ANR是Android系统上,应用交互过程中可能出现的最差的体验了,它代表了应用程序已经经历了 长时间无响应,并导致崩溃 。
当应用程序的主线程被冻结,导致应用程序无法响应用户输入时,就会发生 ANR。届时,系统将弹出一个 ANR对话框 ,提示用户是等待还是强制关闭应用程序。
ANR本身是一套兜底机制,它监控Android应用响应是否及时。
我们可以把发生ANR比作是引爆炸弹,那么整个流程包含三部分组成:
埋定时炸弹:中控系统(system_server进程)启动倒计时,在规定时间内如果目标(应用进程)没有干完所有的活,则中控系统会定向炸毁(杀进程)目标。 拆炸弹:在规定的时间内干完工地的所有活,并及时向中控系统报告完成,请求解除定时炸弹,则幸免于难。 引爆炸弹:中控系统立即封装现场,抓取快照,搜集目标执行慢的罪证(traces),便于后续的案件侦破(调试分析),最后是炸毁目标。 常见的ANR类型有service、broadcast、provider以及input.
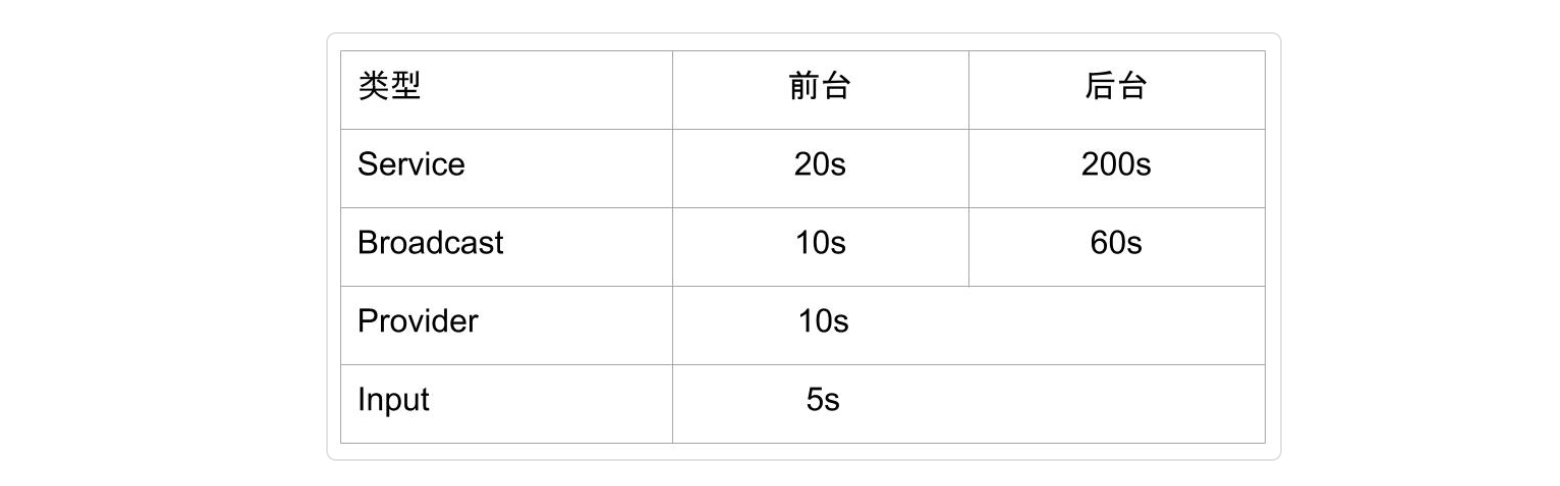
各个ANR类型的超时时间阈值如下:
可以看到,ANR的判定时间和前台后台强相关,差距很大,通常在前台的app会有更严格的限制。
那么Android系统是如何划分前台后台应用的?
前台后台 如果满足以下任一条件,则进程会被认为位于前台。
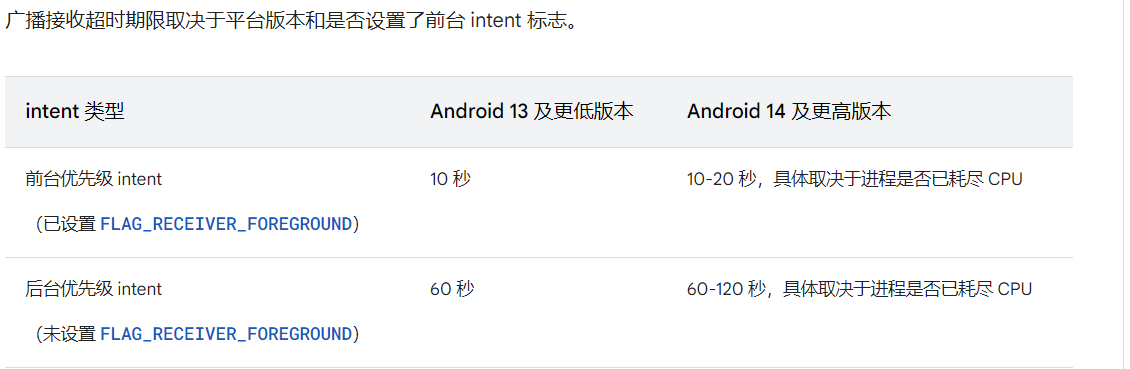
正在用户的互动屏幕上运行一个 Activity(其 onResume() 方法已被调用)。 有一个 BroadcastReceiver 目前正在运行(其 BroadcastReceiver.onReceive() 方法正在执行) 有一个 Service 目前正在执行其某个回调(Service.onCreate()、Service.onStart() 或 Service.onDestroy())中的代码。 输入事件耗时 Google总结有如下几种常见的情况:
原因 出现的情况 建议的解决方法 binder 调用缓慢 主线程 binder 调用缓慢 将该调用移出主线程或尝试优化该调用(如果您拥有该 API)。 连续多次进行 binder 调用 主线程连续多次进行 binder 调用 请勿在紧密循环中执行 binder 调用。 阻塞 I/O 主线程阻塞 I/O,例如数据库或网络访问。 将所有阻塞 IO 移出主线程。 锁争用 主线程处于阻塞状态,正在等待获取锁。 减少主线程和其他线程之间的锁争用。 优化其他线程中运行缓慢的代码。 耗用大量资源的帧 单个帧中的渲染工作量太大,导致严重卡顿。 减少帧渲染工作。请勿使用 n2 算法。使用高效的组件实现滚动或分页等操作,例如使用 Jetpack Paging 库。 被其他组件阻塞 另一个组件(如广播接收器)正在运行并阻塞主线程。 尽可能将非界面工作移出主线程。在其他线程上运行广播接收器。 GPU 挂起 GPU 挂起是系统或硬件问题,会导致渲染被阻塞,进而导致输入调度 ANR。 遗憾的是,通常无法在应用端解决这些问题。如有可能,请与硬件团队联系来排查问题。
例如:
System.Settings系统数据库的写操作 System.Settings 涉及到对系统级配置的修改,这些操作可能需要:
磁盘 I/O 操作: 写入设置需要将数据持久化到存储中。磁盘 I/O 可能是阻塞性的,尤其是在设备性能不佳、存储空间紧张或有其他高负载操作时。 进程间通信 (IPC): System.Settings 的修改通常需要通过 Binder 机制与系统服务进行通信。如果系统服务繁忙或响应缓慢,主线程可能会被阻塞。 并发访问: 如果有多个线程或进程同时尝试写入或读取 System.Settings,可能会导致锁竞争,从而阻塞主线程。 权限检查: 写入某些 System.Settings 值需要特定的权限(例如 WRITE_SETTINGS),系统在执行操作前会进行权限验证,这也会占用一定时间。 生命周期回调里做了耗时操作 Android 的生命周期函数(如 onCreate()、onResume()、onPause()、onDestroy() 等)都是在主线程上调用的。它们的职责是快速完成 UI 初始化、数据加载、状态保存等轻量级任务,以便应用能够迅速响应用户操作并呈现界面。如果在这些函数中执行以下类型的耗时操作,就会阻塞主线程,导致 ANR。
常见的可能导致ANR的操作:
1. onCreate() 中进行耗时操作 场景: 在 onCreate() 中加载大量数据、进行复杂的数据库查询、或执行网络请求。ANR 原因: 应用启动时,onCreate() 需要快速完成,才能显示第一个界面。如果耗时过长,用户将看到黑屏或卡顿,并最终收到 ANR 提示。解决方案: 数据加载和网络请求: 将这些操作移动到后台线程 中执行。Kotlin Coroutines (协程): 推荐使用,利用 Dispatchers.IO 或 Dispatchers.Default。Java ExecutorService / Thread: 手动管理线程池。Android Architecture Components (如 Room, ViewModel): 配合 LiveData 或 Flow,在 ViewModel 中处理数据逻辑,然后在 UI 线程观察数据变化。UI 初始化: 仅在 onCreate() 中进行必要的 UI 视图膨胀和组件绑定。2. onResume() 中进行耗时操作 场景: 在 onResume() 中刷新大量数据、注册耗时监听器。ANR 原因: 当 Activity 从后台回到前台,或从部分遮盖状态恢复时,会调用 onResume()。如果这里有耗时操作,用户会感到界面卡顿,无法立即与应用交互。解决方案: 同 onCreate(),将耗时操作放到后台线程 。 考虑使用 懒加载 (Lazy Loading) 或按需加载 策略,只加载屏幕可见部分的数据。 3. onPause() / onStop() 中进行耗时操作 场景: 在 onPause() 或 onStop() 中保存大量数据到磁盘、执行复杂的数据库事务。ANR 原因: 当用户离开当前 Activity (例如,按下 Home 键、切换到其他应用、或者启动新的 Activity) 时,系统会调用 onPause() 和 onStop()。这些方法需要迅速完成,以便系统能够释放资源或切换到其他应用。如果耗时过长,系统可能认为当前应用卡死,导致 ANR。解决方案: 数据保存: 将耗时的数据持久化操作(如数据库写入、文件写入)移至后台线程 。小量数据: 对于少量非关键数据,可以使用 SharedPreferences.apply() (异步写入) 而不是 SharedPreferences.commit() (同步写入)。复杂的保存逻辑: 考虑使用 WorkManager 来调度后台任务进行数据同步或上传。注意: 尽管 onPause() 和 onStop() 应该快速完成,但它们是保存用户状态的关键时机。务必确保重要数据的保存,即使将其推迟到后台线程,也要确保任务的可靠性。4. onDestroy() 中进行耗时操作 场景: 在 onDestroy() 中释放大量资源、关闭文件句柄、清理缓存等。ANR 原因: 当 Activity 被销毁时调用。虽然此时应用可能即将退出,但如果 onDestroy() 阻塞,也可能导致系统资源长时间不释放,甚至在特定情况下触发 ANR。解决方案: 资源释放: 大多数资源释放(如 MediaPlayer.release()、大图片 Bitmap 释放)可以放在主线程,但如果涉及到大量文件 I/O 或网络断开连接的阻塞,仍应考虑放在后台线程 。清理工作: 确保清理工作简洁高效。广播接收器超时 接收到广播之后,如果在一定时间内没有执行完onReceive,也会被判定为ANR。
goAsync的作用 广播接收器 goAsync() 的用处,简单说就是手动地拖延onReceive执行的时间到子线程结束后。
所以使用的时机就是我们需要在接收到广播之后,开子线程处理耗时任务的时候。广播接收器接收到广播后,开始执行onReceive的方法,这时候进程是前台状态,一旦走完,又会恢复到后台的状态。如果在onReceive回调里直接开子线程,那么onReceive走完后,进程优先级较低,其内的线程优先级也较低,可能任务没有执行完就结束了。分析onReceive源码,可以看到在其结束时,会检查 PendingResult 的状态,如果不为空就表明任务执行完毕。也就恢复到了后台状态。
goAsync() 方法就是将 PendingResult设置为 null,也就不会马上结束掉当前的广播,相当于 “延长了广播的生命周期”,让广播依然处于活跃状态。在子线程的任务执行完毕,再调用一次 PendingResult.finish(),结束onReceive方法的计时。
所以广播接收器ANR的情况就是onReceive方法超时,或者goAsync方法调用完之后,超时时间内没有调用finish。
Service执行超时 onCreate(),onStartCommand(),onBind() 等生命周期在20s内没有处理完成,就会发生ANR。
ANR日志分析 原生位置一般在 /data/anr/ 目录下:
husky:/ $ cd data/anr
husky:/data/anr $ ls
anr_2025-06-25-15-48-12-221 anr_2025-06-25-15-54-17-222 anr_2025-06-25-16-51-03-671 anr_2025-06-25-16-52-33-144
anr_2025-06-25-15-50-25-017 anr_2025-06-25-16-14-41-452 anr_2025-06-25-16-51-21-354
anr_2025-06-25-15-51-11-474 anr_2025-06-25-16-15-16-616 anr_2025-06-25-16-51-58-524
husky:/data/anr $
基于AOSP定制后的系统,如果对ANR日志输出位置有优化,可能为其自定的位置。
一般来说,文件首行就会表明ANR的类型:
输入事件超时未处理
Subject: Input dispatching timed out 。。。。
广播接收器处理超时
Subject: Broadcast of Intent { act=android.intent.action.SCREEN_ON flg=0x50200010 }
Service超时
Subject: executing service com.stephen.commondemo/.anr.AnrService
ContentProvider超时
日志关键字:timeout publishing content providers
分析步骤 首先我们搜索am_anr,找到出现ANR的时间点、进程PID、ANR类型、然后再找搜索PID,找前5秒左右的日志。 过滤ANR IN 查看CPU信息 接着查看traces.txt,找到java的堆栈信息定位代码位置,最后查看源码,分析与解决问题。 分析举例
场景一 07-20 15:36:36.472 1000 1520 1597 I am_anr : [0,1480,com.xxxx.moblie,952680005,Input dispatching timed out (AppWindowToken{da8f666 token=Token{5501f51 ActivityRecord{15c5c78 u0 com.xxxx.moblie/.ui.MainActivity t3862}}}, Waiting because no window has focus but there is a focused application that may eventually add a window when it finishes starting up.)]
ANR时间:07-20 15:36:36.472 进程pid:1480 进程名:com.xxxx.moblie ANR类型:KeyDispatchTimeout
我们已经知道了发生KeyDispatchTimeout的ANR是因为 input事件在5秒内没有处理完成。那么在这个时间07-20 15:36:36.472 的前5秒,也就是(15:36:30 ~15:36:31)时间段左右程序到底做了什么事情?
场景二 07-20 15:36:58.711 1000 1520 1597 E ActivityManager: ANR in com.xxxx.moblie (com.xxxx.moblie/.ui.MainActivity) (关键字ANR in + 进程名 + Activity名称)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: PID: 1480 (进程pid)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: Reason: Input dispatching timed out (AppWindowToken{da8f666 token=Token{5501f51 ActivityRecord{15c5c78 u0 com.xxxx.moblie/.ui.MainActivity t3862}}}, Waiting because no window has focus but there is a focused application that may eventually add a window when it finishes starting up.)(ANR的原因,输入分发超时)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: Load: 0.0 / 0.0 / 0.0 (Load表明是1分钟,5分钟,15分钟CPU的负载)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: CPU usage from 20ms to 20286ms later (2018-07-20 15:36:36.170 to 2018-07-20 15:36:56.436):
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 42% 6774/pressure: 41% user + 1.4% kernel / faults: 168 minor
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 34% 142/kswapd0: 0% user + 34% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 31% 1520/system_server: 13% user + 18% kernel / faults: 58724 minor 1585 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 13% 29901/com.ss.android.article.news: 7.7% user + 6% kernel / faults: 56007 minor 2446 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 13% 32638/com.android.quicksearchbox: 9.4% user + 3.8% kernel / faults: 48999 minor 1540 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 11% (CPU的使用率)1480/com.xxxx.moblie: 5.2%(用户态的使用率) user + (内核态的使用率) 6.3% kernel / faults: 76401 minor 2422 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 8.2% 21000/kworker/u16:12: 0% user + 8.2% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 0.8% 724/mtd: 0% user + 0.8% kernel / faults: 1561 minor 9 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 8% 29704/kworker/u16:8: 0% user + 8% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.9% 24391/kworker/u16:18: 0% user + 7.9% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.1% 30656/kworker/u16:14: 0% user + 7.1% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.1% 9998/kworker/u16:4: 0% user + 7.1% kernel
通过上面所提供的案例我们可以分析出以下几点:
ANR发生的位置是:com.xxxx.moblie/.ui.MainActivity com.xxxx.moblie 占用了11%的CPU,CPU的使用率并不是很高,基本可以排除CPU负载的原因 Reason提示我们是输入分发超时导致的ANR 通过上面几点我们虽然排除了CPU过度负载的可能,但我们并不能准确定位出ANR的确切位置,要想准确定位出ANR发生的确切位置,就要借助系统为了解决ANR问题而提供的终极大杀器——traces.txt文件了。 找到anr目录下的trace.txt trace:
Cmd line:com.xxxx.moblie
"main" prio=5 tid=1 Runnable
| group="main" sCount=0 dsCount=0 obj=0x73bcc7d0 self=0x7f20814c00
| sysTid=20176 nice=-10 cgrp=default sched=0/0 handle=0x7f251349b0
| state=R schedstat=( 0 0 0 ) utm=12 stm=3 core=5 HZ=100
| stack=0x7fdb75e000-0x7fdb760000 stackSize=8MB
| held mutexes= "mutator lock"(shared held)
// java 堆栈调用信息,可以查看调用的关系,定位到具体位置
at ttt.push.InterceptorProxy.addMiuiApplication(InterceptorProxy.java:77)
at ttt.push.InterceptorProxy.create(InterceptorProxy.java:59)
at android.app.Activity.onCreate(Activity.java:1041)
at miui.app.Activity.onCreate(SourceFile:47)
at com.xxxx.moblie.ui.b.onCreate(SourceFile:172)
at com.xxxx.moblie.ui.MainActivity.onCreate(SourceFile:68)
at android.app.Activity.performCreate(Activity.java:7050)
at android.app.Instrumentation.callActivityOnCreate(Instrumentation.java:1214)
at android.app.ActivityThread.performLaunchActivity(ActivityThread.java:2807)
at android.app.ActivityThread.handleLaunchActivity(ActivityThread.java:2929)
at android.app.ActivityThread.-wrap11(ActivityThread.java:-1)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:1618)
at android.os.Handler.dispatchMessage(Handler.java:105)
at android.os.Looper.loop(Looper.java:171)
at android.app.ActivityThread.main(ActivityThread.java:6699)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.Zygote$MethodAndArgsCaller.run(Zygote.java:246)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:783)
这里详细解析一下traces.txt里面的一些字段,看看它到底能给我们提供什么信息.
main:main标识是主线程,如果是线程,那么命名成“Thread-X”的格式,x表示线程id,逐步递增。 prio:线程优先级,默认是5 tid:tid不是线程的id,是线程唯一标识ID group:是线程组名称 sCount:该线程被挂起的次数 dsCount:是线程被调试器挂起的次数 obj:对象地址 self:该线程Native的地址 sysTid:是线程号(主线程的线程号和进程号相同) nice:是线程的调度优先级 sched:分别标志了线程的调度策略和优先级 cgrp:调度归属组 handle:线程处理函数的地址。 state:是调度状态 schedstat:从 /proc/[pid]/task/[tid]/schedstat读出,三个值分别表示线程在cpu上执行的时间、线程的等待时间和线程执行的时间片长度,不支持这项信息的三个值都是0; utm:是线程用户态下使用的时间值(单位是jiffies) stm:是内核态下的调度时间值 core:是最后执行这个线程的cpu核的序号。 Java的堆栈信息是我们最关心的,它能够定位到具体位置。从上面的traces,我们可以判断ttt.push.InterceptorProxy.addMiuiApplicationInterceptorProxy.java:77 导致了com.xxxx.moblie发生了ANR。这时候可以对着源码查看,找到出问题,并且解决它。
综合考虑系统侧原因 很多开发者认为,ANR就是耗时操作导致,全部是app应用层的问题。实际上,线上环境大部分ANR由系统原因导致。
应用层导致ANR(耗时操作)
函数阻塞:如死循环、主线程IO、处理大数据 锁出错:主线程等待子线程的锁 内存紧张:系统分配给一个应用的内存是有上限的,长期处于内存紧张,会导致频繁内存交换,进而导致应用的一些操作超时 系统导致ANR
CPU被抢占:一般来说,前台在玩游戏,可能会导致你的后台广播被抢占CPU 系统服务无法及时响应:比如获取系统联系人等,系统的服务都是Binder机制,服务能力也是有限的,有可能系统服务长时间不响应导致ANR 其他应用占用的大量内存 日志案例分析 下列案例信息来自vivo团队 ,原文:
干货:ANR日志分析全面解析
堆栈信息:主线程未卡死 "main" prio=5 tid=1 Native
| group="main" sCount=1 dsCount=0 flags=1 obj=0x74b38080 self=0x7ad9014c00
| sysTid=23081 nice=0 cgrp=default sched=0/0 handle=0x7b5fdc5548
| state=S schedstat=( 284838633 166738594 505 ) utm=21 stm=7 core=1 HZ=100
| stack=0x7fc95da000-0x7fc95dc000 stackSize=8MB
| held mutexes=
kernel: __switch_to+0xb0/0xbc
kernel: SyS_epoll_wait+0x288/0x364
kernel: SyS_epoll_pwait+0xb0/0x124
kernel: cpu_switch_to+0x38c/0x2258
native: #00 pc 000000000007cd8c /system/lib64/libc.so (__epoll_pwait+8)
native: #01 pc 0000000000014d48 /system/lib64/libutils.so (android::Looper::pollInner(int)+148)
native: #02 pc 0000000000014c18 /system/lib64/libutils.so (android::Looper::pollOnce(int, int*, int*, void**)+60)
native: #03 pc 00000000001275f4 /system/lib64/libandroid_runtime.so (android::android_os_MessageQueue_nativePollOnce(_JNIEnv*, _jobject*, long, int)+44)
at android.os.MessageQueue.nativePollOnce(Native method)
at android.os.MessageQueue.next(MessageQueue.java:330)
at android.os.Looper.loop(Looper.java:169)
at android.app.ActivityThread.main(ActivityThread.java:7073)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:536)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:876)
上述主线程堆栈就是一个很正常的空闲堆栈,表明 主线程正在等待新的消息 。可能为CPU抢占或内存问题导致的,等抓取trace时已经恢复正常。
堆栈信息:主线程执行耗时操作 "main" prio=5 tid=1 Runnable
| group="main" sCount=0 dsCount=0 flags=0 obj=0x72deb848 self=0x7748c10800
| sysTid=8968 nice=-10 cgrp=default sched=0/0 handle=0x77cfa75ed0
| state=R schedstat=( 24783612979 48520902 756 ) utm=2473 stm=5 core=5 HZ=100
| stack=0x7fce68b000-0x7fce68d000 stackSize=8192KB
| held mutexes= "mutator lock"(shared held)
at com.example.test.MainActivity$onCreate$2.onClick(MainActivity.kt:20)——关键行!!!
at android.view.View.performClick(View.java:7187)
at android.view.View.performClickInternal(View.java:7164)
at android.view.View.access$3500(View.java:813)
at android.view.View$PerformClick.run(View.java:27640)
at android.os.Handler.handleCallback(Handler.java:883)
at android.os.Handler.dispatchMessage(Handler.java:100)
at android.os.Looper.loop(Looper.java:230)
at android.app.ActivityThread.main(ActivityThread.java:7725)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:526)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1034)
上述日志表明,主线程正处于执行状态,看堆栈信息可知不是处于空闲状态,发生ANR是因为一处click监听函数里执行了耗时操作。
堆栈信息:主线程被锁阻塞 "main" prio=5 tid=1 Blocked
| group="main" sCount=1 dsCount=0 flags=1 obj=0x72deb848 self=0x7748c10800
| sysTid=22838 nice=-10 cgrp=default sched=0/0 handle=0x77cfa75ed0
| state=S schedstat=( 390366023 28399376 279 ) utm=34 stm=5 core=1 HZ=100
| stack=0x7fce68b000-0x7fce68d000 stackSize=8192KB
| held mutexes=
at com.example.test.MainActivity$onCreate$1.onClick(MainActivity.kt:15)
- waiting to lock <0x01aed1da> (a java.lang.Object) held by thread 3 ——————关键行!!!
at android.view.View.performClick(View.java:7187)
at android.view.View.performClickInternal(View.java:7164)
at android.view.View.access$3500(View.java:813)
at android.view.View$PerformClick.run(View.java:27640)
at android.os.Handler.handleCallback(Handler.java:883)
at android.os.Handler.dispatchMessage(Handler.java:100)
at android.os.Looper.loop(Looper.java:230)
at android.app.ActivityThread.main(ActivityThread.java:7725)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:526)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1034)
........省略N行.....
"WQW TEST" prio=5 tid=3 TimeWating
| group="main" sCount=1 dsCount=0 flags=1 obj=0x12c44230 self=0x772f0ec000
| sysTid=22938 nice=0 cgrp=default sched=0/0 handle=0x77391fbd50
| state=S schedstat=( 274896 0 1 ) utm=0 stm=0 core=1 HZ=100
| stack=0x77390f9000-0x77390fb000 stackSize=1039KB
| held mutexes=
at java.lang.Thread.sleep(Native method)
- sleeping on <0x043831a6> (a java.lang.Object)
at java.lang.Thread.sleep(Thread.java:440)
- locked <0x043831a6> (a java.lang.Object)
at java.lang.Thread.sleep(Thread.java:356)
at com.example.test.MainActivity$onCreate$2$thread$1.run(MainActivity.kt:22)
- locked <0x01aed1da> (a java.lang.Object)————————————————————关键行!!!
at java.lang.Thread.run(Thread.java:919)
这是一个典型的主线程被锁阻塞的例子;
其中等待的锁是 <0x01aed1da> ,这个锁的持有者是线程 3。进一步搜索 “tid=3” 找到线程3, 发现它正在TimeWating。
那么ANR的原因找到了:线程3持有了一把锁,并且自身长时间不释放,主线程等待这把锁发生超时。在线上环境中,常见因锁而ANR的场景是SharePreference写入。比如两个线程都在等待另一个写入完成释放自己需要的锁,导致死锁。
CPU被抢占 CPU usage from 0ms to 10625ms later (2020-03-09 14:38:31.633 to 2020-03-09 14:38:42.257):
543% 2045/com.alibaba.android.rimet: 54% user + 89% kernel / faults: 4608 minor 1 major ————关键行!!!
99% 674/android.hardware.camera.provider@2.4-service: 81% user + 18% kernel / faults: 403 minor
24% 32589/com.wang.test: 22% user + 1.4% kernel / faults: 7432 minor 1 major
........省略N行.....
如上日志,第二行是钉钉的进程,占据CPU高达543%,抢占了大部分CPU资源,因而导致发生ANR。
内存紧张导致ANR 如果有一份日志,CPU和堆栈都很正常(不贴出来了),仍旧发生ANR,考虑是内存紧张。
从CPU第一行信息可以发现,ANR的时间点是2020-10-31
22:38:58.468—CPU usage from 0ms to 21752ms later (2020-10-31 22:38:58.468 to 2020-10-31 22:39:20.220)
接着去logcat里搜索am_meminfo, 这个没有搜索到。再次搜索onTrimMemory,果然发现了很多条记录;
10-31 22:37:19.749 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
10-31 22:37:33.458 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
10-31 22:38:00.153 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
10-31 22:38:58.731 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
10-31 22:39:02.816 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
可以看出,在发生ANR的时间点前后,内存都处于紧张状态,level等级是80,查看Android API 文档;
可知80这个等级是很严重的,应用马上就要被杀死,被杀死的这个应用从名字可以看出来是桌面,连桌面都快要被杀死,那普通应用能好到哪里去呢?
一般来说,发生内存紧张,会导致多个应用发生ANR,所以在日志中如果发现有多个应用一起ANR了,可以初步判定,此ANR与你的应用无关。
系统服务超时导致ANR 系统服务超时一般会包含BinderProxy.transactNative关键字,请看如下日志:
"main" prio=5 tid=1 Native
| group="main" sCount=1 dsCount=0 flags=1 obj=0x727851e8 self=0x78d7060e00
| sysTid=4894 nice=0 cgrp=default sched=0/0 handle=0x795cc1e9a8
| state=S schedstat=( 8292806752 1621087524 7167 ) utm=707 stm=122 core=5 HZ=100
| stack=0x7febb64000-0x7febb66000 stackSize=8MB
| held mutexes=
kernel: __switch_to+0x90/0xc4
kernel: binder_thread_read+0xbd8/0x144c
kernel: binder_ioctl_write_read.constprop.58+0x20c/0x348
kernel: binder_ioctl+0x5d4/0x88c
kernel: do_vfs_ioctl+0xb8/0xb1c
kernel: SyS_ioctl+0x84/0x98
kernel: cpu_switch_to+0x34c/0x22c0
native: #00 pc 000000000007a2ac /system/lib64/libc.so (__ioctl+4)
native: #01 pc 00000000000276ec /system/lib64/libc.so (ioctl+132)
native: #02 pc 00000000000557d4 /system/lib64/libbinder.so (android::IPCThreadState::talkWithDriver(bool)+252)
native: #03 pc 0000000000056494 /system/lib64/libbinder.so (android::IPCThreadState::waitForResponse(android::Parcel*, int*)+60)
native: #04 pc 00000000000562d0 /system/lib64/libbinder.so (android::IPCThreadState::transact(int, unsigned int, android::Parcel const&, android::Parcel*, unsigned int)+216)
native: #05 pc 000000000004ce1c /system/lib64/libbinder.so (android::BpBinder::transact(unsigned int, android::Parcel const&, android::Parcel*, unsigned int)+72)
native: #06 pc 00000000001281c8 /system/lib64/libandroid_runtime.so (???)
native: #07 pc 0000000000947ed4 /system/framework/arm64/boot-framework.oat (Java_android_os_BinderProxy_transactNative__ILandroid_os_Parcel_2Landroid_os_Parcel_2I+196)
at android.os.BinderProxy.transactNative(Native method) ————————————————关键行!!!
at android.os.BinderProxy.transact(Binder.java:804)
at android.net.IConnectivityManager$Stub$Proxy.getActiveNetworkInfo(IConnectivityManager.java:1204)—关键行!
at android.net.ConnectivityManager.getActiveNetworkInfo(ConnectivityManager.java:800)
at com.xiaomi.NetworkUtils.getNetworkInfo(NetworkUtils.java:2)
at com.xiaomi.frameworkbase.utils.NetworkUtils.getNetWorkType(NetworkUtils.java:1)
at com.xiaomi.frameworkbase.utils.NetworkUtils.isWifiConnected(NetworkUtils.java:1)
从堆栈可以看出获取网络信息发生了ANR: getActiveNetworkInfo
前文有讲过:系统的服务都是Binder机制(16个线程),服务能力也是有限的,有可能系统服务长时间不响应导致ANR。如果其他应用占用了所有Binder线程,那么当前应用只能等待。
可进一步搜索:blockUntilThreadAvailable关键字:
at android.os.Binder.blockUntilThreadAvailable(Native method)
如果有发现某个线程的堆栈,包含此字样,可进一步看其堆栈,确定是调用了什么系统服务。此类ANR也是属于系统环境的问题,如果某类型机器上频繁发生此问题,应用层可以考虑规避策略。
冷启动概念和流程 在 Android 应用开发中,冷启动(Cold Start) 是指应用从完全关闭状态(进程不存在)到用户看到第一个界面(通常是 Launcher 或 SplashActivity)的启动过程。
冷启动是用户感知应用性能的关键环节之一,如果冷启动时间过长,会导致用户流失或体验下降。一般的测试流程里,将手指点击图标后,应用首帧显示到屏幕上的时长作为指标,这个比较符合用户的真实体验。
因此,冷启动优化是 Android 性能优化的重要部分。以下是常见的冷启动优化手段,按优化方向分类进行详细说明。
简单来说,冷启动可以分为以下几个阶段:
应用进程创建,系统接收到启动应用的请求后,首先会创建应用的进程(Zygote 进程 fork 出新进程)。应用进程创建后,会初始化 Application 对象,执行 Application.onCreate() 方法。如果在 Application 的 onCreate 中执行了耗时操作(如初始化第三方库、加载大量数据等),会导致冷启动时间变长。然后系统会创建目标 Activity 的实例,并调用其生命周期方法(如 onCreate()、onStart()、onResume())。然后是Activity 的布局加载、视图测量与绘制(Measure、Layout、Draw)。
详细流程可以看这一篇:
Android 冷启动流程分析
优化手段 分析trace文件 首先,采集trace性能文件,查看主要耗时在哪里。
具体的分析流程可以参考:
Android trace文件分析
减少 Application.onCreate() 和 Activity.onCreate() 中的工作量 Application 是应用的入口点,很多开发者会在 Application.onCreate() 中初始化各种第三方库、框架或服务。如果这些初始化操作耗时较长,会直接影响冷启动时间。有些第三方库或服务并不需要在应用启动时立即初始化(如统计 SDK、日志 SDK、推送 SDK 等),可以在应用启动后,真正需要使用这些库时再进行初始化。也可以将非关键的初始化操作移到后台线程中执行。
异步加载,将数据加载、图片处理、网络请求等耗时操作放到后台线程中执行,避免阻塞主线程。可以使用 Kotlin Coroutines、RxJava 或 Executor 来处理异步任务。
优化数据加载,如果需要从本地存储或网络加载数据,只加载初始屏幕所需的数据,而不是一次性加载所有数据。可以考虑分页加载或按需加载。
优化布局和视图层次结构 减少布局的嵌套层级。过深的视图层次会增加测量和绘制时间。
对于简单的线性布局,LinearLayout 和 FrameLayout 通常比 ConstraintLayout 更快。对于复杂布局,ConstraintLayout 可以帮助减少嵌套,从而提升性能。
对于不经常显示或在启动时不需要显示的 UI 部分,可以使用 ViewStub 作为占位符,在需要时再动态加载。这可以减少初始布局的膨胀时间。
同时,减少不必要的背景、重叠视图等,这些都会增加 GPU 的绘制负担。
利用 Android 平台提供的优化工具 Baseline Profiles (基线配置文件),这是 Google 推荐的重要优化手段。Baseline Profiles 可以在首次启动时将代码执行速度提高 30%,使应用启动、屏幕导航、内容滚动等用户交互更加流畅。它通过在编译时优化 DEX 布局来提高启动速度。 App Startup 库,这个库允许你定义一个内容提供者来统一初始化多个组件,而不是为每个组件都定义一个单独的内容提供者,从而显著提高应用启动时间。 R8 优化编译器,启用 R8 的完整模式可以进行更激进的代码优化,包括代码缩减、资源优化、DEX 布局优化等,从而减少应用大小并提高运行时性能,包括启动速度。 图片和资源优化 确保图片大小合适,并进行有效压缩。对于显示在 ImageView 中的图片,将其尺寸调整为与 ImageView 匹配,避免加载过大的图片。
考虑使用 WebP 等高效的图片格式。 使用 Glide、Picasso 等图片加载库在后台线程加载和缓存图片。 如果应用包含大量功能,可以考虑将其拆分为动态模块,按需下载和安装,从而减小初始安装包大小,加快启动速度。 其他技巧 闪屏页优化: 如果使用 Splash 闪屏页,可以在闪屏页显示期间进行一些必要的初始化工作,从而充分利用用户等待的时间。如果应用中注册了多个 ContentProvider,系统会在应用启动时初始化这些 ContentProvider,可能导致冷启动时间变长。可以保留必要的 ContentProvider,移除不必要的 ContentProvider。 同样的,如果应用注册了大量的广播接收器(尤其是静态注册的广播接收器),系统会在应用启动时加载这些接收器,可能导致冷启动时间变长。尽量使用动态注册的广播接收器,避免静态注册。只注册必要的广播接收器,移除不必要的广播接收器。 在冷启动时,如果频繁调用系统服务(如 LocationManager、SensorManager 等),可能会导致系统资源竞争,增加冷启动时间。可以延迟调用系统服务,避免在 Application.onCreate() 或 Activity.onCreate() 中立即调用。或者使用缓存机制,避免重复调用系统服务。 需要注意的是
冷启动优化不能以牺牲功能为代价。例如,延迟初始化某些 SDK 可能会导致功能不可用,需要根据实际场景权衡。 还有,冷启动时间可能因设备性能、系统版本等因素而异。建议在多种设备上进行测试,确保优化效果。 冷启动优化的最终目标是提升用户体验。可以通过启动主题、加载动画等方式掩盖部分初始化时间,提高用户感知的流畅性。 内存 几种引用类型
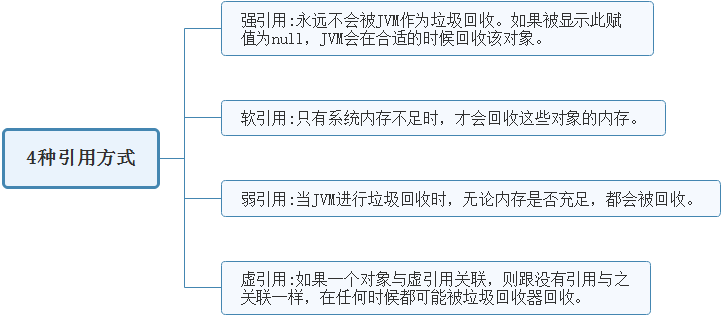
强引用:Object a=new object();Java中采用new关键字创建对象就是一种强引用。对于强引用的对象,就算是出现了OOM也不会对该对象进行回收。在Java中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用。当一个对象被强引用变量引用时,它 处于可达状态 ,它是不可能被垃圾回收机制回收的。 强引用是造成Java内存泄漏的主要原因之一。 对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为null,一般认为就是可以被垃圾收集的了。 软引用:SoftReference<Object> softReference=new SoftReference<>(o1);对于只有软引用的对象来说,当系统内存充足时它不会被回收,当系统内存不足时它会被回收 。软引用通常用在对内存敏感的程序中,比如高速缓存就有用到软引用,内存够用的时候就保留,不够用就回收! 弱引用:WeakReference<Object> weakReference=new WeakReference<>(o1);对于只有弱引用的对象来说,只要垃圾回收机制一运行,不管JVM的内存空间是否足够,都会回收该对象占用的内存。需要使用WeakReference来实现。 虚引用:PhantomReference<Object> phantomReference=new PhantomReference<>(o1,referenceQueue);虚引用是所有引用类型中最弱的一个。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的只是为了能在这个对象被收集器回收时收到一个系统通知 。(虚引用必须和引用队列 (ReferenceQueue)联合使用 )。 内存泄漏 内存泄漏是指在应用程序中,由于某些原因导致不再使用的对象(即垃圾对象)无法被垃圾回收器回收,从而占用了内存空间。内存泄漏可能会导致应用程序的性能下降、内存占用增加,甚至导致应用程序崩溃。
在 Android 开发中,内存泄漏是一个需要特别关注的问题。以下是一些常见的内存泄漏场景:
单例模式引起的内存泄漏 如果单例对象持有了一个生命周期较短的对象的引用,而这个单例的生命周期与整个应用程序的生命周期相同,就可能导致内存泄漏。
public class Singleton {
private static Singleton instance ;
private Context context ;
private Singleton ( Context context ) {
this . context = context ;
}
public static Singleton getInstance ( Context context ) {
if ( instance == null ) {
instance = new Singleton ( context );
}
return instance ;
}
}
在这个单例中,保存了对 Context 的引用。如果传入的是 Activity 的上下文,当 Activity 销毁时,由于单例仍然持有其引用,导致 Activity 无法被回收,从而造成内存泄漏。
解决方案就是尽量使用Application的Context。
非静态内部类引起的内存泄漏 非静态内部类会隐式地持有外部类的引用。如果在外部类(如 Activity)的生命周期内,非静态内部类的实例一直存在,就可能导致外部类无法被回收。在Android开发中,设置的点击监听器,还有Handler等都是常见的非静态内部类的使用场景。
public class MainActivity extends AppCompatActivity {
private Button button ;
@Override
protected void onCreate ( Bundle savedInstanceState ) {
super . onCreate ( savedInstanceState );
setContentView ( R . layout . activity_main );
button = findViewById ( R . id . button );
button . setOnClickListener ( new MyClickListener ());
}
private class MyClickListener implements View . OnClickListener {
@Override
public void onClick ( View v ) {
// 处理点击事件
}
}
}
当 MainActivity 销毁时,由于 MyClickListener 实例持有 MainActivity 的引用,导致 MainActivity 无法被回收。
Handler 引起的内存泄漏 如果在 Activity 中使用 Handler 发送延迟消息,当 Activity 销毁时,消息可能还未被处理,而 Handler 又持有 Activity 的引用,就会导致 Activity 无法被回收。
public class MainActivity extends AppCompatActivity {
private Handler handler = new Handler ();
@Override
protected void onCreate ( Bundle savedInstanceState ) {
super . onCreate ( savedInstanceState );
setContentView ( R . layout . activity_main );
handler . postDelayed ( new Runnable () {
@Override
public void run () {
// 处理延迟任务
}
}, 5000 );
}
}
当 MainActivity 销毁后,由于 Handler 中的延迟任务可能还未执行完毕,导致 MainActivity 无法被回收。
解决方案:
在 Activity 销毁时,及时移除 Handler 中的所有消息。 将Handler改为静态内部类 + WeakReference 来避免内存泄漏。 资源未关闭引起的内存泄漏 例如,对数据库、文件流、网络连接等资源未及时关闭,可能导致资源对象一直被持有,从而造成内存泄漏。
public class MainActivity extends AppCompatActivity {
private SQLiteDatabase database ;
@Override
protected void onCreate ( Bundle savedInstanceState ) {
super . onCreate ( savedInstanceState );
setContentView ( R . layout . activity_main );
database = openOrCreateDatabase ( "mydb" , Context . MODE_PRIVATE , null );
}
}
如果在 Activity 销毁时没有 关闭数据库连接 ,database 对象将一直存在,导致 MainActivity 无法被回收。
解决方案就是在 Activity 销毁时,及时关闭数据库连接。或者在单次读取的场景下使用try-with-resources语句,完毕后会自动关闭资源。
注册的监听器未注销引起的内存泄漏 如果在 Activity 中注册了监听器,如 广播接收器、系统服务、系统数据库的监听器 等等,在 Activity 销毁时没有注销这些监听器,就会导致 Activity 无法被回收。
public class MainActivity extends AppCompatActivity {
private BroadcastReceiver receiver ;
@Override
protected void onCreate ( Bundle savedInstanceState ) {
super . onCreate ( savedInstanceState );
setContentView ( R . layout . activity_main );
receiver = new BroadcastReceiver () {
@Override
public void onReceive ( Context context , Intent intent ) {
// 处理广播
}
};
registerReceiver ( receiver , new IntentFilter ( "com.example.action" ));
}
@Override
protected void onDestroy () {
super . onDestroy ();
// 忘记注销广播接收器
}
}
线程未停止引起的内存泄漏 如果在 Activity 中启动了一个线程,该线程持有了 Activity 的引用,即使 Activity 已经被销毁,线程仍然在运行,就会导致 Activity 无法被回收。原理和解决方案和Handler导致的泄露基本相同。
public class MainActivity extends AppCompatActivity {
private Thread thread ;
@Override
protected void onCreate ( Bundle savedInstanceState ) {
super . onCreate ( savedInstanceState );
setContentView ( R . layout . activity_main );
thread = new Thread ( new Runnable () {
@Override
public void run () {
// 执行耗时操作
}
});
thread . start ();
}
}
集合类存储长生命周期的对象导致泄露 集合类使用不当导致的内存泄漏,这里分两种情况来讨论:
1)集合类添加对象后不移除的情况 对于所有的集合类,如果存储了对象,如果该 集合类实例的生命周期比里面存储的元素还长 ,那么该集合类将一直持有所存储的短生命周期对象的引用,那么就会产生内存泄漏,尤其是使用static修饰该集合类对象时,问题将更严重。我们知道static变量的生命周期和应用的生命周期是一致的,如果添加对象后不移除,那么其所存储的对象将一直无法被gc回收。解决办法就是根据实际使用情况,存储的对象使用完后将其remove掉 ,或者使用完集合类后清空集合 。
2)根据hashCode的值来存储数据的集合类使用不当造成的内存泄漏以HashSet为例子,当一个对象被存储进HashSet集合中以后,就不能再修改该对象中 参与计算hashCode的字段值 了,否则,原本存储的对象将无法再找到,导致无法被单独删除,除非清空集合。
第三方库使用不当造成的内存泄漏 使用第三方库的时候,务必要按照官方文档指定的步骤来做,否则使用不当也可能产生内存泄漏,比如:
EventBus,也是使用观察者模式实现的,同样注册和反注册要成对出现。 Rxjava中,上下文销毁时,Disposable没有调用dispose()方法。 Glide中,在子线程中大量使用Glide.with(applicationContext),可能导致内存溢出。 内存泄露问题分析方法 排查内存问题,我们的项目中可以在debug构建的情况下,使用LeakCanary来进行内存泄漏的检测。LeakCanary会在应用程序发生内存泄漏时,自动生成一个报告,帮助开发者定位和修复内存泄漏问题。
在生产环境中遇到一个内存泄漏问题,如果是必现,我们可以直接根据必现流程,判断我们的应用中执行了哪些代码块,正向追代码引用流程排查。
如果是偶现的,需要先按照日志显示的手顺流程,尝试去使用带LeakCanary的debug版本复现问题。
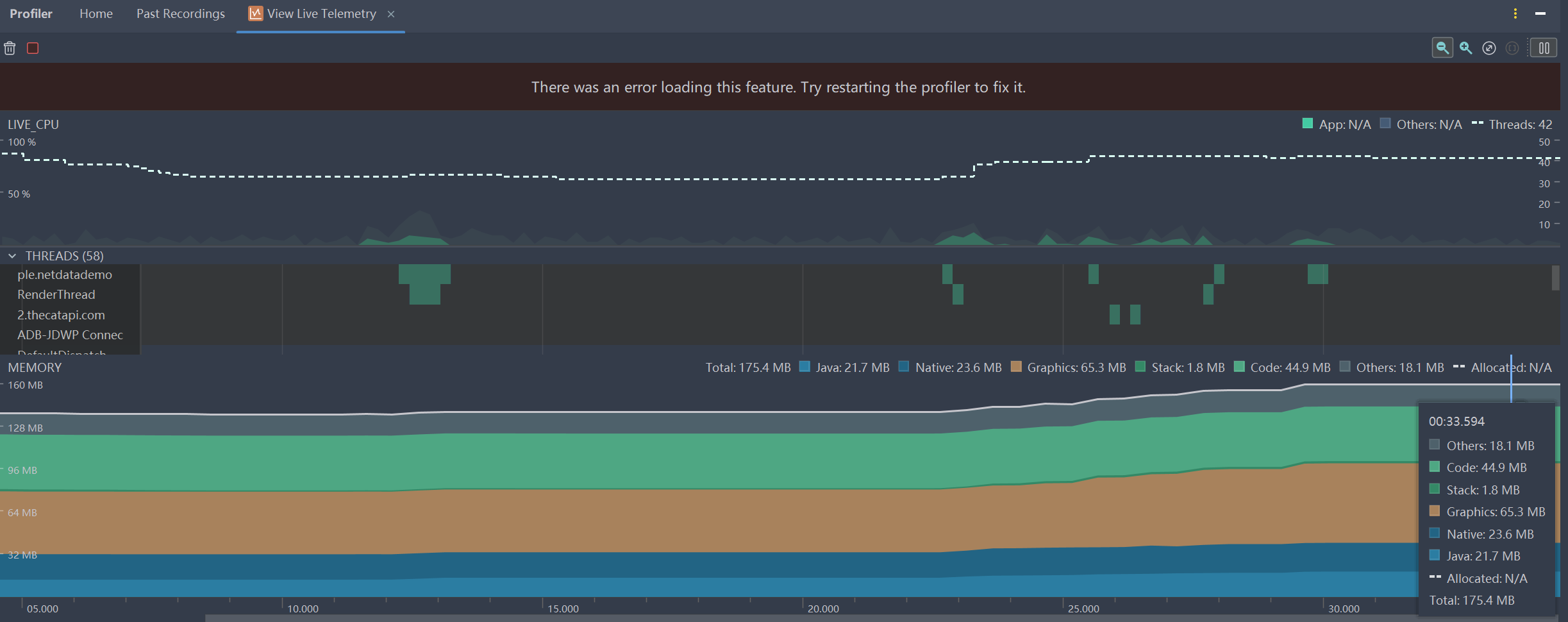
其次,我们可以使用AS的 Memory Profiler 功能模块来分析内存使用情况,实时地查看内存使用的对象和引用关系,从而定位内存泄漏的原因。如果有内存泄露,应用运行一段时间后内存占用会持续上升。
Profiler入口:
Live Telemetry 也可以实时查看应用的内存使用情况,包括内存分配、内存释放等信息。可以通过点击 Live Telemetry 按钮来打开 Live Telemetry 窗口。
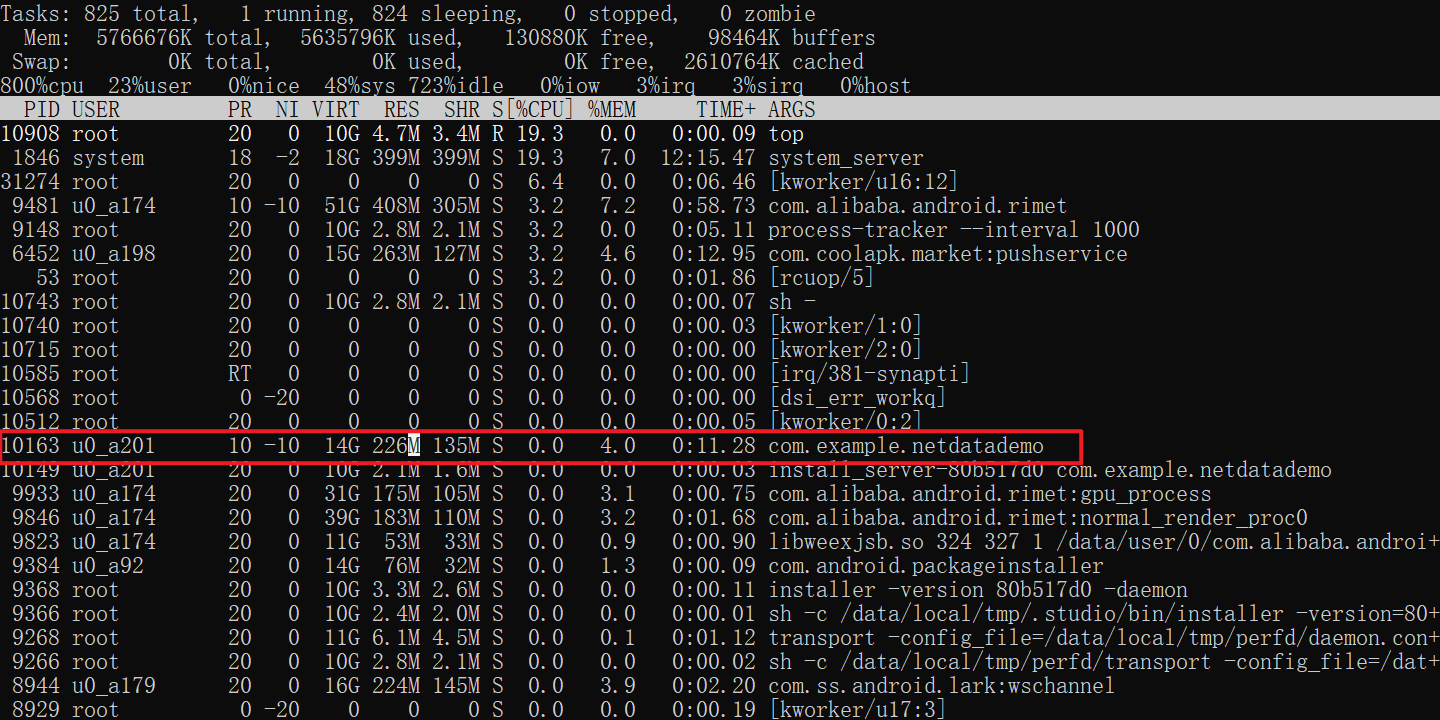
还可以直接在shell中使用top或者ps命令来查看应用的内存使用情况,边操作边观察,看看是哪里导致的内存泄漏,再去分析可能的原因来解决。
LeakCanary检测原理 前天的另一篇文章详细介绍了检测泄漏的流程和原理:
LeakCanary工具的原理解析
内存抖动(Memory Stutter) 内存抖动是指应用程序在短时间内频繁地分配和释放内存,导致系统频繁地进行垃圾回收,从而降低应用程序的性能。内存抖动通常发生在循环中 ,创建临时对象或者频繁地进行内存分配和释放操作。
可能的原因:
频繁的对象创建和销毁 ◦ 在循环中频繁地创建和销毁对象,会导致内存的频繁分配和释放,从而增加垃圾回收的负担。例如,在一个循环中创建了大量的临时对象,这些对象在循环结束后就不再使用,但由于没有及时释放,会导致内存占用不断增加。 ◦ 解决方案:尽量避免在循环中频繁创建对象,可以考虑使用对象池或者重用对象的方式来减少内存分配的次数。 内存分配和释放不平衡 ◦ 内存分配和释放的频率不平衡,导致内存的使用量不断变化,从而增加了垃圾回收的负担。例如,在一个循环中,每次循环都分配了一个新的对象,但在循环结束后没有及时释放这些对象,导致内存占用不断增加。 ◦ 解决方案:在循环结束后,及时释放不再使用的对象,避免内存的过度分配和释放。可以使用对象池或者重用对象的方式来减少内存分配的次数。 内存占用过大 ◦ 应用程序的内存占用过大,导致系统频繁地进行垃圾回收,从而降低应用程序的性能。例如,应用程序的内存占用超过了系统的可用内存,导致系统频繁地进行垃圾回收,从而降低应用程序的性能。 ◦ 解决方案:优化应用程序的内存使用,减少内存的占用。可以使用内存分析工具(如 Android Studio 的 Memory Profiler)来检测应用程序中的内存泄漏情况,并进行相应的优化。 内存碎片 ◦ 内存碎片是指内存中的空闲区域分散不均匀,导致无法分配足够大的连续内存空间。例如,在一个循环中,每次循环都分配了一个新的对象,但在循环结束后没有及时释放这些对象,导致内存中的空闲区域分散不均匀,无法分配足够大的连续内存空间。 应用内存溢出(Out Of Memory) 内存溢出是指应用程序试图分配比系统可用内存更多的内存空间。在 Android 中,每个应用程序都有一个特定的内存限制,这个限制取决于设备的硬件和操作系统版本。当应用程序尝试分配的内存超过这个限制时,就会发生内存溢出错误。在手机上,内存溢出错误通常会导致应用程序崩溃。在车机开发中,系统应用的内存大小如果没有限制,发生OOM甚至会直接导致系统重启。发生内存溢出的可能场景有:
频繁加载大图片,如果直接加载高分辨率的大图片而不进行适当的处理,会占用大量的内存。例如,加载一张 4000x3000 像素的图片,可能会消耗几十兆甚至上百兆的内存。可以使用图片加载库(如 Glide、Picasso 等),这些库通常会自动根据设备的屏幕尺寸和内存情况对图片进行缩放和缓存管理,以减少内存占用。 过多的对象创建,在循环中频繁创建对象或者创建大量不必要的临时对象,会导致内存快速增长。比如在一个频繁调用的方法中不断创建新的字符串对象。可以尽量复用对象,避免不必要的对象创建。对于在循环中创建的对象,可以考虑在循环外部创建并重复使用。 数据缓存不合理,如果缓存的数据过多或者没有及时清理过期的缓存,会占用大量内存。例如,一个网络请求缓存了大量的 JSON 数据,但没有设置缓存大小限制或过期时间。解决方案:合理设置缓存大小和过期时间,定期清理不再需要的缓存数据。可以使用 LruCache 等缓存工具来管理内存缓存。 内存泄漏,不再使用的对象仍然被其他对象引用,导致垃圾回收器无法回收它们的内存。随着时间的推移,内存泄漏会积累大量无法回收的内存,最终导致内存溢出。解决方案:及时释放不再使用的资源,避免静态变量持有长生命周期对象的引用,注意 Activity、Service 等组件的生命周期管理,防止内存泄漏的发生。 在 Android 开发中,要避免内存溢出问题,需要注意合理使用内存资源,优化代码结构和算法,及时清理不再需要的资源,并使用合适的工具进行内存分析和优化。
Low Memory Killer (LMK) 机制 Low Memory Killer 是 Android 系统为了在内存不足时保持系统响应性和性能而设计的一套进程终止机制。
它预测性地、分级地在系统内存压力达到某个阈值时 ,就主动杀死“不重要”的进程,以释放内存,避免等到系统彻底耗尽内存(OOM)时才触发最后的紧急清理。
Low Memory Killer 的功能由用户空间的守护进程 lmkd (Low Memory Killer Daemon) 来执行,它不再是传统的内核驱动程序,而是通过监听内核的内存压力信号(如 vmpressure 事件或 PSI - 压力失速信息)来工作。
LMK 的决定是基于 Android 系统分配给每个进程的 “优先级分数” ,通常称为 oom_adj_score(或简写为 adj 值)。这个分数由 Android 的 ActivityManagerService 动态计算和设置,反映了进程对用户的价值和其生命周期状态。
lmkd 会根据内存压力程度,查看所有运行中的进程,并根据它们的 oom_adj_score 从高到低(即“最不重要”到“最重要”)开始杀死进程,直到释放足够的内存。
oom_adj_score(在 Android 源码中通常称为 adj 或 oom_adj)并不是通过一个简单的数学公式计算出来的,而是由 Android 核心组件 ActivityManagerService (AMS)动态分配和调整 的。
它的计算逻辑是复杂的,它基于应用程序进程中运行的组件 及其与用户的交互状态 。这个分数决定了进程的重要性 ,分数越高,优先级越低,越容易被 Low Memory Killer (LMK) 杀死。
oom_adj_score 计算 以下是 oom_adj_score 的主要决定因素和计算逻辑:
进程状态/组件 oom_adj 值(示例)描述 前台进程 (Foreground) 0 进程内有用户当前正在交互的 Activity。最高优先级,不会被 LMK 杀死。 可见进程 (Visible) 1-200 进程内有可见但非焦点的 Activity(如对话框下的 Activity)。优先级仅次于前台。 前台服务进程 (Foreground Service) 100-200 进程内有通过 startForeground() 运行的服务(如音乐播放、GPS)。 后台服务进程 (Service) 200-400 进程内有正常运行的 Service,但没有 Activity。 可缓存的空进程 (Cached) 900+ 进程内没有任何活动的组件,仅保留在内存中以便快速重启。最低优先级,LMK 的主要目标。
Memory Profiler 使用 Memory Profiler 来分析内存是性能优化的重要方式。其中显示的各个区域反映了进程地址空间中不同类型内存的占用情况。
区域名称 对应内容 (Content) 内存类型 (Type) 典型占用 (Typical Occupants) Java Heap JVM(Java/Dalvik)虚拟机管理的内存区域。 堆 (Heap) Java 对象实例、Kotlin 对象实例、非压缩的 Bitmap 对象引用、应用自定义类实例等。这是最常分析的区域。 Native Heap C/C++ 代码(或底层系统库)直接通过 malloc/new 等函数分配的内存区域。 堆 (Heap) Bitmap 的像素数据Code 应用程序和系统库的可执行机器码(.dex、.so 文件)以及运行时生成的代码。 代码段 (Text Segment) DEX 文件(包含 Java 字节码)、本地库 (.so 文件)、JIT/AOT 编译后的机器码。 Stack 为每个线程分配的私有内存区域。 栈 (Stack) 函数调用栈、方法参数、局部变量(基本类型、对象引用)。Stack 内存通常很小,不会导致 OOM。 Graphics 用于处理显示和图形相关的内存。 专用内存 (Dedicated) 图像缓冲区 (Buffers)、纹理、SurfaceFlinger 相关的内存。 Other 未归类到以上任何区域的内存。 混合 (Mixed) 内存映射文件(mmap)、文件 I/O 缓冲区、系统内核分配的页表等。
Bitmap 对象的内存体现 Bitmap 是 Android 内存分析中最特殊也最重要的对象之一。很多的泄露问题中,如果是图片加载导致的泄露,现象一般比较明显和严重。
它的内存占用被分割 到两个不同的内存区域中:
Java Heap 是 Bitmap 对象的引用和元数据 存储的地方。存储 Bitmap 对象的 Java 引用(java.lang.Object)以及它的元信息(如宽度、高度、配置等)。这部分内存很小,通常只有几十字节。 Native Heap(原生堆),这是 Bitmap 占用的绝大部分内存 ,即像素数据 (Pixel Data) 存储的地方。注意在 Android 8.0 之后Bitmap 的像素数据是存储在 Java Heap 中的。如果使用了 BitmapFactory.Options.inPreferredConfig = Bitmap.Config.HARDWARE 或 JNI C/C++ 代码来处理图像,像素数据仍然可能被分配在 Native Heap 或 Graphics 区域。 后台更新ImageView的危险操作 曾经开发过一个悬浮窗式的APP,没有Activity组件,即需要自己管理View和数据的生命周期关系。有一次在后台不断地更新ImageView的帧动画对象,导致了严重的内存问题。
当你通过 AnimationDrawable(帧动画的实现类)加载一系列图片帧时,无论 ImageView 是否在屏幕上显示,这个过程都会发生以下事情:
解码成Bitmap: 每一张图片资源(比如 R.drawable.frame1)都会被解码成一个 Bitmap 对象。Bitmap 是Android中表示位图的类,它包含了图片的像素数据。内存位置: 这些 Bitmap 对象占用的内存位于应用的 堆内存(Heap Memory) 中。Bitmap 的像素数据也主要分配在应用的堆内存里,由Java/Kotlin的垃圾回收器(GC)管理。持有引用: AnimationDrawable 对象会内部持有一个列表,用来存储每一帧对应的 Drawable 对象。这些 Drawable 对象最终会持有对 Bitmap 对象的强引用。所以,即使界面没有显示,只要你的代码执行了加载帧动画的逻辑,那些被解码后的图片 Bitmap 对象就会被创建并存储在应用的堆内存中。AnimationDrawable 实例持有这些 Bitmap 的引用,防止它们被垃圾回收器回收。
这个“缓存”其实就是 AnimationDrawable 对象自身对所有帧图像Bitmap的直接持有。
如果不断读取新的图片,会使后台的内存占用越来越大 。这是一个非常危险的操作,极有可能导致应用崩溃。**
如果应用在后台(用户看不到UI),还在持续地加载新的图片帧到 AnimationDrawable 中,会发生以下情况:
内存持续增长: 每加载一张新的图片,就会在堆内存中创建一个新的 Bitmap 对象。由于 AnimationDrawable 持有它的引用,这块内存就无法被释放。应用的堆内存占用会像滚雪球一样越来越大。触发 OOM (OutOfMemoryError): 每个Android应用都有一个固定的堆内存上限(具体大小因设备而异)。当你的应用内存占用超过这个上限时,系统会抛出 OutOfMemoryError 异常,导致应用直接崩溃。被系统“杀死”: 即使没有立刻OOM,一个在后台占用大量内存的应用也会给系统带来很大压力。当系统需要更多内存给前台应用(比如用户正在使用的其他App)时,你的应用会成为被系统强制关闭(kill process)的优先目标。用户下次回到你的App时,会发现它被重启了,体验非常糟糕。最佳实践与解决方案 核心原则是:UI资源的加载和释放,必须与UI组件的生命周期严格绑定。
对于帧动画,正确的处理方式如下:
1. 不要在后台加载和启动动画
动画是给用户看的,当UI不可见时,任何动画操作都是在浪费CPU和内存。你应该在界面变为可见时才开始加载和播放动画。
2. 遵循Activity/Fragment的生命周期
在 Activity 或 Fragment 的生命周期回调方法中管理 AnimationDrawable 是最标准、最安全的方式。
onStart() 或 onResume():AnimationDrawable 对象并调用 start() 方法开始播放。这时UI对用户是可见的。onStop() 或 onPause():stop() 方法停止动画。这时UI已经不可见或被部分遮挡。停止动画不仅可以节省CPU,更重要的是,系统可以有机会回收 AnimationDrawable 内部的 Bitmap 资源(如果你也解除了对它的引用)。CPU优化 在 Android 应用中,CPU 是执行所有计算任务的核心硬件。无论是用户交互、数据处理,还是系统后台任务,几乎所有的操作都需要依赖 CPU 来完成。
UI 操作 UI 操作是用户直接感知的部分,虽然 Android 的 UI 渲染主要由 GPU 协助完成,但 CPU 仍然承担了大量的计算任务。
布局测量与布局(Measure/Layout) XML 布局解析:当加载一个 XML 布局文件时,系统需要解析 XML 并将其转换为视图树,这一过程由 CPU 完成。 视图测量与布局(Measure/Layout):在视图树构建完成后,系统需要计算每个视图的大小和位置,这一过程也由 CPU 执行。 视图绘制(Draw):虽然最终的像素填充由 GPU 完成,但绘制指令的生成(如 onDraw() 方法中的 Canvas 操作)是由 CPU 处理的。 CPU 占用高的原因可能有布局过于复杂(嵌套过深的视图树)。频繁调用 requestLayout() 或 invalidate(),导致视图反复测量和绘制。
动画效果 属性动画、补间动画和帧动画,都需要 CPU 参与计算每一帧的状态。如果动画复杂度较高(如大量视图的联动动画),CPU占用会显著增加。另外,在主线程中执行动画计算,也会导致主线程负担过重。
数据处理与计算 任何涉及数据处理的操作都需要 CPU 参与计算,尤其是在处理大量数据或复杂算法时,CPU 占用会显著增加。
数学运算:如加密解密、图像处理、视频编解码、物理模拟等。 排序与搜索:对大量数据进行排序(如 Collections.sort())或搜索(如二分查找、哈希表查询)。 数据转换:如图片缩放、颜色格式转换、音频采样率转换等。 数据解析 JSON/XML 解析:从网络或本地文件中读取 JSON 或 XML 数据并解析为对象,这一过程需要 CPU 进行字符串处理和数据结构转换。 Protobuf/FlatBuffer 解析:虽然这些格式的解析效率较高,但在数据量较大时仍然会占用 CPU。 网络数据的处理:在网络请求中,CPU 通常用于处理数据的序列化和反序列化。 多线程与并发操作 Android 应用中,开发者通常会使用多线程来执行耗时任务(如网络请求、文件读写、数据处理等),以避免阻塞主线程。然而,线程的创建、调度和同步也会占用 CPU 资源。
每个线程的创建和销毁都会消耗一定的 CPU 资源。如果创建了过多的线程(如没有使用线程池),线程调度会成为 CPU 的负担。
使用锁(如 synchronized、ReentrantLock)或其他同步机制(如 CountDownLatch、Semaphore)时,线程可能会因为等待锁而被挂起或唤醒,这一过程会占用 CPU。
后台任务与系统服务 Android 应用可能会在后台执行一些任务(如数据同步、日志上传、定时任务等),这些任务通常由系统服务或应用自带的线程池管理,但仍然需要 CPU 参与。
例如使用 AlarmManager、Handler 或 WorkManager 执行定时任务时,任务的执行逻辑会占用 CPU。 当应用接收到广播(如系统广播或自定义广播)时,注册的广播接收器会执行相应的回调逻辑,这一过程CPU可能会执行计算任务。 如果应用注册了传感器监听(如加速度传感器、陀螺仪),传感器的回调数据需要由 CPU 处理。传感器数据采样频率过高,会导致CPU处理负担过重。 图片与多媒体处理 图片和多媒体处理是 CPU 占用较高的场景之一,尤其是在处理高分辨率图片或高清视频时。
使用 BitmapFactory 解码图片时,CPU 需要将原始字节数据转换为位图对象。如果图片分辨率过高(如几 MB 的图片),解码过程会非常耗时。 对图片进行缩放、裁剪、旋转等操作时,CPU 需要进行大量的像素计算。 播放或录制音频/视频时,编解码过程通常由 CPU 完成(除非使用了硬件加速)。 优化 CPU 占用 针对上述场景,我们可以采取以下优化策略:
减少布局嵌套,使用 ConstraintLayout 等高效布局。避免频繁调用 requestLayout() 或 invalidate()。使用硬件加速(如开启 setLayerType(View.LAYER_TYPE_HARDWARE, null) )来分担 CPU 的绘制压力。还有避免频繁计算复杂的自定义动画。 使用高效的算法和数据结构(如 HashMap 替代嵌套循环)。对大数据集进行分页加载,避免一次性处理过多数据。将数据处理任务移到子线程中执行,避免阻塞主线程。 避免频繁创建和销毁线程,合理使用线程池来管理线程,可以避免创建过多线程。减少锁的使用,避免线程竞争。使用无锁数据结构(如 ConcurrentHashMap)或异步编程模型(如 RxJava、Kotlin 协程)。 合并定时任务,减少任务执行的频率。使用 WorkManager 管理后台任务,避免重复执行。在广播接收器中只执行轻量级逻辑,耗时操作移到服务或线程中执行。 压缩图片分辨率,避免加载过大的图片。使用图片加载库(如 Glide、Picasso),它们会自动处理图片的解码和缓存。使用硬件加速的编解码器(如 MediaCodec)处理音视频。 GPU优化 在 Android 应用中,GPU(图形处理单元) 主要负责图形渲染相关的任务,即将 CPU 提交的绘制指令转化为屏幕上的像素 。
虽然 GPU 的主要职责是图形渲染,但在现代 Android 应用中,GPU 的使用场景已经不仅限于传统的图形绘制,还涉及到一些与图形相关的计算任务(如图像处理、视频渲染等)。
以下是 Android 应用中常见的会使用到 GPU 的操作。
UI 渲染相关操作 UI 渲染是 GPU 最常见的使用场景,因为 Android 的界面是由大量的视图(View)组成的,而这些视图的绘制和显示需要 GPU 的参与。
Android 的视图系统通过 CPU 生成绘制指令(如 Canvas.drawXXX() 方法),然后将这些指令提交给 GPU 进行实际的像素填充。不管是绘制基本图形(如矩形、圆形、路径等),还是绘制文本,位图等。都是由 GPU 将 CPU 提交的绘制指令转化为屏幕上的像素。如果视图树过于复杂或绘制逻辑过于频繁,GPU 的负载会增加。
动画效果 动画的本质是每一帧的视图状态变化,而每一帧的状态变化需要通过 GPU 进行渲染。例如属性动画、补间动画、帧动画和自定义动画(如通过 ValueAnimator 实现的动画)。GPU 需要计算每一帧的像素变化并渲染到屏幕上。如果动画复杂度较高(如多个视图的联动动画)或帧率过高GPU 的负载会显著增加。
过度绘制(Overdraw) 过度绘制是指屏幕上的某些像素被多次绘制(如背景色、View 的背景、子 View 的背景等叠加绘制)。例如多层嵌套的背景色(如父布局和子布局都设置了背景色)。不可见的视图仍然被绘制(如 View.setVisibility(View.GONE) 的视图仍然被调用 draw() 方法)。过度绘制会增加 GPU 的负担,导致渲染性能下降。
图片与图像处理相关操作 图片加载、解码和显示是 Android 应用中常见的操作,这些操作通常需要 GPU 参与渲染,尤其是在处理高分辨率图片或复杂图像效果时。例如从网络或本地加载图片后,图片需要被解码为位图(Bitmap),然后通过 GPU 渲染到屏幕上。GPIU会将解码后的位图渲染到屏幕上。
如果图片分辨率过高(如几 MB 的图片),解码和渲染的负担会显著增加。
还有对图片进行缩放、裁剪、旋转等操作时,可能需要 GPU 参与像素计算。例如使用 Matrix 对图片进行变换(如缩放、旋转)。使用 Bitmap.createScaledBitmap() 对图片进行缩放。如果图片处理逻辑过于复杂,GPU 的负载会增加。
图像滤镜与特效
应用中可能还会使用一些图像滤镜或特效(如模糊、锐化、色彩调整等),这些操作通常需要对每个像素进行计算。
使用 OpenGL ES 或 Vulkan 实现自定义滤镜。 使用第三方库(如 GPUImage)实现图像特效。 图像滤镜和特效通常是计算密集型任务,会显著增加 GPU 的负载。
视频与多媒体相关操作 视频播放、录制和处理是 GPU 的重要使用场景,因为视频本质上是由大量的帧组成的,每一帧的解码、渲染和处理都需要 GPU 的参与。视频播放需要对每一帧进行解码和渲染,而 GPU 可以加速帧的渲染过程。 当我们使用使用 MediaPlayer 或 ExoPlayer 播放视频。使用 SurfaceView 或 TextureView 显示视频画面。GPU 会参与进来加速视频帧的渲染。
如果视频分辨率过高(如 4K 视频),或者播放过程中存在跳帧、卡顿,可能是 GPU 的负载过高。
视频录制需要对摄像头采集的每一帧进行处理和编码,而 GPU 可以加速帧的处理过程。例如使用 Camera2 API 或 CameraX 录制视频。或者使用 OpenGL ES 或 Vulkan 对视频帧进行实时处理(如滤镜、特效)。 GPU 会加速视频帧的处理和渲染。
游戏与高性能图形应用 游戏和高性能图形应用是 GPU 的主要使用场景,因为这些应用通常需要实时渲染大量的图形和动画。例如 2D 游戏需要实时渲染大量的精灵(Sprite)、背景、文字等图形元素。3D 游戏需要实时渲染复杂的三维模型、光影效果、粒子系统等。当我们使用 OpenGL ES 或 Vulkan 进行 3D 渲染。使用游戏引擎(如 Unity、Unreal Engine)进行 3D 游戏开发时,GPU 会加速三维模型的渲染、光影计算和粒子效果。
机器学习与图像处理 一些机器学习模型(如卷积神经网络)和图像处理算法(如目标检测、图像分割)可以利用 GPU 的并行计算能力加速。
使用 TensorFlow Lite 或 ML Kit 进行图像分类、目标检测等任务。 使用 GPU 加速的图像处理库(如 OpenCV + GPU 模块)。 GPU 主要用来加速矩阵运算和像素计算。机器学习和图像处理的计算量通常较大,对 GPU 的性能要求较高。
掉帧优化 Android 系统每隔 16.67ms 发出VSYNC信号,触发对UI进行渲染。如果某一帧的渲染时间超过 16.67ms,就会导致掉帧。例如,某一帧渲染耗时 33ms,就会导致掉 1 帧(因为 33ms > 16.67ms × 2)。
掉帧的表现形式包括:
界面卡顿、不流畅。 动画效果出现“跳帧”。 滑动列表时出现“拖影”或“延迟”。 掉帧可能是由于多种原因引起,CPU、GPU、内存等资源都可能成为瓶颈。
GPU 负责将 CPU 提交的绘制指令转化为屏幕上的像素。如果 GPU 的 负载过高 ,或者 渲染任务过于复杂 ,会导致帧渲染时间超过 16.67ms,从而引发掉帧。
内存问题可能间接导致掉帧,尤其是在内存不足时,系统会频繁进行内存回收,甚至触发 onTrimMemory() 回调,影响应用的性能。例如出现内存泄漏会导致应用的内存占用不断增加,最终触发频繁的垃圾回收(GC),从而影响主线程的执行。表现为界面卡顿,尤其是在长时间运行后。如果设备的内存不足,系统可能会频繁进行内存回收,甚至杀死后台进程以释放内存。这会导致应用的性能下降。应用启动变慢,滑动列表时出现卡顿。
系统层面
如果设备上有大量的后台任务(如其他应用的后台服务、系统更新等),会占用 CPU 和内存资源,影响当前应用的性能。尤其是在设备整体负载较高时,当前应用运行也会跟随变慢。
CPU 资源竞争也是一个因素,如果应用创建了过多的线程,或者线程调度不合理,会导致 CPU 资源竞争,影响主线程的执行。界面卡顿,尤其是在多线程任务较多的场景中。
出现掉帧问题的经典log:
"Skipped xx frames! The application may be doing too much work on its main thread"
奶酪模型 从产品设计到上线,每一个流程都像一片奶酪,令人不愉快的bug就像正好穿透了每一片奶酪的孔,到达了用户那里。比如开发逻辑考虑不全,测试漏测,环境不一致,验收不严格,发布的人员配置错了包。。。
做性能问题跟进时,要多往前一步,加强各个环节的管理,尽可能早的捕获异常。
测试项目 CPU 在启动,卡顿和功耗测试时,需要做CPU的相关测试。
获取CPU核心数量
adb shell cat /sys/devices/system/cpu/present
获取cpu最大频率
adb shell cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_max_freq
获取cpu当前频率
adb shell cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq
获取cpu使用时间
C:\Users\stephen>adb shell cat proc/stat
user nice system idle iowait irq softirq
cpu 11570106 908753 10084803 182776887 83576 1710507 375950 0 0 0
cpu0 2083516 133403 2103739 21423628 10242 435957 101041 0 0 0
cpu1 2159620 138975 2070350 21482805 9850 409451 66651 0 0 0
cpu2 2079859 134242 2058410 21601693 9440 391933 66413 0 0 0
cpu3 2058259 133264 2049679 21604397 9473 377789 123115 0 0 0
cpu4 1117565 193035 979789 24387557 20360 45444 9989 0 0 0
cpu5 689868 54942 326106 25660003 10828 21026 3717 0 0 0
cpu6 681939 55379 321498 25672120 10775 20727 3652 0 0 0
cpu7 699477 65509 175229 20944681 2604 8177 1368 0 0 0
intr 854517694 0 455381193 23874980 0 0 0 51669558 0 0 0 0 207557250 0 0 0 0 0 914 1197 2 1 40218 0 0 0 0 0 0 12476206 0 0 5793575 126636 42212 0 0 18958468 169317 4351606 1895070 396 65628 2311956 0 0 0 0 0 0 0 0 0 0 0 0 0 35577 0 0 0 0 0 0 0 0 0 0 0 0 269992 448 0 1572833 0 0 0 0 0 0 0 0 0 0 0 0 9075516 238492 93961 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 162631 66441 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11059235 0 0 0 0 0 0 0 0 801 491 136 26 440 0 3062479 367011 0 18325 0 35584 207672 0 0 0 0 171047 106114 1054921 616439 0 0 35780 34946 254079 3376 0 9909125 3318728 0 0 5 422 6 0 4 20536 4 4 9814 0 839 255 780289 325 13994 0 0 0 0 0 0 18 60 0 0 0 0 0 0 0 0 0 0 0 0 278 418 1933 0 0 0 0 84 0 0 3 2510466 46 136 133710 251287 66 390 2800222 385903 1408 0 0 0 0 0 7154 1538107 670023 937725 1422598 1489379 0 114654 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 1 1 0 0 1 1 0 0 15 19901 3343 256936 52 0 276656 0 0 0 206182 0 699076 3231 0 0 1289340 7315827 0 0 400 66 17 0 0 0 10 1 1 0 6 0 0 11 4810173 54848
ctxt 1403823113
btime 1733724528
processes 879090
procs_running 1
procs_blocked 0
softirq 142741039 18220587 27876585 91010 10189720 5052564 0 3964375 24884673 501992 51959533
上面的数据打印,第一行有7个字段描述:
user:用户态时间 nice:通过nice修改优先级之后的进程的用户态时间 sysetm:内核态时间 idle:空闲时间 iwait:等待IO完成的时间 irq:硬件中断的时间 softirq:软件中断的时间 数据单位是jiffies,表示时钟中断次数,一般为1/100s
测试应用CPU 对一个 Android 应用进行 CPU 测试,包括 CPU 占用率、CPU 密集型任务的性能、线程使用情况等。通过 CPU 测试,可以发现应用是否存在 CPU 过载、线程阻塞、死锁 或 性能瓶颈 等问题。
可以使用如下方法:
1. 使用 Android Studio Profiler 进行 CPU 测试 Android Studio 内部集成了 Profiler 工具,可以帮助开发者实时监控应用的 CPU 使用情况、方法调用耗时、线程状态等信息。它是Systrace的升级版本,提供了更全面的性能分析功能。
具体的,打开 Android Studio,连接设备或启动模拟器。
在顶部菜单栏选择 View > Tool Windows > Profiler。 选择要测试的应用进程。 在 Profiler 中,切换到 CPU 标签页,可以选择以下两种分析模式:
Sample Java Methods(采样 Java 方法):通过采样方式记录方法的调用情况,适合分析 CPU 密集型任务的性能。对应用性能影响较小,适合长时间测试。 Trace Java Methods(跟踪 Java 方法):记录每个方法的调用耗时,适合分析具体方法的性能瓶颈。对应用性能影响较大,适合短时间测试。 点击 Record 按钮,开始记录 CPU 使用情况。在应用中执行目标操作(如启动页面、滑动列表、点击按钮等)。操作完成后,点击 Stop 按钮,停止记录。
Profiler 会生成 CPU 使用情况的图表和调用树(Call Chart),包括:
CPU 使用率:应用在测试期间的 CPU 占用情况。 调用树(Call Chart):显示方法的调用关系和耗时情况。 火焰图(Flame Chart):以可视化的方式展示方法调用的堆栈信息,帮助快速定位性能瓶颈。 线程活动:显示各个线程的活动情况,帮助分析是否存在线程阻塞或死锁。 2. 命令行工具 adb shell top:查看设备的 CPU 使用情况,包括应用的 CPU 占用率。
adb shell dumpsys cpuinfo:查看应用的 CPU 使用统计信息。
adb shell pidstat(需要安装 sysstat 工具):更详细地查看进程的 CPU 使用情况。
3. Perfetto Perfetto 是 Android 平台上的性能分析工具,可以帮助开发者分析应用的 CPU 使用情况、线程状态、方法调用耗时等。
在终端运行以下命令,启动 Perfetto 数据采集:
adb shell perfetto --txt -c /data/misc/perfetto-configs/trace_config.pbtxt -o /data/misc/perfetto-traces/trace.perfetto-trace
需要提前配置 trace_config.pbtxt 文件,指定要采集的数据类型(如 CPU、内存、线程等)。在数据采集期间,在设备上执行目标操作。停止数据采集后,将生成的 .perfetto-trace 文件导出到电脑:
adb pull /data/misc/perfetto-traces/trace.perfetto-trace
打开 https://ui.perfetto.dev/ ,上传 perfetto-trace 文件进行分析。
可以查看 CPU 使用情况、线程状态、方法调用耗时等详细信息。
GPU GPU测试对于Android手机的性能评估、优化、兼容性检查和故障诊断等方面都具有重要意义。它有助于提高手机的整体性能和用户体验,同时也为开发者提供了优化应用程序的依据。
通过GPU测试,可以了解手机GPU的性能表现,包括图形处理能力、渲染速度、帧率等。确保GPU与操作系统、驱动程序和各种应用程序之间的兼容性。
获取GPU类型
dumpsys SurfaceFlinger | grep GLES
------------RE GLES------------
GLES: Qualcomm, Adreno (TM) 730, OpenGL ES 3.2 V@0615.73 (GIT@8f5499ec14, Ie6ef1a0a80, 1689341690) (Date:07/14/23)
gpubusy 这是一个与 GPU 使用率相关的信息。在 Android 系统中,gpubusy 通常指的是 GPU 繁忙程度的指标,它表示 GPU 在某个时间段内处于忙碌状态的时间比例。这个指标可以帮助开发者了解 GPU 的负载情况,以便优化图形渲染性能。
adb shell cat /sys/class/kgsl/kgsl-3d0/gpubusy
gpuclk 通常指的是 GPU 时钟频率(GPU Clock Frequency)。GPU 时钟频率是指 GPU 芯片内部的时钟信号的频率,它决定了 GPU 每秒钟能够执行的操作次数。GPU 时钟频率越高,GPU 的性能通常就越强,但同时也会消耗更多的电力并产生更多的热量。
adb shell cat /sys/class/kgsl/kgsl-3d0/gpuclk
联发科平台
adb shell cat sys/kernel/debug/ged/hal/gpu_utilization
adb shell cat sys/kernel/debug/ged/hal/current_frequency
FPS 卡顿测试时的测试数据。
FPS frames,在数据获取的周期内,用实际绘制帧数除以时间间隔所得 Skipped frames,表示掉帧数,在数据时间周期内实际掉帧数量 Janky frames,掉帧率,实际掉帧数量除以实际绘制数可得 使用下面这个命令计算单个app的卡顿信息,这里面信息很多,主要有四个部分。
卡顿统计信息 内存占用信息 绘制一帧各个阶段的时间 布局层级和总布局数 redfin:/ # dumpsys gfxinfo com.stephen.redfindemo framestats
卡顿统计数据 ** Graphics info for pid 7206 [com.stephen.redfindemo] **
Stats since: 992991790325ns
Total frames rendered: 84
Janky frames: 4 (4.76%)
Janky frames (legacy): 6 (7.14%)
50th percentile: 5ms
90th percentile: 10ms
95th percentile: 20ms
99th percentile: 105ms
Number Missed Vsync: 1
Number High input latency: 29
Number Slow UI thread: 4
Number Slow bitmap uploads: 0
Number Slow issue draw commands: 3
Number Frame deadline missed: 4
Number Frame deadline missed (legacy): 3
绘制相关占用的内存 CPU Caches:
Glyph Cache: 37.14 KB (1 entry)
Glyph Count: 6
Total CPU memory usage:
38034 bytes, 37.14 KB (0.00 bytes is purgeable)
GPU Caches:
Other:
Other: 7.90 KB (1 entry)
Image:
Texture: 10.57 MB (7 entries)
Scratch:
Texture: 2.00 MB (1 entry)
Buffer Object: 48.00 KB (1 entry)
Total GPU memory usage:
13240552 bytes, 12.63 MB (10.57 MB is purgeable)
绘制一帧各阶段时间图 ---PROFILEDATA---
Flags,FrameTimelineVsyncId,IntendedVsync,Vsync,InputEventId,HandleInputStart,AnimationStart,PerformTraversalsStart,DrawStart,FrameDeadline,FrameInterval,FrameStartTime,SyncQueued,SyncStart,IssueDrawCommandsStart,SwapBuffers,FrameCompleted,DequeueBufferDuration,QueueBufferDuration,GpuCompleted,SwapBuffersCompleted,DisplayPresentTime,
1,3323,993103720308,993103720308,0,993103921638,993103922419,993103923096,993185780292,993124220308,993103919554,11111111,
...
993188207896,993188438677,993190030396,993207265294,993210785034,302969,728802
---PROFILEDATA---
布局层级和总布局数 View hierarchy:
com.stephen.redfindemo/com.stephen.redfindemo.feature.main.MainActivity/android.view.ViewRootImpl@14a75f8
68 views, 115.76 kB of render nodes
/android.view.ViewRootImpl@fc532c0
74 views, 120.03 kB of render nodes
Total ViewRootImpl : 2
Total attached Views : 142
Total RenderNode : 235.79 kB (used) / 732.03 kB (capacity)
文件读写 启动速度和卡顿测试,还要关注文件读写情况。
获取pid
adb shell pidof packageName
获取进程的文件读写数据
redfin:/ # cat /proc/2866/io
rchar: 197231
wchar: 3874
syscr: 40
syscw: 48
read_bytes: 9613312
write_bytes: 0
cancelled_write_bytes: 0
可以获取到读取的总字节数,通过一定时间的差值,就可以计算出改进程读写字节数的增量。
Layout Inspector Layout Inspector 是 Android Studio 提供的一个强大工具,用于查看和分析 Android 应用程序的布局层级。
捕获布局快照 点击 Layout Inspector 窗口中的 Capture New Snapshot 按钮(一个相机图标)。 Layout Inspector 会捕获当前应用程序的布局快照,并显示在窗口中。
查看布局层级 在 Layout Inspector 窗口的左侧,你会看到布局的层级结构。 点击层级结构中的节点,可以在右侧的 Properties 窗口中查看该视图的详细属性。 你还可以在 Layout Inspector 窗口的中间部分查看布局的可视化表示。
分析布局性能 在 Layout Inspector 窗口的右上角,有一些工具按钮,如 Show Layout Bounds、Show System UI 等。 使用这些工具可以帮助你分析布局的性能,例如查看布局边界、隐藏系统 UI 等。
保存和分享布局快照 在 Layout Inspector 窗口中,点击菜单栏的 File -> Save As 来保存当前的布局快照为一个文件。 你还可以点击 File -> Export to Bitmap 来将布局快照导出为一个图片,以便与他人分享或用于文档中。
uptime uptime通常指的是设备自上次重启以来已经运行的时间。
redfin:/ # uptime
21:26:37 up 33 min, 0 users, load average: 2.42, 2.24, 2.02
top 在Android系统中,top命令用于实时显示系统中各个进程的资源占用情况,包括CPU、内存等。top命令输出的每一列代表的含义如下:
PID:进程ID(Process ID),每个进程都有一个唯一的ID。 USER:进程所属的用户。 PR:进程的优先级(Priority)。 NI:进程的Nice值,用于调整进程的优先级。 VIRT:进程使用的虚拟内存大小。 RES:进程使用的物理内存大小(Resident Set Size),即实际占用的内存。 SHR:进程使用的共享内存大小。 S:进程的状态(Status),包括R(运行)、S(睡眠)、D(不可中断睡眠)、Z(僵尸)等。 %CPU:进程占用的CPU百分比。 %MEM:进程占用的内存百分比。 TIME+:进程自启动以来占用的CPU时间,单位为秒。 COMMAND:进程的命令名或启动命令。 例如,以下是top命令的输出示例:
Tasks: 885 total, 1 running, 884 sleeping, 0 stopped, 0 zombie
Mem: 11072M total, 10758M used, 314M free, 5M buffers
Swap: 4095M total, 3130M used, 965M free, 4686M cached
800%cpu 15%user 0%nice 23%sys 758%idle 0%iow 4%irq 1%sirq 0%host
PID USER PR NI VIRT RES SHR S[%CPU] %MEM TIME+ ARGS
8460 u0_a417 20 0 41G 849M 308M S 22.6 7.6 23:58.65 com.netease.cloudmusic
8803 u0_a417 16 -4 22G 299M 188M S 10.6 2.6 7:54.15 com.netease.cloudmusic:play
1494 system 20 0 12G 33M 22M S 7.0 0.2 375:26.62 surfaceflinger
18551 shell 20 0 12G 6.0M 4.0M R 2.3 0.0 0:00.24 top
9643 u0_a417 20 0 20G 170M 119M S 2.3 1.5 1:46.99 com.netease.cloudmusic:pushservice
27119 root 20 0 0 0 0 I 2.0 0.0 1:55.01 [kworker/u16:2-bwmon_wq]
16823 root 20 0 0 0 0 I 1.6 0.0 0:07.72 [kworker/u16:11-memlat_wq]
5852 u0_a232 20 0 20G 118M 82M S 1.0 1.0 39:20.27 com.sonymobile.gameenhancer
316 root RT 0 0 0 0 S 0.6 0.0 24:06.41 [irq/38-190b6400]
14 root 20 0 0 0 0 S 0.6 0.0 35:29.60 [rcuog/0]
16817 root 20 0 0 0 0 I 0.3 0.0 0:12.96 [kworker/u16:4-bwmon_wq]
14833 root 20 0 0 0 0 I 0.3 0.0 0:00.54 [kworker/4:3-mm_percpu_wq]
14414 root 20 0 0 0 0 I 0.3 0.0 0:01.00 [kworker/3:0-mm_percpu_wq]
7476 u0_a422 16 -4 23G 120M 76M S 0.3 1.0 4:31.25 com.tencent.wetype
25566 u0_a422 10 -10 30G 203M 110M S 0.3 1.8 11:58.42 com.tencent.wetype:hld
4513 root 20 0 12G 2.7M 2.6M S 0.3 0.0 6:53.32 msm_irqbalance -f /system/vendor/etc/msm_irqbalance.conf
3231 network_sta+ 20 0 19G 94M 54M S 0.3 0.8 5:16.52 com.android.networkstack.process
1718 system 20 0 12G 3.3M 3.2M S 0.3 0.0 2:20.69 charge_service
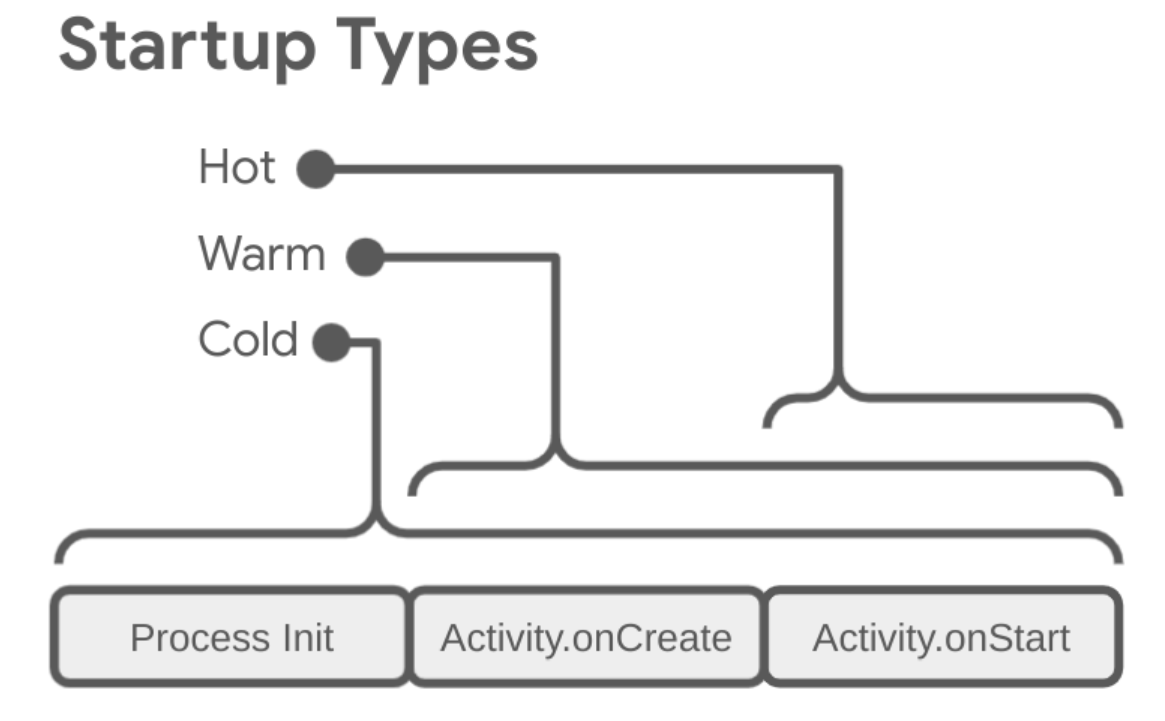
应用启动速度测试 三种启动类型 冷启动 设备刚开机,或者应用被杀死后,再次打开应用的场景。 在冷启动开始时,系统有以下三项任务:
加载并启动应用。 在启动后立即显示应用的空白启动窗口。 创建应用进程。 系统一创建应用进程,应用进程就负责后续阶段:
创建应用对象。 启动主线程。 创建主 activity。 膨胀视图。 创建屏幕布局。 执行初步绘制。 当应用进程完成第一次绘制时,系统进程就会换掉显示的后台窗口,将其替换为主 activity。此时,用户可以开始使用应用。
application创建
进程生成后,到Application创建,执行完onCreate方法,这个方法一般执行全局配置和第三方库的初始化,也是冷启动优化的重点目标之一。执行完后,即AMS的bindApplication方法走完,开始创建主线程,准备进入到Activity的流程。
activity 创建
在应用进程创建 activity 后,activity 将执行以下操作:
初始化值。 调用构造函数。 根据 activity 的当前生命周期状态,相应地调用回调方法,如 Activity.onCreate()。 通常,onCreate() 方法对加载时间的影响最大,因为它执行工作的开销最高:加载和膨胀视图,以及初始化运行 activity 所需的对象。
温启动 温启动,比如在退出应用后又重新启动应用。进程可能继续运行,但应用必须通过调用 onCreate() 从头开始重新创建 activity。 或者系统将您的应用从内存中逐出,然后用户又重新启动它。进程和 activity 需要重启,但传递到 onCreate() 的已保存实例 state bundle 对于完成此任务有一定助益。
热启动 Activity还在后台,如果应用的所有 activity 仍驻留在内存中,则应用可以避免重复执行对象初始化、布局膨胀和呈现。 但是,如果一些内存为响应内存整理事件(如 onTrimMemory())而被完全清除,则需要为了响应热启动事件而重新创建相应的对象。
服务类app添加窗口View 在Android中,将View初次添加到Window,之后再次添加的主要区别在于它们发生的时机和可能的影响。
冷启动-初次添加 当View第一次被添加到Window时,它会经历完整的布局和绘制刷流程这包括测量、布局和绘制阶段。
初次添加View时,系统会为其分配一个唯一的Window ID,并将其放置在Window的视图层次结构中。
热启动-再次添加 如果View已经被添加到Window,然后被移除。例如,通过调用removeView()或ViewGone(),再次添加它时,系统可能会尝试重用之前的Window ID。
再次添加View时,它可能不会经历完整的布局和绘制流程,特别是如果它的尺寸和位置没有改变。系统可能会尝试优化性能,只进行必要的更新。
如果View的状态(如可见性、尺寸、位置等)在移除和再次添加之间发生了变化,系统会相应地更新这些状态。
启动时间指标 Android 使用初步显示所用时间 (TTID) 和完全显示所用时间 (TTFD) 指标来优化冷应用启动和温应用启动。Android 运行时 (ART) 使用这些指标的数据来高效地预编译代码,以优化未来启动。
更快的启动速度可以促进用户与应用的持续互动,从而减少过早退出、重启实例或前往其他应用的情况。
TTID指标 获取初步显示时间TTID,直接在logcat中搜索”Displayed”:显示为1s470ms。
注意:在所有资源加载并显示之前,Logcat 输出中的 Displayed 指标不一定会捕获时间。它会省去布局文件中未引用的资源或被应用作为对象初始化一部分创建的资源。它之所以排除这些资源,是因为加载它们是一个内嵌进程,并且不会阻止应用的初步显示。
有时候,打印后面还有有一个附加的字段:
ActivityManager: Displayed com.android.myexample/.StartupTiming: +3s534ms (total +1m22s643ms)
total 时间测量值是从应用进程启动时开始计算,并且可以包含首次启动但未在屏幕上显示任何内容的另一个 activity。total 时间测量值仅在单个 activity 的时间和总启动时间之间存在差异时才会显示。
TTFD指标 如果有其他的异步操作影响了界面交互,需要在所有控件及数据状态加载完毕,确认可交互状态时,主动调用 reportFullyDrawn方法,以获取最高可达 TTFD 的信息。例如测试Demo中,填入一个长度为1000的recyclerView,完全显示后,主动调用此方法,打印出来的时间为 2s728ms ,比上面看的TTID要长不少。
填列表的代码如下:
MainScope (). launch {
val testList = mutableListOf < String >()
repeat ( 1000 ) {
delay ( 1L )
testList . add ( it . toString ())
}
binding . rvTestteste . apply {
layoutManager =
LinearLayoutManager ( this @MainActivity , LinearLayoutManager . VERTICAL , false )
adapter = SimpleAdapter ( testList )
}
reportFullyDrawn ()
}
在trace文件中查指标数据 抓取trace Android 9开始,系统内默认预制了Perfetto,但是需要手动开启。
adb shell
setprop persist.traced.enable 1
在shell下执行抓取命令,一般只抓取对应单个流程的trace数据,时间10s左右的。
perfetto -o /data/misc/perfetto-traces/trace_log -t 12s -b 100mb -s 150mb sched freq idle am wm gfx view input
参数说明:
-o trace文件输出路径 -t 抓取trace的时间 -b buffer大小 追加tags 抓哪些trace的模块 【谷歌分析Trace 文件的网站:http://ui.perfetto.dev/】
也可以直接用该网站的在线工具来抓取trace。
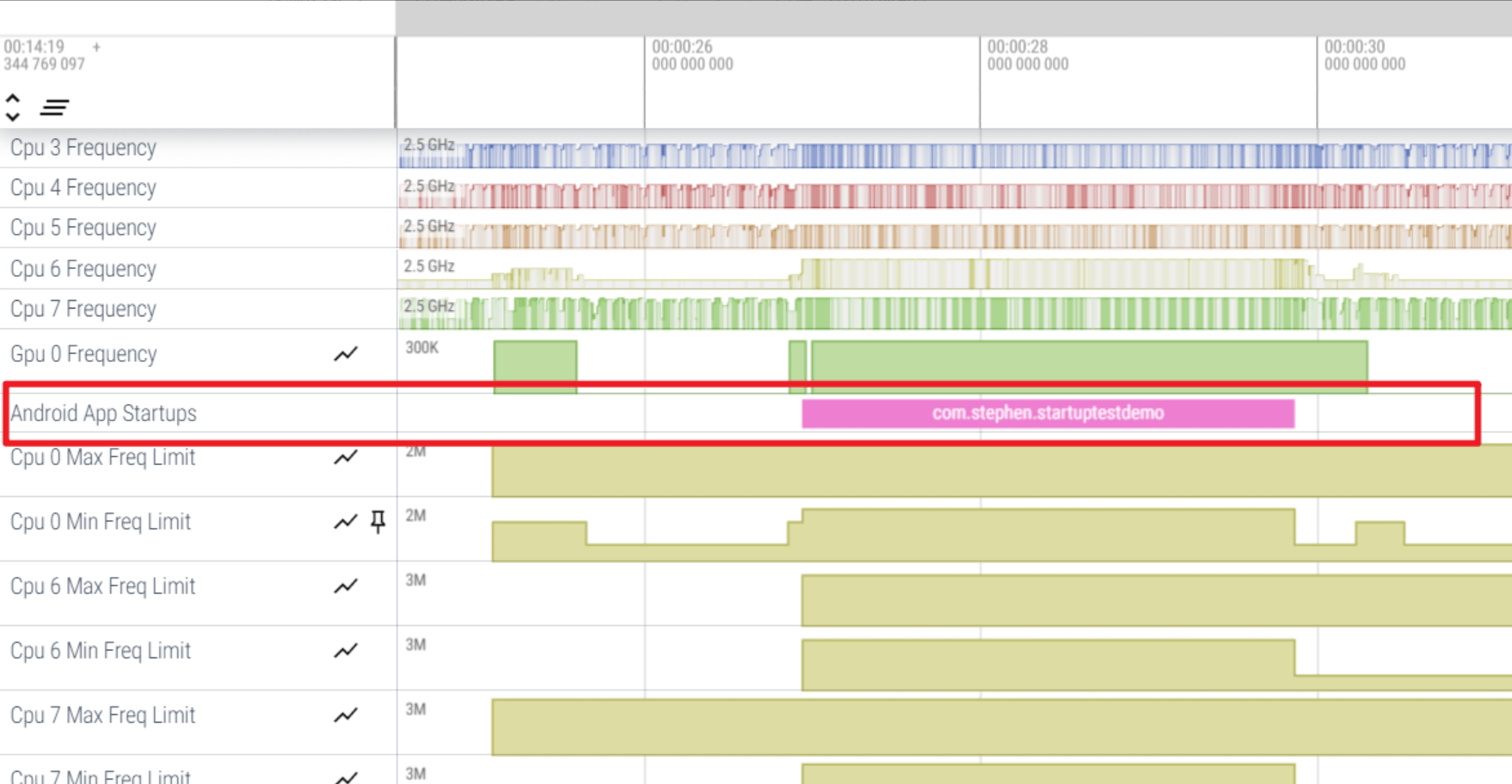
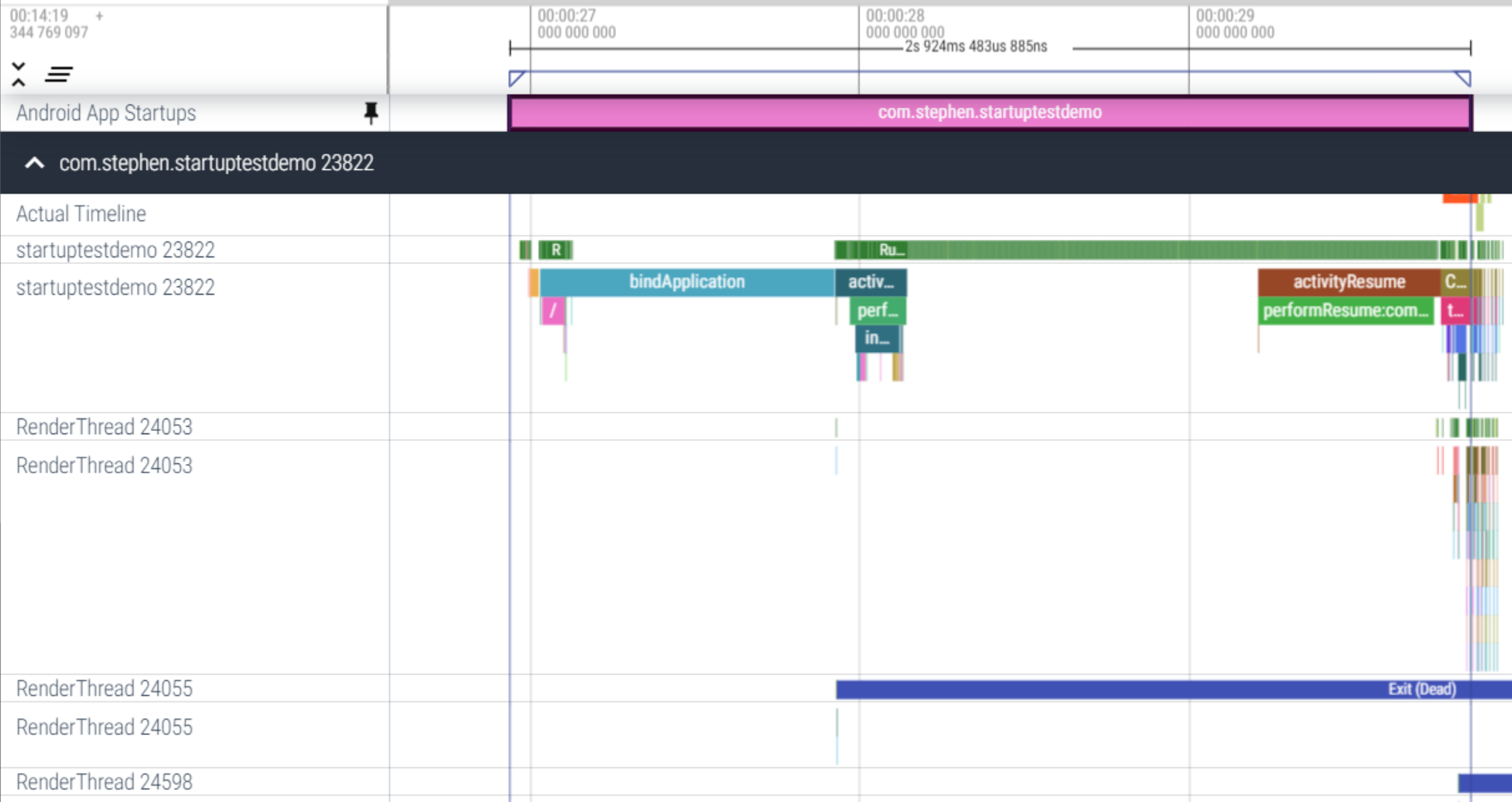
分析trace 在 Perfetto 中,找到包含“Android App Startups”派生指标的行。如果您没有看到该行,请尝试使用设备上的系统跟踪应用捕获跟踪记录。
选中这一slice,按m可以显示这一列的纵向区域。点图钉图标固定这一行,再去下面找详细的启动信息:
LeakCanary 是 Square 公司开源的一款用于检测 Android 应用中 内存泄漏(Memory Leak) 的自动化工具。它能够在应用运行时自动检测内存泄漏,尤其是像 Activity、Fragment 等组件的泄漏,并在发现泄漏时通过通知提醒开发者,同时提供详细的泄漏引用链信息,帮助开发者快速定位问题。
工作原理 主要分为以下几个主要阶段:
1. 监控 Activity 和 Fragment 的生命周期 在 Application 类中,通常会调用 LeakCanary.install(this)。这是 LeakCanary 的入口点。(在2.0版本已经实现了隐式调用,无需手动调用install方法)
LeakCanary 2.0 利用了 Android 的 ContentProvider 自动初始化机制,通过在库中注册一个内部的 LeakCanaryInstaller ContentProvider,系统会在 Application.onCreate() 之前自动初始化它。这样设计有几个好处:一是简化了集成流程,开发者 只需添加依赖 即可;二是实现了自动按需初始化,只在 debug 构建中工作;三是遵循了现代 Android 库的设计趋势。这种改变使得内存泄漏检测对开发者更加透明和无侵入。
LeakCanary 通过注册 Application.ActivityLifecycleCallbacks 和 FragmentManager.FragmentLifecycleCallbacks 来监听所有 Activity 和 Fragment 的生命周期事件。
在这期间,还会初始化后台线程池。LeakCanary 会创建一个专门的后台线程池来执行耗时的操作,例如后面的堆转储操作,以避免阻塞主线程。初始化通知管理器,用于在检测到泄漏或进行堆转储时显示通知。
2. 检测内存泄漏 监听onDestroy回调 以Activity为例,当用户退出一个 Activity 时, Activity 的 onDestroy() 方法会被调用。
由于 LeakCanary 注册了 Application.ActivityLifecycleCallbacks ,它会接收到这个 Activity 的 onDestroyed 回调。
在收到 onDestroyed 回调通知后,LeakCanary 会对即将被销毁的 Activity 对象创建一个特殊的 KeyedWeakReference 。这个 KeyedWeakReference 不仅仅是一个普通的弱引用,它还包含一个唯一的 key 和一些元数据(如 Activity 的类名、创建时间等),用于在后续分析中识别对象。
这个 KeyedWeakReference 会被添加到 LeakCanary 内部的一个 ObjectWatcher 维护的观察列表中。
检查弱引用观测列表 LeakCanary 内部有一个周期性的任务,会定期在后台线程中运行。在这个任务中,LeakCanary 会主动调用 System.gc() 来触发一次垃圾回收。
需要注意的是,System.gc() 只是建议 JVM 进行垃圾回收,并不能保证立即执行或完全清除所有可回收对象。 LeakCanary 会多次尝试 GC,以提高清除弱引用的概率。
在 GC 之后,LeakCanary 会遍历之前创建的集合,查看其中的弱引用是否已经被清除。
弱引用已清除: 如果 KeyedWeakReference.get() 返回 null,说明它引用的 Activity 对象已经被垃圾回收了。这表示 Activity 正常地被销毁, 没有发生内存泄漏 。这个 KeyedWeakReference 就会从集合中移除。 弱引用未清除(被保留): 如果 KeyedWeakReference.get() 仍然返回 非 null ,说明它引用的 Activity 对象仍然存在于内存中,它其实应该是被销毁的。此时,LeakCanary 就认为这个 Activity 对象被“保留(retained)”了,并且很可能发生了内存泄漏。 LeakCanary 会在 Logcat 中打印一条信息,指示哪个 Activity 被保留了。 3. 触发堆转储 LeakCanary 会统计被保留对象的数量。默认情况下,当被保留对象的数量达到 5个(可配置)时,LeakCanary 会触发一次堆转储。这是为了避免频繁的堆转储对用户体验造成影响。
应用在后台: 如果应用进入后台,LeakCanary 会更积极地触发堆转储,默认情况下,只要监测到被保留对象时就会触发。因为在后台时,堆转储对用户体验的影响较小。
当触发堆转储时,LeakCanary 会显示一个 Toast 提示用户,同时在通知栏显示一个进度通知。
LeakCanary 会调用 Debug.dumpHprofData(filePath) 方法将当前 Java 堆的完整快照保存为一个 .hprof 文件到应用的私有存储空间。这个过程是一个耗时操作,会短暂地阻塞应用的主线程。
堆转储对于内存泄漏分析至关重要,但它确实是一个资源密集型操作 ,对应用性能有显著影响,主要因为 性能开销高 ,堆转储需要遍历和记录应用程序内存中的所有可达对象。对于大型应用或包含大量对象的应用,这个过程会涉及大量的 CPU 计算和 I/O 操作。在执行堆转储时,Java 虚拟机通常需要暂停所有应用线程(”Stop-The-World”)以确保内存状态的稳定性和一致性。这意味着你的应用会暂时失去响应,UI 会卡顿甚至冻结几秒钟,用户体验会受到严重影响。将整个内存快照写入 .hprof 文件是一个大量的磁盘写入操作。
堆转储 过程本质上是把整个应用程序的内存快照保存到一个文件中,然后对其进行分析。具体来说,堆转储会执行以下关键任务:
停止应用进程,为了确保内存快照的完整性和一致性,确保所有对象的状态在转储时是静态的。 遍历所有可达对象,Java 虚拟机(JVM)会遍历当前进程内存中所有 可达 (reachable) 的对象。这意味着从根对象(如线程栈、静态变量等)开始,沿着对象引用图遍历所有可以访问到的对象。 记录对象信息,对于每个遍历到的对象,堆转储会记录其重要信息,包括对象的类名,大小,字段值,引用关系。 将内存快照写入文件 (.hprof):所有这些对象信息会被序列化并写入一个特定的文件格式,通常是 .hprof (Heap PROFile) 文件。 4. 分析堆转储文件与展示 为了不影响应用的主进程,LeakCanary 会在一个 独立的后台进程 中启动一个服务(HeapAnalyzerService)来处理 .hprof 文件的分析。这样做的好处是即使堆分析崩溃或出现内存问题,也不会影响到应用本身。
在分析进程中,LeakCanary 会查找那些 应该被垃圾回收但仍然被引用的对象 。它会逆向追溯引用链,找出导致对象无法被回收的“罪魁祸首”(即泄漏路径)。最后,LeakCanary 会通过通知或其他方式向你报告发现的内存泄漏,并提供详细的引用链,帮助你定位问题。
对堆转储文件的分析会使用 LeakCanary 内部的 Shark 库来解析 .hprof 文件。
查找 GC Roots:Shark 会首先识别出所有的 GC Roots (垃圾回收的根对象)。 遍历对象图:从 GC Roots 开始,Shark 会遍历整个对象图,查找所有可达的对象 。 定位被保留对象: Shark 会通过之前 KeyedWeakReference 中存储的 key 来定位到之前被标记为 “被保留” 的对象。 计算最短强引用路径: 这是分析的核心。Shark 会从 GC Roots 到被保留对象之间,计算出最短的强引用路径 。这个路径就是导致泄漏的“泄漏跟踪(leak trace)”。它会显示哪些对象持有对泄漏对象的强引用,直到某个 GC Root。 过滤已知泄漏:LeakCanary 内置了一些规则,可以识别并忽略一些 Android 框架内部的已知泄漏,避免误报。 识别可疑点: LeakCanary 会尝试根据泄漏跟踪识别出最可能导致泄漏的代码位置或对象类型。 哪些可以作为GC Roots的对象呢?Java 语言中包含了如下几种:
1)虚拟机栈(栈帧中的本地变量表)中的引用的对象。
2)方法区中的类静态属性引用的对象。
3)方法区中的常量引用的对象。
4)本地方法栈中JNI(即一般说的Native方法)的引用的对象。
5)运行中的线程
6)由引导类加载器加载的对象
7)GC控制的对象
分析完成后,LeakCanary 会在通知栏弹出一条通知,提示开发者检测到了内存泄漏。
提供一个直观的 UI 界面(通常是 LeakActivity),展示泄漏对象的详细信息,包括:
泄漏对象的类型(如 MainActivity)。 泄漏对象的引用链(即哪些对象持有了它的引用)。 可能的泄漏原因分析(如静态变量持有、Handler 未释放等)。 开发者可以通过这个界面快速定位问题,并进行修复。
自制简单Demo实现 按照如上的设计理念,我们也可以自己尝试实现一个简单的Activity泄露检测工具。以下是一个简单的例子,实现了生命周期监听,循环检查走了 onDestroy 回调的 Activity 是否被及时回收。
object LeakActivityTest {
private val weakReferenceMap = mutableMapOf < String , WeakReference < Activity >>()
private val supervisedCoroutine =
CoroutineScope ( Dispatchers . IO + SupervisorJob () + CoroutineExceptionHandler { _ , throwable ->
infoLog ( "CoroutineExceptionHandler: ${throwable.message}" )
})
private lateinit var loopCheckJob : Job
private val activityLifecycleCallbacks = object : ActivityLifecycleCallbacks {
override fun onActivityCreated ( p0 : Activity , p1 : Bundle ?) {
}
override fun onActivityStarted ( p0 : Activity ) {
}
override fun onActivityResumed ( p0 : Activity ) {
}
override fun onActivityPaused ( p0 : Activity ) {
}
override fun onActivityStopped ( p0 : Activity ) {
}
override fun onActivitySaveInstanceState ( p0 : Activity , p1 : Bundle ) {
}
override fun onActivityDestroyed ( p0 : Activity ) {
infoLog ( "==========>onActivityDestroyed<==========" )
infoLog ( "activity: ${p0::class.java.simpleName}" )
weakReferenceMap [ p0 :: class . java . simpleName ] = WeakReference ( p0 )
System . gc ()
}
}
/**
* 注册 ActivityLifecycleCallbacks
*/
fun registerActivityLifecycleCallbacks ( application : Application ) {
application . registerActivityLifecycleCallbacks ( activityLifecycleCallbacks )
}
/**
* 循环检查弱引用是否被回收
*/
fun startLoopCheckLeak () {
loopCheckJob = supervisedCoroutine . launch {
while ( true ) {
Thread . sleep ( 1000 )
// print size
infoLog ( "weakReferenceMap size: ${weakReferenceMap.size}" )
weakReferenceMap . forEach {
if ( it . value . get () == null ) {
infoLog ( "activity: ${it.key} has been destroyed" )
} else {
infoLog ( "activity: ${it.key} is still alive" )
}
}
}
}
}
fun release () {
loopCheckJob . cancel ()
}
}
LeakCanary 的优点 LeakCanary 是一款非常优秀的内存泄漏检测工具。
具体来具有以下优点:
自动化程度高:无需手动触发,自动检测内存泄漏,适合开发和测试阶段使用。 直观易用:提供清晰的 UI 界面展示泄漏信息,帮助开发者快速定位问题。 轻量级:对应用性能影响较小,不会显著增加应用的体积或运行时开销。 开源免费:由 Square 公司维护,代码开源,社区活跃,易于集成和定制。 LeakCanary 的局限性 尽管 LeakCanary 是一款非常优秀的内存泄漏检测工具,但它也有一些局限性:
仅针对 Activity 和 Fragment:默认情况下,LeakCanary 主要检测 Activity 和 Fragment 的泄漏,其他对象(如自定义 View、Service 等)需要手动扩展。 Heap Dump 分析耗时:生成和分析 Heap Dump 可能会消耗一定的时间和内存资源,尤其是在内存较大的应用中。 无法实时监控:LeakCanary 是在对象销毁后检测泄漏,无法实时监控内存的使用情况(如内存增长趋势)。 对 ProGuard/R8 混淆支持有限:如果应用启用了代码混淆,泄漏引用链中的类名和方法名可能会被混淆,增加分析难度(但 LeakCanary 提供了一定的反混淆支持)。 任何一种UI框架,应该都会维护一个需要绘制的节点树,在View中也会有一个View控件树的存在。
Slot Table结构 Compose Runtime 采用了一种特殊的数据结构,称为 Slot Table 。
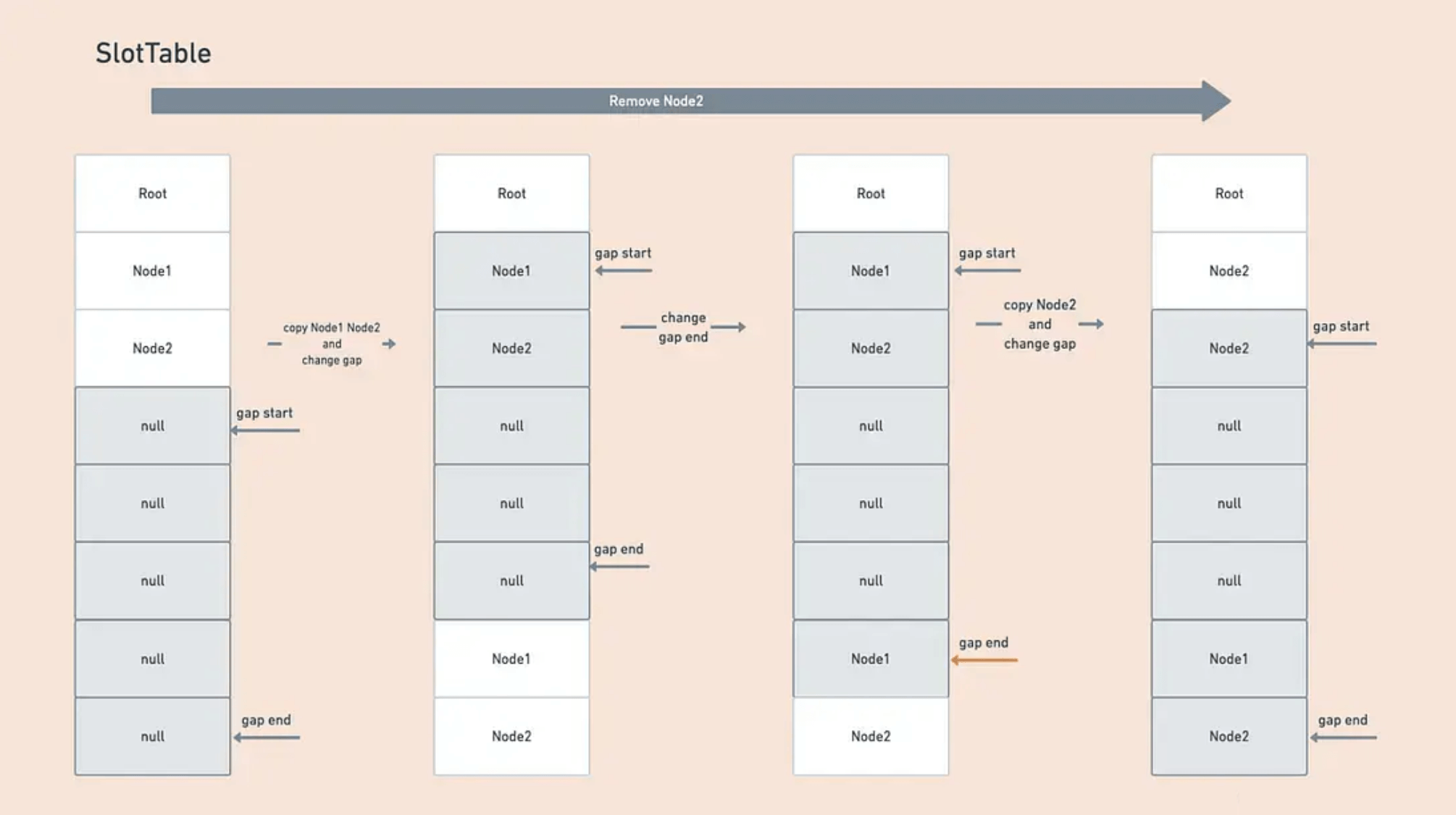
Slot Table 与常用于文本编辑器的另一数据结构 Gap Buffer 相似,这是一个在连续空间中存储数据的类型, 底层采用数组实现 。区别于数组常用方式的是,它的剩余空间,称为 Gap,可根据需要移动到 Slot Table 中的任一区域,这让它在 数据插入与删除时更高效 。
以数据删除为例,如下图:
绘制阶段 Compose要显示界面,也有三个阶段:
组合:要显示什么样的界面。Compose 运行可组合函数并创建界面说明。 布局:要放置界面的位置。该阶段包含两个步骤:测量和放置。对于布局树中的每个节点,布局元素都会根据 2D 坐标来测量并放置自己及其所有子元素。 绘制:渲染的方式。界面元素会绘制到画布(通常是设备屏幕)中。 这些阶段通常会以相同的顺序执行,让数据能够 沿一个方向(从组合到布局,再到绘制)生成帧(也称为单向数据流) 。BoxWithConstraints 以及 LazyColumn 和 LazyRow 是值得注意的特例,其子级的组合取决于父级的布局阶段。
从概念上讲,每个帧都会经历这 3 个阶段;
但为了优化性能,Compose 会避免在所有这些阶段中重复执行根据相同输入计算出相同结果的工作。如果可以重复使用前面计算出的结果,Compose 会跳过对应的可组合函数;如果没有必要,Compose 界面不会对整个树进行重新布局或重新绘制。
Compose 只会执行更新界面所需的最低限度的工作。
之所以能够实现这种优化,是因为 Compose 会跟踪不同阶段中的状态读取。
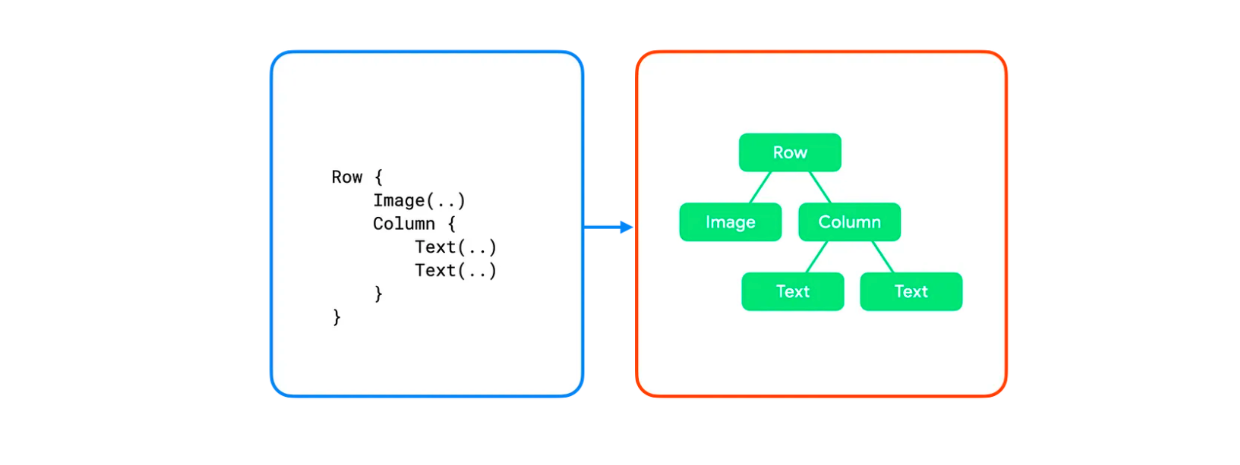
组合 这一步是将各个LayoutNode上树的过程。
代码中的每个可组合函数都会映射到界面树中的单个布局节点。在更复杂的示例中,可组合项可以包含逻辑和控制流,并根据不同的状态生成不同的树。
布局 在布局阶段,Compose 会使用组合阶段生成的界面树作为输入。
在布局阶段,系统会使用以下三步算法遍历树:
测量子项:节点会测量其子项(如果有)。 确定自己的尺寸:节点根据这些测量结果确定自己的尺寸。 放置子项:每个子节点都相对于节点自身的位置进行放置。 在此阶段结束时,每个布局节点都具有:
以上面的节点树为例,算法的工作原理如下:
Row 会测量其子项 Image 和 Column。 系统会测量 Image。它没有任何子节点,因此它会自行确定自己的尺寸,并将尺寸报告回 Row。 接下来,系统会测量 Column。它会先测量自己的子项(两个 Text 可组合项)。 系统会测量第一个 Text。它没有任何子项,因此它会自行确定自己的尺寸,并将其尺寸报告回 Column。 测量第二个 Text。它没有任何子节点,因此它会自行确定自己的尺寸,并将其报告回 Column。 Column 使用子测量结果来确定自己的大小。它使用子项的最大宽度和子项高度的总和。 Column 会相对于自身放置其子项,将它们垂直放置在彼此下方。 Row 使用子测量结果来确定自己的大小。它使用子项的最大高度和子项宽度的总和。然后放置其子项。 请注意,每个节点都只被访问了一次。Compose 运行时只需对界面树进行一次遍历即可测量和放置所有节点,从而提高性能。
当树中的节点数量增加时,遍历树所花费的时间会以线性方式增加。
相反,类比View的架构,如果每个节点被访问多次,则遍历时间会呈指数级增加。这就是为什么在View里面写嵌套结构,会大大影响界面的绘制速度。
绘制 使用上例,树内容会按如下方式绘制:
Row 会绘制它可能具有的任何内容,例如背景颜色。 Image 会自行绘制。 Column 会自行绘制。 第一个和第二个 Text 分别绘制自身。 Compose 在 Android 上的实现最终依赖于 AndroidComposeView,且这是一个 ViewGroup ,那么按原生视图渲染的角度,看一下 AndroidComposeView 对 onDraw() 与 dispatchDraw() 的实现,即可看到 Compose 渲染的原理。
internal class AndroidComposeView(context: Context) :
ViewGroup(context), Owner, ViewRootForTest, PositionCalculator {
...
override fun onDraw(canvas: android.graphics.Canvas) {
}
...
override fun dispatchDraw(canvas: android.graphics.Canvas) {
...
measureAndLayout()
// we don't have to observe here because the root has a layer modifier
// that will observe all children. The AndroidComposeView has only the
// root, so it doesn't have to invalidate itself based on model changes.
canvasHolder.drawInto(canvas) { root.draw(this) }
...
}
...
}
CanvasHolder.drawInto() 将 android.graphics.Canvas 转化为 androidx.compose.ui.graphics.Canvas 实现传递至顶层 LayoutNode 对象 root 的 LayoutNode.draw() 函数中,实现视图树的渲染。
每个阶段的状态读取影响 组合 @Composable 函数或 lambda 代码块中的 状态读取会影响组合阶段,并且可能会影响后续阶段 。
当状态值发生更改时,Recomposer 会安排重新运行所有要读取相应状态值的可组合函数。
如果输入未更改,运行时可能会决定跳过部分或全部可组合函数。如需了解详情,请参阅如果输入未更改,则跳过。
根据组合结果,Compose 界面会运行布局和绘制阶段。如果内容保持不变,并且大小和布局也未更改,界面可能会跳过这些阶段。
布局 布局阶段包含两个步骤:测量和放置。
测量步骤会运行传递给 Layout 可组合项的测量 lambda、LayoutModifier 接口的 MeasureScope.measure 方法,等等。
放置步骤会运行 layout 函数的放置位置块、Modifier.offset { … } 的 lambda 块,等等。
每个步骤的状态读取都 会影响布局阶段,并且可能会影响绘制阶段 。当状态值发生更改时,Compose 界面会安排布局阶段。如果 大小或位置发生更改,界面还会运行绘制阶段 。
更确切地说,测量步骤和放置步骤分别具有单独的重启作用域,这意味着,放置步骤中的状态读取不会在此之前重新调用测量步骤。不过,这两个步骤通常是交织在一起的,因此在放置步骤中读取的状态可能会影响属于测量步骤的其他重启作用域。
绘制 绘制代码期间的状态读取会影响绘制阶段。
常见示例包括 Canvas()、Modifier.drawBehind 和 Modifier.drawWithContent。当状态值发生更改时,Compose 界面只会运行绘制阶段。
Compose导航组件是Jetpack Compose中的一个重要组件,用于管理应用程序中的页面导航流程。它提供了一种简单而灵活的方式来管理不同的屏幕和页面之间的导航。
之前的View架构一般是单Activity,多个Fragment,或者多Activity模式。Compose则是多Activity,多个Composable。
页面跳转单方式有很多,官方推荐的是使用Navigation组件。
依赖配置 主要有三个地方:
首先是navigation-compose组件的依赖配置。 界面在导航时有传参数的需求的话,需要使用kotlin的序列化注解来标注数据类或者单例类,需要配置kotlin的序列化插件。 最后是序列化的依赖配置。 [versions]
kotlin = "2.1.0"
navigation = "2.8.5"
serialization = "1.7.3"
[libraries]
androidx-navigation-compose = { group = "androidx.navigation" , name = "navigation-compose" , version.ref = "navigation" }
serialization = { group = "org.jetbrains.kotlinx" , name = "kotlinx-serialization-json" , version = "serialization" }
[plugins]
jetbrains-kotlin-serialization = { id = "org.jetbrains.kotlin.plugin.serialization" , version.ref = "kotlin" }
Navigation三要素 NavHost 包含当前导航目的地的界面元素。也就是说,当用户浏览应用时,该应用实际上会在导航宿主中切换目的地。
NavGraph 一种数据结构,用于定义应用中的所有导航目的地以及它们如何连接在一起。
NavController 用于管理目的地之间导航的中央协调器。该控制器提供了一些方法,可在目的地之间导航、处理深层链接、管理返回堆栈等。
类比我们开车的场景,NavHost就是车,NavGraph就是路,NavController就是司机。
首先在起始地点,然后确定路线,然后司机控制车去往目的地。
使用 第一步,起始地点,在应用中,就是应用的首页,开屏进入之后的第一个页面。随便取一个HomePage
@Composable
fun HomePage () {
Column {
Text ( text = "Home Page" )
Button ( onClick = { /*TODO*/ }) {
Text ( text = "Go to Detail" )
}
}
}
第二步,确定路线,也就是NavGraph,定义导航图。这里需要先定义好需要跳转的页面。
@Composable
fun HomePage ( homeDate : HomeData , homeToAbout : () -> Unit ) {
Box ( modifier = Modifier . fillMaxSize ( 1f ), contentAlignment = Alignment . Center ) {
Column {
Text ( text = "HomePage data: ${homeDate.name}" )
Button ( onClick = homeToAbout ) {
Text ( text = "HomeToAbout" )
}
}
}
}
@Composable
fun AboutPage ( backStack : () -> Unit ) {
Box (
modifier = Modifier . fillMaxSize ( 1f ),
contentAlignment = Alignment . Center
) {
Text ( text = "AboutPage" )
Button ( onClick = backStack ) {
Text ( text = "Goto HomePage" )
}
}
}
导航过程中传参数和页面标记,我们定义两个数据类来标记:
@Serializable
data class HomeData ( val name : String )
@Serializable
object About
创建导航图:
val navController = rememberNavController ()
val graph = remember {
navController . createGraph ( startDestination = HomeData ( "initial data" )) {
composable < HomeData > { navBackStackEntry ->
val homeData = navBackStackEntry . toRoute < HomeData >()
HomePage ( homeDate = homeData ) {
navController . navigate ( About )
}
}
composable < About > {
AboutPage {
navController . navigate ( HomeData ( "about page to home page" ))
}
}
}
}
NavHost ( navController = navController , graph = graph )
使用时,更简化的写法可以像下面这样。
直接将NavGraph的第二个参数放在末尾,NavHost后面写成lambda的形式。
NavHost ( navController = navController , startDestination = ScreenTitle . Home . name ) {
composable ( route = ScreenTitle . Home . name ) {
HomeScreen (
weatherScreenState ,
onNavToAbout = { navController . navigate ( ScreenTitle . About . name ) },
onNavToAuthor = { navController . navigate ( ScreenTitle . Author . name ) })
}
composable ( route = ScreenTitle . About . name ) {
AboutScreen ( onBack = { navController . popBackStack () })
}
composable ( route = ScreenTitle . Author . name ) {
AuthorScreen ( onBack = { navController . popBackStack () })
}
}
为了统一管理提高可扩展性,我们可以使用一个密封类来管理所有的页面的导航路由数据。
@Serializable
sealed class Screen ( val route : String ) {
@Serializable
object MainPage : Screen ( "mainPage" )
@Serializable
object ArticlePage : Screen ( "articlePage" )
@Serializable
object PicturePage : Screen ( "picturePage" )
@Serializable
object ElsePage : Screen ( "elsePage" )
}
更新UI流程对比 View架构 在原生的View,命令式架构中,如果要使用新的数据,来刷新更改某个控件的显示状态,可以调用这个控件类的状态set方法,例如将某个TextView的文本内容进行修改:
binding . tvTest . text = "test a very very very very very very long text"
TextView的setText方法会触发重新绘制,但是如果这个TextView的父控件的宽高没有发生变化,那么就不会触发重新绘制。如果这个父控件的宽高发生了变化,那么就会触发重新绘制。并且所有受影响的View和ViewGroup控件均会更新。
Compose架构 在 Compose 架构中,您只需要更新这个新的可观察状态的数据,然后就可以自动地重新调用一次可组合函数。这样做会导致函数进行重组。Compose 框架可以智能地仅重组已更改的组件。大致的更新流程上我认为是相同的,尽量只更新受影响的Composeable函数。
这里感受感受写法的差异。
例如,假设有以下可组合函数,用于显示一个按钮,并记录点击的次数:
@Composable
fun TestDemo (){
var clickTimes by remember { mutableStateOf ( 0 ) }
ClickCounter ( clickTimes ){
clickTimes ++
}
}
@Composable
fun ClickCounter ( clicks : Int , onClick : () -> Unit ) {
Button ( onClick = onClick ) {
Text ( "I've been clicked $clicks times" )
}
}
每次点击该按钮时,调用方都会在lambda里更新 clicks 的值。Compose 会再次调用 lambda 与 Text 函数以显示新值;此过程称为“重组”。不依赖于该值的其他函数不会进行重组。
Compose 编译器在背后做了大量工作来保证 recomposition 范围尽可能小,从而避免了无效开销。
重组作用域 还是以这个流程举例
val TAG = "TestDemoPage"
@Composable
fun TestDemo () {
var clickTimes by remember { mutableStateOf ( 0 ) }
Log . d ( TAG , "TestDemo recomposition" )
Button ( onClick = { clickTimes += 1 }. also {
Log . d ( TAG , "lambda recomposition" )
}) {
Log . d ( TAG , "Button content recomposition" )
Text ( "I've been clicked $clickTimes times" ). also {
Log . d ( TAG , "Text recomposition" )
}
}. also {
Log . d ( TAG , "Button recomposition" )
}
}
当按钮点击之后,只有Text和Button内容这个lambda会进行重组。外部的TestDemo和这个Button组件不会进行重组。
为什么不是只有Text进行重组呢?
因为Android系统基于C++编译的虚拟机,在调用到clickTimes变化之后,实际会走两个步骤,将这个新的clickTimes拼接成一个新字符串:
I ' ve been clicked $ clickTimes times
然后将这个新的字符串赋值给Text的text属性,这个过程是在Button的lambda中完成的,所以需要将Button Content这个lambda也进行重组。
将委托改为等于 val clickTimes = remember { mutableStateOf ( 0 ) }
这种写法会导致Button和外部的TestDemo重组吗?
依然不会。
将字符串提取到外面 val TAG = "TestDemoPage"
@Composable
fun TestDemo () {
var clickTimes by remember { mutableStateOf ( 0 ) }
Log . d ( TAG , "TestDemo recomposition" )
val stringTest = "I've been clicked $clickTimes times"
Button ( onClick = { clickTimes += 1 }. also {
Log . d ( TAG , "lambda recomposition" )
}) {
Log . d ( TAG , "Button content recomposition" )
Text ( stringTest ). also {
Log . d ( TAG , "Text recomposition" )
}
}. also {
Log . d ( TAG , "Button recomposition" )
}
}
这种写法会导致Button和外部的TestDemo重组吗?
答案是上面所有的打印log的地方都会参与重组,因为stringTest是一个变量,外部的TestDemo和Button对它都有read的可能,这个变量的变化会影响到所有的读取方。
所以,这种变量里直接使用了remember变量的写法是不推荐的。
日志:
TestDemo recomposition
lambda recomposition
Button content recomposition
Text recomposition
Button recomposition
插入 重组顺序 还可以看出重组的顺序是从clickTimes这个变量的最紧密的读取方开始,发散进行的。
首先stringTest是直接使用方,所以拥有这个变量的TestDemo会进行重组。 lambda代码块在编译后会编译成静态方法,在TestDemo重组调用后,会立即调用lambda代码块的初始化方法,即对其进行重组。 Button内容的lambda重组原理同上 Text和Button的重组就是Compose的正常流程,编译之后的调用顺序为从内部到外部调用。 将Text用Box包一层 如果我们再使用Box这个组件包裹一下Text,会有什么效果呢?
val TAG = "TestDemoPage"
@Composable
fun TestDemo () {
var times by remember { mutableStateOf ( 0 ) }
Log . d ( TAG , "TestDemo recomposition" )
val stringTest = "I've been clicked $times times"
Button ( onClick = { times += 1 }. also {
Log . d ( TAG , "lambda recomposition" )
}) {
Log . d ( TAG , "Button content recomposition" )
Box {
Log . d ( TAG , "Box recomposition" )
Text ( stringTest ). also {
Log . d ( TAG , "Text recomposition" )
}
}
}. also {
Log . d ( TAG , "Button recomposition" )
}
}
日志打印:
TestDemo recomposition
lambda recomposition
Button content recomposition
Box recomposition
Text recomposition
Button recomposition
可以看到Box的重组是在Button内容的lambda重组之后进行的。而不是在Text的重组最后面。
这是为什么呢?
因为Box的实现是一个inline方法,编译之后会被铺平到调用的地方,而不是按照像Button和Text的层级结构从内到外。
所以Box这种inlne方法,是不会算作为最小重组范围内的。而是和其调用的组件共享重组优先级。
同样的,Column、Row、Box 乃至 Layout 这种容器类 Composable 都是 inline 函数。
优化重组范围最小化 在上面的例子中,我们可以看到,一些看起来类似的写法,所产生的最小重组范围是不一样的。
那么如何优化代码,使重组范围最小化呢。
我们可以使用一个非inline的Composable函数包裹起来,这样就可以避免Box的这种情况。
val TAG = "TestDemoPage"
@Composable
fun TestDemo () {
var times by remember { mutableStateOf ( 0 ) }
Log . d ( TAG , "TestDemo recomposition" )
Button ( onClick = { times += 1 }. also {
Log . d ( TAG , "lambda recomposition" )
}) {
Log . d ( TAG , "Button content recomposition" )
Wrraper {
Text ( "I've been clicked $times times" ). also {
Log . d ( TAG , "Text recomposition" )
}
}
}. also {
Log . d ( TAG , "Button recomposition" )
}
}
@Composable
fun Wrraper ( content : @Composable () -> Unit ) {
Log . d ( TAG , "Wrraper recomposition" )
Box {
Log . d ( TAG , "Box recomposition" )
content ()
}
}
这样在点击之后,所需要重组范围的就只有Text一个组件了。
结论 Compose 在编译期分析出会受到某 state 变化影响的代码块,并记录其引用,当此 state 变化时,会根据引用找到这些代码块并标记为 Invalid 。在下一渲染帧到来之前 Compose 会触发 recomposition ,并在重组过程中执行 invalid 代码块。Invalid 代码块即编译器找出的下次重组范围。能够被标记为 Invalid 的代码必须是非 inline 且无返回值的 @Composalbe function/lambda,必须遵循 重组范围最小化 原则。
使用Jetpack Compose有很长一段时间了,最近也有在开发跨平台的版本CMP。结合网络上和实际项目的应用,分享几个可以增强性能,提升可读性和可维护性的Compose开发技巧。
状态提升 这个在很多地方都有提到,可以提升Composable的可测试性和可维护性。
具体来说,就是将Composable的状态提升到父Composable中,由父Composable来管理和维护状态,而子Composable只负责展示和交互。这样可以避免子Composable的状态和逻辑与父Composable的状态和逻辑耦合在一起,从而提高代码的可维护性和可测试性。
例如一个简单的计数组件:
@Composable
fun Counter ( count : Int , onIncrement : () -> Unit ) {
Button ( onClick = onIncrement ) {
Text ( "Clicked $count times" )
}
}
MVI架构设计 这个核心理念用一句话概括就是:数据向下流动,事件向上流动 。
ViewModel组件来管理维护数据状态 View层的Composable组件来观测数据 操作和输入事件通过回调的方式向上流动,触发ViewModel的状态更新 还是以计数为例:
// ViewModel
class CounterViewModel : ViewModel () {
private val _count = mutableStateOf ( 0 )
val count : State < Int > = _count
fun increment () {
_count . value ++
}
}
// View
@Composable
fun CounterScreen ( viewModel : CounterViewModel = viewModel ()) {
val count by viewModel . count . collectAsState ()
Counter (
count = count ,
onIncrement = viewModel :: increment
)
}
插槽化设计 将通用的父组合项抽离出来,将子组合项以插槽的形式传递进去,实现代码的复用和灵活性。
@Composable
fun FancyCard ( content : @Composable () -> Unit ) {
Card {
content ()
}
}
Composed的相当一部分的官方API都是这样设计的。
ViewModel层使用StateFlow作为数据状态 LiveData这个类在Compose中已经不推荐使用了,因为它的设计初衷是为了与传统的Android组件(如Activity和Fragment)进行集成,而Compose是一个基于声明式UI的框架,不依赖于传统的组件生命周期。使用StateFlow可以提供更好的Kotlin适配和灵活性。
class MainViewModel : ViewModel () {
private val _themeState = MutableStateFlow ( ThemeState . DEFAULT )
val themeStateStateFlow = _themeState . asStateFlow ()
fun setThemeState ( themeState : ThemeState ) {
_themeState . value = themeState
}
}
// View
@Composable
fun MainScreen ( viewModel : MainViewModel = viewModel ()) {
val themeState by viewModel . themeStateStateFlow . collectAsState ()
LaunchEffect ( themeState ) {
// 处理主题状态变化
}
}
Composables分类 将各个可组合项分类,如状态相关的、布局相关的、样式相关的等,方便管理和维护。有的只需要显示固定的UI,有的是响应数据变化的组件。
// 状态相关的Composable
@Composable
fun Counter ( count : Int , onIncrement : () -> Unit ) {
Button ( onClick = onIncrement ) {
Text ( "Clicked $count times" )
}
}
使用脚手架Scaffold组件 对于移动端来说,界面的布局一般是有固定的部分,如顶部的导航栏、底部的底部栏等。这些部分可以使用Scaffold组件来实现。
@Composable
fun MainScreen () {
Scaffold (
topBar = {
TopAppBar (
title = { Text ( "Compose Scaffold" ) }
)
},
bottomBar = {
BottomAppBar {
Button ( onClick = { /* 处理底部按钮点击 */ }) {
Text ( "底部按钮" )
}
}
}
) { innerPadding ->
// 主要内容区域
}
}
对列表类控件,设置元素的key减少重组,配置动效 列表类控件,如LazyColumn、LazyRow等,在Compose中使用时,需要为每个列表项设置一个唯一的key,这样可以帮助Compose在列表项发生变化时,只重新组合发生变化的项,而不是全部重新组合。
LazyColumn {
items ( items = items , key = { item -> item . id }) { item ->
ListItem ( item )
}
}
有了这个key标识之后,Compose列表项还可以对每一个item组件都应用动效,比如一个元素A前面再插入一个元素B,元素A的位置变化就不是闪现,而是平滑的过渡。注意列表原数据中的每一个元素的key都要求唯一,如果出现了重复的key标识,会报运行错误。
DerivedStateOf derivedStateOf 的核心作用是只在它的计算结果发生变化时才触发重组。
例如:
// 不推荐
val isFormValid = email . isNotEmpty () && password . length >= 8
在上面的代码中,isFormValid 是一个计算属性,它依赖于 email 和 password 两个变量。当这两个变量发生变化时,就算 isFormValid 的值没有变化,也会触发持有这个属性的外部可组合项发生重组。比如在桌面端,一般会有一个Window可组合项,这个可组合项一个周期内只执行一次,如果在这里触发重组会直接报错。
推荐做法:
// 推荐
val isFormValid by derivedStateOf {
email . isNotEmpty () && password . length >= 8
}
rememberSaveable rememberSaveable 是 Jetpack Compose 中用于在配置变更(如屏幕旋转)或进程被系统杀死后保留状态的工具。
它和 remember 很像,但功能更强大:
remember 只在重组(recomposition)过程中保留状态。如果用户旋转了屏幕,Activity 被重建,remember 保存的状态就会丢失。rememberSaveable 不仅能在重组时保留状态,还能在 Activity 或进程被销毁和重建时(例如,屏幕旋转、从后台长时间返回)保存状态。val name by rememberSaveable { mutableStateOf ( "" ) }
善用LaunchedEffect Compose中提供了很多Side Effect方法,用来处理一些副作用,如网络请求、文件读写等。
其中LaunchedEffect是最常用的一个,它可以在Composable中启动一个协程,用来处理一些异步操作。
比如界面的初始化数据获取,会使用Unit作为key,这样只会在Composable第一次被调用时执行一次。
LaunchedEffect ( Unit ) {
// 初始化数据获取
}
除此之外,LaunchedEffect还可以用来处理一些变化执行的场景
LaunchedEffect ( themeState ) {
// 处理主题状态变化
}
自定义Modifier 一些超高频的Modifier可以自定义,比如点击事件、背景设置、间距设置等。
fun Modifier . defaultPadding () = padding ( 16 . dp )
fun Modifier . defaultClickable () = clickable {
// 处理点击事件
}
Pagination © 2024. All rights reserved. LICENSE | NOTICE | CHANGELOG
Powered by Hydejack v9.2.1