;};structAggregate2{charhello[6];intimpYears[3];stringworld;};intmain(){intmyNums[]={9,5,-1};// myNums is int[3]Aggregate1a1{2017,3.14};cout<<"Pi is approximately: "<<a1.pi<<endl;Aggregate2a2{{'h','e','l','l','o'},{2011,2014,2017},"world"};// AlternativelyAggregate2a2_2{'h','e','l','l','o','\0',2011,2014,2017,"world"};cout<<a2.hello<<' '<<a2.world<<endl;cout<<"C++ standard update scheduled in: "<<a2.impYears[2]<<endl;return0;}
constexpr还可以用于类的构造函数和成员函数,编译器会尽可能将其视为常量处理
#include<iostream>usingnamespacestd;classHuman{intage;public:constexprHuman(inthumansAge):age(humansAge){}constexprintGetAge()const{returnage;}};intmain(){constexprHumansomePerson(15);constinthisAge=somePerson.GetAge();HumananotherPerson(45);// not constant expressionreturn0;}
最简单的继承
#include<iostream>usingnamespacestd;classFish{public:boolisFreshWaterFish;voidSwim(){if(isFreshWaterFish)cout<<"Swims in lake"<<endl;elsecout<<"Swims in sea"<<endl;}};classTuna:publicFish{public:Tuna(){isFreshWaterFish=false;}};classCarp:publicFish{public:Carp(){isFreshWaterFish=true;}};intmain(){CarpmyLunch;TunamyDinner;cout<<"Getting my food to swim"<<endl;cout<<"Lunch: ";myLunch.Swim();cout<<"Dinner: ";myDinner.Swim();return0;}
基类使用protected关键字,该成员只有子类和友元中可以访问,外部不可以访问
基类构造器可以带参数,子类构造器必须一起初始化基类的构造器
#include<iostream>usingnamespacestd;classFish{protected:boolisFreshWaterFish;// accessible only to derived classespublic:// Fish constructorFish(boolisFreshWater):isFreshWaterFish(isFreshWater){}voidSwim(){if(isFreshWaterFish)cout<<"Swims in lake"<<endl;elsecout<<"Swims in sea"<<endl;}};classTuna:publicFish{public:Tuna():Fish(false){}};classCarp:publicFish{public:Carp():Fish(true){}};intmain(){CarpmyLunch;TunamyDinner;cout<<"Getting my food to swim"<<endl;cout<<"Lunch: ";myLunch.Swim();cout<<"Dinner: ";myDinner.Swim();return0;}
基类属性和方法的覆写
如果派生类实现了从基类继承的函数,且返回值和特征标相同,就相当于覆盖了基类的这个方法。
如果基类的方法是public的,外部可以通过域解析运算符::来调用基类方法。 myDinner.Fish::Swim(); // invokes Fish::Swim() using instance of Tuna在子类中,同样用上述方法来调用。
隐藏基类方法
基类中有同名的重载方法时,子类覆写其中一个,子类中会对外隐藏所有的同名方法。
#include<iostream>usingnamespacestd;classFish{public:voidSwim(){cout<<"Fish swims... !"<<endl;}voidSwim(boolisFreshWaterFish){if(isFreshWaterFish)cout<<"Swims in lake"<<endl;elsecout<<"Swims in sea"<<endl;}};classTuna:publicFish{public:voidSwim(boolisFreshWaterFish){Fish::Swim(isFreshWaterFish);}voidSwim(){cout<<"Tuna swims real fast"<<endl;}};intmain(){TunamyDinner;cout<<"Getting my food to swim"<<endl;myDinner.Swim(false);//failure: Tuna::Swim() hides Fish::Swim(bool)myDinner.Swim();return0;}
对于大多数使用私有继承的情形(如 Car 和 Motor 之间的私有继承),更好的选择是,将基类对象作为派生类的一个成员属性。通过继承 Motor 类,相当于对 Car 类进行了限制,使其只能有一台发动机,同时,相比于将 Motor 对象作为私有成员,没有任何好处可言。汽车在不断发展,例如,混合动力车除电力发动机外,还有一台汽油发动机。在这种情况下,让 Car 类继承 Motor 类将成为兼容性瓶颈。
#include<iostream>usingnamespacestd;classFish{public:Fish(){cout<<"Constructed Fish"<<endl;}virtual~Fish()// virtual destructor!{cout<<"Destroyed Fish"<<endl;}};classTuna:publicFish{public:Tuna(){cout<<"Constructed Tuna"<<endl;}~Tuna(){cout<<"Destroyed Tuna"<<endl;}};voidDeleteFishMemory(Fish*pFish){deletepFish;}intmain(){cout<<"Allocating a Tuna on the free store:"<<endl;Tuna*pTuna=newTuna;cout<<"Deleting the Tuna: "<<endl;DeleteFishMemory(pTuna);cout<<"Instantiating a Tuna on the stack:"<<endl;TunamyDinner;cout<<"Automatic destruction as it goes out of scope: "<<endl;return0;}
#include<iostream>usingnamespacestd;classFish{public:// define a pure virtual function SwimvirtualvoidSwim()=0;};classTuna:publicFish{public:voidSwim(){cout<<"Tuna swims fast in the sea!"<<endl;}};classCarp:publicFish{voidSwim(){cout<<"Carp swims slow in the lake!"<<endl;}};voidMakeFishSwim(Fish&inputFish){inputFish.Swim();}intmain(){// Fish myFish; // Fails, cannot instantiate an ABCCarpmyLunch;TunamyDinner;MakeFishSwim(myLunch);MakeFishSwim(myDinner);return0;}
#include<iostream>usingnamespacestd;classAnimal{public:Animal(){cout<<"Animal constructor"<<endl;}// sample memberintage;};classMammal:publicvirtualAnimal{};classBird:publicvirtualAnimal{};classReptile:publicvirtualAnimal{};classPlatypusfinal:publicMammal,publicBird,publicReptile{public:Platypus(){cout<<"Platypus constructor"<<endl;}};intmain(){PlatypusduckBilledP;// no compile error as there is only one Animal::ageduckBilledP.age=25;return0;}/**
Animal constructor
Platypus constructor
*/
#include<iostream>usingnamespacestd;classFish{public:virtualFish*Clone()=0;virtualvoidSwim()=0;virtual~Fish(){};};classTuna:publicFish{public:Fish*Clone()override{returnnewTuna(*this);}voidSwim()overridefinal{cout<<"Tuna swims fast in the sea"<<endl;}};classBluefinTunafinal:publicTuna{public:Fish*Clone()override{returnnewBluefinTuna(*this);}// Cannot override Tuna::Swim as it is "final" in Tuna};classCarpfinal:publicFish{Fish*Clone()override{returnnewCarp(*this);}voidSwim()overridefinal{cout<<"Carp swims slow in the lake"<<endl;}};intmain(){constintARRAY_SIZE=4;Fish*myFishes[ARRAY_SIZE]={NULL};myFishes[0]=newTuna();myFishes[1]=newCarp();myFishes[2]=newBluefinTuna();myFishes[3]=newCarp();Fish*myNewFishes[ARRAY_SIZE];for(intindex=0;index<ARRAY_SIZE;++index)myNewFishes[index]=myFishes[index]->Clone();// invoke a virtual method to checkfor(intindex=0;index<ARRAY_SIZE;++index)myNewFishes[index]->Swim();// memory cleanupfor(intindex=0;index<ARRAY_SIZE;++index){deletemyFishes[index];deletemyNewFishes[index];}return0;}
// also contains postfix increment and decrement#include<iostream>usingnamespacestd;classDate{private:intday,month,year;public:Date(intinMonth,intinDay,intinYear):month(inMonth),day(inDay),year(inYear){};Date&operator++()// prefix increment{++day;return*this;}Date&operator--()// prefix decrement{--day;return*this;}Dateoperator++(int)// postfix increment{Datecopy(month,day,year);++day;returncopy;}Dateoperator--(int)// postfix decrement{Datecopy(month,day,year);--day;returncopy;}voidDisplayDate(){cout<<month<<" / "<<day<<" / "<<year<<endl;}};intmain(){Dateholiday(12,25,2016);// Dec 25, 2016cout<<"The date object is initialized to: ";holiday.DisplayDate();++holiday;// move date ahead by a daycout<<"Date after prefix-increment is: ";holiday.DisplayDate();--holiday;// move date backwards by a daycout<<"Date after a prefix-decrement is: ";holiday.DisplayDate();return0;}
转换运算符
operatorconstchar*(){// operator implementation that returns a char*}
#include<iostream>
#include<sstream> // new include for ostringstream
#include<string>usingnamespacestd;classDate{private:intday,month,year;stringdateInString;public:Date(intinMonth,intinDay,intinYear):month(inMonth),day(inDay),year(inYear){};operatorconstchar*(){ostringstreamformattedDate;// assists easy string constructionformattedDate<<month<<" / "<<day<<" / "<<year;dateInString=formattedDate.str();returndateInString.c_str();}};intmain(){DateHoliday(12,25,2016);cout<<"Holiday is on: "<<Holiday<<endl;// string strHoliday (Holiday); // OK!// strHoliday = Date(11, 11, 2016); // also OK!return0;}
智能指针初体验
#include<iostream>
#include<memory> // new include to use unique_ptrusingnamespacestd;classDate{private:intday,month,year;stringdateInString;public:Date(intinMonth,intinDay,intinYear):month(inMonth),day(inDay),year(inYear){};voidDisplayDate(){cout<<month<<" / "<<day<<" / "<<year<<endl;}};intmain(){unique_ptr<int>smartIntPtr(newint);*smartIntPtr=42;// Use smart pointer type like an int*cout<<"Integer value is: "<<*smartIntPtr<<endl;unique_ptr<Date>smartHoliday(newDate(12,25,2016));cout<<"The new instance of date contains: ";// use smartHoliday just as you would a Date*smartHoliday->DisplayDate();return0;}
#include<iostream>usingnamespacestd;classDate{private:intday,month,year;public:Date(intinMonth,intinDay,intinYear):month(inMonth),day(inDay),year(inYear){}booloperator==(constDate&compareTo){return((day==compareTo.day)&&(month==compareTo.month)&&(year==compareTo.year));}booloperator!=(constDate&compareTo){return!(this->operator==(compareTo));}voidDisplayDate(){cout<<month<<" / "<<day<<" / "<<year<<endl;}};intmain(){Dateholiday1(12,25,2016);Dateholiday2(12,31,2016);cout<<"holiday 1 is: ";holiday1.DisplayDate();cout<<"holiday 2 is: ";holiday2.DisplayDate();if(holiday1==holiday2)cout<<"Equality operator: The two are on the same day"<<endl;elsecout<<"Equality operator: The two are on different days"<<endl;if(holiday1!=holiday2)cout<<"Inequality operator: The two are on different days"<<endl;elsecout<<"Inequality operator: The two are on the same day"<<endl;return0;}/**
holiday 1 is: 12 / 25 / 2016
holiday 2 is: 12 / 31 / 2016
Equality operator: The two are on different days
Inequality operator: The two are on different days
*/
#include<iostream>
#include<string.h>usingnamespacestd;classMyString{private:char*buffer;public:MyString(constchar*initialInput){if(initialInput!=NULL){buffer=newchar[strlen(initialInput)+1];strcpy(buffer,initialInput);}elsebuffer=NULL;}// Copy assignment operatorMyString&operator=(constMyString&CopySource){if((this!=&CopySource)&&(CopySource.buffer!=NULL)){if(buffer!=NULL)delete[]buffer;// ensure deep copy by first allocating own buffer buffer=newchar[strlen(CopySource.buffer)+1];// copy from the source into local bufferstrcpy(buffer,CopySource.buffer);}return*this;}operatorconstchar*(){returnbuffer;}~MyString(){delete[]buffer;}MyString(constMyString&CopySource){cout<<"Copy constructor: copying from MyString"<<endl;if(CopySource.buffer!=NULL){// ensure deep copy by first allocating own buffer buffer=newchar[strlen(CopySource.buffer)+1];// copy from the source into local bufferstrcpy(buffer,CopySource.buffer);}elsebuffer=NULL;}};intmain(){MyStringstring1("Hello ");MyStringstring2(" World");cout<<"Before assignment: "<<endl;cout<<string1<<string2<<endl;string2=string1;cout<<"After assignment string2 = string1: "<<endl;cout<<string1<<string2<<endl;return0;}/**
Before assignment:
Hello World
After assignment string2 = string1:
Hello Hello
*/
如果您编写的类管理着动态分配的资源(如使用 new 分配的数组),除构造函数和析构函数外,请务必实现复制构造函数和复制赋值运算符。
#include<iostream>
#include<string>
#include<string.h>usingnamespacestd;classMyString{private:char*Buffer;// private default constructorMyString(){}public:// constructorMyString(constchar*InitialInput){if(InitialInput!=NULL){Buffer=newchar[strlen(InitialInput)+1];strcpy(Buffer,InitialInput);}elseBuffer=NULL;}MyStringoperator+(constchar*stringIn){stringstrBuf(Buffer);strBuf+=stringIn;MyStringret(strBuf.c_str());returnret;}// Copy constructorMyString(constMyString&CopySource){if(CopySource.Buffer!=NULL){// ensure deep copy by first allocating own buffer Buffer=newchar[strlen(CopySource.Buffer)+1];// copy from the source into local bufferstrcpy(Buffer,CopySource.Buffer);}elseBuffer=NULL;}// Copy assignment operatorMyString&operator=(constMyString&CopySource){if((this!=&CopySource)&&(CopySource.Buffer!=NULL)){if(Buffer!=NULL)delete[]Buffer;// ensure deep copy by first allocating own buffer Buffer=newchar[strlen(CopySource.Buffer)+1];// copy from the source into local bufferstrcpy(Buffer,CopySource.Buffer);}return*this;}constchar&operator[](intIndex)const{if(Index<GetLength())returnBuffer[Index];}// Destructor~MyString(){if(Buffer!=NULL)delete[]Buffer;}intGetLength()const{returnstrlen(Buffer);}operatorconstchar*(){returnBuffer;}};intmain(){cout<<"Type a statement: ";stringstrInput;getline(cin,strInput);MyStringyouSaid(strInput.c_str());cout<<"Using operator[] for displaying your input: "<<endl;for(intindex=0;index<youSaid.GetLength();++index)cout<<youSaid[index]<<" ";cout<<endl;cout<<"Enter index 0 - "<<youSaid.GetLength()-1<<": ";intindex=0;cin>>index;cout<<"Input character at zero-based position: "<<index;cout<<" is: "<<youSaid[index]<<endl;return0;}/**
Type a statement: Hey subscript operators[] are fabulous
Using operator[] for displaying your input:
H e y s u b s c r i p t o p e r a t o r s [ ] a r e f a b u l o u s
Enter index 0 - 37: 2
Input character at zero-based position: 2 is: y
*/
#include<iostream>
#include<string>usingnamespacestd;classDisplay{public:voidoperator()(stringinput)const{cout<<input<<endl;}};intmain(){DisplaydisplayFuncObj;// equivalent to displayFuncObj.operator () ("Display this string!");displayFuncObj("Display this string!");return0;}
在执行下面的拼接加赋值sayHelloAgain = Hello + World + CPP这个过程中,首先调用Hello的+运算符函数,将World的内容加进来,创造一个临时对象(Hello World),同理再把cpp加进来,创造另一个临时对象(Hello World of C++)。然后编译器会调用sayHelloAgain的移动构造函数,将这个临时对象的内容赋给sayHelloAgain,然后删除临时对象的buffer。这个过程只使用了一次移动构造函数。
#include<iostream>usingnamespacestd;structTemperature{doubleKelvin;Temperature(longdoublekelvin):Kelvin(kelvin){}};Temperatureoperator""_C(longdoublecelcius){returnTemperature(celcius+273);}Temperatureoperator""_F(longdoublefahrenheit){returnTemperature((fahrenheit+459.67)*5/9);}intmain(){Temperaturek1=31.73_F;Temperaturek2=0.0_C;cout<<"k1 is "<<k1.Kelvin<<" Kelvin"<<endl;cout<<"k2 is "<<k2.Kelvin<<" Kelvin"<<endl;return0;}/**
k1 is 273 Kelvin
k2 is 273 Kelvin
*/
Base*objBase=newDerived();// Perform a downcastDerived*objDer=dynamic_cast<Derived*>(objBase);if(objDer)// Check for success of the castobjDer->CallDerivedFunction();
这种在运行阶段识别对象类型的机制称为
运行阶段类型识别(runtime type identification,RTTI)。
#include<iostream>usingnamespacestd;classFish{public:virtualvoidSwim(){cout<<"Fish swims in water"<<endl;}// base class should always have virtual destructorvirtual~Fish(){}};classTuna:publicFish{public:voidSwim(){cout<<"Tuna swims real fast in the sea"<<endl;}voidBecomeDinner(){cout<<"Tuna became dinner in Sushi"<<endl;}};classCarp:publicFish{public:voidSwim(){cout<<"Carp swims real slow in the lake"<<endl;}voidTalk(){cout<<"Carp talked carp!"<<endl;}};voidDetectFishType(Fish*objFish){Tuna*objTuna=dynamic_cast<Tuna*>(objFish);if(objTuna){cout<<"Detected Tuna. Making Tuna dinner: "<<endl;objTuna->BecomeDinner();// calling Tuna::BecomeDinner}Carp*objCarp=dynamic_cast<Carp*>(objFish);if(objCarp){cout<<"Detected Carp. Making carp talk: "<<endl;objCarp->Talk();// calling Carp::Talk}cout<<"Verifying type using virtual Fish::Swim: "<<endl;objFish->Swim();// calling virtual function Swim}intmain(){CarpmyLunch;TunamyDinner;DetectFishType(&myDinner);DetectFishType(&myLunch);return0;}
务必检查 dynamic_cast 的返回值,看它是否有效。如果返回值为 NULL,说明转换失败。
reinterpret_cast强制转换
可以做任何类型转换。
这种类型转换实际上是强制编译器接受 static_cast 通常不允许的类型转换,通常用于低级程序(如驱动程序),在这种程序中,需要将数据转换为 API(应用程序编程接口)能够接受的简单类型(例如,有些 OS 级 API 要求提供的数据为 BYTE 数组,即 unsigned char*)。
voidDisplayAllData(constSomeClass*data){// data->DisplayMembers(); Error: attempt to invoke a non-const function!SomeClass*pCastedData=const_cast<SomeClass*>(data);pCastedData->DisplayMembers();// Allowed!}
使用类型转换需要注意
在现代 C++中,除 dynamic_cast 外的类型转换都是可以避免的。仅当需要满足遗留应用程序的需求时,才需要使用其他类型转换运算符。在这种情况下,程序员通常倾向于使用 C 风格类型转换而不是C++类型转换运算符。重要的是,应尽量避免使用类型转换;而一旦使用类型转换,务必要知道幕后发生的情况。
#ifndef HEADER1_H _//multiple inclusion guard:
#define HEADER1_H_ // preprocessor will read this and following lines once
#include<header2.h>classClass1{// class members};#endif // end of header1.h
header2.h 与此类似,但宏定义不同,且包含的是<header1.h>:
#ifndef HEADER2_H_ //multiple inclusion guard
#define HEADER2_H_
#include<header1.h>classClass2{// class members};#endif // end of header2.h
classHoldsPair{private:T1value1;T2value2;public:// Constructor that initializes member variablesHoldsPair(constT1&val1,constT2&val2){value1=val1;value2=val2;};// ... Other member functions};// 在这里,类 HoldsPair 接受两个模板参数,参数名分别为 T1 和 T2。可使用这个类来存储两个类型// 相同或不同的对象,如下所示:// A template instantiation that pairs an int with a doubleHoldsPair<int,double>pairIntDouble(6,1.99);// A template instantiation that pairs an int with an intHoldsPair<int,int>pairIntDouble(6,500);
还可以设置默认类型简化使用,如果实例使用的和默认类型相同,则可以简化对象的声明方式。
// template with default params: int & doubletemplate<typenameT1=int,typenameT2=double>classHoldsPair{private:T1value1;T2value2;public:HoldsPair(constT1&val1,constT2&val2)// constructor:value1(val1),value2(val2){}// Accessor functionsconstT1&GetFirstValue()const{returnvalue1;}constT2&GetSecondValue()const{returnvalue2;}};#include<iostream>usingnamespacestd;intmain(){HoldsPair<>pairIntDbl(300,10.09);HoldsPair<short,constchar*>pairShortStr(25,"Learn templates, love C++");cout<<"The first object contains -"<<endl;cout<<"Value 1: "<<pairIntDbl.GetFirstValue()<<endl;cout<<"Value 2: "<<pairIntDbl.GetSecondValue()<<endl;cout<<"The second object contains -"<<endl;cout<<"Value 1: "<<pairShortStr.GetFirstValue()<<endl;cout<<"Value 2: "<<pairShortStr.GetSecondValue()<<endl;return0;}
#include<iostream>usingnamespacestd;template<typenameT1=int,typenameT2=double>classHoldsPair{private:T1value1;T2value2;public:HoldsPair(constT1&val1,constT2&val2)// constructor:value1(val1),value2(val2){}// Accessor functionsconstT1&GetFirstValue()const;constT2&GetSecondValue()const;};// specialization of HoldsPair for types int & int heretemplate<>classHoldsPair<int,int>{private:intvalue1;intvalue2;stringstrFun;public:HoldsPair(constint&val1,constint&val2)// constructor:value1(val1),value2(val2){}constint&GetFirstValue()const{cout<<"Returning integer "<<value1<<endl;returnvalue1;}};intmain(){HoldsPair<int,int>pairIntInt(222,333);pairIntInt.GetFirstValue();return0;}
带静态变量的模板类
#include<iostream>usingnamespacestd;template<typenameT>classTestStatic{public:staticintstaticVal;};// static member initializationtemplate<typenameT>intTestStatic<T>::staticVal;intmain(){TestStatic<int>intInstance;cout<<"Setting staticVal for intInstance to 2011"<<endl;intInstance.staticVal=2011;TestStatic<double>dblnstance;cout<<"Setting staticVal for Double_2 to 1011"<<endl;dblnstance.staticVal=1011;cout<<"intInstance.staticVal = "<<intInstance.staticVal<<endl;cout<<"dblnstance.staticVal = "<<dblnstance.staticVal<<endl;return0;}/**
Setting staticVal for intInstance to 2011
Setting staticVal for Double_2 to 1011
intInstance.staticVal = 2011
dblnstance.staticVal = 1011
*/
也就是说,如果模板类包含静态成员,该成员将在针对 int 具体化的所有实例之间共享;同样,它还将在针对 double 具体化的所有实例之间共享,且与针对 int 具体化的实例无关。换句话说,可以认为编译器创建了两个版本的 x:x_int 用于针对 int 具体化的实例,而 x_double 针对 double 具体化的实例。
#include<iostream>
#include<tuple>
#include<string>usingnamespacestd;template<typenametupleType>voidDisplayTupleInfo(tupleType&tup){constintnumMembers=tuple_size<tupleType>::value;cout<<"Num elements in tuple: "<<numMembers<<endl;cout<<"Last element value: "<<get<numMembers-1>(tup)<<endl;}intmain(){tuple<int,char,string>tup1(make_tuple(101,'s',"Hello Tuple!"));DisplayTupleInfo(tup1);autotup2(make_tuple(3.14,false));DisplayTupleInfo(tup2);autoconcatTup(tuple_cat(tup2,tup1));// contains tup2, tup1 membersDisplayTupleInfo(concatTup);doublepi;stringsentence;tie(pi,ignore,ignore,ignore,sentence)=concatTup;cout<<"Unpacked! Pi: "<<pi<<" and \""<<sentence<<"\""<<endl;return0;}
static_assert不满足条件直接禁止编译
static_assert 是 C++11 新增的一项功能,让您能够在不满足指定条件时禁止编译。这好像不可思议,但对模板类来说很有用。例如,您可能想禁止针对 int 实例化模板类,为此可使用 static_assert,它是一种编译阶段断言,可用于在开发环境(或控制台中)显示一条自定义消息。
template<typenameT>classEverythingButInt{public:EverythingButInt(){static_assert(sizeof(T)!=sizeof(int),"No int please!");}};intmain(){EverythingButInt<int>test;return0;}
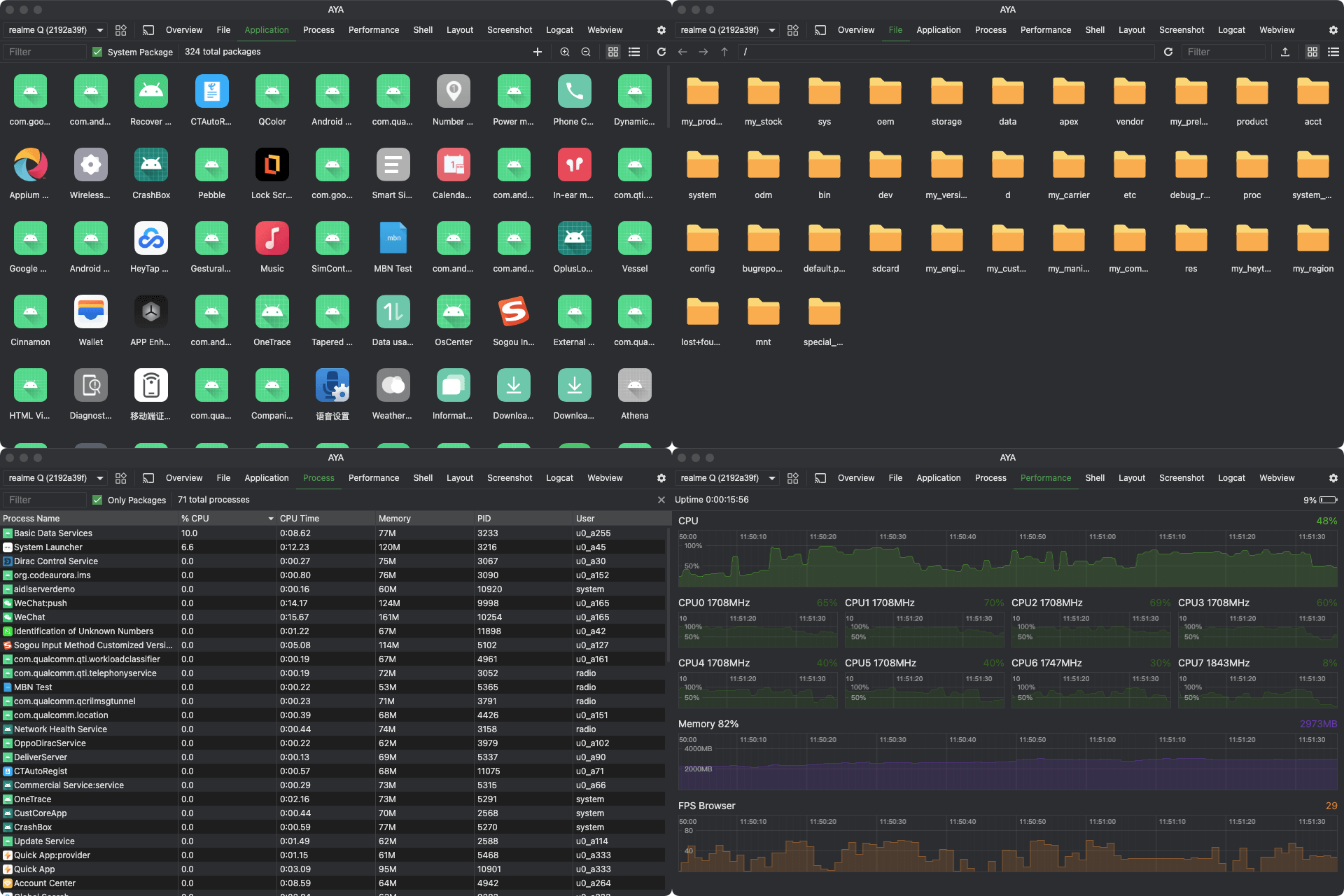
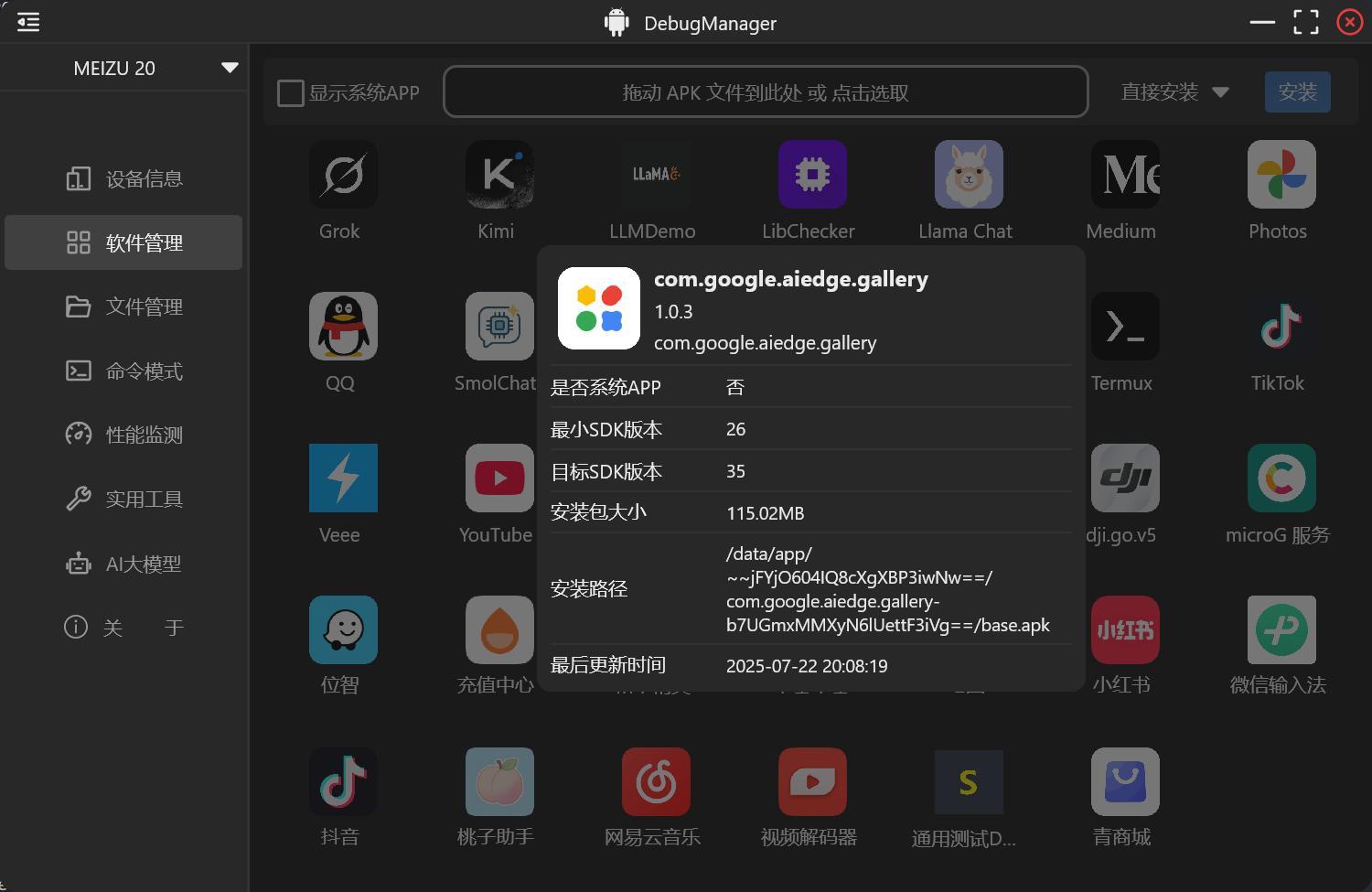
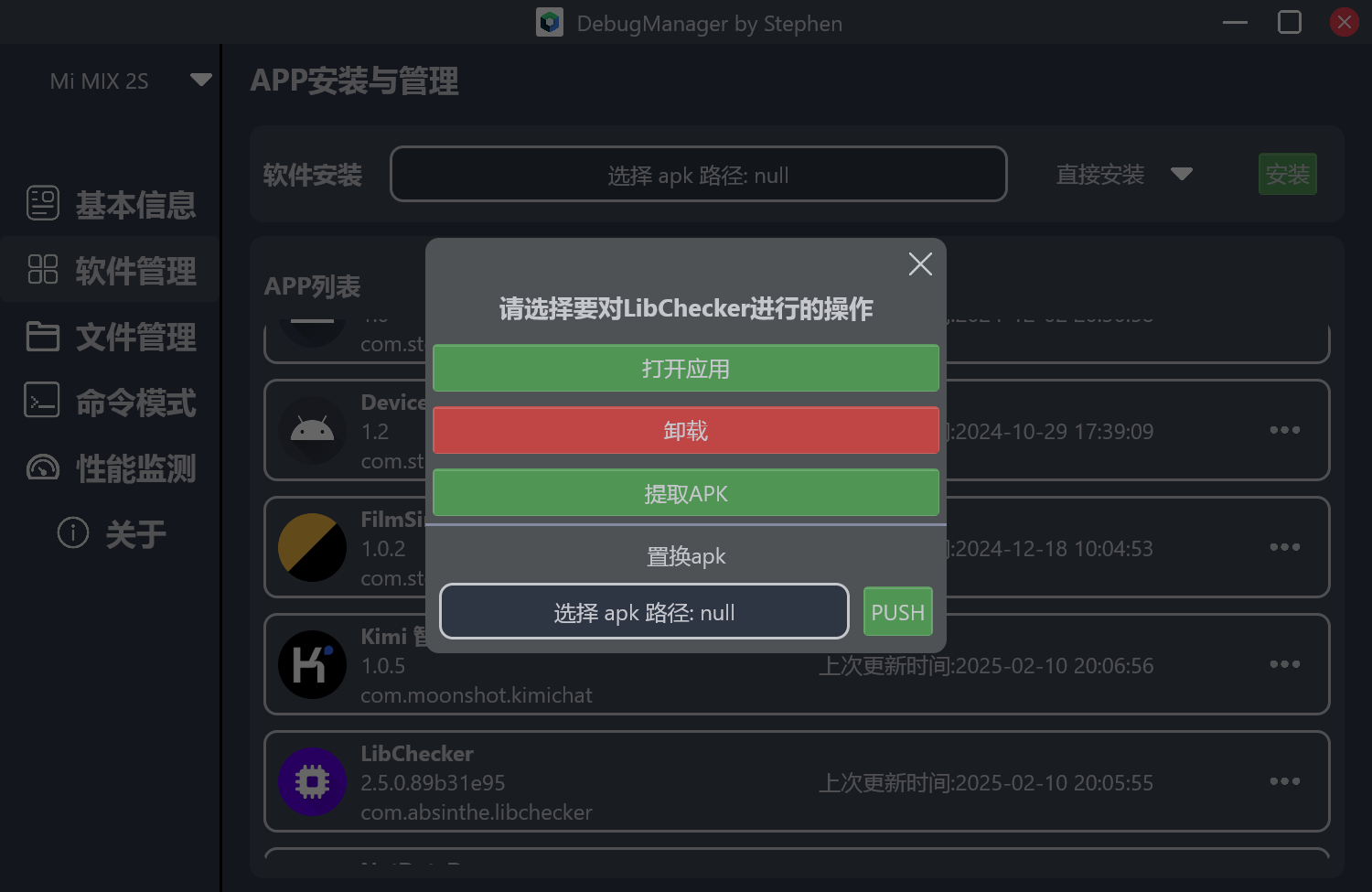
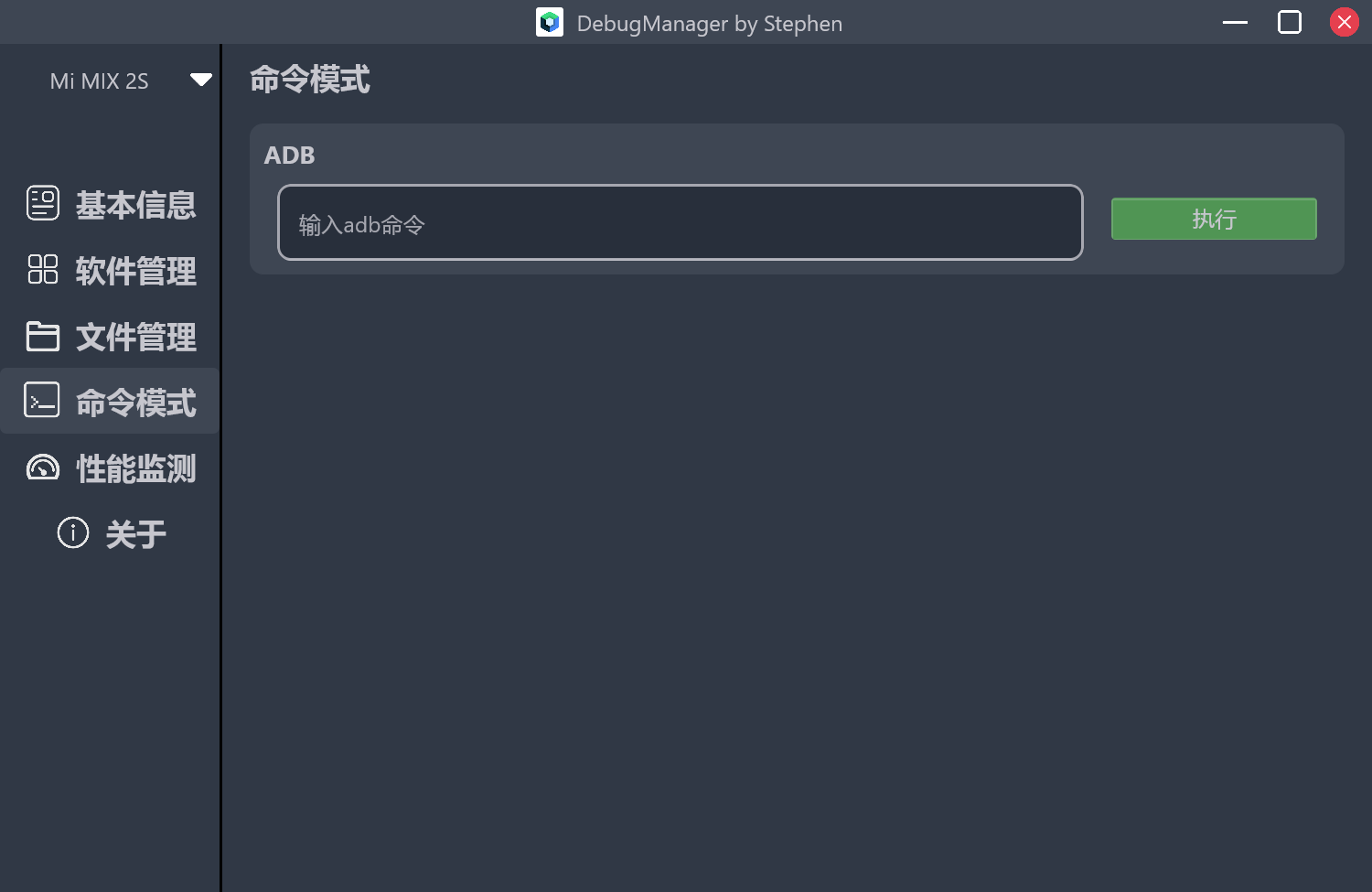
在面对更普遍的手机端的应用管理功能时,我发现了没有系统签名的应用,是不可以直接使用 am startservice 命令来拉起服务的。而且不同手机平台还有权限上面的区别,比如类原生的系统上(Pixel平台,LineageOS),是不用动态申请就可以获取安装的应用信息,但是在国产OS上,有更严格的管理,需要处理读取应用列表权限。
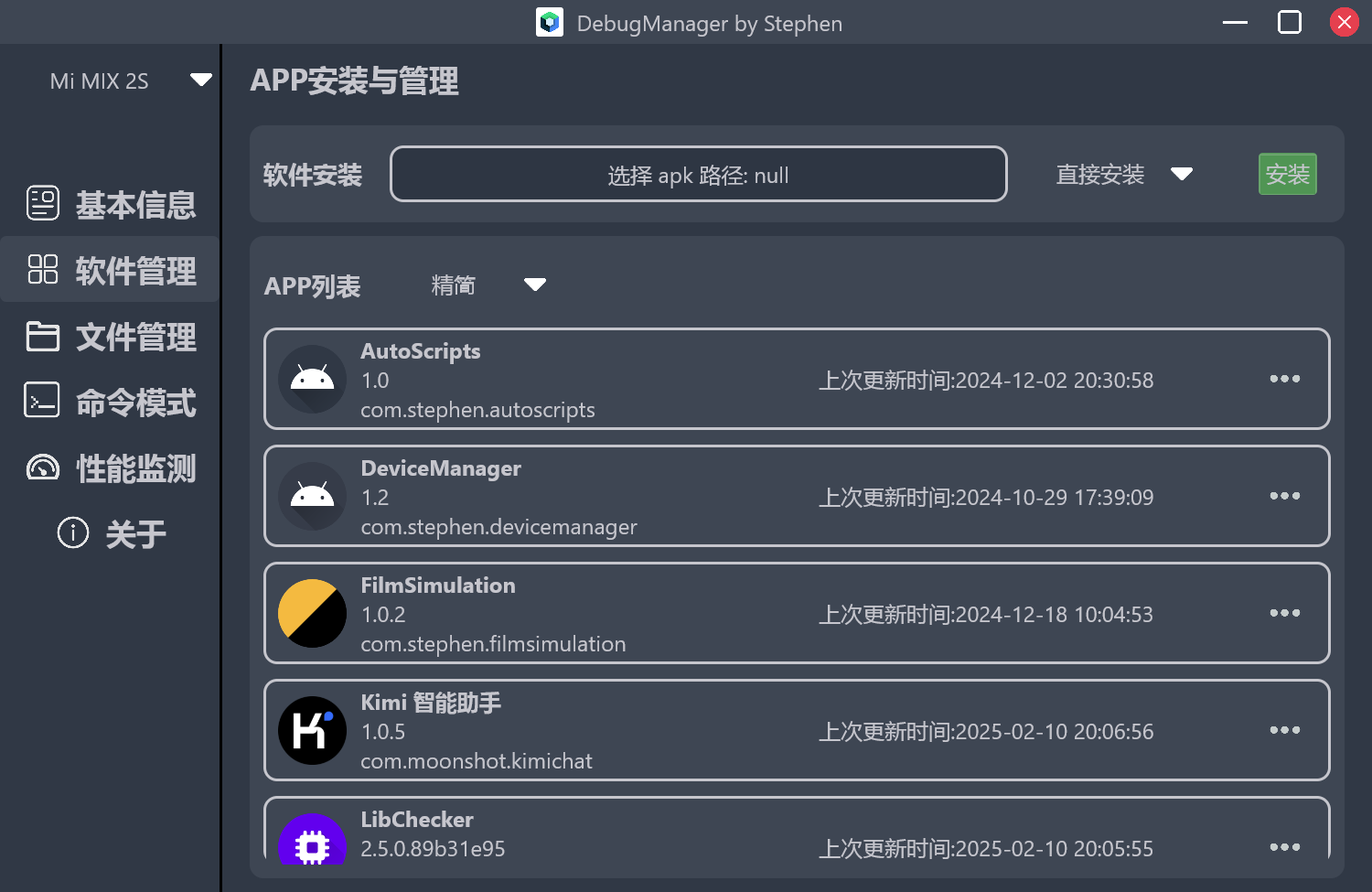
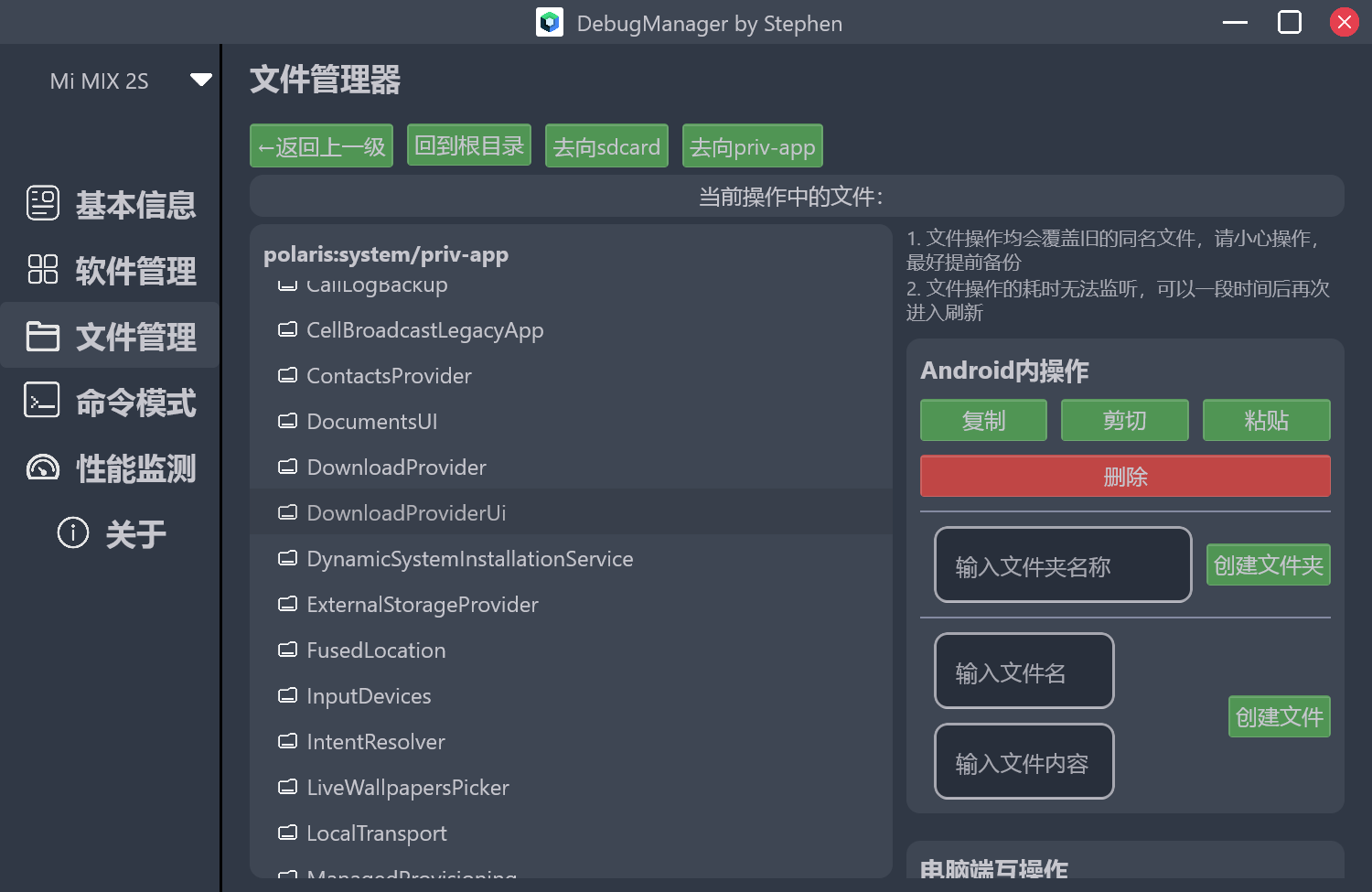
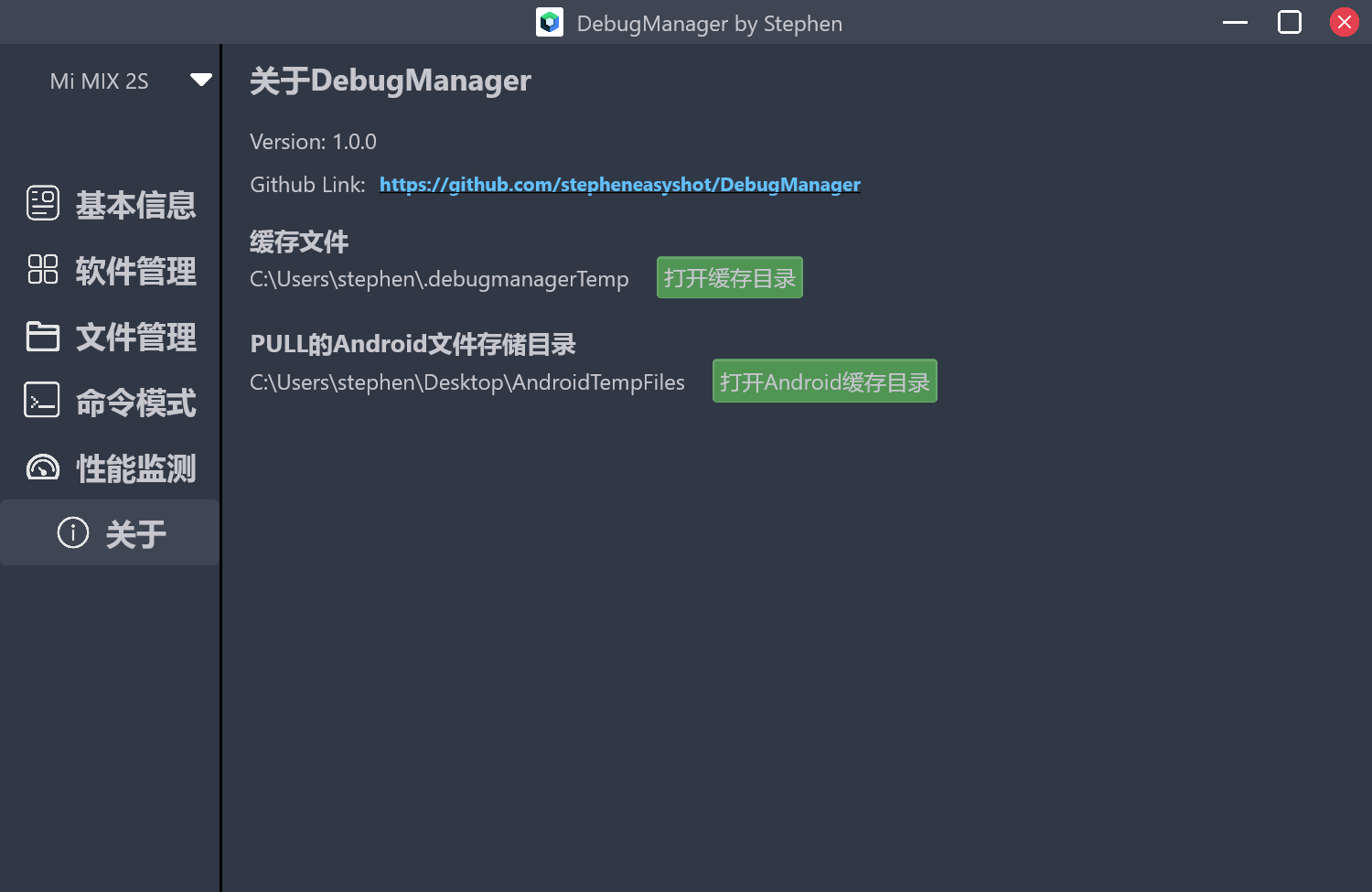
在我们日常的开发过程中,对于车机设备的adb调试操作很多,一大半全是固定的流程。使用bat脚本的话又不那么灵活,体验也不好。所以我很早就想要做一个带界面的Android设备调试工具。在移动端上写纯原生的Compose界面比较熟悉了,想着这个估计也差不多的,就开启了为期一个多月的Compose for Desktop开发。开发体验可以算中上,很多的问题在stackoverflow和官网上都能找到方案。软件命名为DebugManager。
在界面UI设计风格上,我是直接参考了每天打开的 Android Studio 里的主题插件, Atom One Dark 的颜色风格。
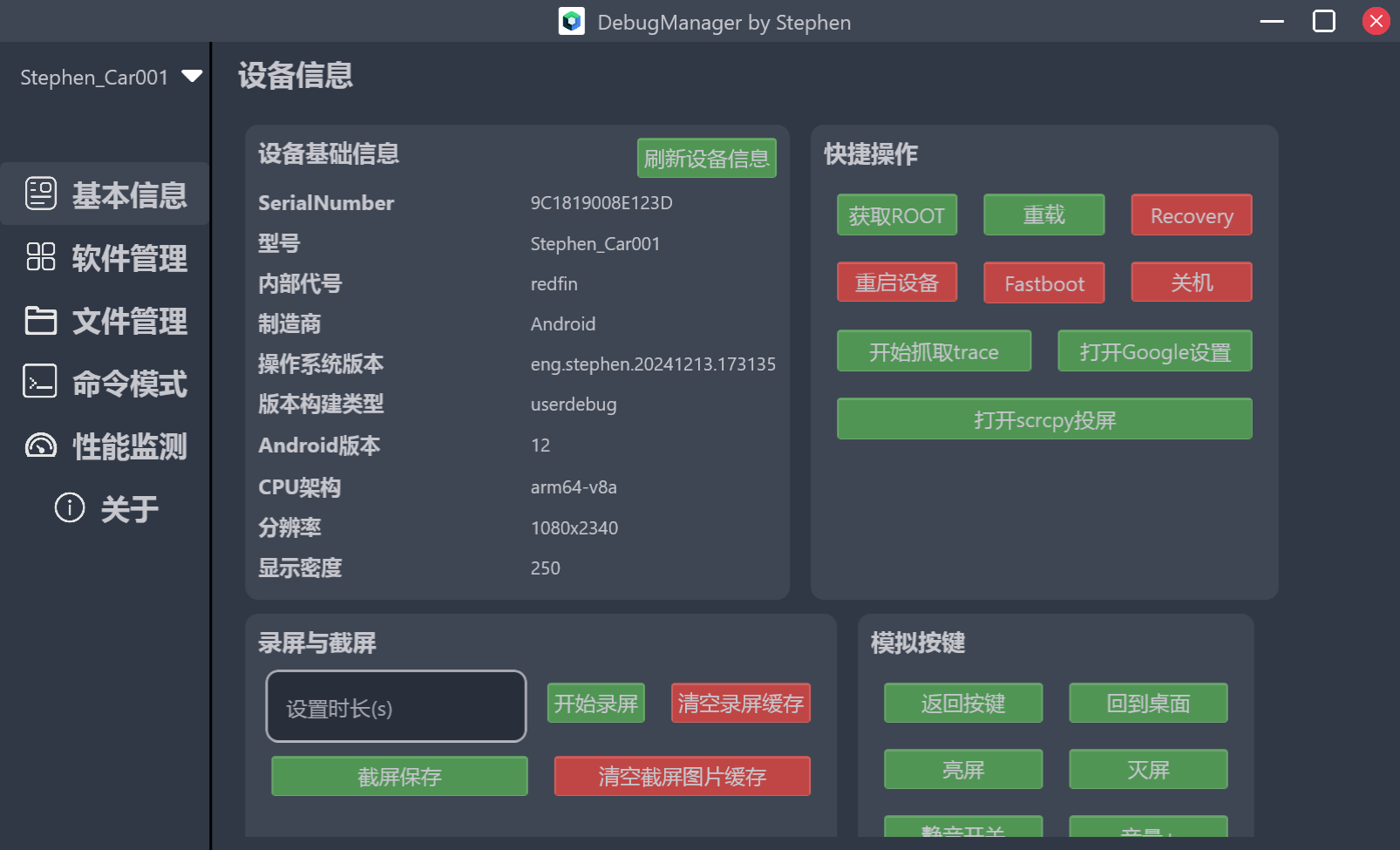
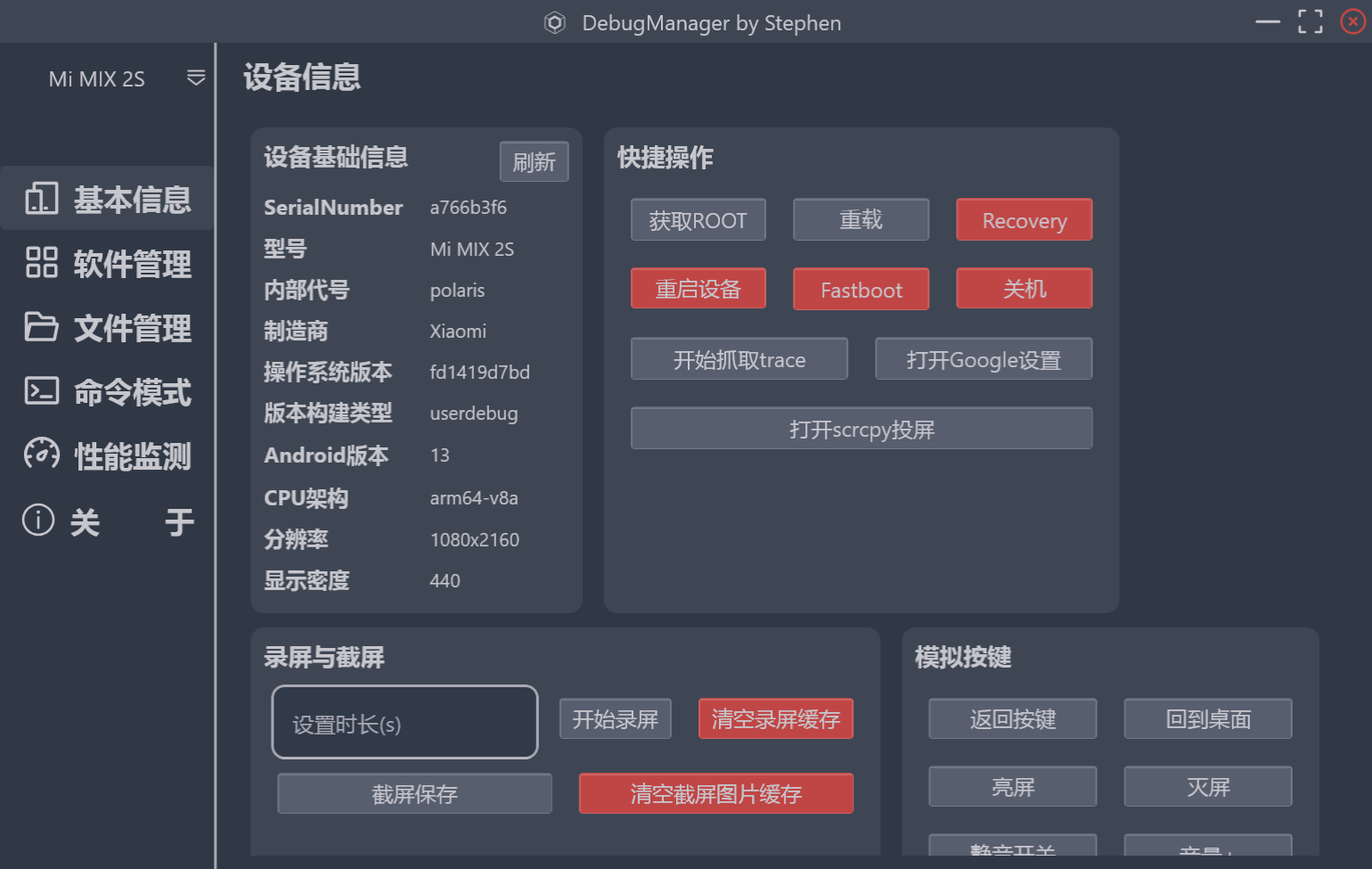
设备信息展示
一进入界面,首页当然是所连接设备的基本信息展示。
大致的实现思路如下,关于界面状态,先定义 UiState :
data classDeviceState(valname:String?=null,valmanufacturer:String?=null,valsdkVersion:String?=null,valsystemVersion:String?=null,valbuildType:String?=null,valinnerName:String?=null,valresolution:String?=null,valdensity:String?=null,valcpuArch:String?=null,valserial:String?=null,valisConnected:Boolean=false){funtoUiState()=DeviceState(name=name,systemVersion=systemVersion,manufacturer=manufacturer,sdkVersion=sdkVersion,buildType=buildType,innerName=innerName,resolution=resolution,cpuArch=cpuArch,density=density,serial=serial,isConnected=isConnected)}