线程的作用 public class Demo01 {
public static void main ( String [] args ) {
var thread = new Thread (() -> {
System . out . println ( "Hello world from a Java thread" );
});
thread . start ();
}
}
本质上Java编译器在编译的时候都认为传递给他的是一个对象,然后执行对象的run方法。
Thread在拿到这个对象的时候,当我们执行Thread的start方法的时候,最终会执行到一个native方法start0:
private native void start0 ();
当JVM执行到这个方法的时候会调用操作系统给上层提供的API创建一个线程,然后这个线程会去解释执行我们之前给Thread对象传入的对象的run方法字节码,当run方法字节码执行完成之后,这个线程就会退出。
看到这里我们仔细思考一下线程在做一件什么样的事情,JVM给我们创建一个线程好像执行完一个函数(run)的字节码之后就退出了,线程的生命周期就结束了。
确实是这样的,JVM给我们提供的线程就是去完成一个函数,然后退出(记住这一点,这一点很重要,为你后面理解线程池的原理有很大的帮助)。
事实上JVM在使用操作系统给他提供的线程的时候也是给这个线程传递一个函数地址,然后让这个线程执行完这个函数。只不过JVM给操作系统传递的函数,这个函数的功能就是去解释执行字节码,当解释执行字节码完成之后,这个函数也会退出(被系统回收)。
看到这里可以将线程的功能总结成一句话:
执行一个函数,当这个函数执行完成之后,线程就会退出,然后被回收,当然这个函数可以调用其他的函数。
可能你会觉得这句话非常简单,但是这句话会我们理解线程池的原理非常有帮助。
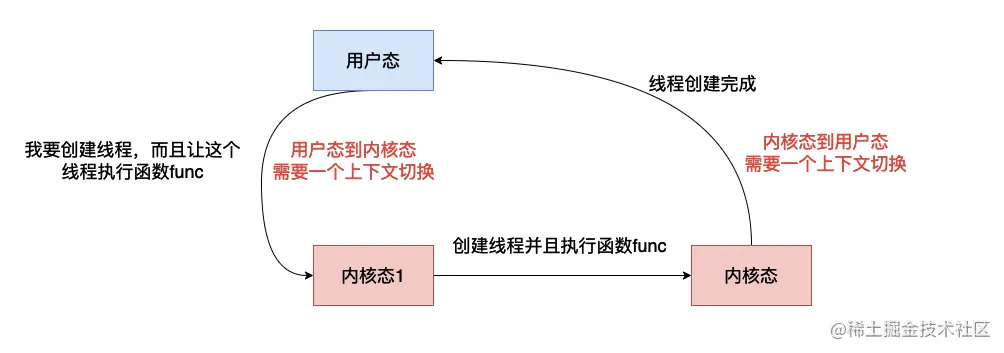
为什么需要线程池 当我们执行start的方法的时候,最终会走到start0方法,这是一个native方法,JVM在执行这个方法的时候会通过系统底层函数 创建一个线程,然后去执行run方法,这里需要注意,创建线程是需要系统资源的,比如说内存,因为操作系统是系统资源的管理者,因此一般需要系统资源的方法都需要操作系统的参与,因此创建线程需要操作系统的帮忙,而一旦需要操作系统介入,执行代码的状态就需要从用户态到内核态转换 (内核态能够执行许多用户态不能够执行的指令),当操作系统创建完线程之后又需要返回用户态,我们的代码将继续被执行,整个过程像下面这样。
从上图可以看到我们需要两次的上下文切换,同时还需要执行一些操作系统的函数,这个过程是非常耗时间的,如果在并发非常高的情况,我们频繁的去生成线程然后销毁,这对我们程序的性能影响还是非常大的。
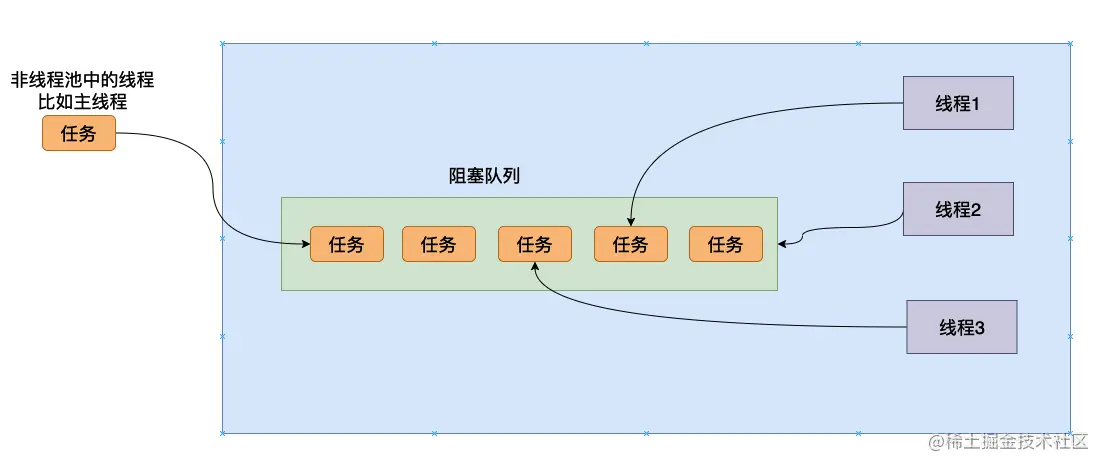
因此许许多多聪明的程序员就想能不能不去频繁的创建线程 而且也能够完成我们的功能——我们创建线程的目的就是想让我们的程序完成的更加快速,让多个不同的线程同时执行不同的任务,执行完这个任务再去阻塞队列取下一个任务执行。于是线程池就被创造出来了。
线程池的结构大致如下所示:
线程池实现原理 在前面我们已经提到了关于线程池和线程比较重要的两个点:
线程就是执行一个函数。 线程池当中的线程可以执行很多函数,但是不会退出。 那么如何实现上面两个要求?
答案就是在一个函数当中进行while循环,然后不断的从任务队列当中获取任务函数,然后进行执行,直到要求停止线程池当中的线程的时候线程再进行退出,整个过程的代码大致如下所示:
public void run () {
while (! isStopped ) {
try {
Runnable task = tasks . take ();
task . run ();
} catch ( InterruptedException e ) {
// do nothing
}
}
}
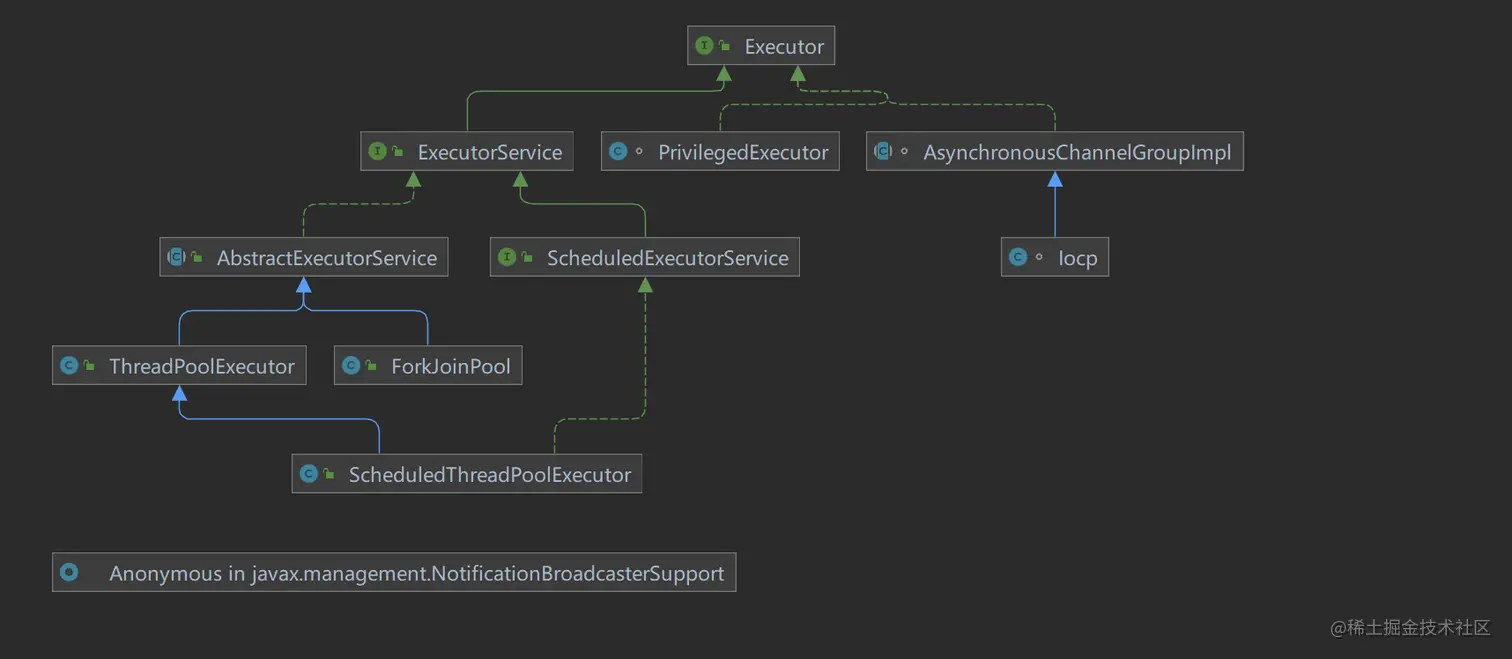
为何要使用线程池? 降低开销:在创建和销毁线程的时候会产生很大的系统开销,频繁创建/销毁 意味着CPU资源的频繁切换和占用,线程是属于稀缺资源,不可以频繁的创建。假设创建线程的时长记为t1,线程执行任务的时长记为t2,销毁线程的时长记为t3,如果我们执行任务 t2<t1+t3 ,那么这样的开销是不划算的,不使用线程池去避免创建和销毁的开销,将是极大的资源浪费。 易复用和管理:将线程都放在一个池子里,便于统一管理(可以延时执行,可以统一命名线程名称等),同时,也便于任务进行复用。 解耦:将线程的创建和销毁与执行任务完全分离出来,这样方便于我们进行维护,也让我们更专注于业务开发。 线程池的优势 提高资源的利用性:通过池化可以重复利用已创建的线程,空闲线程可以处理新提交的任务,从而降低了创建和销毁线程的资源开销。 提高线程的管理性:在一个线程池中管理执行任务的线程,对线程可以进行统一的创建、销毁以及监控等,对线程数做控制,防止线程的无限制创建,避免线程数量的急剧上升而导致CPU过度调度等问题,从而更合理的分配和使用内核资源。 提高程序的响应性:提交任务后,有空闲线程可以直接去执行任务,无需新建。 提高系统的可扩展性:利用线程池可以更好的扩展一些功能,比如定时线程池可以实现系统的定时任务。 线程池的类型 Java提供了一套Executor框架,封装了对多线程的控制,其体系结构如下图所示:
Executor只是一个接口,代码如下:
public interface Executor {
void execute ( Runnable command );
}
ExecutorService接口对该接口进行了扩展,增加很多方法:
shutdown ()
shutdowmNow ()
isShutdown ()
isTerminated ()
awaitTermination ()
submit ( Callable < T >)
submit ( Runnable , T )
submit ( Runnable )
invokeAll ()
重点关注前五个方法:
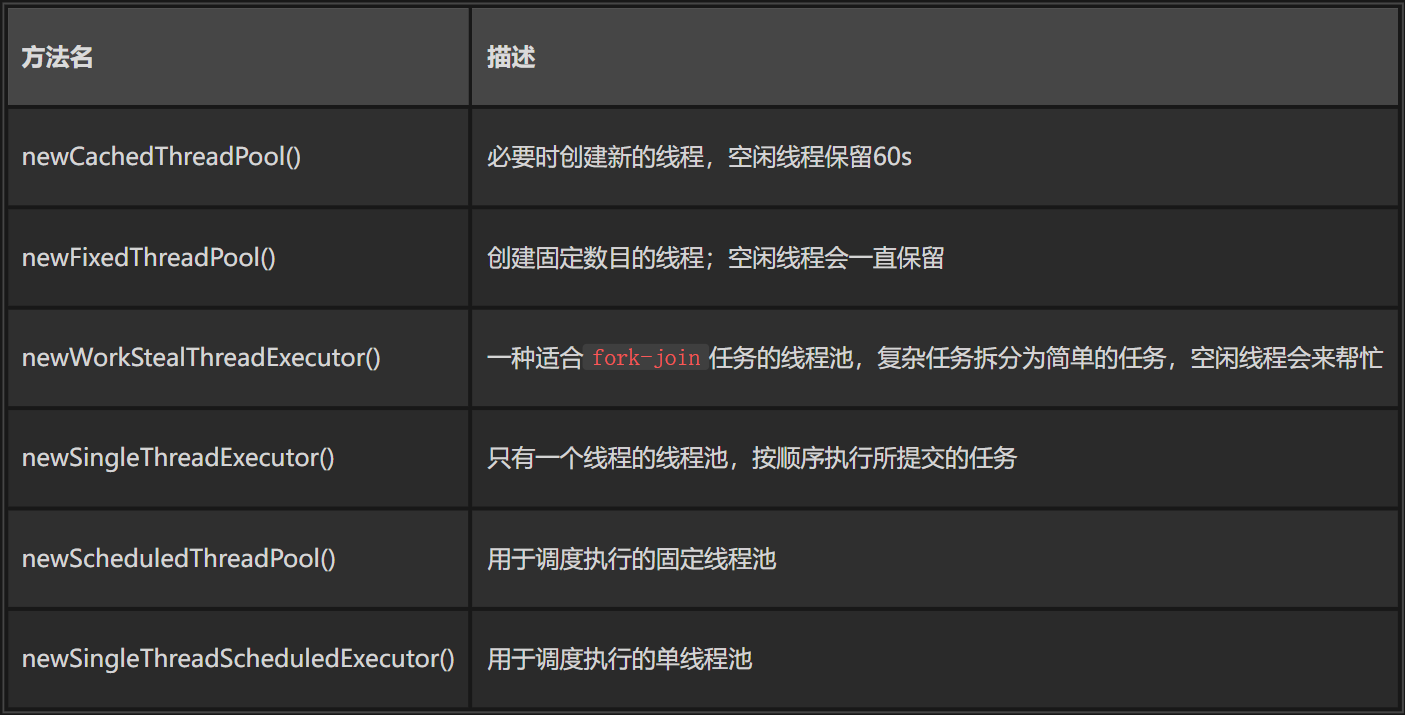
shutdown(): 调用此方法通知线程池 shutdown,调用此方法后,线程池不再接受新的任务,已经提交的任务不会受到影响,会按照顺序执行完毕。不会阻塞调用此方法的线程。 shutdowmNow(),立即尝试停止所有正在运行的任务,返回一个待执行的任务列表。不会阻塞调用此方法的线程。该方法除了尽力去尝试停止线程外,没有任何保证,任何响应中断失败的线程可能永远不会停止(如:通过thread.interrupted()中断线程时)。 isShutdown():返回一个boolean值,如果已经 shutdown 返回true,反之false。 awaitTermination(timeout,timeUnit):阻塞直到所有任务全部完成,或者等待 timeout ,或者在等待timeout期间当前线程抛出InterruptedException isTerminated(): 返回 true 如果所有的任务已经完成且关闭,否则返回false除非在先前已经调用过shutdown()/shutdownNow() AbstractExecutorService 是一个抽象类,实现了 ExecutorService ,其子 ThreadPoolExecutor 进一步扩展了相关功能。Java中提供了一个工具类供我们去使用 ThreadPoolExecutor ,在 Executors 中提供了如下几种线程池。
这么多的线程池,但都是给ThreadPoolExecutor的构造函数传递不同的参数罢了。
线程池的创建与使用 ThreadPoolExecutor的构造函数:
public ThreadPoolExecutor ( int corePoolSize ,
int maximumPoolSize ,
long keepAliveTime ,
TimeUnit unit ,
BlockingQueue < Runnable > workQueue ,
ThreadFactory threadFactory ,
RejectedExecutionHandler handler ) {
if ( corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0 )
throw new IllegalArgumentException ();
if ( workQueue == null || threadFactory == null || handler == null )
throw new NullPointerException ();
this . corePoolSize = corePoolSize ;
this . maximumPoolSize = maximumPoolSize ;
this . workQueue = workQueue ;
this . keepAliveTime = unit . toNanos ( keepAliveTime );
this . threadFactory = threadFactory ;
this . handler = handler ;
}
七大构造参数 int corePoolSize:该线程池中核心线程数最大值 这边我们区分两个概念:
核心线程:线程池新建线程的时候,当前活动的线程总数< corePoolSize,新建的线程即为核心线程。 非核心线程:线程池新建线程的时候,当前活动的线程总数> corePoolSize, 且阻塞队列已满,这时新建一个线程来执行新提交的任务即为非核心线程。 核心线程默认情况下会一直存活在线程池中,即使这个核心线程不工作(空闲状态),除非ThreadPoolExecutor 的 allowCoreThreadTimeOut这个属性为 true,那么核心线程如果空闲状态下,超过一定时间后就被销毁。
int maximumPoolSize:线程总数最大值 线程总数 = 核心线程数 + 非核心线程数
long keepAliveTime:非核心线程空闲超时时间 keepAliveTime即为空闲线程允许的最大的存活时间。如果一个非核心线程空闲状态的时长超过keepAliveTime了,就会被销毁掉。注意:如果设置allowCoreThreadTimeOut = true,就变成核心线程超时销毁了。
TimeUnit unit:是keepAliveTime 的单位 TimeUnit为枚举类型,列举如下:
TimeUnit . DAYS ; //天
TimeUnit . HOURS ; //小时
TimeUnit . MINUTES ; //分钟
TimeUnit . SECONDS ; //秒
TimeUnit . MILLISECONDS ; //毫秒
TimeUnit . MICROSECONDS ; //微妙
TimeUnit . NANOSECONDS ; //纳秒
BlockingQueue workQueue:存放任务的阻塞队列 当核心线程都在工作的时候,新提交的任务就会被添加到这个工作阻塞队列中进行排队等待;如果阻塞队列也满了,线程池就新建非核心线程去执行任务。
workQueue维护的是等待执行的Runnable对象。常用的 workQueue 类型:(无界队列、有界队列、同步移交队列)
SynchronousQueue:同步移交队列,适用于非常大的或者无界的线程池,可以避免任务排队,SynchronousQueue队列接收到任务后,会直接将任务从生产者移交给工作者线程,这种移交机制高效。它是一种不存储元素的队列,任务不会先放到队列中去等线程来取,而是直接移交给执行的线程。只有当线程池是无界的或可以拒绝任务的时候,SynchronousQueue队列的使用才有意义,maximumPoolSize 一般指定成 Integer.MAX_VALUE,即无限大。要将一个元素放入SynchronousQueue,就需要有另一个线程在等待接收这个元素。若没有线程在等待,并且线程池的当前线程数小于最大值,则ThreadPoolExecutor就会新建一个线程;否则,根据饱和策略,拒绝任务。newCachedThreadPool默认使用的就是这种同步移交队列。吞吐量高于LinkedBlockingQueue。 LinkedBlockingQueue:基于链表结构的阻塞队列,FIFO原则排序。当任务提交过来,若当前线程数小于corePoolSize核心线程数,则线程池新建核心线程去执行任务;若当前线程数等于corePoolSize核心线程数,则进入工作队列进行等待。LinkedBlockingQueue队列没有最大值限制,只要任务数超过核心线程数,都会被添加到队列中,这就会导致运行中的总线程数永远不会超过 corePoolSize,所以maximumPoolSize 是一个无效设定。newFixedThreadPool和newSingleThreadPool默认是使用的是无界LinkedBlockingQueue队列。吞吐量高于ArrayBlockingQueue。 ArrayBlockingQueue:基于数组结构的有界阻塞队列,可以设置队列上限值,FIFO原则排序。当任务提交时,若当前线程小于corePoolSize核心线程数,则新建核心线程执行任务;若当先线程数等于corePoolSize核心线程数,则进入队列排队等候;若队列的任务数也排满了,则新建非核心线程执行任务;若队列满了且总线程数达到了maximumPoolSize最大线程数,则根据饱和策略进行任务的拒绝。 DelayQueue:延迟队列,队列内的元素必须实现 Delayed 接口。当任务提交时,入队列后只有达到指定的延时时间,才会执行任务。 PriorityBlockingQueue:优先级阻塞队列,根据优先级执行任务,优先级是通过自然排序或者是Comparator定义实现。 ThreadFactory threadFactory 创建线程的方式,这是一个接口,你 new 他的时候需要实现他的 Thread newThread(Runnable r) 方法,一般用不上。
RejectedExecutionHandler handler:饱和策略 抛出异常专用,当队列和最大线程池都满了之后的拒绝策略。 JDK提供了几种不同的RejectedExecutionHandler实现:
CallerRunsPolicy : 调用线程处理任务 AbortPolicy : 抛出异常 DiscardPolicy : 直接丢弃 DiscardOldestPolicy : 丢弃队列中最老的任务,执行新任务 //默认策略,阻塞队列满,则丢任务、抛出异常
rejected = new ThreadPoolExecutor . AbortPolicy ();
//阻塞队列满,则丢任务,不抛异常
rejected = new ThreadPoolExecutor . DiscardPolicy ();
//删除队列中最旧的任务(最早进入队列的任务),尝试重新提交新的任务
rejected = new ThreadPoolExecutor . DiscardOldestPolicy ();
//队列满,不丢任务,不抛异常,若添加到线程池失败,那么主线程会自己去执行该任务
rejected = new ThreadPoolExecutor . CallerRunsPolicy ();
另外还有一个CallerRunsPolicy
CallerRunsPolicy 其为“调用者运行”策略,实现了一种调节机制 。它不会抛弃任务,也不会抛出异常。 而是将任务回退到调用者。它不会在线程池中执行任务,而是在一个调用了execute的线程中执行该任务。在线程满后,新任务将交由调用线程池execute方法的主线程执行,而由于主线程在忙碌,所以不会执行accept方法,从而实现了一种平缓的性能降低。
当工作队列被填满后,没有预定义的饱和策略来阻塞execute(除了抛弃就是中止还有去让调用者去执行)。然而可以通过Semaphore来限制任务的到达率。
线程池的状态 RUNNING:运行状态,指可以接受任务并执行队列里的任务。 SHUTDOWN:调用了 shutdown() 方法,不再接受新任务,但队列里的任务会执行完毕。 STOP:指调用了 shutdownNow() 方法,不再接受新任务,所有任务都变成STOP状态,不管是否正在执行。该操作会抛弃阻塞队列里的所有任务并中断所有正在执行任务。 TIDYING:所有任务都执行完毕,程序调用 shutdown()/shutdownNow() 方法都会将线程更新为此状态,若调用shutdown(),则等执行任务全部结束,队列即为空,变成TIDYING状态;调用shutdownNow()方法后,队列任务清空且正在执行的任务中断后,更新为TIDYING状态。 TERMINATED:终止状态,当线程执行 terminated() 后会更新为这个状态。 关闭线程池 两种关闭线程池的区别: shutdown(): 执行后停止接受新任务,会把队列的任务执行完毕。 shutdownNow(): 执行后停止接受新任务,但会中断所有的任务(不管是否正在执行中),将线程池状态变为 STOP状态。 重装系统特别多,有时候一些环境配置或者系统设置操作容易忘记,又要重新搜集,在此文作记录。
Windows文件资源管理器六个文件夹删除 文件资源管理器侧边栏的几个文件夹,在选取文件和查看时,占用很多不必要的空间,我希望需要选取资源的文件夹都放在快速访问里就够了。
通过删除注册表(运行regedit打开)把这几个文件夹的显示删除掉:
1、注册表路径:
HKEY_LOCAL_MACHINE
|-SOFTWARE
|-Microsoft
|-Windows
|-CurrentVersion
|-Explorer
|-MyComputer
|-NameSpace
2、找到相应的键值进行删除操作(删除之前先做好备份):
1)删除【下载】文件夹: {088e3905-0323-4b02-9826-5d99428e115f}
2)删除【图片】文件夹: {24ad3ad4-a569-4530-98e1-ab02f9417aa8}
3)删除【音乐】文件夹: {3dfdf296-dbec-4fb4-81d1-6a3438bcf4de}
4)删除【文档】文件夹: {d3162b92-9365-467a-956b-92703aca08af}
5)删除【视频】文件夹: {f86fa3ab-70d2-4fc7-9c99-fcbf05467f3a}
6)删除【桌面】文件夹: {B4BFCC3A-DB2C-424C-B029-7FE99A87C641}
7)删除【3D对象】文件夹: {0DB7E03F-FC29-4DC6-9020-FF41B59E513A}
删除完成之后,通过任务管理器重启文件资源管理器即可生效:
Windows安装ubuntu子系统 控制面板,最后一个程序模块,启用功能,打开勾选Hyper-V和适用于windows的linux子系统这两个选项 重启Windows电脑 微软商店里搜索Ununtu,下载安装 运行安装好的Ubuntu子系统,等待初始化即可 Windows和Ubuntu的共享文件系统,可以访问 mnt 路径:
stephen@DESKTOP-PA80G1H:~$ cd /mnt/e/Dev/Android
stephen@DESKTOP-PA80G1H:/mnt/e/Dev/Android$ ls
CommonDebugDemo JniDemo NetDataDemo SmolChat-Android gallery
可以进行文件的复制操作,在mnt下直接操作会有很严重的IO损耗,最好复制到ubuntu内部路径再使用。
pip换依赖源 python和pip环境变量地址 python主程序安装后,地址加入PATH才可以在cmd里随处使用:
pip包管理器其实就在Scripts路径下:
E:\Env\python\python3135\Scripts
要更换 pip 的package软件源,可以按照以下步骤进行:
临时换源 在安装包时使用 -i 参数,例如: 清华源:
pip install 包名 -i https://pypi.tuna.tsinghua.edu.cn/simple
阿里源:
pip install 包名 -i https://mirrors.aliyun.com/pypi/simple
永久换源 使用以下命令设置全局源: 清华源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
阿里源:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
恢复默认源:使用命令 pip config unset global.index-url
通过更换源,可以显著提高安装 Python 包的速度。
Windows文件共享 选取要共享的文件夹,右键查看属性:
点击高级共享,勾选“共享此文件夹”,然后点击“权限”。
确保“Everyone”用户或特定用户的权限已设置为“读取”或“完全控制”。
点击“确定”保存。
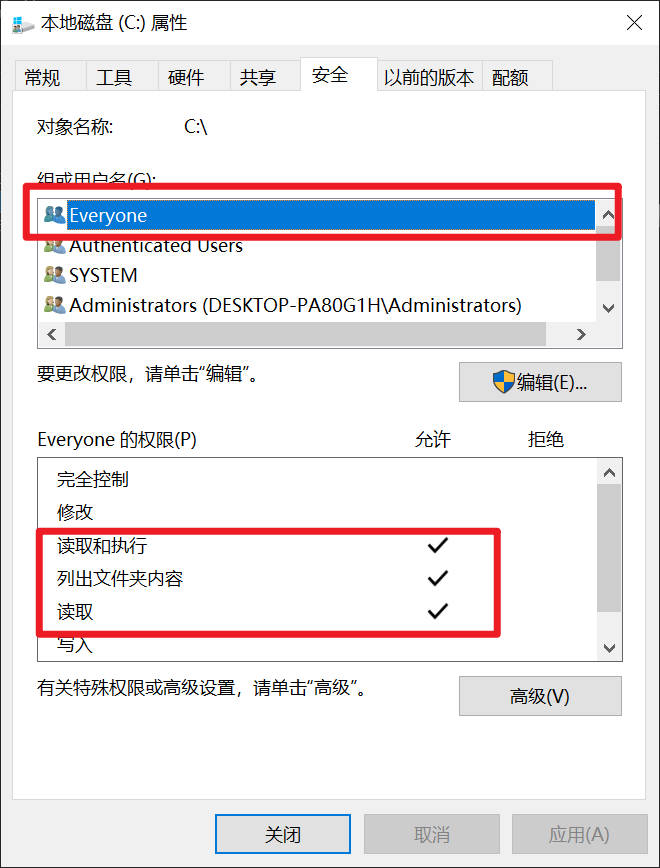
回到“属性”窗口,切换到“安全”选项卡。
这里是非常关键的一步:安全设置也必须给予相应的权限。点击“编辑”,然后点击“添加”。
在输入框中输入“Everyone”,然后点击“检查名称”,再点击“确定”。
为“Everyone”用户设置相应的权限,例如“完全控制”。
点击“确定”保存所有更改。
检查网络共享中心的设置,专用,公用,所有的都开启网路共享
最后查看四个关键服务是否启动。某些 Windows 服务必须运行,才能确保网络发现和共享功能正常工作。
按 Win + R,输入 services.msc,然后按回车。 在服务列表中,找到以下几项,确保它们的启动类型 设置为“自动 ”,并且状态 是“正在运行 ”:Function Discovery Provider Host Function Discovery Resource Publication Server TCP/IP NetBIOS Helper 如果某个服务没有运行,双击它,将启动类型改为“自动”,然后点击“启动”按钮。 完成以上步骤后,重启你的电脑,再尝试从另一台电脑访问共享内容。通常,经过这几个步骤,问题都能得到解决。如果问题依旧,你可以在另一台电脑的“文件资源管理器”地址栏中直接输入共享电脑的 IP 地址来尝试连接,例如 \\192.168.1.100。
Ubuntu22换源 临时换源 在安装包时使用 -i 参数,例如: 清华源:
sudo apt install 包名 -i https://mirrors.tuna.tsinghua.edu.cn/ubuntu/
永久换源 编辑 /etc/apt/sources.list 文件,将其中的源地址替换为清华源或阿里源。
sudo nano /etc/apt/sources.list
将文件内容替换为以下内容(清华源):
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse
保存并退出编辑器(在 nano 中,按 Ctrl + O 保存,然后按 Ctrl + X 退出)。 然后更新软件包列表:
sudo apt update
sudo apt upgrade
Ubuntu24换源 24和之前的有些区别。Ubuntu24.04的源地址配置文件发生改变,不再使用以前的sources.list文件,升级24.04之后,而是使用如下文件:
/etc/apt/sources.list.d/ubuntu.sources
备份源配置文件 sudo cp /etc/apt/sources.list.d/ubuntu.sources /etc/apt/sources.list.d/ubuntu.sources.bak
编辑源配置文件 sudo vim /etc/apt/sources.list.d/ubuntu.sources
3.使用dd将原本内容删除,然后添加以下新的源。清华源
Types: deb
URIs: http://mirrors.tuna.tsinghua.edu.cn/ubuntu/
Suites: noble noble-updates noble-security
Components: main restricted universe multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
更新 三、其它源 1、中科大
Types: deb
URIs: http://mirrors.ustc.edu.cn/ubuntu/
Suites: noble noble-updates noble-security
Components: main restricted universe multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
2、阿里
Types: deb
URIs: http://mirrors.aliyun.com/ubuntu/
Suites: noble noble-updates noble-security
Components: main restricted universe multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
3、网易
Types: deb
URIs: http://mirrors.163.com/ubuntu/
Suites: noble noble-updates noble-security
Components: main restricted universe multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gp
Windows设置一个exe开机自启动 这是最直接、最通用的方法。同时按下 Win + R 键,打开“运行”对话框。
输入 shell:startup 然后点击“确定”。这会打开当前用户的“启动”文件夹。
找到你想要开机自启的应用程序的 快捷方式,然后将它拖拽到这个“启动”文件夹中。
提示: 如果你的应用没有快捷方式,通常可以在开始菜单中找到它,然后右键点击,选择“更多” -> “打开文件位置”,在那里你可以找到快捷方式。如果还是找不到,你也可以自己创建快捷方式。
Windows配置C++开发环境 下载MSYS2 在MSYS2官网 下载最新版本的安装包。
安装MSYS2 运行下载的安装包,按照提示完成安装。建议安装在默认路径 C:\msys64。
更新MSYS2 安装完MSYS2后,发现里面的环境目录都是空白的。
打开MSYS2 MINGW64终端,运行以下命令更新系统和软件包:
如果提示需要重启MSYS2终端,请关闭当前终端并重新打开。
安装开发工具 安装常用的开发工具和库,可以使用以下命令:
pacman -S --needed base-devel mingw-w64-ucrt-x86_64-toolchain
这将安装基本的开发工具和mingw-w64编译器。
配置环境变量 在MSYS2安装目录下找到 ucrt64 的路径,通常是:
D:\Program Files\MSYS2\ucrt64\bin
将这个路径添加到系统的PATH环境变量中。
重启VSCODE 重启完毕打开cpp文件编辑界面,按F5,选择C++(GDB/LLDB),会自动生成launch.json文件。
然后点击右上角运行,即可编译运行C++程序。
Python 转换md文件为pdf 使用pypandoc库。
安装pandoc 在Pandoc官网 下载最新版本的安装包。
安装MikTeX 在MikTeX官网 下载最新版本的安装包。
可能需要配置环境变量
python脚本 import pypandoc
import os
def markdown_to_pdf ( input_md_file , output_pdf_file ):
"""
将 Markdown 文件转换为 PDF 文件。
参数:
input_md_file (str): 输入的 Markdown 文件路径。
output_pdf_file (str): 输出的 PDF 文件路径。
"""
if not os . path . exists ( input_md_file ):
print ( f "错误:找不到文件 ' { input_md_file } '" )
return
try :
# 使用 pypandoc 将 Markdown 转换为 PDF
pypandoc . convert_file ( input_md_file , 'pdf' , outputfile = output_pdf_file )
print ( f "成功将 ' { input_md_file } ' 转换为 ' { output_pdf_file } '" )
except Exception as e :
print ( f "转换过程中发生错误: { e } " )
if __name__ == "__main__" :
# 指定你的输入和输出文件路径
input_file = "C: \\ Users \\ zhanf \\ Desktop \\ tesettestsetes.md" # 替换成你的Markdown文件路径
output_file = "C: \\ Users \\ zhanf \\ Desktop \\ OUTPUT_PDF_FILE.pdf" # 替换成你想要的PDF文件路径
markdown_to_pdf ( input_file , output_file )
运行过程中,可能会自动安装一些宏包,一路点安装即可。最后会生成pdf文件。
目前貌似不兼容中文。
MACOS调整图片大小 命令:
sips --resampleHeightWidth <高度> <宽度> <输入文件路径> --out <输出文件路径>
简单来说,Java 反射(Reflection) 就是一种让 Java 程序在运行时 能够“看清”并操作自身 的能力。
通常,我们编写 Java 代码时,在编译阶段就已经确定了类、方法、字段等信息。但反射打破了这种限制,它允许你在程序运行时:
获取类的信息: 比如,一个对象属于哪个类?这个类有哪些字段(属性)?有哪些方法?有哪些构造函数?等等。操作类的成员: 创建对象: 不通过 new 关键字,而是动态地创建类的实例。访问/修改字段: 即使是 private 的字段,也能读取或修改它的值。调用方法: 即使是 private 的方法,也能动态地调用它。反射主要用于:
框架和库的开发: 很多流行的 Java 框架(如 Spring、Hibernate、JUnit)都大量使用了反射。它们需要在运行时动态地加载类、注入依赖、调用方法等,而不需要提前知道用户会定义哪些具体的类。动态代理: 在不修改原有代码的情况下,为对象增加新的功能。序列化和反序列化: 当对象需要保存到文件或网络传输时,需要知道对象的内部结构。单元测试工具: 允许测试框架访问私有成员进行测试。反射也可以叫自省,向内探查。那些外部访问不到的API,可以通过反射强行调用。如果编译时知道类或对象的具体信息,此时直接对类和对象正常初始化操作即可,无需使用反射(reflection)。如果编译不知道类或对象的具体信息,就要用到 反射 来实现。比如类的名称放在XML文件中,属性和属性值放在XML文件中,需要在运行时读取XML文件,动态获取类的信息。Web领域对动态扩展的要求很高,会大量用到反射。
场景 Java反射机制的核心是在程序运行时 动态加载类并获取类的详细信息 ,从而操作类或对象的属性和方法。本质是JVM得到class对象之后,再通过class对象进行反编译,从而获取对象的各种信息。
Java属于先编译再运行的语言,程序中对象的类型在编译期就确定下来了,而当程序在运行时可能需要动态加载某些类,这些类因为之前用不到,所以没有被加载到JVM。通过反射,可以在运行时动态地创建对象并调用其属性,不需要提前在编译期知道运行的对象是谁。
在编译时根本无法知道该对象或类可能属于哪些类,程序只依靠运行时信息来发现该对象和类的真实信息比如:log4j,Servlet、SSM框架技术都用到了反射机制。
Android平台上,LayoutInflator解析xml利用了反射生成view,还有EventBus使用反射进行了解耦处理等。
使用 使用反射创建对象,调用方法举例:
public class ReflectionExample {
private static final String TAG = "ReflectionExample" ;
public static void init () {
try {
// 获取类对象
Class <?> clazz = Class . forName ( "com.stephen.commondemo.alltest.MyClass" );
// 获取构造函数
Constructor <?> constructor = clazz . getConstructor ();
// 使用构造函数创建对象
Object obj = constructor . newInstance ();
// 获取方法
Method method = clazz . getMethod ( "myMethod" , String . class );
// 调用方法
method . invoke ( obj , "Hello, Reflection!" );
} catch ( ClassNotFoundException | NoSuchMethodException | IllegalAccessException |
InstantiationException | InvocationTargetException e ) {
e . printStackTrace ();
}
}
}
class MyClass {
private static final String TAG = "MyClass" ;
public MyClass () {
Log . i ( TAG , "MyClass instance created." );
}
public void myMethod ( String message ) {
Log . i ( TAG , "Method called with message: " + message );
}
}
优缺点 1、优点:
在运行时获得类的各种内容,进行反编译,对于Java这种先编译再运行的语言,能够让我们很方便的创建灵活的代码,这些代码可以在运行时装配,无需在组件之间进行源代码的链接,更加容易实现面向对象。
2、缺点:
(1)反射会消耗一定的系统资源,因此,如果不需要动态地创建一个对象,那么就不需要用反射; (2)反射调用方法时可以忽略权限检查,因此可能会破坏封装性而导致安全问题。
反射获取Class信息 反射的关键实现方法有以下几个:
得到类:Class.forName(“类名”) 得到所有字段:getDeclaredFields() 得到所有方法:getDeclaredMethods() 得到构造方法:getDeclaredConstructor() 得到实例:newInstance() 调用方法:invoke() 例如现在有一个Human类,设置几个参数,构造函数,公共方法。
package com.stephen.commondemo.alltest ;
public class Human {
private static final String TAG = "Human" ;
public String gender ;
public String age ;
public Human ( String gender , String age ) {
this . gender = gender ;
this . age = age ;
}
private Human () {
}
public Human ( String gender ) {
this . gender = gender ;
}
public String getGender () {
return gender ;
}
public String getAge () {
return age ;
}
public void setGender ( String gender ) {
this . gender = gender ;
}
public void setAge ( String age ) {
this . age = age ;
}
public void eat () {
System . out . println ( "Human is eating." );
}
public void speak ( String str ) {
System . out . println ( "Human is speaking" + str );
}
}
在另一个类,使用反射获取类的信息。
package com.stephen.commondemo.alltest ;
import android.util.Log ;
import java.lang.reflect.Constructor ;
import java.lang.reflect.Field ;
import java.lang.reflect.Method ;
import java.lang.reflect.Modifier ;
import java.util.Arrays ;
import java.util.Objects ;
public class HumanInfoGetter {
private static final String TAG = "HumanInfoGetter" ;
public static void init () throws Exception {
// 1.获取一个类的结构信息(类对象 Class对象)
Class <?> clazz = Class . forName ( "com.stephen.commondemo.alltest.Human" );
// 2.从类对象中获取类的各种结构信息
// 2.1 获取基本结构信息
Log . i ( TAG , clazz . getName ());
Log . i ( TAG , clazz . getSimpleName ());
Log . i ( TAG , Objects . requireNonNull ( clazz . getSuperclass ()). getName ());
Log . i ( TAG , Arrays . toString ( clazz . getInterfaces ()));
// 2.2 获取构造方法
// 只能得到public修饰的构造方法
// Constructor[] constructors = clazz.getConstructors();
// 可以得到所有的构造方法
Constructor [] constructors = clazz . getDeclaredConstructors ();
Log . i ( TAG , constructors . length + "" );
for ( Constructor con : constructors ) {
// System.out.println(con.toString());
Log . i ( TAG , con . getName () + "||" +
Modifier . toString ( con . getModifiers ()) + " ||"
+ Arrays . toString ( con . getParameterTypes ()));
}
// Constructor con = clazz.getConstructor();// 获取无参数构造方法
// Constructor con = clazz.getConstructor(String.class,String.class);
Constructor <?> con =
clazz . getDeclaredConstructor ( String . class , String . class );
Log . i ( TAG , String . valueOf ( con ));
// 2.3 获取属性
// Field[] fields = clazz.getFields();
Field [] fields = clazz . getDeclaredFields ();
Log . i ( TAG , String . valueOf ( fields . length ));
for ( Field f : fields ) {
Log . i ( TAG , String . valueOf ( f ));
}
// Field f = clazz.getField("color");
// private 默认 protecte public都可以获取,但不包括父类的
Field f = clazz . getDeclaredField ( "age" );
Log . i ( TAG , String . valueOf ( f ));
// 2.3 获取方法
// Method[] methods = clazz.getMethods();
Method [] methods = clazz . getDeclaredMethods ();
for ( Method m : methods ) {
Log . i ( TAG , String . valueOf ( m ));
}
Method m1 = clazz . getMethod ( "speak" , String . class );
Method m2 = clazz . getDeclaredMethod ( "eat" );
Log . i ( TAG , String . valueOf ( m1 ));
Log . i ( TAG , String . valueOf ( m2 ));
}
}
原理 从上述内容可以看出,对于反射来说,操纵类最主要的方法是 invoke,所以搞懂了 invoke 方法的实现,也就搞定了反射的底层实现原理了。
invoke 方法的执行流程如下:
查找方法:当通过 java.lang.reflect.Method 对象调用 invoke 方法时,Java 虚拟机(JVM)首先确认该方法是否存在并可以访问。这包括检查方法的访问权限、方法签名是否匹配等。 安全检查:如果方法是私有的或受保护的,还需要进行访问权限的安全检查。如果当前调用者没有足够的权限访问这个方法,将抛出 IllegalAccessException。 参数转换和适配:invoke 方法接受一个对象实例和一组参数,需要将这些参数转换成对应方法签名所需要的类型,并且进行必要的类型检查和装箱拆箱操作。 方法调用:对于非私有方法,Java 反射实际上是通过 JNI(Java Native Interface,Java 本地接口)调用到 JVM 内部的 native 方法,例如 java.lang.reflect.Method.invoke0()。这个 native 方法负责完成真正的动态方法调用。对于 Java 方法,JVM 会通过方法表、虚方法表(vtable)进行查找和调用;对于非虚方法或者静态方法,JVM 会直接调用相应的方法实现。 异常处理:在执行方法的过程中,如果出现任何异常,JVM 会捕获并将异常包装成 InvocationTargetException 抛出,应用程序可以通过这个异常获取到原始异常信息。 返回结果:如果方法正常执行完毕,invoke 方法会返回方法的执行结果,或者如果方法返回类型是 void,则不返回任何值。 通过这种方式,Java 反射的 invoke 方法能够打破编译时的绑定,实现运行时动态调用对象的方法,提供了极大的灵活性,但也带来了运行时性能损耗和安全隐患(如破坏封装性、违反访问控制等)。
反射为什么比正常加载慢 简单来说,因为 反射需要在运行时动态获取类的信息 ,这比在编译时就获取信息要慢。
反射性能低么?为什么?
经过方法调用的测试,反射比正常调用大约慢100倍。反射方法调用耗时大约是 0.0004ms ,而Android屏幕刷新率是60-120hz,每一帧的耗时大概8.3ms到16ms之间,如果要使用户感受到反射带来的卡顿,至少要17000多次调用。
除了循环之外,不会有这么多的反射调用。
所以反射虽然慢,在非高频的场景下,正常使用完全没有问题。
反射慢流传的原因 由于时代原因,在 Android 4.4 及之前的设备上,反射的耗时大约为0.008-0.09ms ,大概慢了 20-300 倍。取个100倍。
按照每一帧16ms来算,给每一帧分配10%的时间片留给反射,那只有41次的调用机会了。
在Android5.0推出了ART,性能优化了一大截。
根据《Java编程思想》中的描述,泛型出现的动机:
有很多原因促成了泛型的出现,而最引人注意的一个原因,就是为了创建容器类。
泛型的本质就是”参数化类型”。一提到参数,最熟悉的就是定义方法的时候需要形参,调用方法的时候,需要传递实参。那”参数化类型”就是将原来具体的类型参数化。泛型的出现避免了强转的操作,在编译器完成类型转化,也就避免了运行的错误。
现在的程序开发大都是面向对象的,平时会用到各种类型的对象,一组对象通常需要用集合来存储它们,因而就有了一些集合类,比如 List、Map 等。
这些集合类里面都是装的具体类型的对象,如果每个类型都去实现诸如 TextViewList、ActivityList 这样的具体的类型,显然是不可能的。
因此就诞生了「泛型」,它的意思是把具体的类型泛化,编码的时候用符号来指代类型,在使用的时候,再确定它的类型。
实例 Java泛型也是一种语法糖,在编译阶段完成类型的转换的工作,避免在运行时强制类型转换而出现 ClassCastException ,类型转化异常。
不使用泛型:
public static void main ( String [] args ) {
List list = new ArrayList ();
list . add ( 11 );
list . add ( "ssss" );
for ( int i = 0 ; i < list . size (); i ++) {
System . out . println (( String ) list . get ( i ));
}
}
因为list类型是Object。所以int,String类型的数据都是可以放入的,也是都可以取出的。但是上述的代码,运行的时候就会抛出 类型转化异常 ,这个相信大家都能明白。
使用泛型:
public static void main ( String [] args ) {
List < String > list = new ArrayList ();
list . add ( "hahah" );
list . add ( "ssss" );
for ( int i = 0 ; i < list . size (); i ++) {
System . out . println (( String ) list . get ( i ));
}
}
在上述的实例中,我们只能添加String类型的数据,否则编译器会报错。
泛型的使用 泛型的三种使用方式:泛型类,泛型方法,泛型接口
泛型类 即把泛型定义在类上:
public class 类名 < 泛型类型1 ,...> {
}
注意事项:泛型类型必须是引用类型(非基本数据类型)
泛型方法 泛型方法概述:把泛型定义在方法上
public < 泛型类型 > 返回类型 方法名 ( 泛型类型 变量名 ) {
}
注意要点:
方法声明中定义的形参只能在该方法里使用,而接口、类声明中定义的类型形参则可以在整个接口、类中使用。当调用 fun() 方法时,根据传入的实际对象,编译器就会判断出类型形参 T 所代表的实际类型。
class Demo {
public < T > T fun ( T t ){ // 可以接收任意类型的数据
return t ; // 直接把参数返回
}
};
public class GenericsDemo26 {
public static void main ( String args []){
Demo d = new Demo () ; // 实例化Demo对象
String str = d . fun ( "汤姆" ) ; // 传递字符串
int i = d . fun ( 30 ) ; // 传递数字,自动装箱
System . out . println ( str ) ; // 输出内容
System . out . println ( i ) ; // 输出内容
}
};
泛型接口 泛型接口概述:把泛型定义在接口
public interface 接口名 < 泛型类型 > {
}
实例:
public interface Inter < T > {
public abstract void show ( T t ) ;
}
/**
* 子类是泛型类
*/
public class InterImpl < E > implements Inter < E > {
@Override
public void show ( E t ) {
System . out . println ( t );
}
}
Inter < String > inter = new InterImpl < String >() ;
inter . show ( "hello" ) ;
源码中泛型的使用 下面是List接口和ArrayList类的代码片段。
//定义接口时指定了一个类型形参,该形参名为E
public interface List < E > extends Collection < E > {
//在该接口里,E可以作为类型使用
public E get ( int index ) {}
public void add ( E e ) {}
}
//定义类时指定了一个类型形参,该形参名为E
public class ArrayList < E > extends AbstractList < E > implements List < E > {
//在该类里,E可以作为类型使用
public void set ( E e ) {
.......................
}
}
泛型类派生子类 父类派生子类的时候不能在包含类型形参,需要传入具体的类型
错误的方式:
public class A extends Container < K , V > {}
正确的方式:
public class A extends Container < Integer , String > {}
也可以不指定具体的类型,系统就会把K,V形参当成Object类型处理
public class A extends Container {}
泛型构造器 构造器也是一种方法,所以也就产生了所谓的泛型构造器。 和使用普通方法一样没有区别,一种是显示指定泛型参数,另一种是隐式推断
class Person {
public < T > Person ( T t ) {
System . out . println ( t );
}
}
使用:
public static void main ( String [] args ) {
new Person ( 22 ); // 隐式
new < String > Person ( "hello" ); //显示
}
特殊说明:
如果构造器是泛型构造器,同时该类也是一个泛型类的情况下应该如何使用泛型构造器:因为泛型构造器可以显式指定自己的类型参数(需要用到菱形,放在构造器之前),而泛型类自己的类型实参也需要指定(菱形放在构造器之后),这就同时出现了两个菱形了,这就会有一些小问题,具体用法再这里总结一下。
以下面这个例子为代表
public class Person < E > {
public < T > Person ( T t ) {
System . out . println ( t );
}
}
正确用法:
public static void main ( String [] args ) {
Person < String > person = new Person ( "sss" );
}
PS:编译器会提醒你怎么做的
高级通配符 <? extends T> 上界通配符 上界通配符顾名思义, <? extends T> 表示的是类型的上界【包含自身】,因此通配的参数化类型可能是 T 或 T 的子类。
正因为无法确定具体的类型是什么,add方法受限(可以添加null,因为null表示任何类型),但可以从列表中获取元素后赋值给父类型。如上图中的第一个例子,第三个add()操作会受限,原因在于 List 和 List 是 List<? extends Animal> 的子类型。
它表示集合中的所有元素都是Animal类型或者其子类
这就是所谓的上限通配符,使用关键字extends来实现,实例化时,指定类型实参只能是extends后类型的子类或其本身。
例如: 这样就确定集合中元素的类型,虽然不确定具体的类型,但最起码知道其父类。然后进行其他操作。
这种赋值由于类型擦除机制,在编译器就会提示报错。
List < Button > buttons = new ArrayList < Button >();
List < TextView > textViews = buttons ;
使用通配符:
List < Button > buttons = new ArrayList < Button >();
List <? extends TextView > textViews = buttons ;
上界通配符可以使 Java 泛型具有「协变性 Covariance」,协变就是允许上面的赋值是合法的。
前面说到 List<? extends TextView> 的泛型类型是个未知类型 ?,编译器也不确定它是啥类型,只是有个限制条件。
由于它满足 ? extends TextView 的限制条件,所以 get 出来的对象,肯定是 TextView 的子类型,根据多态的特性,能够赋值给 TextView,啰嗦一句,赋值给 View 也是没问题的。
到了 add 操作的时候,我们可以这么理解:
List<? extends TextView> 由于类型未知,它可能是 List<Button>,也可能是 List<TextView>。对于前者,显然我们要添加 TextView 是不可以的。 实际情况是编译器无法确定到底属于哪一种,无法继续执行下去,就报错了。
由于 add 的这个限制,使用了 ? extends 泛型通配符的 List,只能够向外提供数据被消费,从这个角度来讲,向外提供数据的一方称为「生产者 Producer」。对应的还有一个概念叫「消费者 Consumer」,对应 Java 里面另一个泛型通配符 ? super。
<? super T> 下界通配符 下界通配符 <? super T> 表示的是参数化类型是 T 的超类型(包含自身),层层至上,直至Object。下界通配符可以使 Java 泛型具有「逆变性 Contravariance」。
与上界通配符对应,这里 super 限制了通配符 ? 的子类型,所以称之为下界。
它也有两层意思:
通配符 ? 表示 List 的泛型类型是一个未知类型。 super 限制了这个未知类型的下界,也就是泛型类型必须满足这个 super 的限制条件。super 我们在类的方法里面经常用到,这里的范围不仅包括 Button 的直接和间接父类,也包括下界 Button 本身。 super 同样支持 interface。 List <? super Button > buttons = new ArrayList < Button >();
List <? super Button > buttons = new ArrayList < TextView >();
List <? super Button > buttons = new ArrayList < Object >();
使用下界通配符 ? super 的泛型 List,只能读取到 Object 对象,一般没有什么实际的使用场景,通常也只拿它来添加数据,也就是消费已有的 List<? super Button>,往里面添加 Button,因此这种泛型类型声明称之为「消费者 Consumer」。
<?> 无界通配符 任意类型,如果没有明确,那么就是Object以及任意的Java类了 无界通配符用 <?> 表示,?代表了任何的一种类型,能代表任何一种类型的只有null(Object本身也算是一种类型,但却不能代表任何一种类型,所以List和List的含义是不同的,前者类型是Object,也就是继承树的最上层,而后者的类型完全是未知的)
泛型擦除 Java 泛型擦除(Type Erasure)是 Java 语言实现泛型的一种机制。简单来说,它意味着在编译时期,所有泛型类型信息都会被“擦除”掉,替换成它们的上界类型(如果存在) 或 Object 类型(如果不存在上界)。在运行时,JVM 实际上并不知道泛型的具体类型参数。
编译器编译带类型说明的集合时会去掉类型信息
3.2 验证实例:
public class GenericTest {
public static void main ( String [] args ) {
new GenericTest (). testType ();
}
public void testType (){
ArrayList < Integer > collection1 = new ArrayList < Integer >();
ArrayList < String > collection2 = new ArrayList < String >();
System . out . println ( collection1 . getClass ()== collection2 . getClass ());
//两者class类型一样,即字节码一致
System . out . println ( collection2 . getClass (). getName ());
//class均为java.util.ArrayList,并无实际类型参数信息
}
}
输出结果:
分析:
这是因为不管为泛型的类型形参传入哪一种类型实参,对于Java来说,它们依然被当成同一类处理,在内存中也只占用一块内存空间。从Java泛型这一概念提出的目的来看,其只是作用于代码编译阶段,在编译过程中,对于正确检验泛型结果后,会将泛型的相关信息擦出,也就是说,成功编译过后的class文件中是不包含任何泛型信息的。泛型信息不会进入到运行时阶段。
在静态方法、静态初始化块或者静态变量的声明和初始化中不允许使用类型形参。由于系统中并不会真正生成泛型类,所以instanceof运算符后不能使用泛型类
泛型与反射 把泛型变量当成方法的参数,利用Method类的 getGenericParameterTypes 方法来获取泛型的实际类型参数
例子:
public class GenericTest {
public static void main ( String [] args ) throws Exception {
getParamType ();
}
/*利用反射获取方法参数的实际参数类型*/
public static void getParamType () throws NoSuchMethodException {
Method method = GenericTest . class . getMethod ( "applyMap" , Map . class );
//获取方法的泛型参数的类型
Type [] types = method . getGenericParameterTypes ();
System . out . println ( types [ 0 ]);
//参数化的类型
ParameterizedType pType = ( ParameterizedType ) types [ 0 ];
//原始类型
System . out . println ( pType . getRawType ());
//实际类型参数
System . out . println ( pType . getActualTypeArguments ()[ 0 ]);
System . out . println ( pType . getActualTypeArguments ()[ 1 ]);
}
/*供测试参数类型的方法*/
public static void applyMap ( Map < Integer , String > map ){
}
}
输出结果:
java.util.Map<java.lang.Integer, java.lang.String>
interface java.util.Map
class java.lang.Integer
class java.lang.String
通过反射绕开编译器对泛型的类型限制
public static void main ( String [] args ) throws Exception {
//定义一个包含int的链表
ArrayList < Integer > al = new ArrayList < Integer >();
al . add ( 1 );
al . add ( 2 );
//获取链表的add方法,注意这里是Object.class,如果写int.class会抛出NoSuchMethodException异常
Method m = al . getClass (). getMethod ( "add" , Object . class );
//调用反射中的add方法加入一个string类型的元素,因为add方法的实际参数是Object
m . invoke ( al , "hello" );
System . out . println ( al . get ( 2 ));
}
泛型的限制 模糊性错误 对于泛型类 User<K,V> 而言,声明了两个泛型类参数。在类中根据不同的类型参数重载show方法。
public class User < K , V > {
public void show ( K k ) { // 报错信息:'show(K)' clashes with 'show(V)'; both methods have same erasure
}
public void show ( V t ) {
}
}
由于泛型擦除,二者本质上都是Obejct类型。方法是一样的,所以编译器会报错。
换一个方式:
public class User < K , V > {
public void show ( String k ) {
}
public void show ( V t ) {
}
}
可以正常的使用
不能实例化类型参数 编译器也不知道该创建那种类型的对象
public class User < K , V > {
private K key = new K (); // 报错:Type parameter 'K' cannot be instantiated directly
}
对静态成员的限制 静态方法无法访问类上定义的泛型;如果静态方法操作的类型不确定,必须要将泛型定义在方法上。
如果静态方法要使用泛型的话,必须将静态方法定义成泛型方法。
public class User < T > {
//错误
private static T t ;
//错误
public static T getT () {
return t ;
}
//正确
public static < K > void test ( K k ) {
}
}
对泛型数组的限制 不能实例化元素类型为类型参数的数组,但是可以将数组指向类型兼容的数组的引用
public class User < T > {
private T [] values ;
public User ( T [] values ) {
//错误,不能实例化元素类型为类型参数的数组
this . values = new T [ 5 ];
//正确,可以将values 指向类型兼容的数组的引用
this . values = values ;
}
}
对泛型异常的限制 泛型类型不能用于 catch 语句,例如
try { ... } catch ( MyGenericException < T > e ) { ... }
是不允许的。
Kotlin中的泛型 本节摘自扔物线的文章:
Kotlin 的泛型
Kotlin 中的 out 和 in 和 Java 泛型一样,Kolin 中的泛型本身也是不可变的。
使用关键字 out 来支持协变,等同于 Java 中的上界通配符 ? extends。 使用关键字 in 来支持逆变,等同于 Java 中的下界通配符 ? super。
var textViews : List < out TextView >
var textViews : List < in TextView >
换了个写法,但作用是完全一样的。out 表示,我这个变量或者参数只用来输出,不用来输入,你只能读我不能写我;in 就反过来,表示它只用来输入,不用来输出,你只能写我不能读我。
* 号 前面讲到了 Java 中单个 ? 号也能作为泛型通配符使用,相当于 ? extends Object。 它在 Kotlin 中有等效的写法:* 号,相当于 out Any。
和 Java 不同的地方是,如果你的类型定义里已经有了 out 或者 in,那这个限制在变量声明时也依然在,不会被 * 号去掉。
比如你的类型定义里是 out T : Number 的,那它加上 <*> 之后的效果就不是 out Any,而是 out Number。
where 关键字 Java 中声明类或接口的时候,可以使用 extends 来设置边界,将泛型类型参数限制为某个类型的子集:
// T 的类型必须是 Animal 的子类型
class Monster < T extends Animal >{
}
注意这个和前面讲的声明变量时的泛型类型声明是不同的东西,这里并没有 ?。
同时这个边界是可以设置多个,用 & 符号连接:
// T 的类型必须同时是 Animal 和 Food 的子类型
class Monster < T extends Animal & Food >{
}
Kotlin 只是把 extends 换成了 : 冒号。
class Monster < T : Animal >
设置多个边界可以使用 where 关键字:
class Monster < T > where T : Animal , T : Food
reified 关键字 由于 Java 中的泛型存在类型擦除的情况,任何在运行时需要知道泛型确切类型信息的操作都没法用了。
比如你不能检查一个对象是否为泛型类型 T 的实例:
< T > void printIfTypeMatch ( Object item ) {
if ( item instanceof T ) { // 👈 IDE 会提示错误,illegal generic type for instanceof
System . out . println ( item );
}
}
Kotlin 里同样也不行:
fun < T > printIfTypeMatch ( item : Any ) {
if ( item is T ) { // 👈 IDE 会提示错误,Cannot check for instance of erased type: T
println ( item )
}
}
这个问题,在 Java 中的解决方案通常是额外传递一个 Class<T> 类型的参数,然后通过 Class#isInstance 方法来检查:
< T > void check ( Object item , Class < T > type ) {
if ( type . isInstance ( item )) {
System . out . println ( item );
}
}
Kotlin 中同样可以这么解决,不过还有一个更方便的做法:使用关键字 reified 配合 inline 来解决:
inline fun < reified T > printIfTypeMatch ( item : Any ) {
if ( item is T ) {
println ( item )
}
}
编译器解释器 编译器和解释器都是将高级语言代码转换成机器码的工具,但它们之间有一些关键区别:
编译器:一次性将整个程序代码转换成目标机器的可执行文件,执行时无需再进行翻译,因此执行速度通常较快。但编译过程需要额外的时间,且生成的可执行文件在不同平台上不可移植。 解释器:逐行解释源代码,并将其转换成机器码执行。解释器不需要生成可执行文件,因此节省了编译时间,但执行速度通常较慢。另外,解释器可以实现跨平台的代码执行,因为源代码在不同平台上均需要解释器来执行。 JVM核心功能 JVM的主要作用是执行Java程序的字节码。在Java应用程序开发中,Java源代码首先被编译成字节码文件(.class文件),而不是本地机器码。
这个字节码是一种与平台无关的中间表示,可以在任何支持Java的平台上运行。
JVM字节码的执行过程大概可以分为以下几个步骤:
装载:虚拟机启动后,通过类加载器将.class文件加载到内存中,并进行解析。 链接:将被引用的类、方法、变量等符号引用转化为直接引用,并将常量池中的符号引用替换为直接引用。 初始化:对类进行初始化。包括执行类构造器<clinit>()方法,静态变量赋值等。 解释执行:将解析后的字节码逐行解释执行,根据操作码执行相应的操作。 编译执行:如果某个方法被多次执行,JIT编译器会将其编译为本地代码,以提高执行效率。 垃圾回收:JVM自动进行垃圾回收,将不再使用的对象进行回收,释放内存空间。 总的来说,JVM字节码的执行过程包括“装载-链接-初始化-解释执行/编译执行-垃圾回收”等几个步骤,其中解释执行和编译执行是主要的执行方式。
跨平台特性 JVM跨平台兼容性的原因是因为Java程序编译后生成的是字节码(ByteCode)而不是特定平台上的机器码(Machine Code)。也就是说,Java程序并不是直接翻译成本地平台上的机器码,而是转换成JVM可以识别的字节码,最终由JVM解释执行或编译成本地平台上的机器码。
也就是说JVM充当了一个中间层,负责将字节码翻译成特定操作系统的机器码。
这样做的好处是,由于Java程序并不会直接依赖于本地操作系统或硬件,所以只要有支持Java虚拟机的平台,就可以在该平台上运行Java程序,而不需要对程序进行修改。
这种跨平台机制使得Java程序可以在多个操作系统上进行编译和执行,从而使得Java成为一种性能良好、易于移植的语言。因此,JVM被认为是一种跨平台运行的虚拟机,Java也因此而被大量使用。
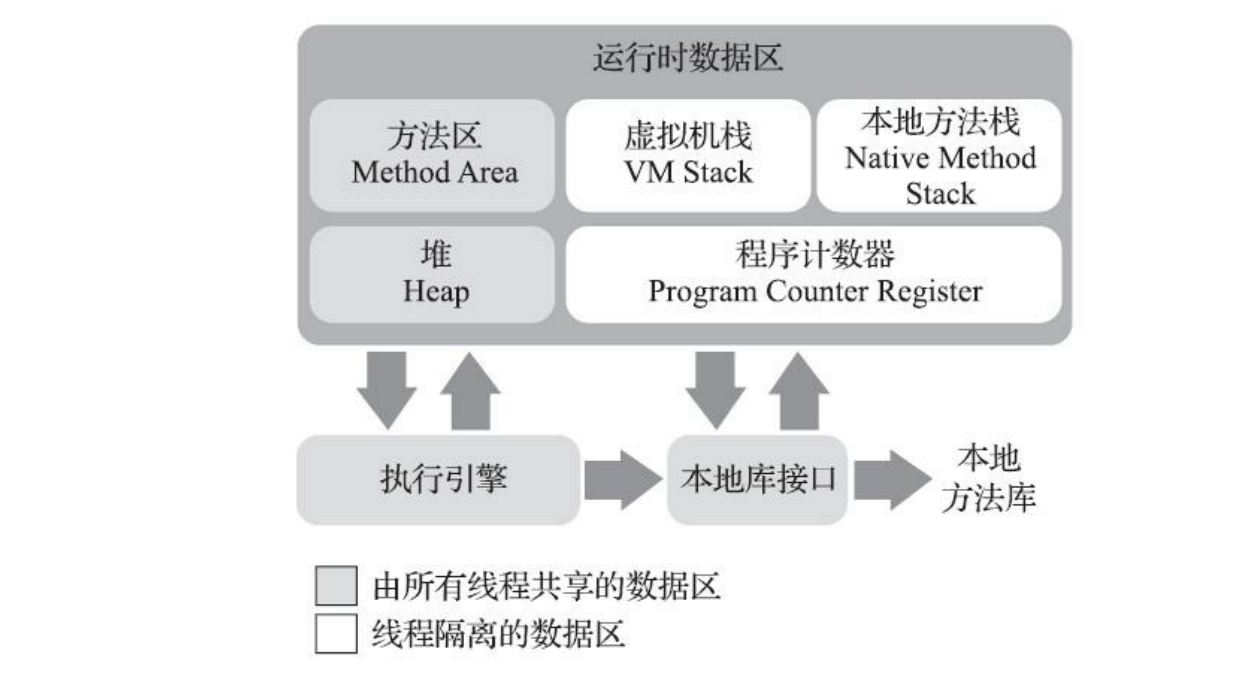
Java内存区域 每一个java进程都是运行在一个独立的jvm虚拟机里面的,彼此之间数据隔离不互通。
一个进程所处的Java虚拟机的内存可以用下面这张热门图片概括:
程序计数器:一小块区域, 线程私有 。记录了每个线程的代码执行到了哪一行,各种循环,判断都是通过这个区域存的数值来走的。Java多线程是时间分片,各个线程在一段时间内占用这个核来执行任务,这个线程切换到另一个线程,其恢复的依据也是计数器的值。 虚拟机栈:周期与线程相同,也是 线程私有 。每个方法执行时,都会创建一个栈帧, 栈帧里面存储方法内的局部变量表,方法出口等等信息 。每个方法执行到退出的过程,就是一个个的方法栈帧入栈出栈的过程。这个区域有两个异常,如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;如果JVM允许动态扩展,当栈扩展时无法申请到足够的内存会抛出 OutOfMemoryError 异常。 本地方法栈:和虚拟机栈作用一样,但是服务于 本地的Native方法 。同样会抛出上面的两种异常。 Java堆:最大的一块,所有 线程共享 的数据。几乎所有的对象实例都在这里保存。Java堆是垃圾收集器管理的内存区域。Java堆可以处于物理上不连续的内存空间中,可以选择固定大小或可扩展。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出 OutOfMemoryError 异常。 方法区: 线程共享 。用于存储已被虚拟机加载的 对象类型信息、常量、静态变量、即时编译器编译后的代码缓存 等数据。对其要求比较宽松,几乎不用考虑垃圾回收,但是回收也是有必要的,主要针对常量的回收和类型卸载。如果方法区无法满足新的内存分配需求时,将抛出 OutOfMemoryError 异常。运行时常量池,其是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。运行期间也可以将新的常量放入池中。 直接内存:直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现。在JDK 1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。 更详细的内存分配图如下:
对象创建 当遇到new字节码时,首先会检查这个指令参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
对象所需的内存大小在类加载完成即可完全确定下来。为对象分配内存即把一块确定大小的内存块从Java堆中分离出来使用。
假设Java堆中的内存是规整的,使用的内存在一边,空闲的内存在另一边,中间放置一个指针作为分界点指示器,那分配内存就是把指针往空闲的区域移动一段距离,这种方式叫 指针碰撞 。
如果堆内存是相互交错的,那么虚拟机就必须维护一个列表,记录哪些内存是可用的,分配内存时就是从列表中找到一块足够大的区域给对象实例,再更新纪录,这种方式叫做 空闲列表 。
采用哪种方式由垃圾收集器是否带有空间压缩整理的能力决定。
并发安全解决方案 对象创建是非常频繁的行为,可能在为对象A分配时,指针还未修改,对象B又从原来的指针指向处开始分配内存。
分配收尾 分配完成后需要把分配空间全部置零,确保对象实例字段再Java代码中可以不赋初值直接使用。 接下来,Java虚拟机还要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码(实际上对象的哈希码会延后到真正调用Object::hashCode()方法时才计算)、对象的GC分代年龄等信息。这些信息存放在对象的对象头(Object Header)之中。根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
虚拟机的视角,对象已经分配完成,从程序的视角看,对象创建才看看开始,到其构造函数。
对象在堆中的内存分配 分为三个部分:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
对象头 分为两部分,首先是对象运行时数据,如哈希码,GC分代信息,锁状态标志等,在32位和64位虚拟机上,这部分数据分别占32bit和64bit。且被设计成动态定义的数据结构,以存储尽量多的数据。 另一部分是类型指针,指向对象元数据的指针,虚拟机根据这个确定对象是哪一个类的实例,并不是所有实例都会保留类型指针。
实例数据 我们所定义的各种类型的字段类容,内存分配顺序为longs/doubles、ints、shorts/chars、bytes/booleans、oops(OrdinaryObject Pointers,OOPs)。相同宽度倾向于一起分配,先加载父类定义的,后加载子类自己的。在虚拟机的CompactFields为true时,子类里较短的变量也会插入父类的空隙中以节省空间。
对齐填充 对象的第三部分是对齐填充,这并不是必然存在的,也没有特别的含义.JVM要求对象起始地址必须是8字节的整数倍,即对象占用空间大小也必须是8字节整数倍,不够的部分就会被对齐填充。
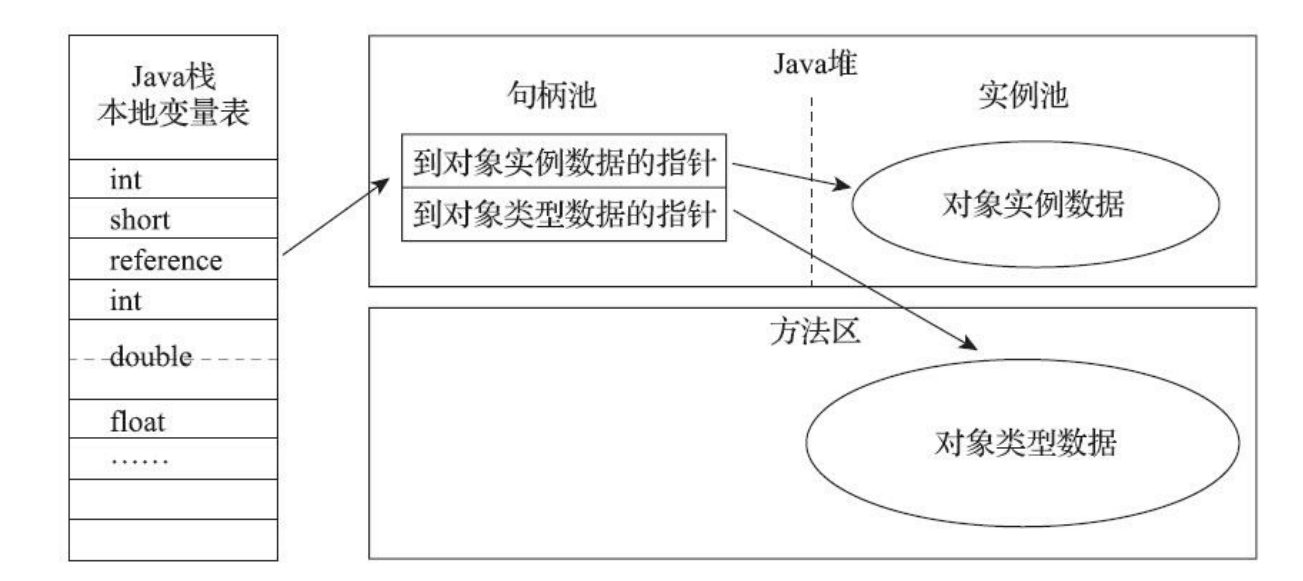
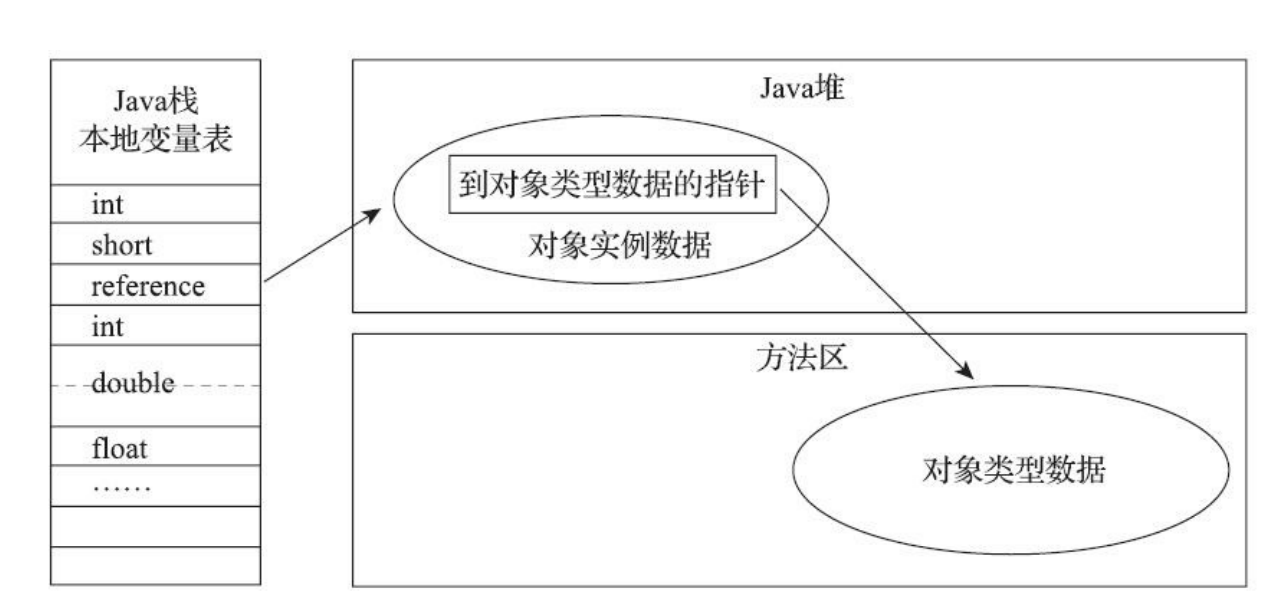
对象的访问 Java程序通过栈上的reference数据来操作堆上的具体对象。两种方式,通过句柄访问和指针直接访问。
句柄访问 Java堆中将可能会划分出一块内存来作为句柄池,句柄包含对象的示例数据的指针和对象类型数据的指针。
使用句柄来访问的最大好处就是reference中存储的是稳定句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要被修改。
直接指针 这种方式来访问对象,Java堆中对象的内存布局就必须考虑如何放置访问类型数据的相关信息,reference中存储的直接就是对象地址,如果只是访问对象本身的话,就不需要多一次间接访问的开销。
使用直接指针来访问最大的好处就是速度更快,它节省了一次指针定位的时间开销。由于对象访问在Java中非常频繁,因此这类开销积少成多也是一项极为可观的执行成本。
垃圾回收 垃圾回收,即GC(Garbage Collection),回收无用内存空间,使其对未来实例可用的过程。由于设备的内存空间是有限的,为了防止内存空间被占满导致应用程序无法运行,就需要对无用对象占用的内存进行回收,也称垃圾回收。 垃圾回收过程中除了会清理废弃的对象外,还会清理内存碎片,完成内存整理。
判断对象是否存活的方法 GC堆内存中存放着几乎所有的对象(方法区中也存储着一部分),垃圾回收器在对该内存进行回收前,首先需要确定这些对象哪些是“活着”,哪些已经“死去”,内存回收就是要回收这些已经“死去”的对象。
那么如何其判断一个对象是否还“活着”呢?方法主要由如下两种:
引用计数法 该算法由于无法处理对象之间相互循环引用的问题,在Java中并未采用该算法,在此不做深入探究;
根搜索算法(GC ROOT Tracing) Java中采用了该算法来判断对象是否是存活的,也叫可达性分析。
通过一系列名为 GC Roots 的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论来说就是从GC Roots到这个对象不可达)时,则证明对象是不可用的,即该对象是“死去”的,同理,如果有引用链相连,则证明对象可以,是“活着”的。
哪些可以作为GC Roots的对象呢?Java 语言中包含了如下几种:
1)虚拟机栈(栈帧中的本地变量表)中的引用的对象。
2)方法区中的类静态属性引用的对象。
3)方法区中的常量引用的对象。
4)本地方法栈中JNI(即一般说的Native方法)的引用的对象。
5)运行中的线程
6)由引导类加载器加载的对象
7)GC控制的对象
回收流程 现代商用虚拟机基本都采用分代收集算法来进行垃圾回收,当然这里的分代算法是一种混合算法,不同时期采用不同的算法来回收。
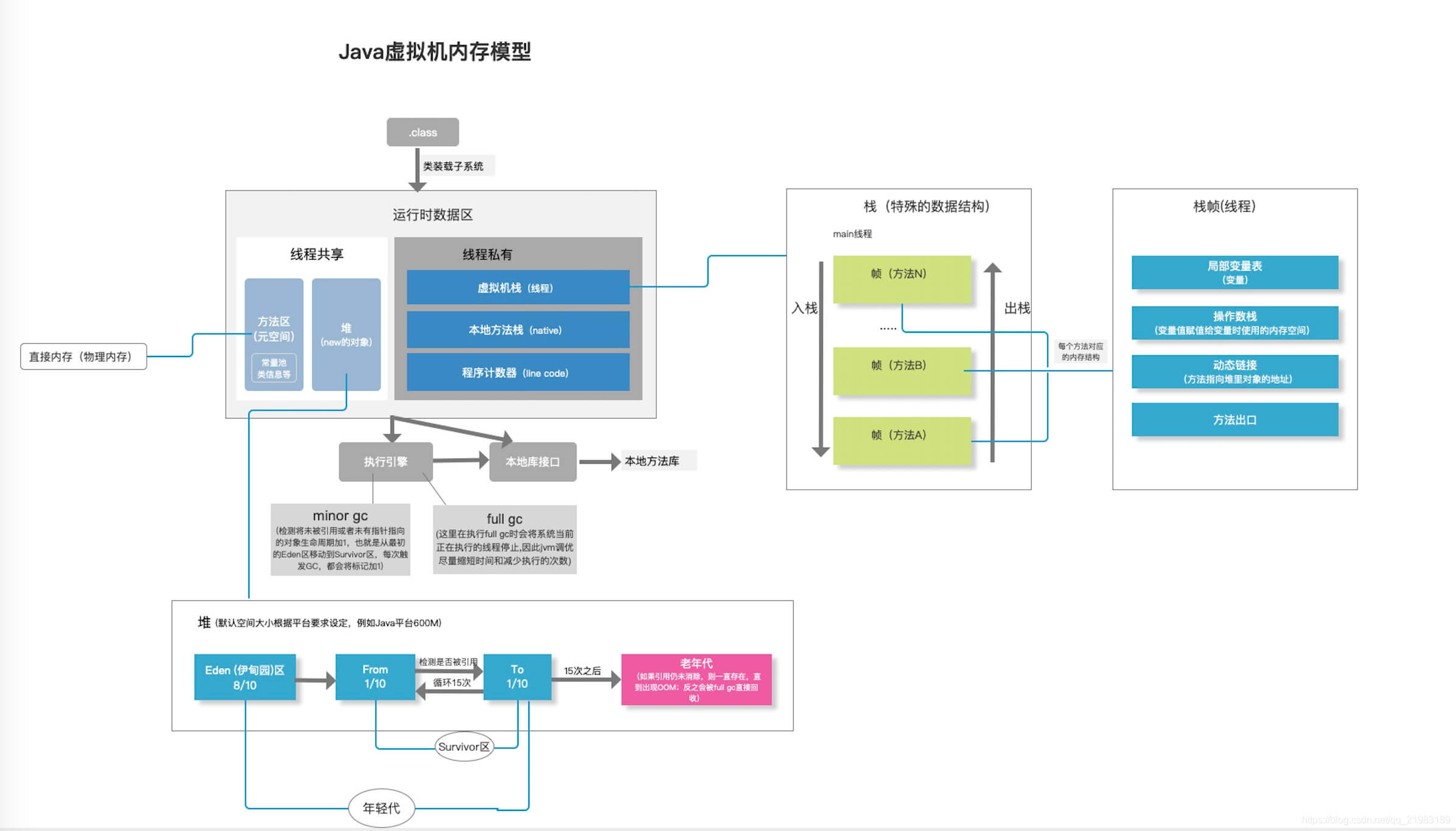
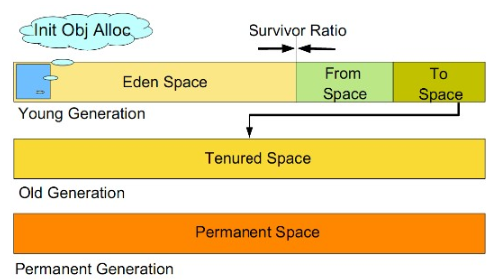
由于不同的对象的生命周期不一样,分代的垃圾回收策略正式基于这一点。因此,不同生命周期的对象可以采取不同的回收算法,以便提高回收效率。该算法包含三个区域:年轻代(Young Generation)、年老代(Old Generation)、持久代(Permanent Generation)。
年轻代(Young Generation) 所有新生成的对象首先都是放在年轻代中。年轻代的目标就是尽可能快速地回收哪些生命周期短的对象。
新生代内存按照8:1:1的比例分为一个Eden区和两个survivor(survivor0,survivor1)区。
Eden区,字面意思翻译过来,就是伊甸区,人类生命开始的地方。当一个实例被创建了,首先会被存储在该区域内,大部分对象在Eden区中生成。 Survivor区,幸存者区,字面理解就是用于存储幸存下来对象。 回收时机:
一开始都在Eden区里,当Eden快满了就触发回收,之后,先将Eden区还存活的对象复制到一个Survivor0区,然后清空Eden区。 当这个Survivor0区也存放满了后,则将Eden和Survivor0区中存活对象都复制到另外一个survivor1区,然后清空Eden和这个Survivor0区,此时的Survivor0区就也是空的了。 然后将Survivor0区和Survivor1区交换,即保持Servivor1为空,如此往复。 这种回收算法也叫 复制算法 ,即将存活对象复制到另一个区域,然后尽可能清空原来的区域。
新生代发生的GC也叫做 Minor GC ,MinorGC发生频率比较高,不一定等Eden区满了才会触发。
为什么设置两个survivor区域?
如果只有一个eden区和一个survivor区,那么假设场景,当发生ygc后,存活对象从eden迁移到survivor,这样看好像没什么问题,很棒,但是假设eden满了,这个时候要进行ygc,那么发现此时,eden和survivor都保存有存活对象,那么你是不是要对这两个区域进行gc,找出存活对象,那么你想想是不是难度很大,还容易造成碎片,如果你使用复制算法,那么难度很大,如果你使用标记清除算法,那么容易造成内存碎片,如果你使用标记清除算法,那么耗时很长。
所以如果存在两个survivor区,那么工作就非常的 轻松,只需要在eden区和其中一个survivor(b1)找出存活对象,一次性放到另一个空的survivor(b2),然后再直接清除eden区和survivor(b1),这样效率是不是很快?快的一。
年轻代往老年代转移的条件
有一个JVM参数 -XX:PretenureSizeThreshold ,默认值是 0 ,表示任何情况都先把对象分配给 Eden 区。若设置为1048576字节,也就是1M。则表示当创建的对象大于1M时,就会直接把这个对象放入到老年区,就根本不会经过新生区了。这么做的原因:大对象在经历复制算法进行GC的时候会降低性能。 如果新生区中的某个对象 经历了15次GC 后,还是没有被回收掉,那么它就会被转入老年区。 如果当 Survivor1 区不足以存放 Eden 区和 Survivor0 的存活对象时,就将存活对象 直接放到年老代 。 如果年老代也满了,就会触发一次 Major GC(Full GC) ,即新生代和年老代都进行回收。
年老代(Old Generation) 在新生代中经历了多次GC后仍然存活的对象,就会被放入到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
年老代比新生代内存大很多(大概比例2:1?),当年老代中存满时触发 Full GC ,其发生频率比较低,年老代对象存活时间较长,存活率比较高。
一开始对象都是任意分布的,在经历完垃圾回收之后,就会标记出哪些是存活对象,哪些是垃圾对象,然后就会把这些存活的对象在内存中进行整理移动,尽量都挪到一边去靠在一起,然后再把垃圾对象进行清除,这样做的好处就是避免了垃圾回收后产生的大片内存碎片。
即此处采用的叫 Compacting 算法,由于该区域比较大,而且通常对象生命周期比较长,compaction需要一定的时间,所以这部分的GC时间比较长,较为耗时。
所以如果系统频繁出现Full GC,会严重影响系统性能,出现卡顿。所以JVM优化的一大问题就是减少Full GC频率。
持久代(Permanent Generation) 持久代用于存放 静态文件,如Java类、方法等 ,该区域比较稳定,对GC没有显著影响。这一部分也被称为运行时常量,有的版本说JDK1.7后该部分从方法区中移到GC堆中,有的版本却说,JDK1.7后该部分被移除,有待考证。
垃圾回收时线程的表现 STW STW事件(Stop-The-World)是指在垃圾回收过程中,Java虚拟机(JVM)需要暂停所有应用程序线程。
STW原因 垃圾回收的分析工作必须在一个能确保一致性的快照中进行。一致性指整个分析期间整个执行系统看起来像被冻结在某个时间点上,如果出现分析过程中对象引用关系还在不断变化,则分析结果的准确性无法保证。STW停顿的位置:SafePoint
安全点 安全点是指在程序执行过程中,一些特定的位置,如 方法调用、循环跳转等,这些位置被称为安全点 。在垃圾回收过程中,需要确保在这些安全点上,所有线程都已经停止执行,以确保一致性。
减少STW带来的影响 需要对垃圾收集器的配置进行优化,例如选择不同类型的垃圾收集器、调整堆大小或其他垃圾收集器参数。
例如,选择并发回收器作为垃圾回收器,如CMS、G1等,因为并发回收器主要关注的是减少STW的时长。它允许垃圾收集线程在应用程序线程运行的同时执行部分垃圾收集工作,从而减少了STW的时间。在并发回收期间,只会在特定的收集阶段发生短暂的STW。
此外,还可以通过调整堆大小和其他垃圾收集器参数来减少STW的时间。例如,可以通过调整堆大小来减少垃圾收集器在收集过程中的工作量。较小的堆大小可以减少垃圾收集器的工作量,从而减少STW的时间。
类文件的结构 魔数 每个Class文件的头4个字节称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件。
版本号 紧接着魔数的4个字节存储的是Class文件的版本号,Class文件的版本号每个字节都有意义,前2个字节是次版本号(Minor Version),后2个字节是主版本号(Major Version)。
常量池 紧接着主次版本号之后的是常量池入口,常量池可以理解为Class文件之中的资源仓库,它是Class文件结构中与其他项目关联最多的数据类型,也是占用Class文件空间最大的数据项目之一,同时它还是在Class文件中第一个出现的表类型数据项目。
常量池中主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。字面量比较接近Java语言层次的常量概念,如文本字符串、被声明为final的常量值等。而符号引用则属于编译原理方面的概念,包括下面三类常量: * 被模块导出或者开放的包(Package) * 类和接口的全限定名(Fully Qualified Name) * 字段的名称和描述符(Descriptor) * 方法的名称和描述符 * 方法句柄和方法类型(Method Handle、Method Type、Invoke Dynamic) * 动态调用点和动态常量(Dynamically-Computed Call Site、Dynamically-Computed Constant)
访问标志 紧接着常量池结束的是访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类的话,是否被声明为final等。
类索引、父类索引与接口索引集合 类索引(this_class)和父类索引(super_class)都是一个u2类型的数据,而接口索引集合(interfaces)是一组u2类型的数据的集合。Class文件中由这三项数据来确定这个类的继承关系。
类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于Java语言的单继承性,所以父类索引只有一个,除了java.lang.Object之外,所有的Java类都有父类,因此除了java.lang.Object外,所有Java类的父类索引都不会是0。
接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按implements语句(如果这个类本身是一个接口,则应当是extends语句)后的接口顺序从左到右排列在接口索引集合中。
字段表集合 字段表(Field Table)用于描述接口或者类中声明的变量。字段包括类级变量以及实例级变量,但不包括在方法内部声明的局部变量。
字段表集合中不会列出从父类或者父接口中继承而来的字段,但有可能列出原本Java代码之中不存在的字段,譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
方法表集合 方法表(Method Table)用于描述接口或者类中声明的方法。
方法表集合中不会列出从父类或者父接口中继承而来的方法,但有可能列出原本Java代码之中不存在的方法,譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
属性表集合 属性表(Attribute Table)用于描述某些场景专有的信息。
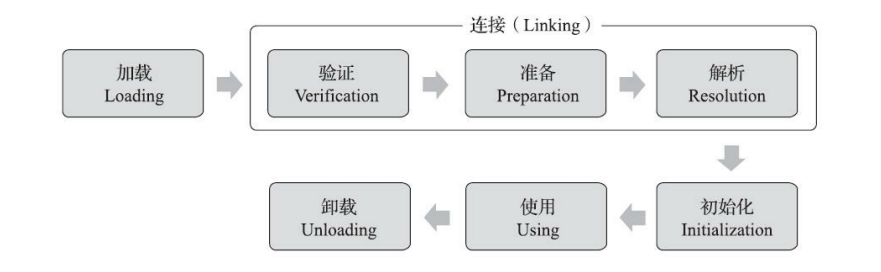
类加载 类生命周期 一个类型从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期将会经历加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)七个阶段,其中验证、准备、解析三个部分统称为连接(Linking)。
解析阶段在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定特性(也称为动态绑定或晚期绑定)。
这些阶段通常都是互相交叉地混合进行的,会在一个阶段执行的过程中调用、激活另一个阶段。
类初始化的六种时机 类加载的时机看作和类初始化的时机是一致的 ,因为初始化的时候,加载,验证准备等阶段一定是在这之前完成的。
关于初始化的时机,《Java虚拟机规范》则是严格规定了 有且只有 六种情况必须立即对类进行“初始化”:
遇到new、getstatic、putstatic或invokestatic这四条字节码指令时,如果类型没有进行过初始化,则需要先触发其初始化阶段。能够生成这四条指令的典型Java代码场景有:使用new关键字实例化对象的时候。 读取或设置一个类型的静态字段(被final修饰、已在编译期把结果放入常量池的静态字段除外)的时候。 调用一个类型的静态方法的时候。 使用java.lang.reflect包的方法对类型进行反射调用的时候,如果类型没有进行过初始化,则需要先触发其初始化。 当初始化类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。1. 当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。 当使用JDK 7新加入的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果为REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial四种类型的方法句柄,并且这个方法句柄对应的类没有进行过初始化,则需要先触发其初始化。 当一个接口中定义了JDK 8新加入的默认方法(被default关键字修饰的接口方法)时,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。 这六种场景中的行为称为对一个类型进行 主动引用 。除此之外,所有引用类型的方式都不会触发初始化,称为 被动引用 。
容易弄错的情况:
类里面的static常量
static常量在编译时,通过常量传播优化,会被放入调用该类的常量池中。外面的代码运行时如果只是调用到这个变量,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
class ConstClass {
static {
System . out . println ( "ConstClass static block" );
}
public static final String HELLOWORLD = "hello world" ;
}
public class Test {
static {
System . out . println ( "Test static block" );
}
public static void main ( String [] args ) {
System . out . println ( ConstClass . HELLOWORLD );
}
}
创建一个包装类型的数组
public class SuperClass {
static {
System . out . println ( "SuperClass init!" );
}
public static int value = 123 ;
}
/**
* 被动使用类字段演示二:
* 通过数组定义来引用类,不会触发此类的初始化
**/
public class NotInitialization {
public static void main ( String [] args ) {
SuperClass [] sca = new SuperClass [ 10 ];
}
}
没有看到“SuperClass init!”,说明没有触发类org.fenixsoft.classloading.SuperClass的初始化阶段。但是这段代码里面触发了 另一个名为“[Lorg.fenixsoft.classloading.SuperClass”的类的初始化阶段,对于用户代码来说,这并不是一个合法的类型名称,它是一个由虚拟机自动生成的、直接继承于java.lang.Object的子类,创建动作由字节码指令newarray触发。
Java语言中对数组的访问要比C/C++相对安全,很大程度上就是因为这个类包装了数组元素的访问,而C/C++中则是直接翻译为对数组指针的移动。在Java语言里,当检查到发生数组越界时会抛出 java.lang.ArrayIndexOutOfBoundsException 异常,避免了直接造成非法内存访问。
加载(Loading)过程 在加载阶段,Java虚拟机需要完成以下三件事情:
1)通过一个类的全限定名来获取定义此类的二进制字节流。 2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。 3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
对于数组类而言,情况就有所不同,数组类本身不通过类加载器创建,它是由Java虚拟机直接在内存中动态构造出来的。
通过一个类的全限定名来获取定义此类的二进制字节流”这条规则,它并没有指明二进制字节流必须得从某个Class文件中获取,确切地说是根本没有指明要从哪里获取、如何获取。
开放定义带来的好处
这也是JVM可以让其他技术借由它遍地开花的主要原因。
从ZIP压缩包中读取,这很常见,最终成为日后JAR、EAR、WAR格式的基础。 从网络中获取,这种场景最典型的应用就是Web Applet。 运行时计算生成,这种场景使用得最多的就是动态代理技术,在java.lang.reflect.Proxy中,就是用了ProxyGenerator.generateProxyClass()来为特定接口生成形式为“*$Proxy”的代理类的二进制字节流。 由其他文件生成,典型场景是JSP应用,由JSP文件生成对应的Class文件。 从数据库中读取,这种场景相对少见些,例如有些中间件服务器(如SAP Netweaver)可以选择把程序安装到数据库中来完成程序代码在集群间的分发。 可以从加密文件中获取,这是典型的防Class文件被反编译的保护措施,通过加载时解密Class文件来保障程序运行逻辑不被窥探。 验证(Verification)过程 验证阶段是非常重要的,这个阶段是否严谨,直接决定了Java虚拟机是否能承受恶意代码的攻击,从代码量和耗费的执行性能的角度上讲,验证阶段的工作量在虚拟机的类加载过程中占了相当大的比重。
文件格式验证 是否以魔数0xCAFEBABE开头。 主、次版本号是否在当前Java虚拟机接受范围之内。 常量池的常量中是否有不被支持的常量类型(检查常量tag标志)。 指向常量的各种索引值中是否有指向不存在的常量或不符合类型的常量。 CONSTANT_Utf8_info型的常量中是否有不符合UTF-8编码的数据。 Class文件中各个部分及文件本身是否有被删除的或附加的其他信息。 …… 元数据验证 这个类是否有父类(除了java.lang.Object之外,所有的类都应当有父类)。 这个类的父类是否继承了不允许被继承的类(被final修饰的类)。 如果这个类不是抽象类,是否实现了其父类或接口之中要求实现的所有方法。 类中的字段、方法是否与父类产生矛盾(例如覆盖了父类的final字段,或者出现不符合规则的方法重载,例如方法参数都一致,但返回值类型却不同等)。 …… 字节码验证 保证任意时刻操作数栈的数据类型与指令代码序列都能配合工作,例如不会出现类似这样的情况:在操作栈放置了一个int类型的数据,使用时却按long类型来加载入本地变量表中。 保证跳转指令不会跳转到方法体以外的字节码指令上。 保证方法体内的类型转换是有效的,例如可以把一个子类对象赋值给父类数据类型,这是安全的,但是把父类对象赋值给子类数据类型,甚至把对象赋值给与它毫无继承关系、完全不相干的一个数据类型,则是危险和不合法的。符号引用验证 符号引用中通过字符串描述的全限定名是否能找到对应的类。 在指定类中是否存在符合方法的字段描述符及简单名称所描述的方法和字段。 符号引用中的类、字段、方法的访问性(private、protected、public、)是否可被当前类访问。 准备(Preparation)过程 准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并 设置类变量初始值 的阶段,从概念上讲,这些变量所使用的内存都应当在方法区中进行分配,但必须注意到方法区本身是一个逻辑上的区域,在JDK 7及之前, HotSpot使用永久代来实现方法区 时,实现是完全符合这种逻辑概念的;而在JDK 8及之后, 类变量则会随着Class对象一起存放在Java堆中 ,这时候“类变量在方法区”就完全是一种对逻辑概念的表述了。
需要注意,这时候进行内存分配的仅包括类变量,而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在Java堆中。
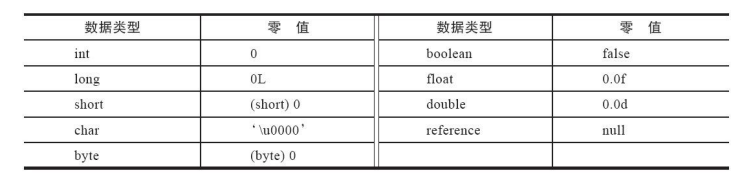
关于初始值,举一个例子:
public static int value = 123 ;
那变量value在准备阶段过后的初始值为0而不是123,因为这时尚未开始执行任何Java方法,而把value赋值为123的putstatic指令是程序被编译后,存放于类构造器<clinit>()方法之中,所以把value赋值为123的动作要到类的初始化阶段才会被执行。
常见的类型的零值:
解析(Resolution)过程 解析阶段是Java虚拟机将常量池内的 符号引用替换为直接引用 的过程。
符号引用:符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。 直接引用:直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是与虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经在内存中存在。 《Java虚拟机规范》之中并未规定解析阶段发生的具体时间,虚拟机实现可以根据需要来自行判断,到底是在类被加载器加载时就对常量池中的符号引用进行解析,还是等到一个符号引用将要被使用前才去解析它。
解析动作主要针对 类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符 这7类符号引用进行,分别对应于常量池的CONSTANT_Class_info、CON-STANT_Fieldref_info、 CONSTANT_Methodref_info、CONSTANT_InterfaceMethodref_info、 CONSTANT_MethodType_info、CONSTANT_MethodHandle_info、CONSTANT_Dyna-mic_info和 CONSTANT_InvokeDynamic_info 8种常量类型。
类或接口的解析 如果类 D 要在解析过程中,对一个未解析过符号引用 N 的类或接口 C 进行解析,需要包括以下三个步骤:
如果C不是一个数组类型,那虚拟机将会把代表N的全限定名传递给D的类加载器去加载这个类C。在加载过程中,由于元数据验证、字节码验证的需要,又可能触发其他相关类的加载动作,例如加载这个类的父类或实现的接口。一旦这个加载过程出现了任何异常,解析过程就将宣告失败。 如果C是一个数组类型,并且数组的元素类型为对象,也就是N的描述符会是类似“[Ljava/lang/Integer”的形式,那将会按照第1点的规则加载数组元素类型。如果N的描述符如前面所假设的形式,需要加载的元素类型就是“java.lang.Integer”,接着由虚拟机生成一个代表此数组维度和元素的数组对象。 如果上面的步骤没有出现任何异常,那么C在虚拟机中实际上已经成为一个有效的类或接口了,但在解析完成之前还要进行符号引用验证,以确保解析结果能在虚拟机中使用。如果验证不通过,将抛出一个java.lang.IncompatibleClassChangeError异常的子类,如java.lang.IllegalAccessError、java.lang.AbstractMethodError、java.lang.InstantiationError等。 访问权限验证
如果我们说一个D拥有C的访问权限,那就意味着以下3条规则中至少有其中一条成立:
被访问类C是public的,并且与访问类D处于同一个模块。 被访问类C是public的,不与访问类D处于同一个模块,但是被访问类C的模块允许被访问类D的模块进行访问。 被访问类C不是public的,但是它与访问类D处于同一个包中。 字段解析 要解析一个未被解析过的字段符号引用,首先将会对字段表内class_index 项中索引的CONSTANT_Class_info符号引用进行解析,也就是字段所属的类或接口的符号引用。
如果在解析这个类或接口符号引用的过程中出现了任何异常,都会导致字段符号引用解析的失败。
如果解析成功完成,那把这个字段所属的类或接口用C表示,《Java虚拟机规范》要求按照如下步骤对C进行后续字段的搜索:
1)如果C本身就包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,查找结束。 2)否则,如果在C中实现了接口,将会按照继承关系从下往上递归搜索各个接口和它的父接口,如果接口中包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,查找结束。 3)否则,如果C不是java.lang.Object的话,将会按照继承关系从下往上递归搜索其父类,如果在父类中包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,查找结束。 4)否则,查找失败,抛出java.lang.NoSuchFieldError异常。如果查找过程成功返回了引用,将会对这个字段进行权限验证,如果发现不具备对字段的访问权限,将抛出java.lang.IllegalAccessError异常。
方法解析 也是需要先解析出方法表的class_index项中索引的方法所属的类或接口的符号引用,如果解析成功,那么我们依然用C表示这个类,接下来虚拟机将会按照如下步骤进行后续的方法搜索:
1)由于Class文件格式中类的方法和接口的方法符号引用的常量类型定义是分开的,如果在类的方法表中发现class_index中索引的C是个接口的话,那就直接抛出java.lang.IncompatibleClassChangeError异常。 2)如果通过了第一步,在类C中查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。 3)否则,在类C的父类中递归查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。 4)否则,在类C实现的接口列表及它们的父接口之中递归查找是否有简单名称和描述符都与目标相匹配的方法,如果存在匹配的方法,说明类C是一个抽象类,这时候查找结束,抛出java.lang.AbstractMethodError异常。 5)否则,宣告方法查找失败,抛出java.lang.NoSuchMethodError。 最后,如果查找过程成功返回了直接引用,将会对这个方法进行权限验证,如果发现不具备对此方法的访问权限,将抛出java.lang.IllegalAccessError异常。
接口方法解析 接口方法也是需要先解析出接口方法表的class_index项中索引的方法所属的类或接口的符号引用,如果解析成功,依然用C表示这个接口,接下来虚拟机将会按照如下步骤进行后续的接口方法搜索:
1)与类的方法解析相反,如果在接口方法表中发现class_index中的索引C是个类而不是接口,那么就直接抛出java.lang.IncompatibleClassChangeError异常。 2)否则,在接口C中查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。 3)否则,在接口C的父接口中递归查找,直到java.lang.Object类(接口方法的查找范围也会包括Object类中的方法)为止,看是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。 4)对于规则3,由于Java的接口允许多重继承,如果C的不同父接口中存有多个简单名称和描述符都与目标相匹配的方法,那将会从这多个方法中返回其中一个并结束查找,《Java虚拟机规范》中并没有进一步规则约束应该返回哪一个接口方法。但与之前字段查找类似地,不同发行商实现的Javac编译器有可能会按照更严格的约束拒绝编译这种代码来避免不确定性。 5)否则,宣告方法查找失败,抛出java.lang.NoSuchMethodError异常。
初始化(Initialization)过程 进行准备阶段时,变量已经赋过一次系统要求的初始零值,而在初始化阶段,则会根据程序员通过程序编码制定的主观计划去初始化类变量和其他资源。我们也可以从另外一种更直接的形式来表达:初始化阶段就是执行类构造器<clinit>()方法的过程。
<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块(static{}块)中的语句 合并产生 的,编译器收集的顺序是由语句在源文件中出现的顺序决定的.
静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问 。
public class Test {
static {
i = 0 ; // 给变量复制可以正常编译通过
System . out . print ( i ); // 这句编译器会提示“非法向前引用”
}
static int i = 1 ;
}
Java虚拟机会保证在子类的<clinit>()方法执行前,父类的<clinit>()方法已经执行完毕。因此在Java虚拟机中第一个被执行的<clinit>()方法的类型肯定是java.lang.Object。由于父类的<clinit>()方法先执行,也就意味着父类中定义的静态语句块要优先于子类的变量赋值操作。
<clinit>()方法对于类或接口来说并不是必需的,如果一个类中没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生成<clinit>()方法。
接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成<clinit>()方法。但接口与类不同的是,执行接口的<clinit>()方法不需要先执行父接口的<clinit>()方法,因为只有当父接口中定义的变量被使用时,父接口才会被初始化。此外,接口的实现类在初始化时也 一样不会执行接口的<clinit>()方法。
Java虚拟机必须保证一个类的<clinit>()方法在多线程环境中被正确地加锁同步,如果多个线程同时去初始化一个类,那么只会有其中一个线程去执行这个类的<clinit>()方法, 其他线程都需要阻塞等待 ,直到活动线程执行完毕<clinit>()方法。如果在一个类的<clinit>()方法中有耗时很长的操作,那就可能造成多个线程阻塞,在实际应用中这种阻塞往往是很隐蔽的。初始化完毕之后,其他线程解除阻塞,则不会再执行<clinit>()方法,因为一个类只会被初始化一次。
类加载器 对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。
这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
举例如下:
/**
* 类加载器与instanceof关键字演示
*
* @author zzm
*/
public class ClassLoaderTest {
public static void main ( String [] args ) throws Exception {
ClassLoader myLoader = new ClassLoader () {
@Override
public Class <?> loadClass ( String name ) throws ClassNotFoundException {
try {
String fileName = name . substring ( name . lastIndexOf ( "." ) + 1 )+ ".class" ;
InputStream is = getClass (). getResourceAsStream ( fileName );
if ( is == null ) {
return super . loadClass ( name );
}
byte [] b = new byte [ is . available ()];
is . read ( b );
return defineClass ( name , b , 0 , b . length );
} catch ( IOException e ) {
throw new ClassNotFoundException ( name );
}
}
};
Object obj = myLoader . loadClass ( "org.fenixsoft.classloading.ClassLoaderTest" ). newInstance ();
System . out . println ( obj . getClass ());
System . out . println ( obj instanceof org . fenixsoft . classloading . ClassLoaderTest );
}
}
// 运行结果:
// class org.fenixsoft.classloading.ClassLoaderTest
// false
双亲委派模型 JVM设计了三层加载器的双亲委派模型,保证了Java程序的稳定运行。
首先问一个问题,如果所有的类都用启动类加载器有什么问题?
无法加载用户自定义类
启动类加载器的局限性:启动类加载器只负责加载JVM核心类库(如 java.lang、java.util 等位于 JAVA_HOME/lib 目录下的类),它无法加载用户自定义的类(如应用程序类)。 路径限制:启动类加载器无法加载 classpath 下的类,导致用户自定义类无法被加载和运行。
类冲突风险
如果所有类都由启动类加载器加载,不同应用或模块中的同名类会冲突,无法隔离。 无法实现模块化:现代Java应用通常需要模块化加载(如OSGi、Java 9模块系统),启动类加载器无法满足这种需求。
灵活性不足
无法动态加载类:启动类加载器无法动态加载类,而应用类加载器(如 AppClassLoader)可以根据需要动态加载类。 无法支持热部署:在Web容器或应用服务器中,热部署需要动态加载和卸载类,启动类加载器无法满足这一需求。
等等
双亲委派模型 站在Java虚拟机的角度来看,只存在两种不同的类加载器:一种是 启动类加载器(BootstrapClassLoader) ,这个类加载器使用C++语言实现,是虚拟机自身的一部分;另外一种就是 其他所有的类加载器 ,这些类加载器都由Java语言实现,独立存在于虚拟机外部,并且全都继承自抽象类 java.lang.ClassLoader 。
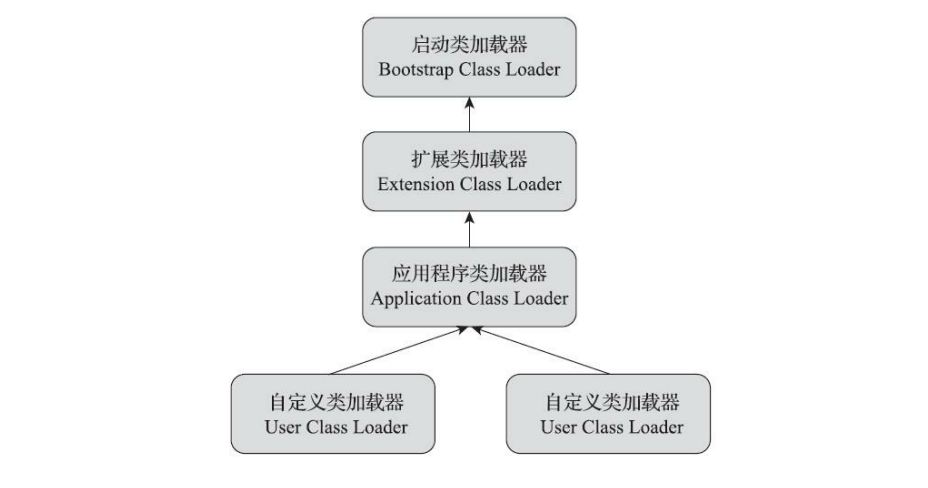
系统提供的三个类加载器:
启动类加载器(Bootstrap Class Loader)
前面已经介绍过,这个类加载器负责加载存放在 <JAVA_HOME>\lib 目录,或者被 -Xbootclasspath 参数所指定的路径中存放的,而且是Java虚拟机能够识别的(按照文件名识别,如rt.jar、tools.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机的内存中。启动类加载器无法被Java程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给引导类加载器去处理,那直接使用null代替即可。
扩展类加载器(Extension Class Loader)
这个加载器由 sun.misc.Launcher$ExtClassLoader 实现,它负责加载 <JAVA_HOME>\lib\ext 目录中,或者被 java.ext.dirs 系统变量所指定的路径中所有的类库,,JDK的开发团队允许用户将具有通用性的类库放置在ext目录里以扩展Java SE的功能,后面被模块化给替代扩展功能。开发者可以直接使用扩展类加载器。
应用程序类加载器(Application Class Loader)
这个类加载器由 sun.misc.Launcher$AppClassLoader 来实现。由于应用程序类加载器是 ClassLoader 类中的 getSystemClassLoader() 方法的返回,所以有些场合中也称它为“系统类加载器”。它负责加载用户类路径(ClassPath)上所有的类库,开发者同样可以直接在代码中使用这个类加载器。
图解关系:
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。不过这里类加载器之间的父子关系一般不是以继承Inheritance)的关系来实现的,而是通常使用组合(Composition)关系来复用父加载器的代码。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求 委派给父类加载器 去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当 父加载器反馈自己无法完成这个加载请求 (它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
代码实现:
protected synchronized Class <?> loadClass ( String name , boolean resolve ) throws ClassNotFoundException
{
// 首先,检查请求的类是否已经被加载过了
Class c = findLoadedClass ( name );
if ( c == null ) {
try {
if ( parent != null ) {
c = parent . loadClass ( name , false );
} else {
c = findBootstrapClassOrNull ( name );
}
} catch ( ClassNotFoundException e ) {
// 如果父类加载器抛出ClassNotFoundException
// 说明父类加载器无法完成加载请求
}
if ( c == null ) {
// 在父类加载器无法加载时
// 再调用本身的findClass方法来进行类加载
c = findClass ( name );
}
}
if ( resolve ) {
resolveClass ( c );
}
return c ;
}
双亲委派模型的革新 Java历史上,出现过不符合双亲委派模型的三大事件:
第一次,是在jdk1.2的这个模型出现之前,双亲委派模型还没有出现,而java.lang.ClassLoader则在Java的第一个版本中就已经存在,面对已经存在的用户自定义类加载器的代码,Java设计者们引入双亲委派模型时不得不做出一些妥协,为了兼容这些已有代码,无法再以技术手段避免loadClass()被子类覆盖的可能性,只能在JDK 1.2之后的java.lang.ClassLoader中添加一个新的protected方法findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在loadClass()中编写代码。避免不符合jvm的这个设计初衷
第二次, 如果有基础类型又要调用回用户的代码 ,那该怎么办呢?
一个典型的例子便是JNDI服务,其存在的目的就是对资源进行查找和集中管理,它需要调用由其他厂商实现并部署在应用程序的ClassPath下的JNDI服务提供者接口(Service Provider Interface,SPI)的代码,现在问题来了,启动类加载器是绝不可能认识、加载这些代码的。
Java的设计团队只好引入了一个不太优雅的设计:线程上下文类加载器 (Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContext-ClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。
有了线程上下文类加载器,程序就可以做一些“舞弊”的事情了。JNDI服务使用这个线程上下文类加载器去加载所需的SPI服务代码,这是一种父类加载器去请求子类加载器完成类加载的行为,这种行为实际上是打通了双亲委派模型的层次结构来逆向使用类加载器,已经违背了双亲委派模型的一般性原则。
但也是无可奈何的事情。Java中涉及SPI的加载基本上都采用这种方式来完成,例如JNDI、JDBC、JCE、JAXB和JBI等。不过,当SPI的服务提供者多于一个的时候,代码就只能根据具体提供者的类型来硬编码判断,为了消除这种极不优雅的实现方式,在JDK 6时,JDK提供了 java.util.ServiceLoader 类,以META-INF/services中的配置信息,辅以责任链模式,这才算是给SPI的加载提供了一种相对合理的解决方案。
第三次,是由于用户对程序动态性的追求而导致的。对于个人电脑来说,重启一次其实没有什么大不了的,但对于一些生产系统来说,关机重启一次可能就要被列为生产事故,这种情况下热部署就对软件开发者,尤其是大型系统或企业级软件开发者具有很大的吸引力。
那时候最热门的是以IBM公司主导的 JSR-291(即OSGi R4.2) 提案。
OSGi实现模块化热部署的关键是它自定义的类加载器机制的实现,每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。在OSGi环境下,类加载器不再双亲委派模型推荐的树状结构,而是进一步发展为更加复杂的网状结构,当收到类加载请求时,OSGi将按照下面的顺序进行类搜索:
1)将以java.*开头的类,委派给父类加载器加载。 2)否则,将委派列表名单内的类,委派给父类加载器加载。 3)否则,将Import列表中的类,委派给Export这个类的Bundle的类加载器加载。 4)否则,查找当前Bundle的ClassPath,使用自己的类加载器加载。 5)否则,查找类是否在自己的Fragment Bundle中,如果在,则委派给Fragment Bundle的类加载器加载。 6)否则,查找Dynamic Import列表的Bundle,委派给对应Bundle的类加载器加载。 7)否则,类查找失败。
上面的查找顺序中只有开头两点仍然符合双亲委派模型的原则,其余的类查找都是在平级的类加载器中进行的。
模块化 为了能够实现模块化的关键目标—— 可配置的封装隔离机制 ,Java虚拟机对类加载架构也做出了相应的变动调整,才使模块化系统得以顺利地运作。
除了像Jar包一样充当代码容器以外,Java的模块定义还包含以下内容:
依赖其他模块的列表。 导出的包列表,即其他模块可以使用的列表。 开放的包列表,即其他模块可反射访问模块的列表。 使用的服务列表。 提供服务的实现列表。 JDK 9之前,如果类路径中缺失了运行时依赖的类型,那就只能等程序运行到发生该类型的加载、链接时才会报出运行的异常。
而在JDK 9以后,如果启用了模块化进行封装,模块就可以声明对其他模块的显式依赖,这样Java虚拟机就能够在启动时验证应用程序开发阶段设定好的依赖关系在运行期是否完备,如有缺失那就直接启动失败,从而避免了很大一部分由于类型依赖而引发的运行时异常。
可配置的封装隔离机制还解决了原来类路径上跨JAR文件的public类型的可访问性问题。JDK 9中的public类型不再意味着程序的所有地方的代码都可以随意访问到它们,模块提供了更精细的可访问性控制,必须明确声明其中哪一些public的类型可以被其他哪一些模块访问,这种访问控制也主要是在类加载过程中完成的。
兼容传统类路径加载机制 JDK 9提出了与“类路径”(ClassPath)相对应的“模块路径”(ModulePath)的概念。简单来说,就是某个类库到底是模块还是传统的JAR包,只取决于它存放在哪种路径上。
JAR文件在类路径的访问规则:所有类路径下的JAR文件及其他资源文件,都被视为自动打包在一个匿名模块(Unnamed Module)里,这个匿名模块几乎是没有任何隔离的,它可以看到和使用类路径上所有的包、JDK系统模块中所有的导出包,以及模块路径上所有模块中导出的包。
模块在模块路径的访问规则:模块路径下的具名模块(Named Module)只能访问到它依赖定义中列明依赖的模块和包,匿名模块里所有的内容对具名模块来说都是不可见的,即具名模块看不见传统JAR包的内容。
JAR文件在模块路径的访问规则:如果把一个传统的、不包含模块定义的JAR文件放置到模块路径中,它就会变成一个自动模块(Automatic Module)。尽管不包含module-info.class,但自动模块将默认依赖于整个模块路径中的所有模块,因此可以访问到所有模块导出的包,自动模块也默认导出自己所有的包。
以上3条规则保证了即使Java应用依然使用传统的类路径,升级到JDK 9对应用来说几乎不会有任何感觉。
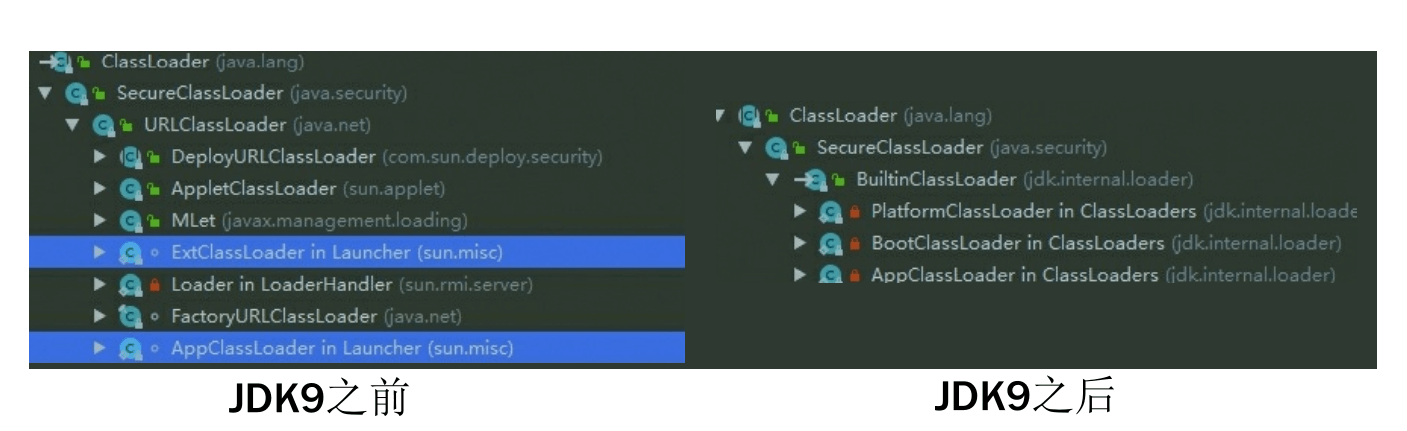
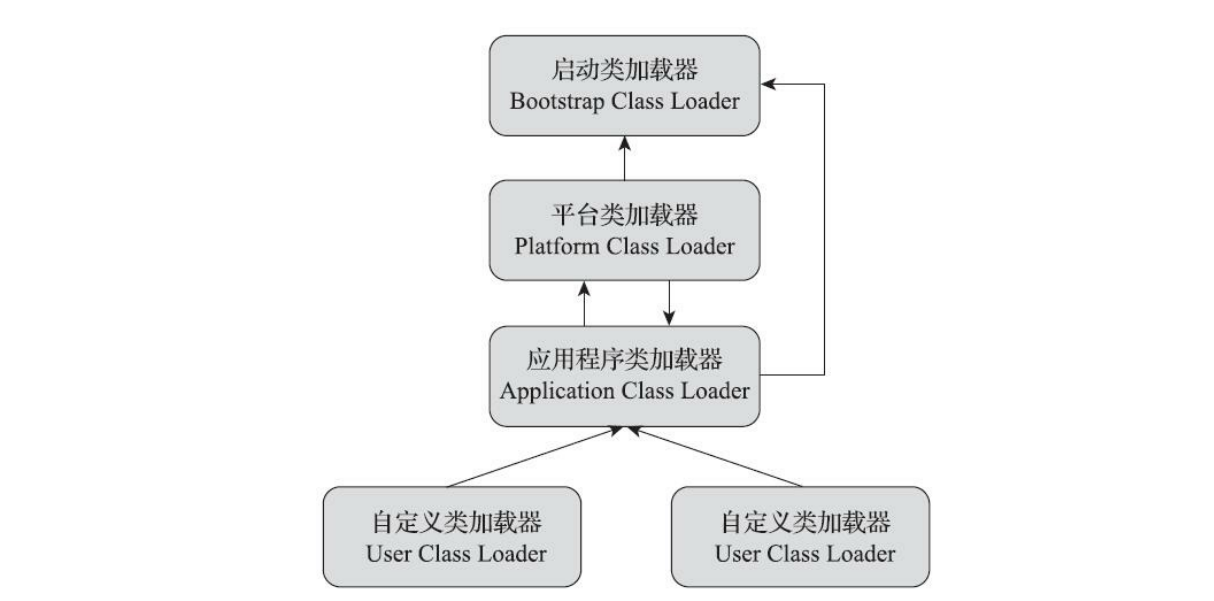
模块化升级后的类加载器结构 首先,是扩展类加载器(Extension Class Loader)被平台类加载器(Platform Class Loader)取代。这其实是一个很顺理成章的变动,既然整个JDK都基于模块化进行构建(原来的rt.jar和tools.jar被拆分成数十个JMOD文件),其中的Java类库就已天然地满足了可扩展的需求,那自然无须再保留 <JAVA_HOME>\lib\ext 目录,此前使用这个目录或者java.ext.dirs系统变量来扩展JDK功能的机制已经没有继续存在的价值了
其次,平台类加载器和应用程序类加载器都不再派生自java.net.URLClassLoader,如果有程序直接依赖了这种继承关系,或者依赖了URLClassLoader类的特定方法,那代码很可能会在JDK 9及更高版 本的JDK中崩溃。现在启动类加载器、平台类加载器、应用程序类加载器全都继承于jdk.internal.loader.BuiltinClassLoader,在BuiltinClassLoader中实现了新的模块化架构下类如何从模块中加载的逻辑,以及模块中资源可访问性的处理。
启动类加载器现在是在Java虚拟机内部和Java类库共同协作实现的类加载器,尽管有了BootClassLoader这样的Java类,但为了与之前的代码保持兼容,所有在获取启动类加载器的场景(譬如Object.class.getClassLoader())中仍然会返回null来代替,而不会得到BootClassLoader的实例。
java.base java.security.sasl
java.datatransfer java.xml
java.desktop jdk.httpserver
java.instrument jdk.internal.vm.ci
java.logging jdk.management
java.management jdk.management.agent
java.management.rmi jdk.naming.rmi
java.naming jdk.net
java.prefs jdk.sctp
java.rmi jdk.unsupported
java.activation* jdk.accessibility
java.compiler* jdk.charsets
java.corba* jdk.crypto.cryptoki
java.scripting jdk.crypto.ec
java.se jdk.dynalink
java.se.ee jdk.incubator.httpclient
java.security.jgss jdk.internal.vm.compiler*
java.smartcardio jdk.jsobject
java.sql jdk.localedata
java.sql.rowset jdk.naming.dns
java.transaction* jdk.scripting.nashorn
java.xml.bind* jdk.security.auth
java.xml.crypto jdk.security.jgss
java.xml.ws* jdk.xml.dom
java.xml.ws.annotation* jdk.zipfs
jdk.aot jdk.jdeps
jdk.attach jdk.jdi
jdk.compiler jdk.jdwp.agent
jdk.editpad jdk.jlink
jdk.hotspot.agent jdk.jshell
jdk.internal.ed jdk.jstatd
jdk.internal.jvmstat jdk.pack
jdk.internal.le jdk.policytool
jdk.internal.opt jdk.rmic
jdk.jartool jdk.scripting.nashorn.shell
jdk.javadoc jdk.xml.bind*
jdk.jcmd jdk.xml.ws*
jdk.jconsole
字节码执行 物理机的执行引擎是直接建立在处理器、缓存、指令集和操作系统层面上的,而虚拟机的执行引擎则是由软件自行实现的,因此可以不受物理条件制约地定制指令集与执行引擎的结构体系,能够执行那些不被硬件直接支持的指令集格式。
在不同的虚拟机实现中,执行引擎在执行字节码的时候,通常会有解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)两种 选择,也可能两者兼备,还可能会有同时包含几个不同级别的即时编译器一起工作的执行引擎。
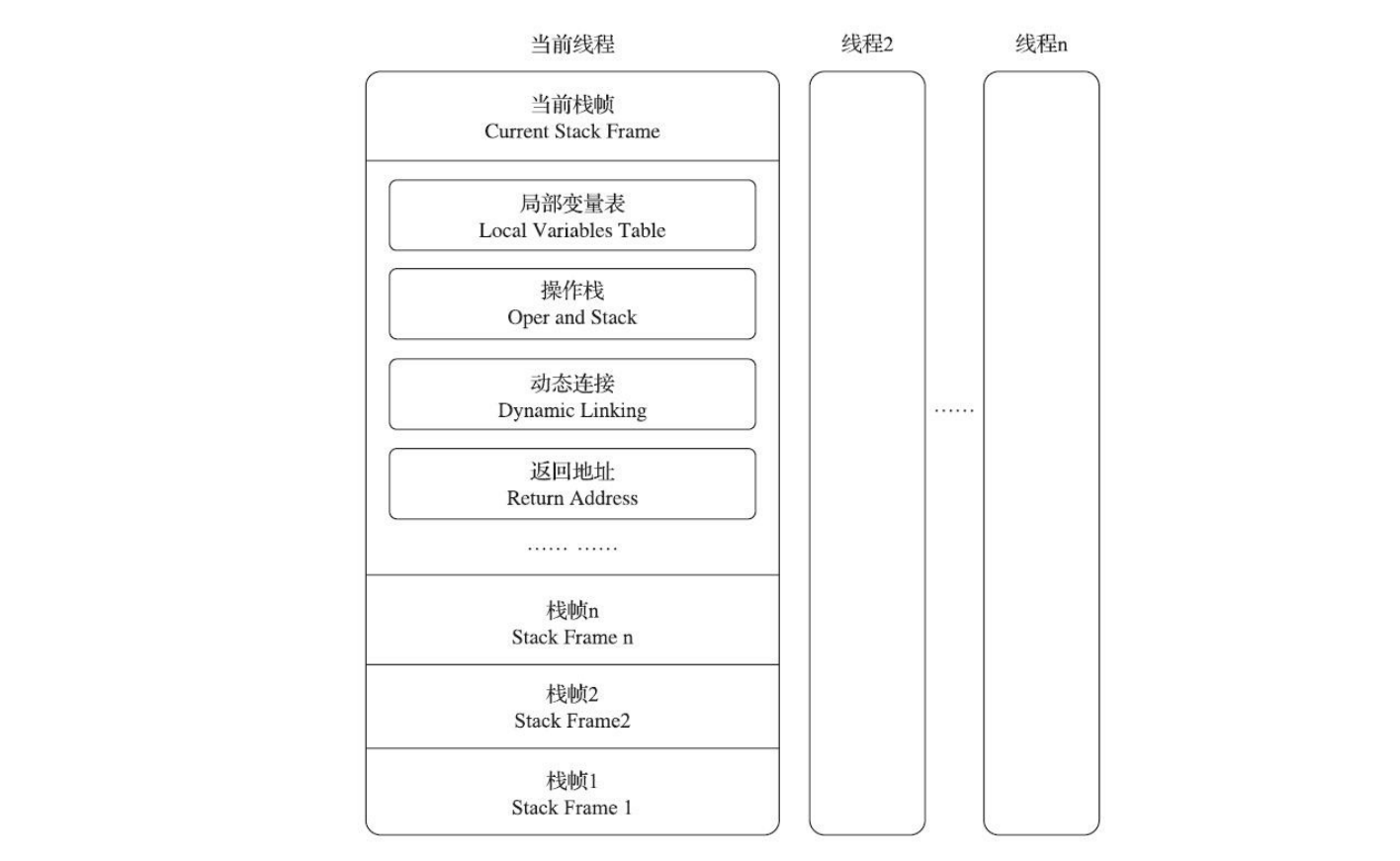
栈帧 Java虚拟机以方法作为最基本的执行单元,“栈帧”(Stack Frame)则是用于支持虚拟机进行方法调用和方法执行背后的数据结构,它也是虚拟机运行时数据区中的虚拟机栈(Virtual MachineStack)的栈元素。栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。
每一个方法从调用开始至执行结束的过程,都对应着一个栈帧在虚拟机栈里面从入栈到出栈的过程。每一个栈帧都包括了局部变量表、操作数栈、动态连接、方法返回地址和一些额外的附加信息。在编译Java程序源码的时候,栈帧中需要多大的局部变量表,需要多深的操作数栈就已经被分析计算出来,并且写入到方法表的Code属性之中。换言之,一个栈帧需要分配多少内存,并不会受到程序运行期变量数据的影响,而仅仅取决于程序源码和具体的虚拟机实现的栈内存布局形式。
一个线程中的方法调用链可能会很长。
以Java程序的角度来看,同一时刻、同一条线程里面,在调用堆栈的所有方法都同时处于执行状态。 而对于执行引擎来讲,在活动线程中,只有位于栈顶的方法才是在运行的,只有位于栈顶的栈帧才是生效的,其被称为“当前栈帧”(Current Stack Frame),与这个栈帧所关联的方法被称为“当前方法”(Current Method)。执行引擎所运行的所有字节码指令都只针对当前栈帧进行操作。 局部变量表 局部变量表(Local Variables Table)是一组变量值的存储空间,用于存放方法参数和方法内部定义的局部变量。在Java程序被编译为Class文件时,就在方法的Code属性的max_locals数据项中确定了该方法所需分配的局部变量表的最大容量。
局部变量表的容量以变量槽(Variable Slot)为最小单位,《Java虚拟机规范》中很有导向性地说到 每个变量槽都应该能存放一个boolean、byte、char、short、int、float、reference或returnAddress类型的数据 ,这8种数据类型,都可以使用32位或更小的物理内存来存储,这种描述允许变量槽的长度可以随着处理器、操作系统或虚拟机实现的不同而发生变化,保证了即使在64位虚拟机中使用了64位的物理内存空间去实现一个变量槽,虚拟机仍要使用对齐和补白的手段让变量槽在外观上看起来与32位虚拟机中的一致。
操作数栈 操作数栈(Operand Stack)也常被称为操作栈,同局部变量表一样,操作数栈的最大深度也在编译的时候被写入到Code属性的max_stacks数据项之中。
操作数栈的每一个元素都可以是包括long和double在内的任意Java数据类型。32位数据类型所占的栈容量为1,64位数据类型所占的栈容量为2。
Javac编译器的数据流分析工作保证了在方法执行的任何时候,操作数栈的深度都不会超过在max_stacks数据项中设定的最大值。当一个方法刚刚开始执行的时候,这个方法的操作数栈是空的,在方法的执行过程中,会有各种 字节码指令往操作数栈中写入和提取内容,也就是出栈和入栈操作。
譬如在做算术运算的时候是通过将运算涉及的操作数栈压入栈顶后调用运算指令来进行的,又譬如在调用其他方法的时候是通过操作数栈来进行方法参数的传递。举个例子,例如整数加法的字节码指令iadd,这条指令在运行的时候要求操作数栈中最接近栈顶的两个元素已经存入了两个int型的数值,当执行这个指令时,会把这两个int值出栈并相加,然后将相加的结果重新入栈。
操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,在编译程序代码的时候,编译器必须要严格保证这一点,在类校验阶段的数据流分析中还要再次验证这一点。
再以上面的iadd指令为例,这个指令只能用于整型数的加法,它在执行时,最接近栈顶的两个元素的数据类型必须为int型,不能出现一个long和一个float使用iadd命令相加的情况。另外在概念模型中,两个不同栈帧作为不同方法的虚拟机栈的元素,是完全相互独立的。
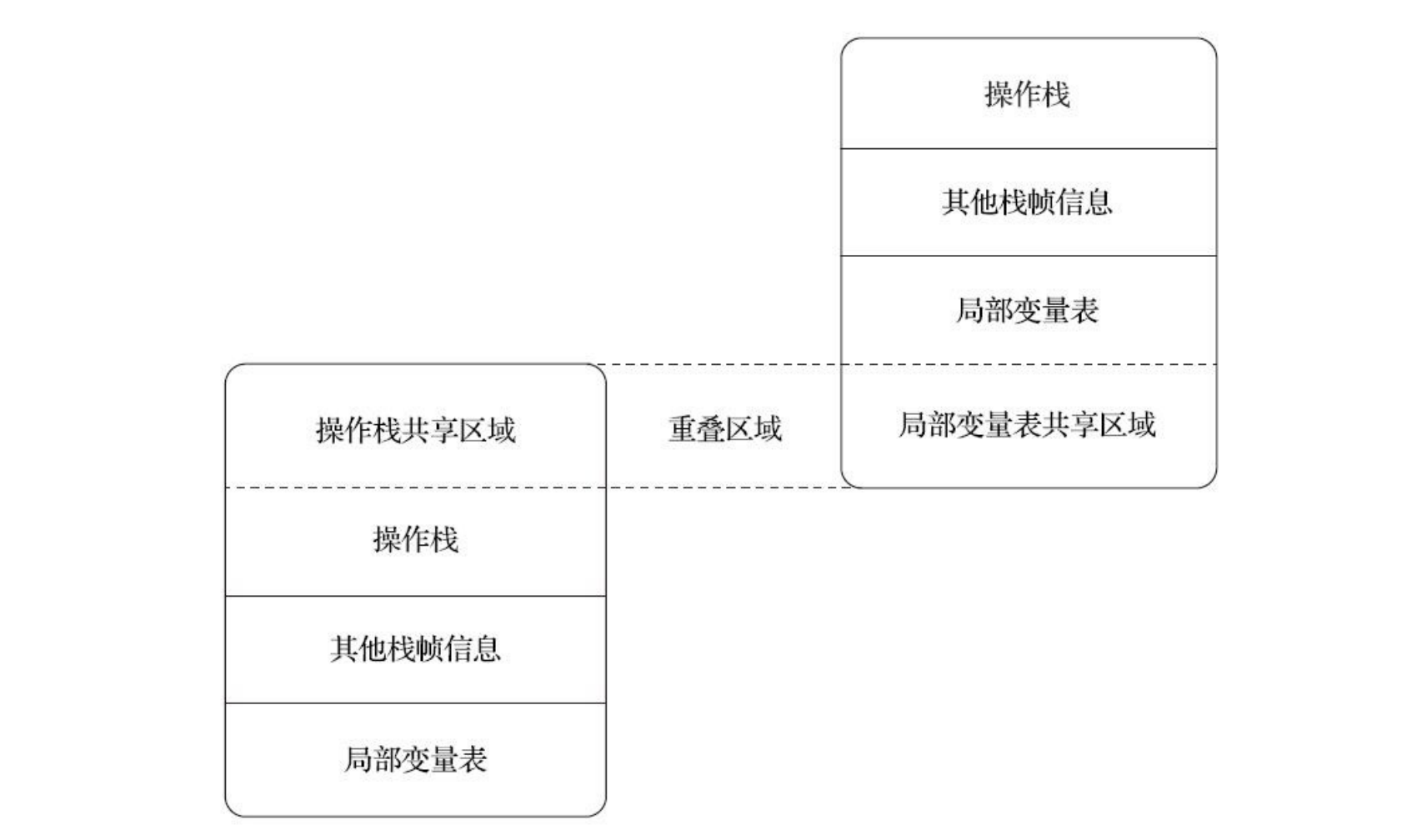
但是在大多虚拟机的实现里都会进行一些优化处理,令两个栈帧出现一部分重叠。让下面栈帧的部分操作数栈与上面栈帧的部分局部变量表重叠在一起,这样做不仅节约了一些空间,更重要的是在进行方法调用时就可以直接共用一部分数据,无须进行额外的参数复制传递了。
Java虚拟机的解释执行引擎被称为“基于栈的执行引擎”,里面的“栈”就是操作数栈。
动态连接 每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接(Dynamic Linking)。
Class文件的常量池中存有大量的符号引用,字节码中的方法调用指令就以常量池里指向方法的符号引用作为参数。
这些符号引用一部分会在类加载阶段或者第一次使用的时候就被转化为直接引用,这种转化被称为静态解析。 另外一部分将在每一次运行期间都转化为直接引用,这部分就称为动态连接。 方法返回地址 当一个方法开始执行后,只有两种方式退出这个方法。
第一种方式是执行引擎遇到 任意一个方法返回的字节码指令 ,这时候可能会有返回值传递给上层的方法调用者,这种退出方法的方式称为“正常调用完成”(Normal Method Invocation Completion)。
另外一种退出方式是在 方法执行的过程中遇到了异常 ,并且这个异常没有在方法体内得到妥善处理。这种退出方法的方式称为“异常调用完成(Abrupt Method Invocation Completion)”。一个方法使用异常完成出口的方式退出,是不会给它的上层调用者提供任何返回值的。
无论采用何种退出方式,在方法退出之后,都必须 返回到最初方法被调用时的位置 ,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层主调方法的执行状态。一般来说,方法正常退出时,主调方法的PC计数器的值就可以作为返回地址,栈帧中很可能会保存这个计数器。而方法异常退出时,返回地址是要通过异常处理器表来确定的,栈帧中就一般不会保存这部分信息。
方法退出的过程实际上等同于把当前栈帧出栈,因此退出时可能执行的操作有: 恢复上层方法的局部变量表和操作数栈,把返回值(如果有的话)压入调用者栈帧的操作数栈中,调整PC计数器的值以指向方法调用指令后面的一条指令 等。
方法调用 方法调用并不等同于方法中的代码被执行,方法调用阶段唯一的任务就是 确定被调用方法的版本 (即调用哪一个方法),暂时还未涉及方法内部的具体运行过程。在程序运行时,进行方法调用是最普遍、最频繁的操作之一。Class文件的编译过程中不包含传统程序语言编译的连接步骤, 一切方法调用在Class文件里面存储的都只是符号引用 ,而不是方法在实际运行时内存布局中的入口地址(也就是之前说的直接引用)。这个特性给Java带来了更强大的动态扩展能力,但也 使得Java方法调用过程变得相对复杂 ,某些调用需要在类加载期间,甚至到运行期间才能确定目标方法的直接引用。
解析调用 不同类型的方法,字节码指令集里设计了不同的指令。在Java虚拟机支持以下5条方法调用字节码指令,分别是:
invokestatic。用于调用静态方法。 invokespecial。用于调用实例构造器 <init>() 方法、私有方法和父类中的方法。 invokevirtual。用于调用所有的虚方法。 invokeinterface。用于调用接口方法,会在运行时再确定一个实现该接口的对象。 invokedynamic。先在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法。前面4条调用指令,分派逻辑都固化在Java虚拟机内部,而invokedynamic指令的分派逻辑是由用户设定的引导方法来决定的。 只要能被 invokestatic和invokespecial 指令调用的方法,都可以在解析阶段中确定唯一的调用版本,Java语言里符合这个条件的方法共有静态方法、私有方法、实例构造器、父类方法4种,再加上被final修饰的方法(尽管它使用invokevirtual指令调用),这5种方法调用会 在类加载的时候就可以把符号引用解析为该方法的直接引用 。这些方法统称为“非虚方法”(Non-Virtual Method),与之相反,其他方法就被称为“虚方法”(Virtual Method)。
在类加载的解析阶段,会将其中的一部分符号引用转化为直接引用,这种解析能够成立的前提是:方法在程序真正运行之前就有一个可确定的调用版本,并且这个方法的调用版本在运行期是不可改变的。换句话说,调用目标在程序代码写好、编译器进行编译那一刻就已经确定下来。这类方法的调用被称为解析(Resolution)。
静态分派调用 方法静态分派演示:
/**
* 方法静态分派演示
* @author zzm
*/
public class StaticDispatch {
static abstract class Human {
}
static class Man extends Human {
}
static class Woman extends Human {
}
public void sayHello ( Human guy ) {
System . out . println ( "hello,guy!" );
}
public void sayHello ( Man guy ) {
System . out . println ( "hello,gentleman!" );
}
public void sayHello ( Woman guy ) {
System . out . println ( "hello,lady!" );
}
public static void main ( String [] args ) {
Human man = new Man ();
Human woman = new Woman ();
StaticDispatch sr = new StaticDispatch ();
sr . sayHello ( man );
sr . sayHello ( woman );
}
}
// hello,guy
// hello,guy
把上面代码中的“Human”称为变量的 “静态类型”(Static Type) ,或者叫“外观类型”(Apparent Type),后面的“Man”则被称为变量的 “实际类型”(Actual Type) 或者叫“运行时类型”(Runtime Type)。
静态类型和实际类型在程序中都可能会发生变化,区别是静态类型的变化仅仅在使用时发生,变量本身的静态类型不会被改变,并且 最终的静态类型是在编译期可知的;而实际类型变化的结果在运行期才可确定 ,编译器在编译程序的时候并不知道一个对象的实际类型是什么。
例如:
// 实际类型变化
Human human = ( new Random ()). nextBoolean () ? new Man () : new Woman ();
// 静态类型变化
sr . sayHello (( Man ) human )
sr . sayHello (( Woman ) human )
代码中故意定义了两个静态类型相同,而实际类型不同的变量,但 虚拟机(或者准确地说是编译器)在重载时是通过参数的静态类型而不是实际类型作为判定依据的 。由于静态类型在编译期可知,所以在编译阶段,Javac编译器就根据参数的静态类型决定了会使用哪个重载版本,因此选择了sayHello(Human)作为调用目标,并把这个方法的符号引用写到main()方法里的两条 invokevirtual 指令的参数中。
所有依赖静态类型来决定方法执行版本的分派动作,都称为静态分派。静态分派的最典型应用表现就是方法重载。静态分派发生在编译阶段,因此确定静态分派的动作实际上不是由虚拟机来执行的。
需要注意Javac编译器虽然能确定出方法的重载版本,但在很多情况下这个重载版本并不是“唯一”的,往往只能确定一个“相对更合适的”版本。
以下举例可以看出这一点:
重载方法匹配优先级 public class Overload {
public static void sayHello ( Object arg ) {
System . out . println ( "hello Object" );
}
public static void sayHello ( int arg ) {
System . out . println ( "hello int" );
}
public static void sayHello ( long arg ) {
System . out . println ( "hello long" );
}
public static void sayHello ( Character arg ) {
System . out . println ( "hello Character" );
}
public static void sayHello ( char arg ) {
System . out . println ( "hello char" );
}
public static void sayHello ( char ... arg ) {
System . out . println ( "hello char ..." );
}
public static void sayHello ( Serializable arg ) {
System . out . println ( "hello Serializable" );
}
public static void main ( String [] args ) {
sayHello ( 'a' );
}
}
输出:
hello char
因为a是一个字符类型,如果注释掉sayHello(char arg)方法,那么输出的结果将是:
hello int
这里做了 一次自动类型转换 ,’a’除了可以代表一个字符串,还可以代表数字97(字符’a’的Unicode数值为十进制数字97),因此参数类型为int的重载也是合适的。继续注释掉sayHello(int arg)方法,那么输出的结果将是:
hello long
时发生了 两次自动类型转换 ,’a’转型为整数97之后,进一步转型为长整数97L,匹配了参数类型为long的重载。笔者在代码中没有写其他的类型如float、double等的重载,不过实际上自动转型还能继续发生多次,按照 char>int>long>float>double 的顺序转型进行匹配,但不会匹配到byte和short类型的重载,因为char到byte或short的转型是不安全的。
继续注释掉sayHello(long arg)方法,那么输出的结果将是:
hello Character
这里发生了 一次自动装箱 ,’a’被包装为了Character类型的对象。注释掉sayHello(Character arg)方法,那么输出的结果将是:
hello Serializable
是因为java.lang.Serializable是java.lang.Character类实现的一个接口,当自动装箱之后发现还是找不到装箱类,但是找到了装箱类所实现的接口类型,所以紧接着又发生一次自动转型。
继续注释掉sayHello(Serializable arg)方法,输出会变为:
hello Object
这时是char装箱后转型为父类了,如果有多个父类,那将在继承关系中从下往上开始搜索,越接上层的优先级越低。即使方法调用传入的参数值为null时,这个规则仍然适用。我们把sayHello(Objectarg)也注释掉,输出将会变为:
hello char …
7个重载方法已经被注释得只剩1个了,可见变长参数的重载优先级是最低的,这时候字符’a’被当作了一个char[]数组的元素。
动态分派 下Java语言里动态分派的实现过程,它与Java语言多态性的另外一个重要体现——重写(Override)有着很密切的关联。
/**
* 方法动态分派演示
* @author zzm
*/
public class DynamicDispatch {
static abstract class Human {
protected abstract void sayHello ();
}
static class Man extends Human {
@Override
protected void sayHello () {
System . out . println ( "man say hello" );
}
}
static class Woman extends Human {
@Override
protected void sayHello () {
System . out . println ( "woman say hello" );
}
}
public static void main ( String [] args ) {
Human man = new Man ();
Human woman = new Woman ();
man . sayHello ();
woman . sayHello ();
man = new Woman ();
man . sayHello ();
}
}
// man say hello
// woman say hello
// woman say hello
显然这里选择调用的方法版本是不可能再根据静态类型来决定的,因为静态类型同样都是Human的两个变量man和woman在调用sayHello()方法时产生了不同的行为,甚至变量man在两次调用中还执行了两个不同的方法。
上面代码编译的字节码:
public static void main(java.lang.String[]);
Code:
Stack=2, Locals=3, Args_size=1
0: new #16; //class org/fenixsoft/polymorphic/DynamicDispatch$Man
3: dup
4: invokespecial #18; //Method org/fenixsoft/polymorphic/Dynamic Dispatch$Man."<init>":()V
7: astore_1
8: new #19; //class org/fenixsoft/polymorphic/DynamicDispatch$Woman
11: dup
12: invokespecial #21; //Method org/fenixsoft/polymorphic/DynamicDispatch$Woman."<init>":()V
15: astore_2
16: aload_1
17: invokevirtual #22; //Method org/fenixsoft/polymorphic/Dynamic Dispatch$Human.sayHello:()V
20: aload_2
21: invokevirtual #22; //Method org/fenixsoft/polymorphic/Dynamic Dispatch$Human.sayHello:()V
24: new #19; //class org/fenixsoft/polymorphic/DynamicDispatch$Woman
27: dup
28: invokespecial #21; //Method org/fenixsoft/polymorphic/DynamicDispatch$Woman."<init>":()V
31: astore_1
32: aload_1
33: invokevirtual #22; //Method org/fenixsoft/polymorphic/Dynamic Dispatch$Human.sayHello:()V
36: return
16和20行的aload指令分别把刚刚创建的两个对象的引用压到栈顶,这两个对象是将要执行的 sayHello()方法的所有者,称为接收者(Receiver) ;17和21行是方法调用指令,这两条调用指令单从字节码角度来看,无论是指令(都是 invokevirtual )还是参数(都是常量池中第22项的常量,注释显示了这个常量是Human.sayHello()的符号引用)都完全一样,但是这两句指令最终执行的目标方法并不相同。
invokevirtual是如何确定调用方法版本、如何实现多态的?
1)找到操作数栈顶的第一个元素 所指向的对象的实际类型 ,记作C。
2)如果在类型C中找到与常量中的描述符和简单名称都相符的方法,则进行访问权限校验,如果通过则 返回这个方法的直接引用 ,查找过程结束;不通过则返回java.lang.IllegalAccessError异常。
3)否则,按照继承关系从下往上依次对C的各个父类进行第二步的搜索和验证过程。
4)如果始终没有找到合适的方法,则抛出java.lang.AbstractMethodError异常。
正是因为invokevirtual指令执行的第一步就是在运行期确定接收者的实际类型,所以两次调用中的invokevirtual指令并不是把常量池中方法的符号引用解析到直接引用上就结束了,还会根据方法接收者的实际类型来选择方法版本,这个过程就是Java语言中方法重写的本质。我们把这种 在运行期根据实际类型确定方法执行版本的分派过程称为动态分派 。
既然这种多态性的根源在于虚方法调用指令invokevirtual的执行逻辑,那自然我们得出的结论就只会对方法有效,对字段是无效的,因为字段不使用这条指令。事实上,在Java里面只有虚方法存在,字段永远不可能是虚的,换句话说,字段永远不参与多态,哪个类的方法访问某个名字的字段时,该 名字指的就是这个类能看到的那个字段。当子类声明了与父类同名的字段时,虽然在子类的内存中两个字段都会存在,但是子类的字段会遮蔽父类的同名字段。
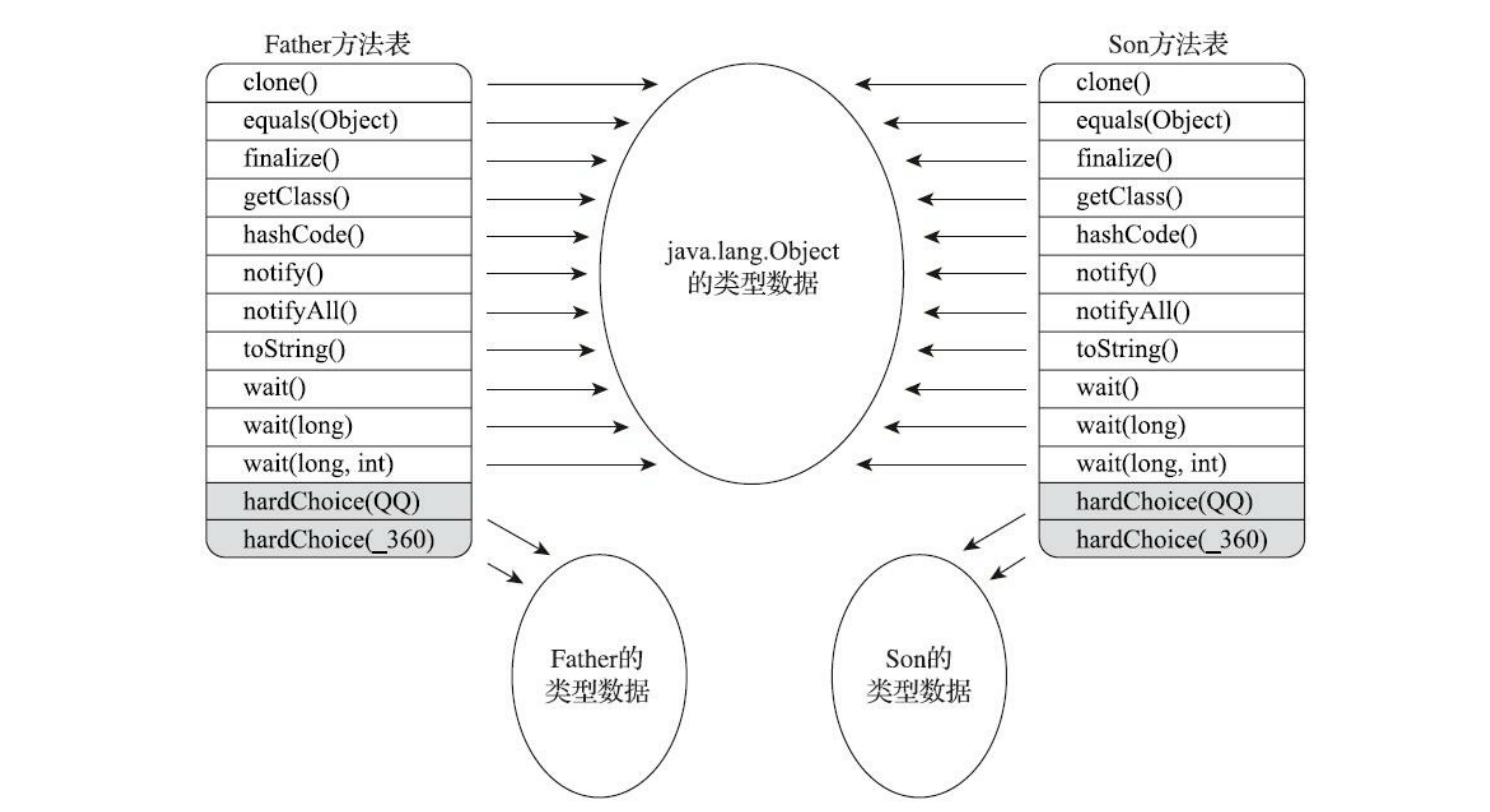
单分派和多分派 方法的接收者与方法的参数 统称为方法的 宗量 。
根据分派基于多少种宗量,可以将分派划分为单分派和多分派两种。单分派是根据一个宗量对目标方法进行选择,多分派则是根据多于一个宗量对目标方法进行选择。
/**
* 单分派、多分派演示
* @author zzm
*/
public class Dispatch {
static class QQ {}
static class _360 {}
public static class Father {
public void hardChoice ( QQ arg ) {
System . out . println ( "father choose qq" );
}
public void hardChoice ( _360 arg ) {
System . out . println ( "father choose 360" );
}
}
public static class Son extends Father {
@Override
public void hardChoice ( QQ arg ) {
System . out . println ( "son choose qq" );
}
@Override
public void hardChoice ( _360 arg ) {
System . out . println ( "son choose 360" );
}
}
public static void main ( String [] args ) {
Father father = new Father ();
Father son = new Son ();
father . hardChoice ( new _360 ());
son . hardChoice ( new QQ ());
}
}
在main()里调用了两次hardChoice()方法,这两次hardChoice()方法的选择结果在程序输出中已经显示得很清楚了。
我们关注的首先是 编译阶段 中编译器的选择过程,也就是静态分派的过程。这时候 选择目标方法的依据有两点 :一是静态类型是Father还是Son,二是方法参数是QQ还是360。这次选择结果的最终产物是产生了两条invokevirtual指令,Son的静态类型也是Father,这两条调用指令的参数分别为常量池中指向 Father::hardChoice(360) 及 Father::hardChoice(QQ) 方法的符号引用。因为是根据两个宗量进行选择,所以Java语言的静态分派属于多分派类型。
再看看运行阶段中虚拟机的选择,也就是动态分派的过程。在执行“son.hardChoice(new QQ())”这行代码时,更准确地说,是在执行这行代码所对应的invokevirtual指令时,由于 编译期已经决定目标方法的签名必须为hardChoice(QQ) ,虚拟机此时不会关心传递过来的参数“QQ”到底是“腾讯QQ”还是“奇瑞QQ”,因为 这时候参数的静态类型、实际类型都对方法的选择不会构成任何影响 , 唯一 可以影响虚拟机选择的因素只有该方法的接受者的实际类型是Father还是Son,故最终调用到了实际类型Son类的QQ方法里。因为 只有一个宗量作为选择依据 ,所以Java语言的动态分派属于单分派类型。
JVM动态分派实现 动态分派是执行非常频繁的动作,而且动态分派的方法版本选择过程需要运行时在接收者类型的方法元数据中搜索合适的目标方法,因此,Java虚拟机实现基于执行性能的考虑,真正运行时一般不会如此频繁地去反复搜索类型元数据。面对这种情况,一种基础而且常见的优化手段是为类型在方法区中建立一个 虚方法表 (Virtual Method Table,也称为vtable,与此对应的,在invokeinterface执行时也会用到接口方法表——Interface Method Table,简称itable),使用 虚方法表索引来代替元数据查找以提高性能 。
虚方法表中存放着各个方法的实际入口地址。如果某个方法在子类中没有被重写,那子类的虚方法表中的地址入口和父类相同方法的地址入口是一致的,都指向父类的实现入口。如果子类中重写了这个方法,子类虚方法表中的地址也会被替换为指向子类实现版本的入口地址。
为了程序实现方便,具有相同签名的方法,在父类、子类的虚方法表中都应当具有一样的索引序号,这样当类型变换时,仅需要变更查找的虚方法表,就可以从不同的虚方法表中按索引转换出所需的入口地址。虚方法表一般在类加载的连接阶段进行初始化,准备了类的变量初始值后,虚拟机会把该类的虚方法表也一同初始化完毕。
动态类型语言 动态类型语言 的关键特征是它的 类型检查的主体过程是在运行期而不是编译期进行的 ,满足这个特征的语言有很多,常用的包括:APL、Clojure、Erlang、Groovy、JavaScript、Lisp、Lua、PHP、Prolog、Python、Ruby、Smalltalk、Tcl,等等。那相对地,在编译期就进行类型检查过程的语言,譬如C++和Java等就是最常用的静态类型语言。
动态语言面临的难题 前面已经提到过,方法的符号引用在编译时产生,而动态类型语言只有在运行期才能确定方法的接收者。这样,在Java虚拟机上实现的动态类型语言就不得不使用“曲线救国”的方式(如编译时留个占位符类型,运行时动态生成字节码实现具体类型到占位符类型的适配)来实现,但这样势必会让动态类型语言实现的复杂度增加,也会带来额外的性能和内存开销。内存开销是很显而易见的,方法调用产生的那一大堆的动态类就摆在那里。而其中最严重的 性能瓶颈是在于动态类型方法调用时,由于无法确定调用对象的静态类型,而导致的方法内联无法有效进行 。
例如:
var arrays = { "abc" , new ObjectX (), 123 , Dog , Cat , Car ..}
for ( item in arrays ){
item . sayHello ();
}
在动态类型语言下这样的代码是没有问题,但由于在运行时arrays中的元素可以是任意类型,即使它们的类型中都有sayHello()方法,也肯定无法在编译优化的时候就确定具体sayHello()的代码在哪里,编译器只能不停编译它所遇见的每一个sayHello()方法,并缓存起来供执行时选择、调用和内联,如果arrays数组中不同类型的对象很多,就势必会对内联缓存产生很大的压力,缓存的大小总是有限的,类型信息的不确定性导致了缓存内容不断被失效和更新,先前优化过的方法也可能被不断替换而无法重复使用。
这便是JDK 7时JSR-292提案中invokedynamic指令以及java.lang.invoke包出现的技术背景。
方法句柄 JDK 7时新加入的java.lang.invoke包是JSR 292的一个重要组成部分,这个包的主要目的是在之前单纯依靠符号引用来确定调用的目标方法这条路之外,提供一种新的动态确定目标方法的机制,称为“方法句柄”(Method Handle)。
在拥有方法句柄之后,Java语言也可以拥有类似于函数指针或者委托的方法别名这样的工具了。
/**
* JSR 292 MethodHandle基础用法演示
* @author zzm
*/
public class MethodHandleTest {
static class ClassA {
public void println ( String s ) {
System . out . println ( s );
}
}
public static void main ( String [] args ) throws Throwable {
Object obj = System . currentTimeMillis () % 2 == 0 ? System . out : new ClassA ();
// 无论obj最终是哪个实现类,下面这句都能正确调用到println方法。
getPrintlnMH ( obj ). invokeExact ( "icyfenix" );
}
private static MethodHandle getPrintlnMH ( Object reveiver ) throws Throwable {
/**
* MethodType:代表“方法类型”,包含了方法的返回值(methodType()的第一个参数)和
* 具体参数(methodType()第二个及以后的参数)。
*/
MethodType mt = MethodType . methodType ( void . class , String . class );
/**
* lookup()方法来自于MethodHandles.lookup,这句的作用是在指定类中查找符合
* 给定的方法名称、方法类型,并且符合调用权限的方法句柄。
* 因为这里调用的是一个虚方法,按照Java语言的规则,方法第一个参数是隐式的,
* 代表该方法的接收者,也即this指向的对象,这个参数以前是放在参数列表中进行
* 传递,现在提供了bindTo()方法来完成这件事情。
*/
return lookup (). findVirtual ( reveiver . getClass (), "println" , mt ). bindTo ( reveiver );
}
}
方法getPrintlnMH()中实际上是模拟了invokevirtual指令的执行过程,只不过它的分派逻辑并非固化在Class文件的字节码上,而是通过一个由用户设计的Java方法来实现。而这个方法本身的返回值(MethodHandle对象),可以视为对最终调用方法的一个“引用”。
仅站在Java语言的角度看,MethodHandle在使用方法和效果上与Reflection有众多相似之处。不过,它们也有以下这些区别:
Reflection和MethodHandle机制本质上都是在模拟方法调用,但是Reflection是在模拟Java代码层次的方法调用,而MethodHandle是在模拟字节码层次的方法调用。在MethodHandles.Lookup上的3个方法findStatic()、findVirtual()、findSpecial()正是为了对应于invokestatic、invokevirtual(以及invokeinterface)和invokespecial这几条字节码指令的执行权限校验行为,而这些底层细节在使用Reflection API时是不需要关心的。 Reflection中的java.lang.reflect.Method对象远比MethodHandle机制中的java.lang.invoke.MethodHandle对象所包含的信息来得多。前者是方法在Java端的全面映像,包含了方法的签名、描述符以及方法属性表中各种属性的Java端表示方式,还包含执行权限等的运行期信息。而后者仅包含执行该方法的相关信息。用开发人员通俗的话来讲,Reflection是重量级,而MethodHandle是轻量级。 由于MethodHandle是对字节码的方法指令调用的模拟,那理论上虚拟机在这方面做的各种优化(如方法内联),在MethodHandle上也应当可以采用类似思路去支持(但目前实现还在继续完善中),而通过反射去调用方法则几乎不可能直接去实施各类调用点优化措施。MethodHandle与Reflection除了上面列举的区别外,最关键的一点还在于去掉前面讨论施加的前提“仅站在Java语言的角度看”之后:Reflection API的设计目标是只为Java语言服务的,而MethodHandle则设计为可服务于所有Java虚拟机之上的语言,其中也包括了Java语言而已,而且Java在这里并不是主角。 invokedynamic 某种意义上可以说 invokedynamic 指令与MethodHandle机制的作用是一样的,都是为了解决原有4条“invoke*”指令方法分派规则完全固化在虚拟机之中的问题,把如何查找目标方法的决定权从虚拟机转嫁到具体用户代码之中,让用户(广义的用户,包含其他程序语言的设计者)有更高的自由度。而且,它们两者的思路也是可类比的,都是为了达成同一个目的,只是一个用上层代码和API来实现,另一个用字节码和Class中其他属性、常量来完成。
每天都在使用try-catch,但是没有对其设计理念和工作机制做一个比较详细的了解,现稍微总结下。
JVM 上的 try-catch 机制的实现是基于 Java 字节码层面的一些特殊指令和数据结构来完成的。
Java 中的异常是指程序运行时发生的意外情况,它会中断正常的指令流。Java 将异常分为两大类:
检查型异常(Checked Exception):必须显式捕获或声明抛出(如 IOException) 非检查型异常(Unchecked Exception):包括 RuntimeException 及其子类(如 NullPointerException) try-catch 机制提供了一种结构化的方式来捕获并处理可能发生的异常,防止程序因未处理的异常而突然终止,斌且在异常发生后执行清理或恢复操作。
实现原理 大体流程 当异常被抛出时,JVM 的执行流程如下:
创建异常对象(调用异常类的构造函数) 查找当前方法的异常处理表:如果找到匹配的 catch 块,跳转到对应的处理代码 如果没有找到,弹出当前栈帧,回到调用者方法 重复步骤2,直到找到匹配的 catch 块或到达线程栈底(此时线程终止) 1. 异常表 (Exception Table) 这是 JVM 实现 try-catch 机制的关键。在 Java 字节码中,每个方法都会有一个或多个异常表条目。每个异常表条目通常包含以下信息:
start_pc (start program counter): try 块开始的字节码指令偏移量。end_pc (end program counter): try 块结束的字节码指令偏移量(不包含此指令)。handler_pc (handler program counter): catch 块开始的字节码指令偏移量。catch_type (catch type): 捕获的异常类型(例如 java.lang.ArithmeticException)。如果为 0,则表示捕获所有 Throwable 异常(类似于 finally 块或泛型异常捕获)。当 Java 编译器将 .java 文件编译成 .class 文件时,它会为 try-catch 结构生成相应的字节码和异常表条目。
2. 异常的抛出 (Throwing an Exception) 当程序执行到 try 块内,如果发生异常(例如除零错误、空指针等),或者代码中显式地使用 throw 语句抛出异常时,JVM 会根据抛出的异常类型创建一个相应的异常对象 (例如 ArithmeticException)。
然后从当前方法的异常表中,从下往上(或者从内到外,取决于异常表的组织方式)查找与当前执行位置和异常类型匹配的异常表条目。异常发生的 pc 值必须在 start_pc 和 end_pc 之间。抛出的异常类型必须是 catch_type 指定的异常类型或其子类。
如果找到了匹配的 catch 块,JVM 会将程序计数器(pc)设置为该 catch 块的 handler_pc,并将其异常对象压入操作数栈的顶部。然后,控制流将转移到 catch 块的代码继续执行。
如果当前方法没有找到匹配的 catch 块,JVM 会将异常沿着调用栈向上抛出,直到找到一个能够处理该异常的方法。如果一直抛到 main 方法,仍然没有被捕获,那么 JVM 会终止程序的执行,并打印异常的堆栈信息。
3. finally 块的实现 finally 块是用来确保其中的代码无论是否发生异常都会执行。
在编译阶段,编译器会将 finally 块的代码 复制到所有可能的出口点 ,包括 try 块正常结束、try 块中发生异常被 catch 块处理后、以及 try 或 catch 块中使用了 return、break 或 continue 等语句提前退出时。
如果 finally 块是在一个异常被捕获后执行的,并且 finally 块自身没有抛出新的异常,那么原来的异常会重新抛出(如果它没有被 catch 块完全处理)。如果 finally 块自身抛出了新的异常,则会覆盖掉之前的异常。
4. try-with-resources 的实现 try-with-resources 是 Java 7 引入的语法糖,用于自动管理资源。在编译时,它会被转换成包含隐式 try-finally 结构的字节码,确保资源在使用完毕后(无论是否发生异常)都被正确关闭。这通常通过调用资源的 close() 方法来实现。
使用建议 捕获特定异常:避免捕获过于宽泛的 Exception,尽量捕获具体的异常类型 不要忽略异常:空的 catch 块是糟糕的做法,至少应该记录日志 合理使用 finally:用于资源释放等必须执行的操作 避免在 finally 中抛出异常:这会掩盖原始异常 考虑异常链:抛出新的异常时,保留原始异常信息(使用带 cause 的构造函数) 合理使用自定义异常:为特定业务场景创建有意义的异常类型 性能方面:异常实例化开销:创建异常对象比普通对象开销大(需要填充栈轨迹)* 控制流改变:异常处理会导致控制流跳转,比正常的条件判断慢 不要用异常进行常规流程控制 对于可预见的错误情况,优先使用条件判断 只在真正异常的情况下使用 try-catch 不同线程的try-catch Android开发中,经常有第三方依赖库的设计问题,单独开辟另一个线程,导致报错直接在其内部抛出,没有给到外部调用方进行处理,导致程序崩溃。
不同线程之间不能直接使用 try-catch 块来捕获另一个线程中抛出的异常。
每个线程都有自己的 独立的执行栈 。当一个线程抛出异常时,JVM 会沿着该线程的调用栈向上查找匹配的 catch 块。如果当前线程的调用栈中没有找到能够处理该异常的 catch 块,该线程就会终止。
为什么不能直接捕获?
想象一下,如果一个线程可以捕获另一个线程的异常,那么这会带来很多复杂性和不确定性:
时间同步问题: 哪个线程应该先捕获?如果多个线程都尝试捕获同一个异常,谁会成功?状态不一致: 一个线程抛出异常可能意味着它的内部状态已经损坏。如果另一个线程捕获了这个异常并继续执行,可能会导致数据不一致或其他不可预测的行为。程序的复杂性: 线程间的异常捕获会使程序的控制流变得非常复杂和难以理解。如何在多线程环境中处理异常?
尽管不能直接跨线程 try-catch,但 Java 提供了多种机制来在多线程环境中处理异常:
在线程内部使用 try-catch: 这是最常见和推荐的做法。每个线程都应该在其 run() 方法内部(或 Callable 的 call() 方法内部)使用 try-catch 块来处理它自己可能抛出的异常。这样可以确保即使线程内部发生错误,也不会导致整个应用程序崩溃,并且可以在线程内部进行适当的错误日志记录或恢复操作。
class MyRunnable implements Runnable {
@Override
public void run () {
try {
// 线程内部的业务逻辑,可能抛出异常
int result = 10 / 0 ; // 抛出 ArithmeticException
System . out . println ( "Result: " + result );
} catch ( ArithmeticException e ) {
System . err . println ( "线程内部捕获到 ArithmeticException: " + e . getMessage ());
// 进行错误日志记录、清理操作等
} catch ( Exception e ) {
System . err . println ( "线程内部捕获到通用异常: " + e . getMessage ());
}
}
}
public class Main {
public static void main ( String [] args ) {
Thread thread = new Thread ( new MyRunnable ());
thread . start ();
// main 线程不会捕获 MyRunnable 线程内部的异常
System . out . println ( "Main thread finished." );
}
}
Thread.UncaughtExceptionHandler:UncaughtExceptionHandler。你可以为每个线程或为所有线程设置一个默认的未捕获异常处理器。这对于日志记录未预期的异常非常有用。
class MyRunnable implements Runnable {
@Override
public void run () {
// 这里没有 try-catch
int result = 10 / 0 ; // 抛出 ArithmeticException
System . out . println ( "Result: " + result );
}
}
public class Main {
public static void main ( String [] args ) {
Thread thread = new Thread ( new MyRunnable ());
// 为特定线程设置未捕获异常处理器
thread . setUncaughtExceptionHandler ( new Thread . UncaughtExceptionHandler () {
@Override
public void uncaughtException ( Thread t , Throwable e ) {
System . err . println ( "线程 " + t . getName () + " 发生了未捕获异常: " + e . getMessage ());
e . printStackTrace (); // 打印堆栈信息
}
});
// 也可以设置全局的默认未捕获异常处理器
// Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
// @Override
// public void uncaughtException(Thread t, Throwable e) {
// System.err.println("全局捕获到线程 " + t.getName() + " 的未捕获异常: " + e.getMessage());
// }
// });
thread . start ();
System . out . println ( "Main thread finished." );
}
}
使用 Callable 和 Future: 如果你使用 ExecutorService 来管理线程,并且希望从子线程中获取结果或捕获异常,可以使用 Callable 接口而不是 Runnable。Callable 的 call() 方法可以抛出检查异常,并且它的结果(包括异常)可以通过 Future 对象来获取。
import java.util.concurrent.* ;
class MyCallable implements Callable < String > {
@Override
public String call () throws Exception {
// 线程内部的业务逻辑
if ( Math . random () > 0.5 ) {
throw new RuntimeException ( "随机抛出的异常!" );
}
return "任务完成" ;
}
}
public class Main {
public static void main ( String [] args ) {
ExecutorService executor = Executors . newSingleThreadExecutor ();
Future < String > future = executor . submit ( new MyCallable ());
try {
String result = future . get (); // 获取任务结果,如果发生异常,会抛出 ExecutionException
System . out . println ( "任务结果: " + result );
} catch ( InterruptedException e ) {
Thread . currentThread (). interrupt (); // 恢复中断状态
System . err . println ( "主线程被中断: " + e . getMessage ());
} catch ( ExecutionException e ) {
System . err . println ( "任务执行异常: " + e . getCause (). getMessage ()); // 获取实际的异常
e . getCause (). printStackTrace ();
} finally {
executor . shutdown ();
}
}
}
高内聚&低耦合 这是最常见的一个概念,也是各个设计模式的最基本的原则。
高内聚 模块内部的各个类,要实现紧密连接,功能上高度的相互配合。按照内聚程度从低到高主要有以下几种:
偶然内聚:一个模块内的各处理元素之间没有任何联系,只是偶然地被凑到一起。这种模块也称为巧合内聚,内聚程度最低。 逻辑内聚:这种模块把几种相关的功能组合在一起, 每次被调用时,由传送给模块参数来确定该模块应完成哪一种功能 。 时间内聚:把需要同时执行的动作组合在一起形成的模块称为时间内聚模块。 过程内聚:构件或者操作的组合方式是,允许在调用前面的构件或操作之后,马上调用后面的构件或操作,即使两者之间没有数据进行传递。简单的说就是如果一个模块内的处理元素是相关的,而且必须以特定次序执行则称为过程内聚。例如某要完成登录的功能,前一个功能判断网络状态,后一个执行登录操作,显然是按照特 定次序执行的。 通信内聚:指模块内所有处理元素都在同一个数据结构上操作或所有处理功能都通过公用数据而发生关联(有时称之为信息内聚)。即指模块内各个组成部分都使用相同的数据结构或产生相同的数据结构。 顺序内聚:一个模块中各个处理元素和同一个功能密切相关,而且这些处理必须顺序执行,通常前一个处理元素的输出时后一个处理元素的输入。例如某要完成获取订单信息的功能,前一个功能获取用户信息,后一个执行计算均价操作,显然该模块内两部分紧密关联。 顺序内聚的内聚度比较高,但缺点是不如功能内聚易于维护。 功能内聚:模块内所有元素的各个组成部分全部都为完成同一个功能而存在,共同完成一个单一的功能,模块已不可再分。即模块仅包括为完成某个功能所必须的所有成分,这些成分紧密联系、缺一不可。 低耦合 耦合,即模块间的关联程度,模块间的耦合度是指模块之间的依赖关系,包括控制关系、调用关系、数据传递关系。模块间联系越多,其耦合性越强,同时表明其独立性越差。
按照耦合程度从低到高排布如下:
非直接耦合:两个模块之间没有直接关系,它们之间的联系完全是通过主模块的控制和调用来实现的。耦合度最弱,模块独立性最强。 数据耦合:调用模块和被调用模块之间只传递简单的数据项参数。相当于高级语言中的值传递。 标记耦合:调用模块和被调用模块之间传递数据结构而不是简单数据,同时也称作特征耦合。表就和的模块间传递的不是简单变量,而是像高级语言中的数据名、记录名和文件名等数据结果,这些名字即为标记,其实传递的是地址。 控制耦合:模块之间传递的不是数据信息,而是控制信息例如标志、开关量等,一个模块控制了另一个模块的功能。 外部耦合:一组模块都访问同一全局简单变量,而且不通过参数表传递该全局变量的信息,则称之为外部耦合。 公共耦合:一组模块都访问同一个全局数据结构,则称之为公共耦合。公共数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。如果模块只是向公共数据环境输入数据,或是只从公共数据环境取出数据,这属于比较松散的公共耦合;如果模块既向公共数据环境输入数据又从公共数据环境取出数据,这属于较紧密的公共耦合。公共耦合会引起以下问题:无法控制各个模块对公共数据的存取,严重影响了软件模块的可靠性和适应性。 使软件的可维护性变差。若一个模块修改了公共数据,则会影响相关模块。 降低了软件的可理解性。不容易清楚知道哪些数据被哪些模块所共享,排错困难。 一般地,仅当模块间共享的数据很多且通过参数传递很不方便时,才使用公共耦合。
内容耦合:一个模块直接访问另一模块的内容,则称这两个模块为内容耦合。若在程序中出现下列情况之一,则说明两个模块之间发生了内容耦合:一个模块直接访问另一个模块的内部数据。 一个模块不通过正常入口而直接转入到另一个模块的内部。 两个模块有一部分代码重叠(该部分代码具有一定的独立功能)。 一个模块有多个入口。 内容耦合可能在汇编语言中出现。大多数高级语言都已设计成不允许出现内容耦合。这种耦合的耦合性最强,模块独立性最弱。
六大设计原则 单一职责原则 定义:就一个类而言,应该仅有一个引起它变化的原因。 开放封闭原则 定义:类、模块、函数等应该是可以拓展的,但是不可修改。 里氏替换原则 定义:所有引用基类(父类)的地方必须能透明地使用其子类的对象。由于使用基类对象的地方都可以使用子类对象,因此在程序中尽量使用基类类型来对对象进行定义,而在运行时再确定其子类类型,用子类对象来替换父类对象。子类的所有方法必须在父类中声明,或子类必须实现父类中声明的所有方法。 依赖倒置原则 定义:高层模块不应该依赖低层模块,两者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。模块间的依赖通过抽象发生,实现类之间不发生直接依赖关系,其依赖关系是通过接口或者抽象类产生的。如果类与类直接依赖细节,那么就会直接耦合。 迪米特原则 定义:一个软件实体应当尽可能少地与其他实体发生相互作用。简言之,就是通过引入一个合理的第三者来降低现有对象之间的耦合度。 接口隔离原则 定义:一个类对另一个类的依赖应该建立在最小的接口上。建立单一接口,不要建立庞大臃肿的接口;尽量细化接口,接口中的方法尽量少。 创建型设计模式 单例模式 一、饿汉单例模式,实例随类初始化一起加载,无线程安全问题。特点是类加载慢,访问速度快。如果未使用,就会有内存浪费。
public class Singleton {
private static Singleton instance = new Singleton ();
private Singleton () {
}
public static Singleton getInstance () {
return instance ;
}
}
二、懒汉线程安全模式,保证线程安全,需要时才进行对象实例化,但是每次获取实例都需要进行同步,也会增大开销。
public class Singleton {
private static Singleton instance ;
private Singleton () {
}
public static synchronized Singleton getinstance () {
if ( instance == null ) {
instance = new Singleton ();
}
return instance ;
}
}
三、静态内部单例模式,只有第一次调用getinstance方法时才会加载holder类,初始化instance。
public class Singleton {
private Singleton () {
}
public static Singleton getInstance () {
return SingletonHolder . sInstance ;
}
private static class SingletonHolder {
private static final Singleton sInstance = new Singleton ();
}
}
四、枚举单例,默认线程安全。
public enum Singleton {
INSTANCE ;
public void doSomeThing () {
}
}
杜绝反序列化生成另一个实例,可以将readResolve()返回值设为singleton对象。
使用场景 工具类 项目共享全局资源 实现I/O或者数据库等资源的操作 工厂模式 简单工厂模式,用来说明工厂方法模式。
Factory:工厂类,这是简单工厂模式的核心,它负责实现创建所有实例的内部逻辑。工厂类的创建产品类的方法可以被外界直接调用,创建所需的产品对象。 IProduct:抽象产品类,这是简单工厂模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。 Product:具体产品类,这是简单工厂模式的创建目标。 由工厂类,根据使用者的参数来决定创建哪一个产品实现类: public class ComputerFactory {
public static Computer createComputer ( String type ) {
Computer mComputer = null ;
switch ( type ) {
case "lenovo" :
mComputer = new LenovoComputer ();
break ;
case "hp" :
mComputer = new HpComputer ();
break ;
case "asus" :
mComputer = new AsusComputer ();
break ;
}
return mComputer ;
}
}
缺点,每次需要新增一个产品实现类时,都需要去修改工厂类里的方法。
工厂方法模式 ConcreateFactory类里通过反射来创建对应的产品类,具体创建哪一个由调用方去传入Class来确定。
public class GDComputerFactor extends ComputerFactory {
@Override
public < T extends Computer > T createComputer ( Class < T > clz ) {
Computer computer = null ;
String classname = clz . getName ();
try {
//通过反射来生产不同厂家的计算机
computer = ( Computer ) Class . forName ( classname ). newInstance ();
} catch ( Exception e ) {
e . printStackTrace ();
}
return ( T ) computer ;
}
}
建造者模式 使用场景:
当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时。 相同的方法,不同的执行顺序,产生不同的事件结果时。 多个部件或零件都可以被装配到一个对象中,但是产生的运行结果又不相同时。 产品类非常复杂,或者产品类中的调用顺序不同而产生了不同的效能。 在创建一些复杂的对象时,这些对象的内部组成构件间的建造顺序是稳定的,但是对象的内部组成构件面临着复杂的变化。 核心为Builder实现类,里面由Director导演类来调用来确定建造类的参数,最后调用create()创建一个对象。这个过程对外部不可见。
public class MoonComputerBuilder extends Builder {
private Computer mComputer = new Computer ();
@Override
public void buildCpu ( String cpu ) {
mComputer . setmCpu ( cpu );
}
@Override
public void buildMainboard ( String mainboard ) {
mComputer . setmMainboard ( mainboard );
}
@Override
public void buildRam ( String ram ) {
mComputer . setmRam ( ram );
}
@Override
public Computer create () {
return mComputer ;
}
}
优点:
使用建造者模式可以使客户端不必知道产品内部组成的细节。具体的建造者类之间是相互独立的,容易扩展。由于具体的建造者是独立的,因此可以对建造过程逐步细化,而不对其他的模块产生任何影响。
缺点:
产生多余的Build对象以及导演类。
结构型设计模式 代理模式 在代理模式中,存在三个角色:
抽象主题(Subject):定义了真实主题和代理主题的公共接口,这样在任何使用真实主题的地方都可以使用代理主题。 真实主题(RealSubject):是实际需要被代理的对象,它定义了具体的业务逻辑。 代理主题(Proxy):持有对真实主题的引用 ,并可以在调用真实主题的方法前后添加额外的逻辑。 示例代码: interface Service {
void doService ();
}
class RealService implements Service {
@Override
public void doService () {
System . out . println ( "执行真实服务" );
}
}
class StaticProxy implements Service {
private Service realService ;
public StaticProxy ( Service realService ) {
this . realService = realService ;
}
@Override
public void doService () {
System . out . println ( "在执行服务前的额外操作" );
realService . doService ();
System . out . println ( "在执行服务后的额外操作" );
}
}
public class StaticProxyDemo {
public static void main ( String [] args ) {
Service realService = new RealService ();
Service proxy = new StaticProxy ( realService );
proxy . doService ();
}
}
在上述代码中:
定义了一个Service接口,RealService类实现了该接口。 StaticProxy类也实现了Service接口,作为静态代理类。它持有一个Service类型的对象realService,在doService方法中可以在调用真实对象的方法前后添加额外的操作。 在main方法中创建了真实服务对象,并将其传递给代理对象,然后调用代理对象的方法。 动态代理 上面是静态代理,即在编译的时候,代理类的class文件就确定了。动态代理则是在运行时通过反射来动态生成代理类对象。Java 提供了动态的代理接口 InvocationHandler,实现该接口需要重写 invoke() 方法。
object DynamixProxyDemo {
interface IShop {
fun buy ( p : Int )
}
class RealShop : IShop {
override fun buy ( number : Int ) {
Log . i ( GLOBAL_TAG , "DynamicProxy RealShop: BUY $number HAT!" )
}
}
class DynamicShopProxy ( private val shop : IShop ) : InvocationHandler {
override fun invoke ( proxy : Any ?, method : Method ?, args : Array < out Any >?) =
method ?. invoke ( shop , args ?. get ( 0 ) as Int )
}
fun entrance () {
val realShop = RealShop ()
val shopProxy : IShop = Proxy . newProxyInstance (
realShop . javaClass . classLoader ,
Array ( 1 ) { IShop :: class . java },
DynamicShopProxy ( realShop )
) as IShop
shopProxy . buy ( 5 )
}
}
通过Proxy.newProxyInstance来生成动态代理类,强转调用disomething方法,会调用到DynamicProxyHandler的invoke方法。需要注意参数传递,有参无参,类型转换。
使用场景和优点
远程代理:为一个对象在不同的地址空间提供局部代表,这样系统可以将 Server 部分的实现隐藏。 虚拟代理:使用一个代理对象表示一个十分耗费资源的对象并在真正需要时才创建。 安全代理:用来控制真实对象访问时的权限。一般用于真实对象有不同的访问权限时。 智能指引:当调用真实的对象时,代理处理另外一些事,比如计算真实对象的引用计数,当该对象没有引用时,可以自动释放它;或者访问一个实际对象时,检查是否已经能够锁定它,以确保其他对象不能改变它。 代理模式的优点
真实主题类就是实现实际的业务逻辑,不用关心其他非本职的工作。 真实主题类随时都会发生变化;但是因为它实现了公共的接口,所以代理类可以不做任何修改就能够使用。 装饰模式 大体和代理模式类似,但是装饰者在调用实现类的时候,可以插入自己实现的其他方法。
Component:抽象组件,可以是接口或是抽象类,被装饰的最原始的对象。 ConcreteComponent:组件具体实现类。Component的具体实现类,被装饰的具体对象。 Decorator:抽象装饰者,从外类来拓展Component类的功能,但对于Component来说无须知道Decorator的存在。在它的属性中必然有一个private变量指向Component抽象组件。 ConcreteDecorator:装饰者的具体实现类。 抽象装饰者:
public abstract class Master extends Swordsman {
private Swordsman mSwordsman ;
public Master ( Swordsman mSwordsman ) {
this . mSwordsman = mSwordsman ;
}
@override
public void attackMagic () {
mSwordsman . attackMagic ();
}
}
想扩展组件实现类的装饰者:
public class HongQiGong extends Master {
public HongQiGong ( Swordsman mSwordsman ) {
super ( mSwordsman );
}
public void teachAttackMagic () {
System . out . println ( "洪七公教授打狗棒法" );
System . out . println ( "杨过使用打狗棒法" );
}
@override
public void attackMagic () {
super . attackMagic ();
teachAttackMagic ();
}
}
优点:
通过组合而非继承的方式,动态地扩展一个对象的功能,在运行时选择不同的装饰器,从而实现不同的行为。 有效避免了使用继承的方式扩展对象功能而带来的灵活性差、子类无限制扩张的问题。 具体组件类与具体装饰类可以独立变化,用户可以根据需要增加新的具体组件类和具体装饰类,在使用时再对其进行组合,原有代码无须改变,符合“开放封闭原则”。 缺点:
因为所有对象均继承于Component,所以如果Component内部结构发生改变,则不可避免地影响所有子类(装饰者和被装饰者)。如果基类改变,则势必影响对象的内部。 比继承更加灵活机动的特性,也同时意味着装饰模式比继承更加易于出错,排错也很困难。对于多次装饰的对象,调试时寻找错误可能需要逐级排查,较为烦琐。所以,只在必要的时候使用装饰模式。 装饰层数不能过多,否则会影响效率。 Kotlin的扩展函数 是一种更为方便的实现方式。从语言层面,生成后缀加Kt的Java类,里面生成对应的static函数。
外观模式 Facade:外观类,知道哪些子系统类负责处理请求,将客户端的请求代理给适当的子系统对象。 Subsystem:子系统类,可以有一个或者多个子系统。实现子系统的功能,处理外观类指派的任务,注意子系统类不含有外观类的引用。 实际上就是对其他类的封装,多次调用综合成一个方法。
/**
* 外观类张无忌
*/
public class ZhangWuji {
private JingMai jingMai ;
private ZhaoShi zhaoShi ;
private NeiGong neiGong ;
public ZhangWuJi () {
jingMai = new JingMai ();
zhaoShi = new ZhaoShi ();
neiGong = new NeiGong ();
}
// 使用乾坤大挪移
public void Qiankun () {
jingMai . jingmai (); //开启经脉
neiGong . Qiankun (); //使用内功乾坤大挪移
}
//使用七伤拳
public void QiShang () {
jingMai . jingmai (); //开启经脉
neiGong . JiuYang (); //使用内功九阳神功
zhaoShi . QiShangQuan (); //使用招式七伤拳
}
}
张无忌使用的一些技能,综合了其他子系统类的若干个其他方法。
优点:
减少系统的相互依赖,所有的依赖都是对外观类的依赖,与子系统无关。 对用户隐藏了子系统的具体实现,减少用户对子系统的耦合。这样即使具体的子系统发生了变化,用户也不会感知到。 加强了安全性,子系统中的方法如果不在外观类中开通,就无法访问到子系统中的方法。 缺点:
不符合开放封闭原则。如果业务出现变更,则可能要直接修改外观类。 享元模式 使用共享对象有效地支持大量细粒度的对象。要求细粒度对象,那么不可避免地使得对象数量多且性质相近。
这些对象分为两个部分:内部状态和外部状态。
内部状态是对象可共享出来的信息,存储在享元对象内部并且不会随环境的改变而改变;而外部状态是对象依赖的一个标记,它是随环境改变而改变的并且不可共享的状态。
例如商城系统,商品对象维护一份即可,不随每个客户端请求查看而重新创建一个。
public class Goods implements IGoods {
private String name ; //名称
private String version ; //版本
Goods ( String name ) {
this . name = name ;
}
@Override
public void showGoodsPrice ( String version ) {
if ( version . equals ( "32G" )) {
System . out . println ( "价格为5199元" );
} else if ( version . equals ( "128G" )) {
System . out . println ( "价格为5999元" );
}
}
}
name为内部状态,用来标记自身,不变化。version为外部状态,由外部传入,实时变化。
工厂:
public class GoodsFactory {
private static Map < String , Goods > pool = new HashMap < String , Goods >();
public static Goods getGoods ( String name ) {
if ( pool . containsKey ( name )) {
System . out . println ( "使用缓存,key为:" + name );
return pool . get ( name );
} else {
Goods goods = new Goods ( name );
pool . put ( name , goods );
System . out . println ( "创建商品,key为:" + name );
return goods ;
}
}
}
pool里符合要求的对象已存在,直接复用,没有才创建。
使用场景:
行为型设计模式 策略模式 当我们写代码时总会遇到一种情况,就是我们会有很多的选择,由此衍生出很多的if…else,或者case。
如果每个条件语句中包含了一个简单的逻辑,那还比较容易处理;但如果在一个条件语句中又包含了多个条件语句,就会使得代码变得臃肿,维护的成本也会加大,这显然违背了开放封闭原则。
策略模式是一种行为设计模式,它定义了一系列算法,并将每一个算法封装起来,使它们可以相互替换。策略模式让算法的变化独立于使用算法的客户端。
demo:
public class ZhangWuji {
public static void main ( String [] args ) {
Context context ;
//张无忌遇到对手宋青书,采用对较弱对手的策略
context = new Context ( new WeakRivalStrategy ());
context . fighting ();
//张无忌遇到对手灭绝师太,采用对普通对手的策略
context = new Context ( new CommonRivalsticategy ());
context . fighting ();
//张无忌遇到对手成昆,采用对强大对手的策略
context = new Context ( new StrongRivalStrcategy ());
context . fighting ();
}
}
策略模式的使用场景和优缺点
对客户隐藏具体策略(算法)的实现细节,彼此完全独立。 针对同一类型问题的多种处理方式,仅仅是具体行为有差别时。 在一个类中定义了很多行为,而且这些行为在这个类里的操作以多个条件语句的形式出现。策略模式将相关的条件分支移入它们各自的 Strategy 类中,以代替这些条件语句。
使用策略模式可以避免使用多重条件语句。多重条件语句不易维护,而且易出错。 易于拓展。当需要添加一个策略时,只需要实现接口就可以了。
每一个策略都是一个类,复用性小。如果策略过多,类的数量会增多。上层模块必须知道有哪些策略,才能够使用这些策略,这与迪米特原则相违背。
模板方法模式 在软件开发中,有时会遇到类似的情况:某个方法的实现需要多个步骤,其中有些步骤是固定的;而有些步骤并不固定,存在可变性。为了提高代码的复用性和系统的灵活性,可以使用模板方法模式来应对这类情况。
public abstract class AbstractSwordsman {
//该方法为final,防止算法框架被覆写
public final void fighting () {
//运行内功,抽象方法
neigong ();
//调整经脉,具体方法
meridian ();
//如果有武器,则准备武器
if ( hasWeapons ()) { //2
weapons ();
}
//使用招式
moves ();
//钩子方法
hook (); //1
}
//空实现方法
protected void hook () {
}
protected abstract void neigong ();
protected abstract void weapons ();
protected abstract void moves ();
protected void meridian () {
System . out . println ( "开启正经与奇经" );
}
/**
* 是否有武器,默认是有武器的,钩子方法
*
* @return
*/
protected boolean hasWeapons () {
return true ;
}
}
定义:定义一个操作中的算法框架,而将一些步骤延迟到子类中,使得子类不改变一个算法的结构即可重定义算法的某些特定步骤。
这个抽象类包含了3种类型的方法,分别是抽象方法、具体方法和钩子方法。抽象方法是交由子类去实现的,具体方法则是父类实现了子类公共的方法。在上面的例子中就是武侠开启经脉的方式都一样,所以就在具体方法中实现。
钩子方法则分为两类:第一类在上面代码注释1 处,它有一个空实现的方法,子类可以视情况来决定是否要覆盖它;第二类在注释 2 处,这类钩子方法的返回类型通常是 boolean 类型的,其一般用于对某个条件进行判断,如果条件满足则执行某一步骤,否则将不执行。
观察者模式 观察者模式又被称为发布-订阅模式,属于行为型设计模式的一种,是一个在项目中经常使用的模式。
它的定义如下。
定义:定义对象间一种一对多的依赖关系,每当一个对象改变状态时,则所有依赖于它的对象都会得到通知并被自动更新。
Subject:抽象主题(抽象被观察者)。抽象主题角色把所有观察者对象保存在一个集合里,每个主题都可以有任意数量的观察者。抽象主题提供一个接口,可以增加和删除观察者对象。 ConcreteSubject:具体主题(具体被观察者)。该角色将有关状态存入具体观察者对象,在具体主题的内部状态发生改变时,给所有注册过的观察者发送通知。 Observer:抽象观察者,是观察者的抽象类。它定义了一个更新接口,使得在得到主题更改通知时更新自己。 ConcrereObserver:具体观察者,实现抽象观察者定义的更新接口,以便在得到主题更改通知时更新自身的状态。 public class Client {
public static void main ( String [] args ) {
SubscriptionSubject mSubscriptionSubject = new SubscriptionSubject ();
//创建微信用户
Weixinuser userl = new WeixinUser ( "杨影枫" );
WeixinUser user2 = new WeixinUser ( "月眉儿" );
WeixinUser user3 = new WeixinUser ( "紫轩" );
//订阅公众号
mSubscriptionSubject . attach ( userl );
mSubscriptionSubject . attach ( user2 );
mSubscriptionSubject . attach ( user3 );
//公众号更新发出消息给订阅的微信用户
mSubscriptionSubject . notify ( "刘望舒的专栏更新了" );
}
}
被观察者维护一个列表,用于添加删除观察者,在变化时给所有的观察者发送通知。
观察者模式的使用场景和优缺点
关联行为场景。需要注意的是,关联行为是可拆分的,而不是“组合”关系。 事件多级触发场景。跨系统的消息交换场景,如消息队列、事件总线的处理机制。
观察者和被观察者之间是抽象耦合,容易扩展。方便建立一套触发机制。
在应用观察者模式时需要考虑一下开发效率和运行效率的问题。程序中包括一个被观察者、多个观察者,开发、调试等内容会比较复杂,而且在 Java 中消息的通知一般是顺序执行的,那么一个观察者卡顿,会影响整体的执行效率,在这种情况下,一般会采用异步方式。
小结 需要注意的是学习设计模式最忌讳生搬硬套,为了设计模式而设计。设计模式主要解决的问题就是设计模式的六大原则,只要我们设计的代码遵循这六大原则,那么就是优秀的代码。
在当今的物联网(IoT)时代,我们的智能手机早已不仅仅是通讯工具,更是连接和控制身边智能硬件的中枢 。无论是追踪你运动数据的智能手环,监测你睡眠质量的智能床垫,还是让你告别钥匙的智能门锁,它们与 Android 设备之间高效、可靠的通信桥梁,正是低功耗蓝牙 (Bluetooth Low Energy, BLE) 技术。
什么是 BLE?
BLE 低功耗蓝牙 (通常也被称为 Bluetooth Smart)是专为物联网应用设计的无线通信协议。它继承了传统蓝牙的可靠性,但在功耗上做到了极致优化 。不同于传统蓝牙需要持续、高带宽的数据流,BLE 的核心在于快速连接、发送少量数据后迅速休眠,这使得它成为电池供电的小型设备的首选。对于 Android 开发者来说,熟练掌握如何利用 Android 系统提供的 API 与这些 BLE 设备进行交互,是构建现代移动应用的关键技能。
丰富的应用场景
BLE 连接技术已经渗透到我们生活的方方面面,带来了无限的创新可能:
健康与运动追踪: 智能手表、心率带、运动传感器等将实时数据传输到你的 Android App,进行分析和可视化。智能家居与控制: 通过手机控制智能灯泡、温度计、门锁、以及各种传感器。资产定位与寻物: 利用 iBeacon 或 Eddystone 等技术实现室内导航、商家推送,以及通过小巧的蓝牙标签寻找丢失的物品。本篇博客将介绍Android设备和BLE设备通信的几个关键流程,扫描 、连接 、发现服务 ,并最终实现与 BLE 设备的高效数据交互 。
核心概念先行:
手机 (Central / 中心设备): 主动扫描并连接其他设备的设备,在BLE协议中称为 中心设备 。手机、电脑等通常扮演这个角色。 BLE设备 (Peripheral / 外围设备): 被动广播自身信息,等待被连接的设备,称为外围设备 。如智能手环、心率带、防丢器等。 GATT (Generic Attribute Profile): 这是连接建立后,双方通信所遵循的核心协议。它定义了一个 服务-特征值 的数据结构。服务: 一个独立的功能模块。例如,一个“心率服务”。 特征: 服务下的具体数据点。它是实际读写操作的对象。例如,在“心率服务”下,会有 “心率测量特征” (用于读取心率数据)和 “心率位置特征” (用于写入或通知佩戴位置)。 属性: 特征、服务等都被称为属性,每个属性都有一个唯一的标识符。 1. 寻找设备 广播与扫描 这个阶段的目标是让手机发现BLE设备的存在
1.1 外围设备广播 外围设备会周期性地(例如每秒100次)向周围环境 发送广播数据包 (Advertising Packets)。这些数据包包含少量信息,这就是广播报文。
广播报文内容:
设备地址: 类似MAC地址,是设备的唯一标识符。 设备名称: 可读的名称,如 “MI_Band”。 发射功率: 用于粗略的距离估算。 服务UUIDs: 设备所支持的主要服务的列表。这是手机判断设备类型的关键(例如,看到“心率服务”的UUID,就知道这是个心率设备)。 制造商特定数据: 设备厂商可以自定义放入一些数据,如电池电量、硬件版本等。 1.2 中心设备扫描 手机(通常作为中央设备 Central)处于扫描 状态,App通过操作系统提供的蓝牙API启动蓝牙扫描,手机的蓝牙芯片会监听来自周围 BLE 设备的广播数据包,在同样的广播通道上监听这些广播报文。
手机收到数据包后,会将其解析并回调 给应用程序,提取出上述广播的信息,并在App的扫描结果列表中显示出来(例如,显示“发现设备:MI_Band”)。
此时,手机知道了BLE设备的存在和基本信息,但双方还未建立正式连接。这是设备间建立联系的第一步。
1.3 广播细节 在 手机(Observer) 跟 设备B(Advertiser) 建立连接之前,设备B需要先进行广播,即设备B不断发送如下广播信号,t 为广播间隔。
每发送一次广播包,我们称其为一次广播事件(advertising event),因此t也称为广播事件间隔。广播事件是有一个持续时间的,蓝牙芯片只有在广播事件期间才打开射频模块,这个时候功耗比较高,其余时间蓝牙芯片都处于idle状态,因此平均功耗非常低,以Nordic nRF52810为例,每1秒钟发一次广播,平均功耗不到11uA。
每一个广播事件包含三个广播包,即分别在37/38/39三个射频通道上同时广播相同的信息,即真正的广播事件是下面这个样子的。
设备B不断发送广播信号给手机(Observer),如果手机不开启扫描窗口,手机是收不到设备B的广播的,如下图所示,不仅手机要开启射频接收窗口,而且 只有手机的射频接收窗口跟广播发送的发射窗口匹配成功 ,而且 广播射频通道和手机扫描射频通道是同一个通道 ,手机才能收到设备B的广播信号。
也就是说,如果设备B在37通道发送广播包,而手机在扫描38通道,那么即使他们俩的射频窗口匹配,两者也是无法进行通信的。
由于这种匹配成功是一个概率事件,因此手机扫到设备B也是一个概率事件,也就是说,手机有时会很快扫到设备B,比如只需要一个广播事件,手机有时又会很慢才能扫到设备B,比如需要10个广播事件甚至更多。
避免信道干扰 为了避免与其他无线设备(主要是Wi-Fi)的干扰,BLE广播事件的三个广播包分别在 37/38/39 三个射频通道上广播,这三个通道分别避开了Wi-Fi信道 1/11/6 的下边缘和上边缘。
频率冲突:Wi-Fi主要工作在2.4GHz频段,而这个频段也正是蓝牙(包括BLE)的工作频段。Wi-Fi将其频段划分为多个信道,例如常用的1, 6, 11信道。Wi-Fi信道1 的中心频率是 2.412 GHz Wi-Fi信道6 的中心频率是 2.437 GHz Wi-Fi信道11 的中心频率是 2.462 GHz BLE信道的频率:BLE信道37: 2.402 GHz BLE信道38: 2.426 GHz BLE信道39: 2.480 GHz 你可能会注意到,BLE总共有40个物理信道(0-39)。37、38、39用于广播,那么剩下的0-36信道用于什么呢?
数据信道:在BLE连接建立之后,通信双方会使用 自适应跳频技术 ,在0-36这37个信道上进行数据传输。 跳频的意义:连接后使用跳频,是为了在数据传输阶段也能 动态地避开瞬时干扰 。主从设备会共同协商,跳过那些信噪比差、干扰大的信道,从而在连接状态下也能维持一个稳定、高效的数据链路。 2. 建立连接 当用户在手机 App 上选择一个设备后,就会开始连接过程。
手机请求:
动作: 手机 App 调用系统 API,向选定的 BLE 设备发送连接请求 (Connection Request)。信息: 请求中会包含连接参数 ,如连接间隔(Connection Interval)、从机延迟(Slave Latency)和超时时间(Supervision Timeout),这些参数定义了连接后数据交换的频率和容错能力。即双方会协商一套通信参数,如连接间隔(设备多久通信一次,影响功耗和响应速度)、从机延迟等。BLE 设备响应:
动作: BLE 设备从广播状态切换到连接 状态,并接受 连接请求。结果: 双方建立了一个双向的、独占的 连接。从此刻起,设备停止广播,并且只有这个手机能与它通信。双方进入链路层 (Link Layer)的数据交换阶段。在连接状态下,通信会从之前的3个广播通道切换到37个数据通道,并通过一种自适应跳频技术来避免无线干扰,保证通信稳定。3. 服务发现 连接建立后,手机需要知道设备上有什么功能。
BLE 使用 GATT (Generic Attribute Profile) 规范来组织数据。数据被组织成服务和特性,每个特性都有一个 UUID 标识。
手机作为 GATT 客户端 ,会自动向BLE设备发送一个 服务发现请求 。
BLE设备会将其内部的所有服务,以及每个服务下的所有特征,像一个文件目录一样完整地返回给手机。
手机端的蓝牙协议栈会解析这个“目录”,并建立一个本地的GATT数据库。手机 App 知道了设备的全部功能结构(UUID 和属性),就可以通过查询这个数据库来知道可以对设备进行哪些操作。
4. 配对绑定 安全校验和配对(Bonding/Pairing) 在手机和 BLE 设备之间的通信中不是必须的 。是否需要配对,完全取决于 BLE 设备上的特性(Characteristic) 的配置。
很多 BLE 服务中的特性(例如,电池电量、设备名称、简单的通知开关)被配置为可以进行未加密或无需身份验证的读取和写入操作。对于这些特性,手机可以直接在连接建立后进行服务发现,然后直接进行读写,不需要经过配对(Pairing)或绑定(Bonding)的复杂流程。
配对 是用于建立加密和身份验证的链路,它在以下情况是必须的:
敏感数据传输: 当传输的数据具有隐私性或敏感性时(如医疗数据、GPS 位置、个人运动记录)。 控制关键功能: 当手机需要控制设备的关键、有影响的功能时(如智能门锁的开关、支付授权、修改固件设置)。 需要用户身份确认: 设备的某个特性被配置为需要加密或身份验证权限才能访问。当手机尝试读写这个受保护的特性时,BLE 栈(Stack)会强制触发配对流程。 配对/绑定 流程 配对和绑定是为了建立信任 关系,并交换安全密钥 ,以便在后续连接中能进行加密通信 。安全性和配对通常发生在服务发现之后,或在第一次读写受保护的特性时触发。如访问加密、身份验证的特性时,系统会自动触发配对流程。
通信双方协商安全级别和配对方式(如 Just Works 、Passkey Entry 、Numeric Comparison 等)。配对过程中,手机可能会弹出配对请求框,显示一个随机生成的6位数字码。用户需要在设备上确认这个数字码,或者简单地点击 “配对” 按钮。然后双方会交换密钥,建立信任关系。
配对成功后,双方交换 长期密钥 (LTK) ,并将其存储起来(称为绑定 )。绑定后,后续连接可以直接使用 LTK 建立加密链路,无需重复配对。
5. 通信 - 基于GATT的数据交互 所有通信都是通过 对特征的读写 操作完成的。特征有不同的属性来控制其行为:
Read: 手机可以主动读取特征的值。例如,读取一次当前的电池电量 Write: 手机可以向特征写入数据(控制设备)。例如,向设备发送一个“寻找手环”的命令,手环收到之后就会震动 Notify / Indicate: 这是BLE通信中最重要、最节能的模式。设备可以在数据变化时,主动向手机推送数据,而手机无需不停地询问。Notify 通知: 不可靠通知,手机不回复确认。 Indicate 指示: 可靠通知,设备会等待手机的确认后再发送下一条。 这个流程是所有基于 BLE 的应用通信的基础。在 Android 平台,可以在 Android 的 BluetoothLeScanner 类中找到扫描相关的 API,在 BluetoothGatt 类中找到连接、服务发现和数据读写相关的 API。
如何传输大段数据 低功耗蓝牙 (BLE) 在设计之初是为了低功耗和传输少量 数据而优化的。因此,它在传输大段数据时会有一些限制和特定的处理方式。
BLE 数据传输基于 GATT (Generic Attribute Profile) ,数据是封装在 ATT (Attribute Protocol) 数据包中传输的。
ATT 最大传输单元 (ATT_MTU) 是应用层一次可以发送或接收的最大数据包大小。
在 BLE 4.0/4.1 中,默认的 ATT_MTU 是 23 字节。这意味着,在一个 Notification、Indication 或 Write 请求中,用户数据(特征值)部分最大只有 20 字节(因为 3 字节用于 ATT 头部, 23 - 3 = 20)。 在 BLE 4.2 及更高版本中,设备可以协商更大的 ATT_MTU(例如 250 字节以上),这显著提高了单次传输的效率。 物理层最大传输单元 (PDU) 的限制比 ATT_MTU 更底层。在 BLE 5.0 中,数据包的 PDU 最大可以达到 257 字节。
分包和重组 & 缩短传输间隔 由于单次 ATT 传输的有效载荷(Payload)有限(通常至少 20 字节,即使协商了更大的 MTU,也通常小于 512 字节),传输大段数据(如文件、图片等)就必须依赖应用层 进行分包和重组 。
a. 应用层分包 (Segmentation) 和重组 (Reassembly) 发送端分包 将完整的原始数据(例如 1MB 的文件)切分成多个小的分包。每个分包的大小取决于当前连接协商的 ATT_MTU 所允许的最大特征值大小。
1. 拆分小段数据 每一段数据包 添加头部 每个分包都需要添加一个自定义的应用层头部 (Header)。这个头部通常包含。
序号/索引 (Sequence Number) 用于接收端按正确顺序重组数据。总包数 (Total Packets) 或 数据长度 (Total Length) 帮助接收端判断是否接收完整。校验和 (Checksum) :用于验证分包数据的完整性。2. 逐包发送 发送端通过 BLE 的 Notification 或 Write Without Response (取决于你的设计)将这些分包一个接一个地发送出去。
3. 接收端重组 接收端根据每个分包中的 序号 ,将收到的数据段缓存并按照正确的顺序拼接起来,直到所有分包都收到,形成完整的原始数据。再做一次 完整性检查 通过头部中的 总包数/长度 和 校验和 来验证接收到的完整数据的正确性。
b. 提高传输效率的关键技术 为了加快传输速度,应该尽可能利用 BLE 协议栈提供的优化:
协商更大的 MTU :在连接建立后,立即 进行 MTU 协商(例如 Android/iOS 系统会自动进行,或者应用层手动触发)。将 MTU 增大到 256 甚至 517 字节,可以成倍减少分包的数量和 ATT 事务的次数。数据长度扩展 (DLE) :在 BLE 4.2 及更高版本中引入,它允许将物理层 PDU 的有效载荷从默认的 27 字节增加到 257 字节。这直接支持了 MTU 扩展。使用 Write Without Response 或 Notification :这两种方法是非确认机制,发送端发送数据后不需要等待接收端的确认 (ACK),因此可以连续快速发送。这是传输大段数据的首选方式,但需要应用层自行处理丢包或错误(通常通过重传机制)。优化连接间隔 (Connection Interval) :连接间隔越短,收发数据的频率越高,吞吐量也越大。但要注意,极短的连接间隔会增加功耗。你需要找到一个吞吐量和功耗之间的平衡点。Android项目简单实践 1.扫描设备 连接BLE设备,首先需要扫描。Android SDK中使用 BluetoothLeScanner 对象来执行扫描的动作:
private BluetoothLeScanner bluetoothLeScanner ;
bluetoothLeScanner = bluetoothAdapter . getBluetoothLeScanner ();
bluetoothLeScanner . startScan ( scanCallback );
由于扫描是一个异步的过程,所以这里需要传入一个回调接口,我们在回调接口去获取扫描的结果:
public ScanCallback scanCallback = new ScanCallback () {
@Override
public void onScanResult ( int callbackType , ScanResult result ) {
super . onScanResult ( callbackType , result );
ScanRecord record = result . getScanRecord ();
BluetoothDevice device = result . getDevice ();
String deviceName = record . getDeviceName ();
Log . d ( TAG , "record name:" + deviceName );
Log . d ( TAG , "ServiceUuids:" + record . getServiceUuids ());
if ( TextUtils . isEmpty ( deviceName )) {
return ;
}
if ( deviceName . startsWith ( "XX" )) { //这里我们可以找出设备名以XX开头的BLE设备
byte [] bytes = record . getBytes (); //这里可以获取整个广播的完整数据,包括协议头等
for ( int i = 0 ; i < bytes . length ; i ++) {
Log . d ( TAG , "[" + i + "]:" + bytes [ i ]);
}
bluetoothLeScanner . stopScan ( scanCallback ); //需要停止扫描
}
}
};
2.连接设备 在找到了“XX”名称的设备后,我们就可以发起GATT协议的连接了:
/**
*
* @param autoConnect Whether to directly connect to the remote device (false) or to automatically connect as soon as the remote device becomes available (true).
* @param callback GATT callback handler that will receive asynchronous callbacks.
*/
device . connectGatt ( context , false , gattCallback );
第二个参数 autoConnect 如果是false代表仅发起本次连接,如果连接不上则会反馈连接失败;如果是true则表示只要这个远程的设备可用,那么底层协议栈就会自动去连接,并且第一次连接不上,也会继续去连接。
第三个参数 callback 是一个 关于GATT协议相关的回调接口 ,主要有GATT连接状态的回调、发现Service服务的回调、特征值(Characteristic)发生改变的回调、最大传输单元(MTU)改变的回调、物理层发送模式(PHY)改变回调等,如下:
BluetoothGattCallback gattCallback = new BluetoothGattCallback () {
@Override
public void onPhyUpdate ( BluetoothGatt gatt , int txPhy , int rxPhy , int status ) {
super . onPhyRead ( gatt , txPhy , rxPhy , status );
Log . d ( TAG , "onPhyUpdate txPhy:" + txPhy + "; rxPhy:" + rxPhy );
}
@Override
public void onMtuChanged ( BluetoothGatt gatt , int mtu , int status ) {
super . onMtuChanged ( gatt , mtu , status );
Log . d ( TAG , "onMtuChanged mtu:" + mtu + "; status:" + status );
}
@Override
public void onConnectionStateChange ( BluetoothGatt gatt , int status , int newState ) {
super . onConnectionStateChange ( gatt , status , newState );
Log . d ( TAG , "onConnectionStateChange newState:" + newState );
if ( newState == BluetoothProfile . STATE_CONNECTED ) { //协议连接成功
Log . d ( TAG , "STATE_CONNECTED" );
bluetoothGatt = gatt ;
bluetoothGatt . discoverServices (); //发现service服务
} else if ( newState == BluetoothProfile . STATE_DISCONNECTED ) { //协议连接失败
Log . d ( TAG , "STATE_DISCONNECTED" );
}
}
}
3.获取服务和特征 在GATT协议连接成功之后,就可以去发现从设备端提供了哪些Service服务,如上代码。
这是一个异步的过程,待从设备反馈了自己提供的服务之后,Android框架层会通过BluetoothGattCallback回调通知,如下:
BluetoothGattCallback gattCallback = new BluetoothGattCallback () {
@Override
public void onServicesDiscovered ( BluetoothGatt gatt , int status ) {
super . onServicesDiscovered ( gatt , status );
List < BluetoothGattService > services = gatt . getServices ();
for ( BluetoothGattService service : services ) {
Log . d ( TAG , "UUID:" + service . getUuid (). toString ());
}
//1.根据UUID获取到服务
mGattService = gatt . getService ( UUID . fromString ( "0000ff00-0000-1000-8000-00805f9b34fb" ));
if ( mGattService == null ) {
Log . w ( TAG , "GattService is null!" );
} else {
Log . i ( TAG , "connect GattService" );
if ( writeCharacteristic == null ) {
//2.获取一个特征(Characteristic),这是从设备定义好的,我通过这个Characteristic去写从设备感兴趣的值
writeCharacteristic = mGattService
. getCharacteristic ( UUID . fromString ( "0000ff02-0000-1000-8000-00805f9b34fb" ));
}
if ( readCharacteristic == null ) {
//3.获取一个主设备需要去读的特征(Characteristic),获取从设备发送过来的数据
readCharacteristic = mGattService
. getCharacteristic ( UUID . fromString ( "0000ff01-0000-1000-8000-00805f9b34fb" ));
//4.注册特征(Characteristic)值改变的监听
bluetoothGatt . setCharacteristicNotification ( readCharacteristic , true );
List < BluetoothGattDescriptor > descriptors = readCharacteristic . getDescriptors ();
for ( BluetoothGattDescriptor descriptor : descriptors ) {
descriptor . setValue ( BluetoothGattDescriptor . ENABLE_NOTIFICATION_VALUE );
bluetoothGatt . writeDescriptor ( descriptor );
}
}
}
}
};
经过上述代码中的四个步骤,两个设备间已经可以发送和接收数据了。
4.通过特征(Characteristic)发送数据 把需要发送的数据设置到 writeCharacteristic,然后再调用 BluetoothGatt 的写入方法,即可完成数据的发送:
writeCharacteristic . setValue ( datas );
bluetoothGatt . writeCharacteristic ( writeCharacteristic );
5.读取数据 当从设备有数据发送到主设备之后,Android系统会回调 BluetoothGattCallback 的 onCharacteristicChanged 方法通知:
@Override
public void onCharacteristicChanged ( BluetoothGatt gatt , BluetoothGattCharacteristic characteristic ) {
super . onCharacteristicChanged ( gatt , characteristic );
UUID uuid = characteristic . getUuid ();
byte [] receiveData = characteristic . getValue ();
for ( byte b : receiveData ) {
Log . d ( TAG , "receiveData:" + Integer . toHexString ( b ));
}
}
三、注意事项 1.自动连接属性 connectGatt 方法的自动连接参数设置为true之后,连接建立了,这个时候如果是断开连接,如下:
bluetoothGatt . disconnect ();
虽然在Android层面的 BluetoothGattCallback 接口会立刻反馈一个 STATE_DISCONNECTED 信号值,但是在数据链路层却还是处于连接的状态,连接并没有断开。
2.开启定位功能 现在Android最新的版本,需要开启定位才能使用BLE功能。
判断定位功能是否开启:
private boolean isLocationEnable ( Context context ) {
LocationManager locationManager = ( LocationManager ) context . getSystemService ( Context . LOCATION_SERVICE );
boolean networkProvider = locationManager . isProviderEnabled ( LocationManager . NETWORK_PROVIDER );
boolean gpsProvider = locationManager . isProviderEnabled ( LocationManager . GPS_PROVIDER );
if ( networkProvider || gpsProvider ) {
return true ;
}
return false ;
}
开启定位功能的方法:
LocationManager locationManager = ( LocationManager ) context . getSystemService ( Context . LOCATION_SERVICE );
try {
Field field = UserHandle . class . getDeclaredField ( "SYSTEM" );
field . setAccessible ( true );
UserHandle userHandle = ( UserHandle ) field . get ( UserHandle . class );
Method method = LocationManager . class . getDeclaredMethod (
"setLocationEnabledForUser" ,
boolean . class ,
UserHandle . class );
method . invoke ( locationManager , true , userHandle );
} catch ( Exception e ) {
}
3.最大传输单元(MTU)的设置 Android默认的最大传输单元(MTU)是23个字节,除去报文头占用的3个字节,实际最大只能传递20个字节。当两个设备之间传递的数据长度超过20字节的时候,数据就会被截断,导致通信异常。
只有在GATT协议连接成功之后,才可以设置MTU值,最大MTU=512,如下:
bluetoothGatt . requestMtu ( 128 );
4.从设备广播间隔影响连接 当Android协议栈(Host)给蓝牙芯片Chip发送一个连接的指令,芯片在收到之后,会在一定的时间内去接收从设备的广播,在收到广播之后才会发送连接请求给从设备;如果从设备的广播间隔设置不合理,就会导致芯片无法在限定的时间内收到广播,导致无法发送连接请求。
对于安卓开发者来说,理解并熟练运用架构模式是提升代码质量、可维护性和可测试性的关键。
我们总是在追求编写更清晰、更健壮、更易于维护的代码。而选择一个合适的应用架构,正是实现这一目标的基石。从经典的 MVC,到后来的 MVP、MVVM,再到如今函数式思想影响下的 MVI,安卓的架构模式一直在演进。
为了方便对比,我们设定一个极其简单的业务场景:
一个登录界面,包含输入用户名、密码的输入框和一个登录按钮。点击按钮后,模拟一个网络请求,根据结果(成功/失败)更新 UI。
MVC (Model-View-Controller) MVC 是一个非常古老的 UI 架构模式,在安卓早期开发中,它是一种“天然”的结构。
Model (模型): 负责处理数据和业务逻辑。例如,网络请求、数据库操作、数据bean类。View (视图): 负责展示 UI 界面,并将用户的操作(点击、输入)传递出去。在安卓中,这通常由 XML 布局文件和 Activity/Fragment 扮演。Controller (控制器): 接收来自 View 的用户操作,调用 Model 处理业务逻辑,然后更新 View 的显示。Activity/Fragment 通常也承担了 Controller 的角色。MVC的问题 在安卓中,Activity/Fragment 的职责过重,它既是 View 的一部分,又是 Controller。这 导致 View 和 Controller 紧密耦合 ,业务 逻辑和 UI 代码混杂 在一起,使得代码难以测试和维护。这就是我们常说的超大型Activity和Fragment。
简单代码实现 UserModel.kt (Model)
// M - Model: 负责业务逻辑和数据
data class User ( val name : String )
object UserModel {
// 模拟登录网络请求
fun login ( username : String , callback : ( Result < User >) -> Unit ) {
// 模拟延时
Thread . sleep ( 1000 )
if ( username == "admin" ) {
callback ( Result . success ( User ( "Administrator" )))
} else {
callback ( Result . failure ( Exception ( "用户名或密码错误" )))
}
}
}
activity_login.xml (View)
<LinearLayout xmlns:android= "http://schemas.android.com/apk/res/android"
android:layout_width= "match_parent"
android:layout_height= "match_parent"
android:orientation= "vertical"
android:padding= "16dp" >
<EditText
android:id= "@+id/et_username"
android:layout_width= "match_parent"
android:layout_height= "wrap_content"
android:hint= "Username" />
<Button
android:id= "@+id/btn_login"
android:layout_width= "match_parent"
android:layout_height= "wrap_content"
android:text= "Login" />
<ProgressBar
android:id= "@+id/progress_bar"
android:layout_width= "wrap_content"
android:layout_height= "wrap_content"
android:layout_gravity= "center"
android:visibility= "gone" />
</LinearLayout>
LoginActivity.kt (View & Controller)
// V & C: Activity 同时扮演视图和控制器的角色
class LoginActivity : AppCompatActivity () {
private lateinit var usernameEditText : EditText
private lateinit var loginButton : Button
private lateinit var progressBar : ProgressBar
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
setContentView ( R . layout . activity_login )
usernameEditText = findViewById ( R . id . et_username )
loginButton = findViewById ( R . id . btn_login )
progressBar = findViewById ( R . id . progress_bar )
loginButton . setOnClickListener {
handleLogin ()
}
}
private fun handleLogin () {
showLoading ()
val username = usernameEditText . text . toString ()
// 控制器直接调用模型
// 注意:这里为了简化在主线程调用,实际开发应使用协程或线程池
Thread {
UserModel . login ( username ) { result ->
runOnUiThread {
hideLoading ()
result . onSuccess { user ->
showSuccess ( "欢迎, ${user.name}!" )
}. onFailure { error ->
showError ( error . message ?: "登录失败" )
}
}
}
}. start ()
}
private fun showLoading () {
progressBar . visibility = View . VISIBLE
}
private fun hideLoading () {
progressBar . visibility = View . GONE
}
private fun showSuccess ( message : String ) {
Toast . makeText ( this , message , Toast . LENGTH_SHORT ). show ()
}
private fun showError ( message : String ) {
Toast . makeText ( this , message , Toast . LENGTH_SHORT ). show ()
}
}
MVP (Model-View-Presenter) 为了解决 MVC 中 Controller 和 View 的过度耦合问题,MVP 诞生了。它引入了一个新的角色:Presenter。
Model: 职责不变,处理数据和业务逻辑。View: 职责更纯粹,只负责 UI 的渲染和事件的传递。Activity/Fragment 属于 View 层。它通常会实现一个接口,供 Presenter 调用。Presenter: 作为 View 和 Model 之间的桥梁。它从 Model 获取数据,然后调用 View 接口的方法来更新 UI。Presenter 不持有任何 Android 框架的引用 ,这使得它很容易进行单元测试。解决了一些MVC的痛点,View 和 Presenter 通过接口进行通信,实现了彼此的解耦。Presenter 持有 View 的接口引用,但不关心 View 的具体实现。
MVP的问题 主要有两点:
接口爆炸: 为了清晰地定义View和Presenter之间的契约,你需要为每一个界面(或功能模块)定义至少两个接口: IView 和 IPresenter 。随着项目模块的增加,接口数量会急剧膨胀,导致代码文件数量非常多。 繁琐的绑定与解绑: Presenter 需要持有 View 的引用,为了避免内存泄漏(尤其是在异步任务回调时),你必须在View(如Activity/Fragment)的生命周期方法(onCreate, onDestroy)中手动进行 attachView() 和 detachView() 操作。这个过程是重复且容易出错的。 代码实现 LoginContract.kt (契约接口)
// 定义 View 和 Presenter 之间的契约
interface LoginContract {
// View 必须实现的接口
interface View {
fun showLoading ()
fun hideLoading ()
fun showLoginSuccess ( message : String )
fun showLoginError ( message : String )
}
// Presenter 必须实现的接口
interface Presenter {
fun login ( username : String )
fun onDestroy ()
}
}
LoginPresenter.kt (Presenter)
// P - Presenter: 不含任何 Android SDK 代码,纯 Kotlin/Java
class LoginPresenter ( private var view : LoginContract . View ?) : LoginContract . Presenter {
// Presenter 持有 Model 的引用
private val model = UserModel
override fun login ( username : String ) {
view ?. showLoading ()
// 同样,这里简化处理,实际应在子线程
Thread {
model . login ( username ) { result ->
// 回到主线程更新 UI
( view as ? AppCompatActivity ) ?. runOnUiThread {
view ?. hideLoading ()
result . onSuccess { user ->
view ?. showLoginSuccess ( "欢迎, ${user.name}!" )
}. onFailure { error ->
view ?. showLoginError ( error . message ?: "登录失败" )
}
}
}
}. start ()
}
// 防止内存泄漏
override fun onDestroy () {
view = null
}
}
LoginActivity.kt (View)
// V - View: 只负责 UI 展示和用户事件传递
class LoginActivity : AppCompatActivity (), LoginContract . View {
private lateinit var presenter : LoginContract . Presenter
// ... UI 控件声明 ...
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
setContentView ( R . layout . activity_login )
presenter = LoginPresenter ( this )
// ... findViewById ...
loginButton . setOnClickListener {
presenter . login ( usernameEditText . text . toString ())
}
}
override fun showLoading () {
progressBar . visibility = View . VISIBLE
}
override fun hideLoading () {
progressBar . visibility = View . GONE
}
override fun showLoginSuccess ( message : String ) {
Toast . makeText ( this , message , Toast . LENGTH_SHORT ). show ()
}
override fun showLoginError ( message : String ) {
Toast . makeText ( this , message , Toast . LENGTH_SHORT ). show ()
}
override fun onDestroy () {
presenter . onDestroy ()
super . onDestroy ()
}
}
MVVM (Model-View-ViewModel) MVVM 是 Google 官方推荐的架构模式,也是 Jetpack 组件(如 ViewModel, LiveData, DataBinding)的核心思想。
Model: 职责不变。View: 职责依然是 UI 展示。但它不再被动地等待 Presenter 调用,而是主动观察 (Observe) ViewModel 中的数据变化来更新自己。ViewModel: 类似于 Presenter,负责处理业务逻辑并持有数据。但它不直接引用 View。它通过暴露可观察的数据(如 LiveData或 StateFlow)来通知 View 更新。ViewModel 的生命周期与 UI 控制器(Activity/Fragment)的配置更改无关,因此在屏幕旋转时数据不会丢失。解决前面两代主流架构的痛点: 数据绑定 (Data Binding) 和 生命周期感知 (Lifecycle-Aware) 。View 和 ViewModel 通过可观察的数据流进行单向或双向绑定,实现了比 MVP 更彻底的解耦。
MVVM的问题 状态管理的复杂性(Lack of Unidirectional Data Flow):
虽然 MVVM 实现了视图和数据之间的双向绑定,但在复杂的场景下,这可能导致数据流变得难以追踪。当一个数据模型在多个视图或组件之间共享时,任何一方的修改都可能影响到其他部分,使得状态的来源和变化路径变得模糊不清。 不一致的状态(Inconsistent State):
在某些情况下,视图可能会从多个地方接收数据更新(例如,网络请求、本地数据库更新、用户输入)。当这些更新并非同步发生时,视图可能会进入一种不一致的状态,导致用户界面出现意料之外的行为或显示错误。 代码实现 LoginViewModel.kt (ViewModel)
// VM - ViewModel: 持有数据和业务逻辑,通过 LiveData 通知 View
class LoginViewModel : ViewModel () {
private val model = UserModel
// UI 状态的 LiveData
private val _loginState = MutableLiveData < LoginUiState >()
val loginState : LiveData < LoginUiState > = _loginState
fun login ( username : String ) {
_loginState . value = LoginUiState . Loading
// 使用 ViewModelScope 协程来处理异步操作
viewModelScope . launch ( Dispatchers . IO ) {
model . login ( username ) { result ->
val newState = result . fold (
onSuccess = { user -> LoginUiState . Success ( "欢迎, ${user.name}!" ) },
onFailure = { error -> LoginUiState . Error ( error . message ?: "登录失败" ) }
)
// 切换回主线程更新 LiveData
withContext ( Dispatchers . Main ) {
_loginState . value = newState
}
}
}
}
}
// 定义 UI 状态的密封类
sealed class LoginUiState {
object Loading : LoginUiState ()
data class Success ( val message : String ) : LoginUiState ()
data class Error ( val message : String ) : LoginUiState ()
}
LoginActivity.kt (View)
// V - View: 观察 ViewModel 中的数据变化来更新 UI
class LoginActivity : AppCompatActivity () {
// 通过 ktx 库轻松获取 ViewModel
private val viewModel : LoginViewModel by viewModels ()
// ... UI 控件声明 ...
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
setContentView ( R . layout . activity_login )
// ... findViewById ...
loginButton . setOnClickListener {
viewModel . login ( usernameEditText . text . toString ())
}
// 观察 LiveData 的变化
viewModel . loginState . observe ( this ) { state ->
when ( state ) {
is LoginUiState . Loading -> showLoading ()
is LoginUiState . Success -> {
hideLoading ()
showSuccess ( state . message )
}
is LoginUiState . Error -> {
hideLoading ()
showError ( state . message )
}
}
}
}
// ... UI 更新方法 ...
}
别忘了在 build.gradle 文件中添加 ViewModel 和 LiveData 的依赖。
MVI (Model-View-Intent) MVI 是一种更现代的架构模式,深受函数式编程思想的影响,它强调单向数据流 和状态的唯一可信源 。
Model: 在 MVI 中,Model 通常指UI 状态 (State) 。它是一个不可变的数据结构,代表了 UI 在某一时刻的所有状态。View: 负责渲染 UI 状态,并捕获用户意图 (Intent) ,将其发送出去。Intent: 不要和安卓的 Intent 组件混淆。这里的 Intent 指的是用户的操作意图,例如 LoginClickedIntent、UsernameChangedIntent 等。环形单向数据流: View 发送 Intent (用户意图)。 ViewModel (或类似角色) 接收 Intent,处理业务逻辑。 ViewModel 生成一个新的 State (UI 状态)。 View 订阅 State 的变化,并用新状态渲染自己。 唯一数据源: UI 的所有状态都由一个 State 对象管理,任何对 UI 的更新都必须通过生成一个新的 State 来实现。这使得状态变化变得可预测和易于调试。这一定程度上解决了 MVVM 架构的多数据来源导致UI变化难以追踪的问题。代码实现 LoginContract.kt (State, Intent, Effect)
// M - State: UI 的状态,必须是不可变的
data class LoginViewState (
val isLoading : Boolean = false ,
val errorMessage : String ? = null
)
// I - Intent: 用户的意图
sealed class LoginIntent {
data class LoginClicked ( val username : String ) : LoginIntent ()
}
// Side Effect: 一次性事件,如 Toast 或导航
sealed class LoginEffect {
data class ShowSuccessToast ( val message : String ) : LoginEffect ()
}
LoginViewModel.kt (处理 Intent,生成 State)
// ViewModel: 处理 Intent,更新 State,发送 Effect
class LoginViewModel : ViewModel () {
private val model = UserModel
private val _state = MutableStateFlow ( LoginViewState ())
val state : StateFlow < LoginViewState > = _state . asStateFlow ()
private val _effect = MutableSharedFlow < LoginEffect >()
val effect : SharedFlow < LoginEffect > = _effect . asSharedFlow ()
// 统一处理所有 Intent
fun processIntent ( intent : LoginIntent ) {
when ( intent ) {
is LoginIntent . LoginClicked -> login ( intent . username )
}
}
private fun login ( username : String ) {
viewModelScope . launch {
_state . value = _state . value . copy ( isLoading = true , errorMessage = null )
// 使用 Coroutine + Flow
kotlin . runCatching {
// 模拟异步调用
withContext ( Dispatchers . IO ) { model . performLogin ( username ) }
}. onSuccess { user ->
_state . value = _state . value . copy ( isLoading = false )
_effect . emit ( LoginEffect . ShowSuccessToast ( "欢迎, ${user.name}!" ))
}. onFailure { error ->
_state . value = _state . value . copy ( isLoading = false , errorMessage = error . message )
}
}
}
}
// 可以在 Model 中提供一个挂起函数
suspend fun UserModel . performLogin ( username : String ): User {
delay ( 1000 )
if ( username == "admin" ) return User ( "Administrator" )
else throw Exception ( "用户名或密码错误" )
}
LoginActivity.kt (View)
// V - View: 发送 Intent,订阅 State 和 Effect
class LoginActivity : AppCompatActivity () {
private val viewModel : LoginViewModel by viewModels ()
// ... UI 控件 ...
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
// ... setContentView, findViewById ...
loginButton . setOnClickListener {
viewModel . processIntent ( LoginIntent . LoginClicked ( usernameEditText . text . toString ()))
}
// 订阅 State 变化来更新持久性 UI
lifecycleScope . launch {
viewModel . state . collect { state ->
progressBar . visibility = if ( state . isLoading ) View . VISIBLE else View . GONE
state . errorMessage ?. let { Toast . makeText ( this @LoginActivity , it , Toast . LENGTH_SHORT ). show () }
}
}
// 订阅 Effect 来处理一次性事件
lifecycleScope . launch {
viewModel . effect . collect { effect ->
when ( effect ) {
is LoginEffect . ShowSuccessToast -> {
Toast . makeText ( this @LoginActivity , effect . message , Toast . LENGTH_SHORT ). show ()
}
}
}
}
}
}
从 MVC 到 MVI,我们可以清晰地看到一个趋势:职责分离越来越明确,耦合度越来越低,代码的可测试性和可维护性越来越强 。特别是从 MVVM 到 MVI,我们开始更多地借鉴函数式编程 的思想,通过管理不可变的状态和单向数据流来构建更加稳健和可预测的应用。
Clean Architecture 相比于 MVC、MVP、MVVM 这些主要关注于 UI层 的架构模式外,Clean Architecture(整洁架构)是一个更高层次、更宏观的架构思想。
简单来说,如果把 MVP/MVVM 看作是如何组织一个具体页面的代码(View、Presenter/ViewModel、Model),那么 Clean Architecture 就是如何组织整个 App 所有模块代码的宏伟蓝图 。
Clean Architecture 由 Robert C. Martin (人称 “Uncle Bob”) 提出,其核心目标是 “分离关注点” (Separation of Concerns) ,通过将软件系统划分成不同的层次,来创建一个易于维护、独立于框架、可测试性极强的系统。
核心思想:依赖关系原则 (The Dependency Rule) 这是 Clean Architecture 最最核心的一条规则:
源代码的依赖关系,只能从外层指向内层。
想象一个洋葱或一组同心圆,内层代码对任何外层代码都一无所知。
这些层次通常代表什么呢?从内到外:
Entities (实体层) 这是最核心的内层。 定义了整个应用的核心业务对象和规则。在安卓中,这通常是你的数据模型类(例如 User, Product, Order 等),它们是纯粹的 Kotlin/Java 对象 (POJO/POKO),不应该包含任何与安卓框架、数据库或网络相关的代码。极度稳定,变动最少。它不知道任何其他层的存在。
Use Cases / Interactors (用例层 / 交互器) 这是应用的业务逻辑层。封装并实现了应用的所有业务用例。例如 LoginUseCase (处理登录逻辑)、GetUserProfileUseCase (获取用户信息)、PlaceOrderUseCase (下单逻辑) 等。它们会协调 Entities 来完成具体的业务操作。这一层同样是纯 Kotlin/Java 代码,不依赖任何外层。它知道 Entities,但不知道谁会来调用它,也不知道数据从哪里来(是从网络还是数据库)。
Interface Adapters (接口适配器层) 这是数据转换层。负责将 Use Cases 和 Entities 层的数据,转换成适合外层(如UI、数据库)使用的格式,反之亦然。你熟悉的 MVP 中的 Presenter 和 MVVM 中的 ViewModel 就生活在这一层 。此外,还包括数据库的数据映射器 (Mappers)、网络请求返回的数据模型 (DTOs) 等。
它的作用就像一个双向翻译官。例如,ViewModel 调用 Use Case,获取到纯业务数据 (Entity),然后 ViewModel 将这个 Entity 转换成 UI 可以直接显示的格式 (UI Model)。
Frameworks & Drivers (框架与驱动层) 这是最外层,也是最不稳定的一层。包含所有具体的实现细节。例如:
UI: Activities, Fragments, Jetpack Compose UI数据库: Room, Realm 的具体实现网络: Retrofit, Volley 的具体实现安卓框架: 各种 Android SDK 的调用这一层是所有东西粘合在一起的地方,依赖关系都指向内部。比如,Activity 持有 ViewModel 的引用,但 ViewModel 对 Activity 一无所知。
Clean Architecture 与 MVP/MVVM 的关系 很多人会误解 Clean Architecture 是 MVP/MVVM 的替代品,其实不是。它们是互补关系:
Clean Architecture 是一个宏观的、全局的架构设计。 它定义了整个应用的模块划分和依赖方向,比如把业务逻辑 (domain 模块) 和数据获取 (data 模块) 以及界面展示 (presentation 模块) 分开。MVP/MVVM 是一个微观的、专注于 UI 层的设计模式。 它通常被应用在 Clean Architecture 的最外两层(Interface Adapters 和 Frameworks & Drivers)来组织 UI 代码。可以这样理解一个典型的请求流程:
View (Activity/Fragment) 在最外层,它接收到用户操作。View 通知 ViewModel (位于接口适配器层)。 ViewModel 调用相应的 Use Case (位于用例层) 来执行业务逻辑。 Use Case 可能会通过一个 Repository 接口 (接口定义在 Use Case 层) 来请求数据。 这个接口的具体实现 RepositoryImpl (位于框架驱动层或接口适配器层) 会决定是从网络 (Retrofit) 还是从本地数据库 (Room) 获取数据。 数据从内层一步步返回,经过适配器层的转换,最终由 ViewModel 提供给 View 进行展示。 在这个流程中,Use Case 层根本不关心数据是来自网络还是数据库,也不关心数据最终是显示在 Activity 上还是一个 Compose 屏幕上。这就实现了彻底的解耦。
优点总结 独立于框架 (Framework Independent): 核心业务逻辑不依赖于安卓 SDK,可以轻松迁移到其他平台(如桌面应用)。可测试性强 (Testable): 内层的业务逻辑 (Use Cases, Entities) 是纯粹的 Kotlin/Java 代码,可以进行非常快速的单元测试,无需启动模拟器。独立于 UI (UI Independent): 你可以随意更换你的 UI 实现(比如从 XML 布局换成 Jetpack Compose),而无需改动任何业务逻辑。独立于数据库 (Database Independent): 你可以从 Room 切换到其他数据库,只需要改动最外层的具体实现,核心逻辑不受影响。代码结构清晰 (Maintainable): 尤其在大型复杂项目中,严格的分层让代码职责分明,新人更容易上手,代码也更容易维护。Android平台常见动效 现在市面上的形形色色Android客户端,为了更优的用户体验,我们开发的上游产品和交互往往会在界面里设计很多动效。传统的一页页的静态展示页面已经不足以满足用户的审美需求了。
而动效的分类也是花样百出的,以播放时机来说有点击触发,打开页面触发,还有可跟随手指的交互持续触发的等等。有时候一些和数据耦合性较大的动效甚至需要我们自己来手写复杂的自定义View,比如曲线图、图表类型。
而我日常碰到的大部分的动效需求,还是依赖UI设计的同时来制作提供的,像那些短时间单次的展示类动效,往往实现方式比较随意,对资源的格式要求也不太严苛。
简单动画 帧动画,在Android中,帧动画是通过Drawable动画实现的。你可以创建一个AnimationDrawable对象,然后在XML中定义一系列的帧(frames),每帧可以是一个Drawable资源。然后在代码中启动这个动画。注意确保你的每个Drawable资源的尺寸是一致的,以便在动画过程中保持帧的正确显示。 PAG动画,pag相较于上面的帧动画对性能更加友好。PAG是腾讯公司自主研发的一套完整动画工作流解决方案。最初的原因是为了解决更为复杂的视频编辑场景下动画渲染问题,同时又覆盖了UI动画和直播场景,于2022年1月在Github开源。其使用方法可以说相当简单,只需要先从github主页确定版本,到gradle里引入依赖,然后在我们应用的xml布局中放置pagView,没有额外的属性需要配置。最后在代码里设置其文件源,循环方式,调用播放即可。 MP4动画,比较直接,将动画导出为视频格式,直接获取mediaplayer实例,绑定surfaceView或者TextureView,再填文件,播放视频即可。需要关注的是surfaceView播放视频一开始可能会有黑屏问题,可以用静态图占位。 可交互3D动效 Kanzi动效 跟手可互动的动效,也不得不谈kanzi动效。以下介绍来自百科与官网:
Kanzi产品是行业领先的3D引擎和UI开发工具,支持高效率沉浸式3D效果,跨系统多屏互联并能与安卓生态完美融合,已经成为全球主流车厂智能座舱首选的UI开发工具和引擎。更新后的Kanzi架构可与安卓操作系统、生态系统深度兼容。Kanzi可基于安卓的任何功能提供强大的图形设计支持,确保高质量的图像效果。
对于Kanzi动效的集成使用方式,因为没有自己从头开始对接,我只按照顺序一笔带过,有不对的地方欢迎指正。首先我们集成kanzi运行所需的Runtime.aar,kanziJava支持库aar,资源文件,资源列表的txt等等,还需要在gradle里写明不可压缩的文件类型,以防止无法加载资源。
在使用上,我们先在XML布局中声明,同时通过属性填入asstes里的资源名,和资源文件绑定:
<com.rightware.kanzi.KanziTextureView
android:id= "@+id/tx_KanziSurfaceView"
android:layout_width= "@dimen/dp_2560"
android:layout_height= "@dimen/dp_1190"
app:clearColor= "@android:color/transparent"
app:kzbPathList= "climate.kzb"
app:layout_constraintTop_toTopOf= "parent"
app:name= "climate"
app:startupPrefabUrl= "kzb://climate/StartupPrefab"
tools:ignore= "MissingConstraints" />
在Java代码里我们需要设置通信的工具类,在里面添加监听器来接收和上行下行信号的交互:
// 数据接口定义
public interface AndroidNotifyListener {
void notifyDataChanged ( String name , String value );
void dataSourceFinish ();
}
// 添加数据接收监听和下行通信
AndroidUtils . setListeners ( this );
AndroidUtils . removeListeners ( this );
AndroidUtils . setValue ( SourceData . RightMidMove_up2down , y );
Unity动效 本文重点,Unity的大名在游戏界可谓如雷贯耳,记得小时候玩的很多游戏的开屏界面即有一个大大的 Unity 字样和图标。
Unity是实时3D互动内容创作和运营平台。包括游戏开发、美术、建筑、汽车设计、影视在内的所有创作者,借助Unity将创意变成现实。Unity平台提供一整套完善的软件解决方案,可用于创作、运营和变现任何实时互动的2D和3D内容,支持平台包括手机、平板电脑、PC、游戏主机、增强现实和虚拟现实设备。Unity作为全球领先的 3D 引擎之一,团结引擎可以为 3D HMI提供全栈支持。即为从概念设计到量产部署的整个 HMI 工作流程提供创意咨询、性能调优、项目开发等解决方案,从而为车载信息娱乐系统和智能驾驶座舱打造令人惊叹的交互式体验。
其实在第一版我们项目集成的是上面的Kanzi方案,其性能表现较Unity要差一些。性能还是其次,发起替换的主要原因还是在项目推进的过程中,对方工程师对动效样式的优化达不到评测部门的要求,后来更新迭代就更换了Unity方案。
而本文的重点也是在于Unity3D动效的使用,案例为车载IVI系统空调app的风向调节,交互逻辑比上面举的例子更加复杂,需要实时跟手,在交互热区范围内需要不断变化动效形态,并完成双向通信,保证动效和车载信号的一致性。
Android应用对接Unity集成的两种方案 以下提到的集成方案均可以在Unity的官方网站进行更加详细的查阅:
团结引擎 手册
通信协议制定 集成的第一步,要提前根据APP产品交互逻辑,来指定和Unity之间的通信协议。有哪些功能是开关,需要调整哪些属性。例如空调app里就涉及几个出风口的打开关闭,可以以0/1来区分。还有风口的方向调节,需要互传x,y坐标值。Android和Unity之间一般是采用JSON字符串来通信的。
而且,两方通信链路和Unity的集成方式还有关,像下面要谈到的第一种进程隔离方案,就是通过集成全量的Unity依赖包,利用aar内部JNI接口来通信的,而第二种Client/Server架构就是通过Android的AIDL接口来和单独的Unity服务端进程通信的。
进程隔离方案-UAAL(Render As Library) 基于UAAL(Render As Library),支持把渲染服务嵌入原生安卓APP。
Tuanjie 引擎可作为 Render Service,嵌入原生 Android APP,为原生 Android APP 提供 3D 内容 支持多个 view,支持非全屏渲染,每个 APP 仅需集成 View 组件,脱离 Activity 支持加载多个 Tuanjie 实例 Tuanjie Editor 打包出的 Android Studio 工程或 APK 包括 Client 和 Service 两部分。
UAAL 方案的优势在于,Unity 渲染服务和原生 APP 之间的通信链路是独立的,原生 APP 可以通过 JNI 接口和 Unity 渲染服务进行通信,而 Unity 渲染服务也可以通过 JNI 接口和原生 APP 进行通信。
这种方式集成的话,Unity会将渲染引擎,资源文件,和Android上层的通信代码都打包导出到一个aar中,其体积随动效的复杂程度而变化,同时会使集成方的apk包体积增加。而且项目里有多少方要使用Unity动效,就需要多少份的渲染引擎。这个方案由客户端来负责Unity控件的创建销毁,显示隐藏,一般适用一对一,通信链路简单的,即项目中可能只有一个模块需要使用Unity动效的情况。在多模块需要使用Unity的情况下,进程隔离的方案对性能的占用也比较高。
上层使用到的控件——UnityPlayer,它是一个Unity自定义的FrameLayout,里面有他们自己实现的一系列添加view,显示,和渲染逻辑。资源文件均存在于Unity打的依赖包中,对外不开放。
集成步骤 第一步,将Unity提供的aar放置于libs文件夹中,并在gradle里添加其编译引用。
implementation files ( 'libs/UnityAnimation_0321V4.aar' )
第二步,gradle中配置Unity所需的NDK版本,配置abifilters,设置要将哪些架构的动态库打包到apk中,对于车机项目来说只需要固定的某一种架构即可。还有设置不压缩的文件类型,使Unity可以顺利找到资源使用。
ndkVersion "23.1.7779620"
aaptOptions {
noCompress = [ '.tj3d' , '.ress' , '.resource' , '.obb' , '.bundle' , '.tuanjieexp' , 'global-metadata.so' ] + tuanjieStreamingAssets . tokenize ( ', ' )
ignoreAssetsPattern = "!.svn:!.git:!.ds_store:!*.scc:!CVS:!thumbs.db:!picasa.ini:!*~"
}
ndk {
abiFilters 'arm64-v8a'
}
有一点需要注意,我们还需要在项目的string.xml资源文件中添加Unity所需的一条 String 资源,否则Unity侧会空指针。
<string name= "game_view_content_description" > Game view</string>
第三步,将要显示Unity动效的页面 Activity 改为继承自 UnityPlayerActivity ,Unity的核心显示控件是 UnityPlayer ,它的创建销毁,显示隐藏,由 UnityPlayerActivity 来统一管理,项目中集成这个 Activity 的子类再将 mUnityPlayer 通过 addView() 添加到自己的根布局 ViewGroup 中当背景即可,而且可以在xml上面继续增加其他View控件。
第四步,封装Unity通信工具类,Android给Unity发消息可以直接通过 UnityPlayer 的 sendMessage() 静态方法,传入Unity通信协议中指定的类名。
UnityPlayer . UnitySendMessage ( OBJ_NAME , METHOD_NAME , communicateMessage )
Unity使用C#开发,其给 Android 上层发消息则是通过反射回调信号类里的方法实现的,所以我们最好将信号管理类做成单例的,并给其Unity留下一个方法或者成员,可以拿到我们类的实例,顺利反射回调。我这里使用的是一个Kotlin类声明,并对外暴露一个公开的 unityInstance 成员。而这个方法 onReceiveMsgFromUnity ,即是Unity的反射调用,我们在其中进行信号的解析,并传到View中去,注意这个方法不是在主线程中反射的,所以后面需要优化一波。
object UnityMessageHelper {
val unityInstance = this
// Unity给Android的消息回调
fun onReceiveMsgFromUnity ( msg : String ) {
LogUtils . d ( TAG , "onReceiveMsgFromUnity: $msg" )
if ( listenerList . size > 0 ) {
listenerList . forEach {
it . onReceiveUnityMessage ( msg )
}
}
}
}
信号类UnityMessageHelper的优化 由于我们的目标工程是空调app,在用户调节风向时的回调频率相当高,而自动扫风模式下,底层上传的数据频率也相当高,所以不适合到主线程中操作这么多的数据,我们用协程,配合Default调度器来处理这种CPU密集型的任务。两条链路,用户手指的拖动操作时,Unity反射回调的线程本身都是工作线程了,所以我们在使用自定义的接口回调到View类的时候,使用MainScope.launch包一层,确保是到主线程更新我们的UI。而自动扫风模式从域控制器接收到风口点击的坐标值时,我们拿到数据后给Unity下发信号,更新动效的指向位置。可以使用协程上下文切换,withContext(Dispatcher.Default)将其切到工作线程里发送给Unity。
遇到的问题 Unity方给的aar里的基类Activity适用与绝大多数的普通应用,但是我这里空调app的定位是一个高层级的悬浮窗,我的工程里压根就没有Activity。
这个时候我们用不上他们定义的 UnityPlayerActivity ,只能使用原生Raw的UnityPlayer,自己管理其创建,销毁,resume和pause。这里需要注意的是,UnityPlayer的创建需要传一个Context上下文,而应用里又没有Activity类型的Context,故只能使用非Activity类型的Context,在实践中发现,这个UnityPlayer的实例必须是我们的应用拿到可用的窗口 token 句柄之后,才能被成功创建,否则就会报错。
所以正确的创建与初始化顺序是先使用WindowManager添加一个xml布局inflate来的ViewGroup,在其onAttachToWindow的方法回调之后,再创建UnityPlayer的实例,并添加到这个ViewGroup的布局中去,调用其resume方法。
这样添加的UnityPlayer有一个无法解决的黑屏问题,因为Unity的渲染加载至少都需要4,5秒,期间我们只能在更上层的View里设置静态背景图覆盖上去,等Unity加载完毕,发送ready的回调之后,我们移除掉这个占位的静态图,展示Unity动效的界面。这也是进程隔离的方案的一个很棘手的问题。我的解决方案是在开机的时候往屏幕外添加一个View专门来初始化加载Unity,加载完毕后,再将UnityPlayer给从里面remove掉,重新添加到实际的要展示的窗口中去,这样打开界面的时候可以略去加载的耗时,稍微减少页面僵直的时间。
单进程-URAS(Render As Service) 一个渲染服务 Service 支持多个 Client APP 运行,且每个 Client APP 相互独立、互不干扰、可自更新。
仅需一个 Service,多个工程共用同一个 Service,每个工程均正常运行且互不干扰 一个新 Client 集成到已运行 Service 中,新 Client 可正常运行和渲染,已运行的 Client 和 Service 均不受干扰。 已运行的 Service 和 Client 中,关闭一个 Client,不影响其他 Client 和 Service 的正常运行 每个 Client 可通过 OTA 单独更新,更新后可正常运行,且不影响其他 Client 和 Service Unity Rendering as Service(简称URAS) 的渲染方案是团结引擎特有的,无需在多个安卓应用中集成多个Unity 3D player,而是后台运行,前端应用可直接调用,节省系统资源,更适合多应用动效一镜到底的设计。
相较进程隔离方案的优势 这个方案是在UAAL方案的基础上升级的,所以有一些前期工作是重复的,不作重复的阐述。
它是将要显示的几个Unity引擎都打包到同一个Server服务端去统一管控。其实服务端的apk打包也是拿到Unity提供的服务端AAR打进一个空工程,内部逻辑也隐藏到了AAR中。服务端和客户端的通信采用我们熟知的AIDL接口来实现。而且这个服务端我们需要设置为persistent应用,使其能开机自启,自动执行渲染等工作,其他应用有显示需求可以秒开,并且长时间不显示也不会自己回收资源了,客户端的黑屏问题也可以解决了。
相比于UAAL方案,客户端需要集成的是一个体积很小的Client.aar,对于客户端apk的体积控制是有优势的。
URAS渲染原理 BufferQueue BufferQueue 机制 是 Android 图形系统中最核心、最重要的底层机制之一,它实现了图形数据的生产者(Producer)和消费者(Consumer)之间的高效、零拷贝 的通信。
它可以将一个组件(生产者 )生成的图形数据缓冲区,安全、高效地传递给另一个组件(消费者 )以供显示或进一步处理。 关键点是零拷贝,数据在生产者和消费者之间是通过内存句柄 (Handle) 传递的,而不是通过 CPU 复制实际的像素数据。这对于高性能的图形(如视频、3D)渲染至关重要。
BufferQueue 本质上是一个队列,但它管理的不是数据本身,而是图形缓冲区 (Graphic Buffers) 的句柄。
生产者调用 dequeueBuffer() 从队列中获取一个空闲 的缓冲区。将图形数据(例如一帧画面)绘制到这个缓冲区中。调用 queueBuffer():将填充好的缓冲区排入队列 ,通知消费者数据已准备好。 消费者是需要使用图形数据进行显示的组件,调用 acquireBuffer(),从队列中获取 一个生产者刚刚填充好的缓冲区。使用缓冲区中的数据进行合成、显示或进一步处理。调用 releaseBuffer() 将缓冲区释放 回队列,使其再次变为空闲 ,供生产者重复使用。 BufferQueue 的工作流程 初始化: 生产者和消费者通过 Binder IPC 建立连接,并协商 BufferQueue 的参数(例如最大缓冲区数量)。BufferQueue 会根据需求,通过 Gralloc生产者获取缓冲区: 生产者调用 dequeueBuffer(),从 BufferQueue 中拿到一个空闲的缓冲区句柄(ID = n)。生产者渲染: 生产者(通常是 GPU)将一帧画面渲染到缓冲区 n 中。生产者入队: 生产者调用 queueBuffer(),将缓冲区 n 放入待消费队列。消费者通知: BufferQueue 通知消费者(例如 SurfaceFlinger),新数据已到达。消费者获取缓冲区: 消费者调用 acquireBuffer(),从队列中取出缓冲区 n 的句柄。消费者处理/显示: 消费者(例如 SurfaceFlinger)使用缓冲区 n 的数据进行合成,最终交给硬件显示。消费者释放: 消费者完成对缓冲区 n 的使用后,调用 releaseBuffer(),将缓冲区 n 返回给空闲列表。循环: 缓冲区 n 再次变为“空闲”,生产者可以再次获取并重复使用。跨进程渲染 使用 Surface / SurfaceTexture / SurfaceView,这是Android中实现跨进程图形数据共享和渲染的最核心机制,尤其适用于高性能的3D渲染(如游戏、AR/VR、视频播放、复杂图形引擎等)。
Android的图形系统基于 BufferQueueSurface 本质上就是 BufferQueue 的生产者(Producer)端。当进程B将渲染好的图形数据(例如,一个OpenGL ES的帧)放入 BufferQueue 后,进程A的 SurfaceView 或 TextureView(它们是 BufferQueue 的消费者 Consumer)就可以从队列中取出并直接显示。
当客户端的 SurfaceView 创建时,会向系统请求一个 Surface 对象,这个 Surface 就关联了一个 BufferQueue。通过 Binder IPC 将 Surface 对象的句柄(或一个包装了 Surface 的特殊对象)传递给Unity服务端。
服务端在接收到 Surface 句柄后,将其作为 渲染目标 (例如,作为 OpenGL ES 的 EGL 窗口)。将图形数据(如 glSwapBuffers())渲染到这个 Surface 关联的 BufferQueue 中。一旦服务端将渲染数据提交到 BufferQueue,系统会自动将这些数据交给客户端的 SurfaceView 进行合成和显示,绕过了传统的Android View绘制流程 (即 onDraw)。
这种渲染方式性能极高,因为数据传输是在底层图形缓冲区级别完成,无需CPU进行像素拷贝,适用于视频流、3D渲染等对帧率要求高的场景。
也可以使用 TextureView + SurfaceTexture + Binder IPC,这是一种特殊的组合,TextureView 将内容渲染到一个 SurfaceTexture 上,而 SurfaceTexture 也可以跨进程共享,通常用于更灵活的纹理操作(例如对渲染内容进行旋转、缩放等 View 级别的变换)。它的底层原理与 SurfaceView 类似,也是基于 BufferQueue 。
URAS集成与使用方式 我们只需要在 gradle 里引入这个客户端aar。在gradle sync之后,将远程的 UnityView 添加到自己的布局中去,配置好display参数(用来给服务端区分是哪个引擎的内容),并指定服务端的包名。承载的View类型有 SurfaceView 和 TextureView 两种,而我的应用界面因为是一个悬浮窗口,设计有进出场的渐隐渐出动效,而 SurfaceView 不可以线性地设置alpha动画,所以选取 TextureView 来当作容器。
<com.unity3d.renderservice.client.TuanjieView
android:id= "@+id/unityview"
android:layout_width= "match_parent"
android:layout_height= "match_parent"
app:tuanjieDisplay= "2"
app:tuanjieServicePkgName= "com.tuanjie.renderservice"
app:tuanjieViewType= "TextureView" />
剩余的代码逻辑仅仅是服务端 Service 的启动,添加服务连接的回调,消息回调。由于服务端为若干个 Client 的公共引擎,所以连 resume 和 pause 都不需要处理,因为这两个操作会对所有的客户端都生效。我们只需要确保启动服务,并使用正确的display即可,面板退到后台可以使用 setVisbility 来控制其显示隐藏。
除此之外,我们的通信工具类, UnityMessageHelper 还需要实现两个接口,一个服务连接状态接口,一个业务数据的消息回调接口,代码如下:
object UnityMessageHelper : TuanjieRenderService . Callback , SendMessageCallback {
override fun onServiceConnected () {
LogUtils . w ( TAG , "onUnityRenderServiceConnected" )
}
override fun onServiceDisconnected () {
LogUtils . w ( TAG , "onUnityRenderServiceDisConnected" )
.. .
}
override fun onServiceStartRenderView ( p0 : Int ) {
LogUtils . i ( TAG , "onServiceStartRenderView" )
}
override fun onClientRecvMessage ( message : String ?) = null
// 服务端的消息回调
override fun onClientRecvMessageWithNoRet ( msg : String ?) {
// 回调消息的解析
}
}
可以说URAS方案由于其统一管控,一对多的特点,在性能和客户端的易集成性方面,是优于UAAL方案的。另外,还可以从架构层面上,联动更多的动效使用模块,实现一镜到底的丝滑转场。
Pagination © 2024. All rights reserved. LICENSE | NOTICE | CHANGELOG
Powered by Hydejack v9.2.1