【Android进阶】JVM&DVM&ART虚拟机对比

本文介绍了JVM虚拟机,Dalvik虚拟机还有ART虚拟机三者之间不同特点的对比
去年通读了深入理解Java虚拟机,对JVM的一系列特性有了系统的了解,然而作为Android开发,却还没有对Android平台特有的两代虚拟机做更为细致的学习,属实有点说不过去。在车机Android系统app的开发中,几乎涉及不到apk的动态安装卸载,一般是参与系统集成编译完就发布镜像,烧写后一直运行。所以对此专题,了解甚少。
JVM跨平台特性的原理是 字节码 ,字节码是一种中间代码,它是一种 面向虚拟机 的代码,而不是面向硬件的代码。每个JRE编译的时候针对每个平台编译,因此下载JRE(JVM、Java核心类库和支持文件)的时候是分平台的,JVM的作用是把平台无关的.class里面的字节码翻译成平台相关的机器码,来实现跨平台。
为何Android不直接使用JVM
从问题寻找答案,总是一个有效的学习方法,为什么Android平台当年不直接使用JVM作为硬件抽象之上的虚拟机供应用运行呢?
在早期(Android 4.4之前),Android使用的是Dalvik虚拟机,这是谷歌为安卓系统专门设计和开发的一款虚拟机,主要用于在资源受限的移动设备上高效运行应用程序。不直接使用JVM,主要有以下几个原因:
- 资源限制: 早期的移动设备内存和存储空间都很有限。 JVM需要较大的内存和存储空间 ,不适合资源受限的移动设备。Dalvik虚拟机针对移动设备进行了优化,更加轻量级。
- 性能考虑: JVM主要针对服务器和桌面环境优化,移动设备上,可能没有桌面和服务器上那么强大的性能,故JVM在移动设备上性能表现可能不佳。 Dalvik虚拟机采用了寄存器架构 ,相比 JVM的栈架构 在移动设备上有更好的性能表现。
- 许可证问题: JVM受Oracle公司的许可证限制,Android为了避免潜在的法律风险,选择开发自己的虚拟机。这也是一个为人乐道的历史原因。
- 定制化需求: Android需要一个 更加定制化的解决方案 来满足移动平台的特殊需求,如电源管理、内存管理等。Dalvik虚拟机可以更好地与Android系统集成。
- 字节码格式: Dalvik使用的.dex格式比Java的.class文件更紧凑,更适合移动设备有限的存储空间。
- 多进程架构: Android的应用运行在独立的进程中,每个进程有自己的Dalvik虚拟机实例,这种架构更适合移动操作系统的需求。
- 安全性考虑: Dalvik虚拟机在安全性方面也有一定的优势,如对内存访问的控制和对异常的处理。
事实证明,Android使用Dalvik虚拟机的选择是正确的,如果直接使用JVM,在以上这些因素的影响下,Android系统可能真的发展不起来。
Dalvik虚拟机
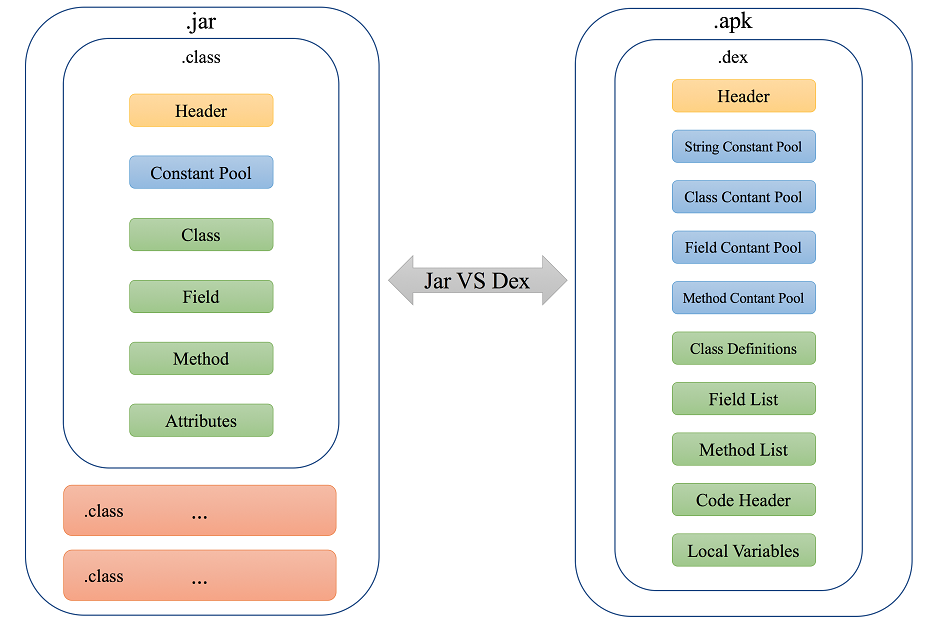
JVM虚拟机里面,解释运行的是class文件,而在Dalvik虚拟机里面,解释运行的是dex(即“Dalvik Executable”)文件。
dex文件
回顾一下class文件的组成:
- 魔数:用于标识文件类型,通常为0xCAFEBABE。
- 版本号:用于标识class文件的版本号,包括主版本号和次版本号。
- 常量池:用于存储常量,包括字符串、类名、字段名、方法名等。
- 访问标志:用于标识类的访问权限,如public、final等。
- 类信息:包括类名、父类名、接口名等。
- 字段信息:包括字段名、字段类型、访问标志等。
- 方法信息:包括方法名、方法类型、访问标志等。
- 属性信息:用于存储类的附加信息,如注解、泛型信息等。
为了减小执行文件的体积,安卓的Dalvik虚拟机选择dex文件来替代class文件。
class文件合并为dex文件这个过程,主要由 Android SDK 中的dx工具(在较新的Android Gradle插件中被d8工具替代)完成。通过这个转换过程,多个class文件被合并转换成一个更紧凑、更适合移动设备的dex文件,从而减小了应用的大小,提高了加载和执行效率。
class文件转换成dex文件的过程称为”dexing”,主要通过以下步骤完成:
- 收集所有的class文件: 首先,系统会收集所有需要转换的class文件。这些文件通常来自于你的Java源代码编译后的结果,以及你项目中使用的库。
- 解析class文件: 每个class文件都会被解析,提取其中的常量池、方法、字段等信息。
- 合并常量池: dex格式的一个主要优化是合并所有class文件的常量池。相同的字符串、类型和方法引用只会在dex文件中出现一次,大大减少了重复数据。
- 重新编码数据: class文件中的数据会被重新编码为dex格式。这包括将Java字节码转换为Dalvik字节码,以及重新组织类、方法和字段的结构。
- 优化: 在转换过程中,还会进行一些优化,例如删除未使用的字段和方法,内联一些简单的方法调用等。
- 生成dex文件: 最后,所有处理后的数据被写入到一个或多个dex文件中。一个dex文件可以包含多个class的内容。
- 验证: 生成的dex文件会经过验证,确保其格式正确,可以被Dalvik虚拟机(或ART运行时)正确加载和执行。
二者格式对比如下:
JVM和Dalvik运行流程
JVM基于栈操作
每个Java线程都有自己的 Java虚拟机栈 ,用于存储方法调用的信息,包括局部变量、部分结果和方法调用/返回等。
当一个方法被调用时,会在栈上创建一个新的 栈帧(Stack Frame) 。栈帧包含局部变量表,操作数栈,指向运行时常量池的引用,方法返回地址等信息。
JVM使用基于栈的指令集,这意味着大多数操作都是通过压栈和出栈来完成的。例如:
int foo(int a, int b) {
return (a + b) * (a - b);
}
转换后的字节码指令为:
int foo(int, int);
Code:
0: iload_1 // 将局部变量a压入栈
1: iload_2 // 将局部变量b压入栈
2: iadd // 弹出栈顶的两个元素,相加,结果压入栈
3: iload_1 // 将局部变量a压入栈
4: iload_2 // 将局部变量b压入栈
5: isub // 弹出栈顶的两个元素,相减,结果压入栈
6: imul // 弹出栈顶的两个元素,相乘,结果压入栈
7: ireturn // 返回栈顶元素作为方法结果
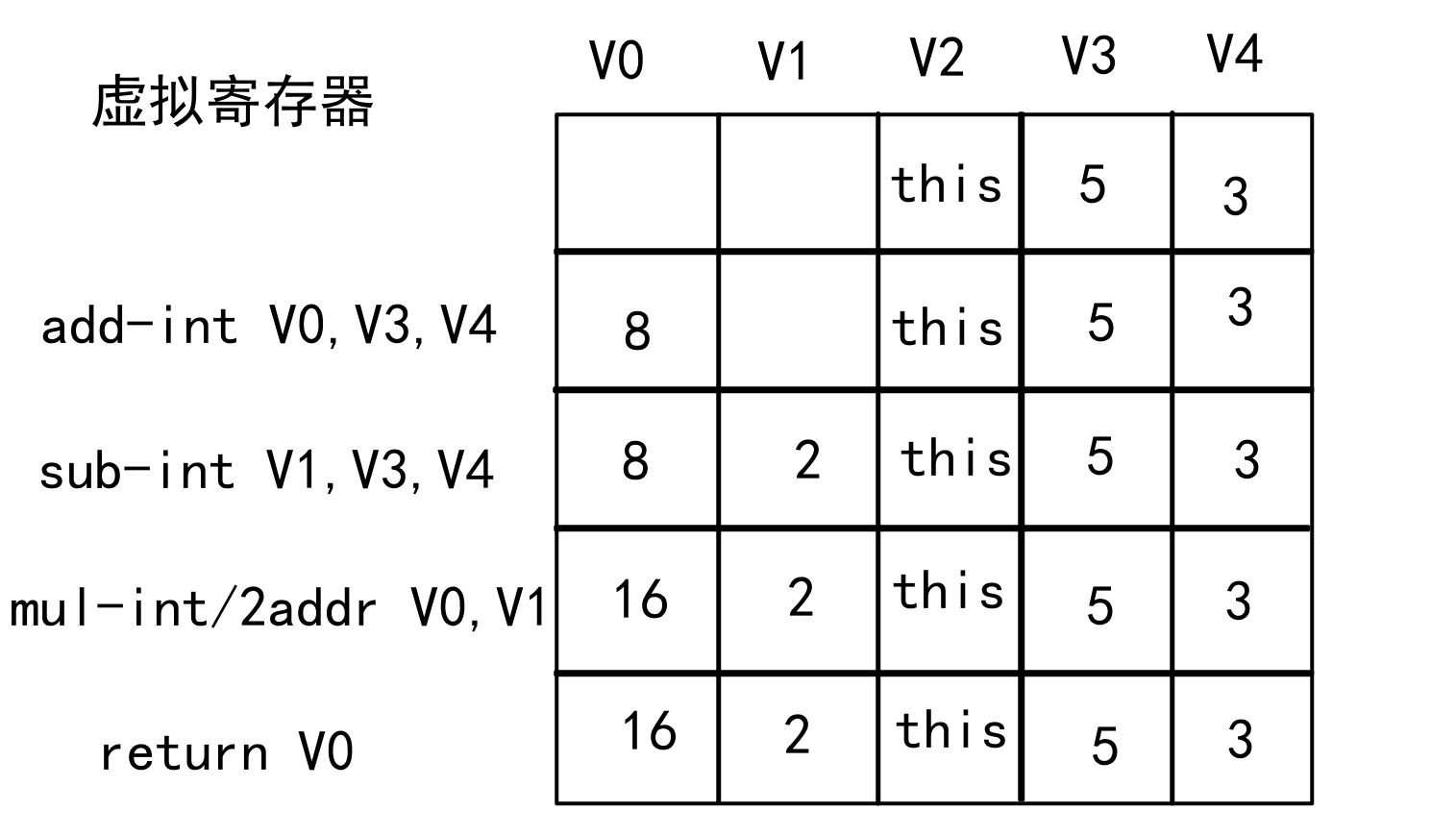
Dalvik基于寄存器操作
在Dalvik虚拟机中,寄存器是虚拟的,不同于物理CPU中的硬件寄存器。这些虚拟寄存器实际上是存储在内存中的,用于存储局部变量、方法参数、中间计算结果等。
Dalvik虚拟机使用基于寄存器的指令集,这意味着大多数操作都是通过寄存器来完成的。还是上面同样的计算方法:
int foo(int a, int b) {
return (a + b) * (a - b);
}
转换后的字节码指令
0000: add-int v0, v3, v4
0002: sub-int v1, v3, v4
0004: mul-int/2addr v0, v1
0005: return v0
add-int是一个需要两个操作数的指令,其指令格式是:add-int vAA, vBB, vCC。其指令的运算过程,是将后面两个寄存器中的值进行(加)运算,然后将结果放在(第一个)目标寄存器中。其余类似
计算流程如下图:
内存对比
一个JVM进程所处的Java虚拟机的内存可以用下面这张热门图片概括:
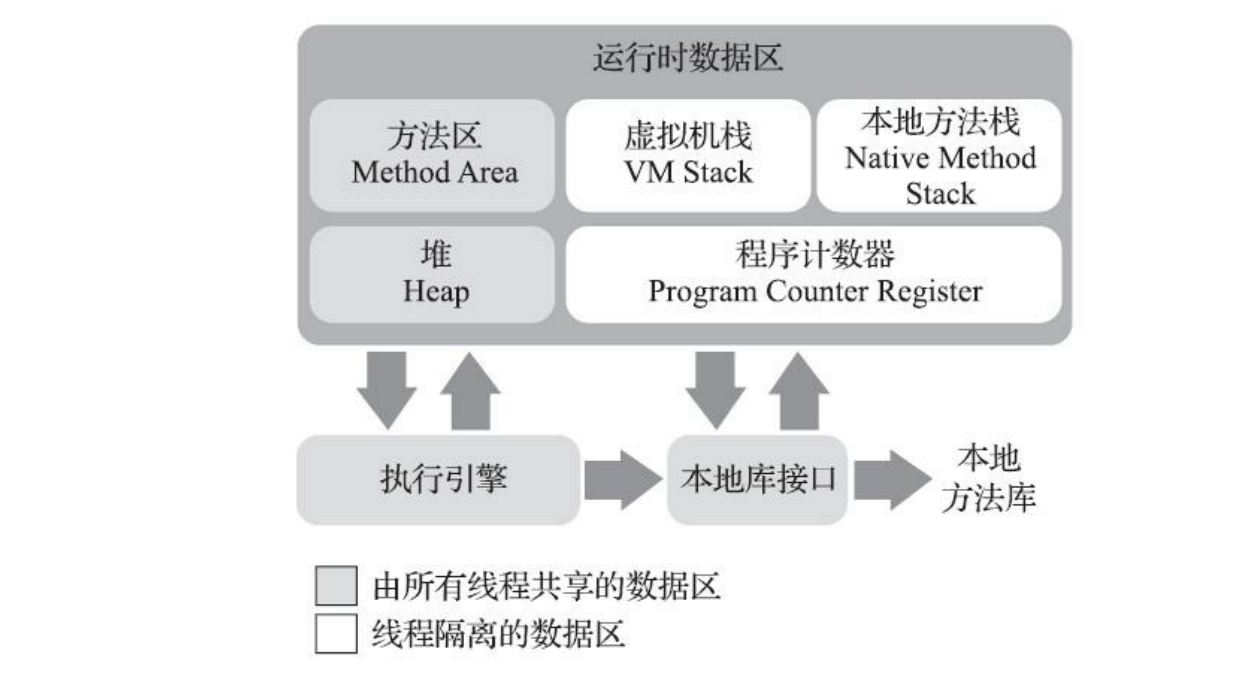
Dalvik虚拟机的内存模型略有不同。
Dalvik内存模型
Dalvik虚拟机用来分配对象的堆划分为两部分,一部分叫做Active Heap,另一部分叫做Zygote Heap。
Android系统启动后,会有一个Zygote进程创建第一个Dalvik虚拟机,它只维护了一个堆。以后启动的所有应用程序进程是被Zygote进程fork出来的,并都持有一个自己的Dalvik虚拟机。在创建应用程序的过程中,Dalvik虚拟机采用 COW策略 复制Zygote进程的地址空间。
COW策略,即Copy-On-Write,一开始的时候(未复制Zygote进程的地址空间的时候),应用程序进程和Zygote进程共享了同一个用来分配对象的堆。当Zygote进程或者应用程序进程对该堆 进行写操作时,内核就会执行真正的拷贝操作 ,使得Zygote进程和应用程序进程分别拥有自己的一份拷贝,这就是所谓的COW。因为copy是十分耗时的,所以必须尽量避免copy或者尽量少的copy。
为了实现这个目的,当创建第一个应用程序进程时,会将已经使用了的那部分堆内存划分为一部分作为 Zygote堆 ,还没有使用的堆内存划分为另外一部分称为 Active堆 。
Zygote Heap 堆内存中, 有一部分区域的内存是只读的, 如系统相关的库, 共享库, 预置库, 这些内存数据所有应用公用。这些预加载的类、资源和对象可以在Zygote进程和应用程序进程中做到 长期共享 。这样既能减少拷贝操作,还能减少对内存的需求。
这样只需把zygote堆中的内容复制给应用程序进程就可以了。以后无论是Zygote进程,还是应用程序进程,当 它们需要分配对象的时候,都在Active堆上进行 。这样就可以使得Zygote堆尽可能少地被执行写操作,因而就可以减少执行写时拷贝的操作。
DVM特点内存模型图
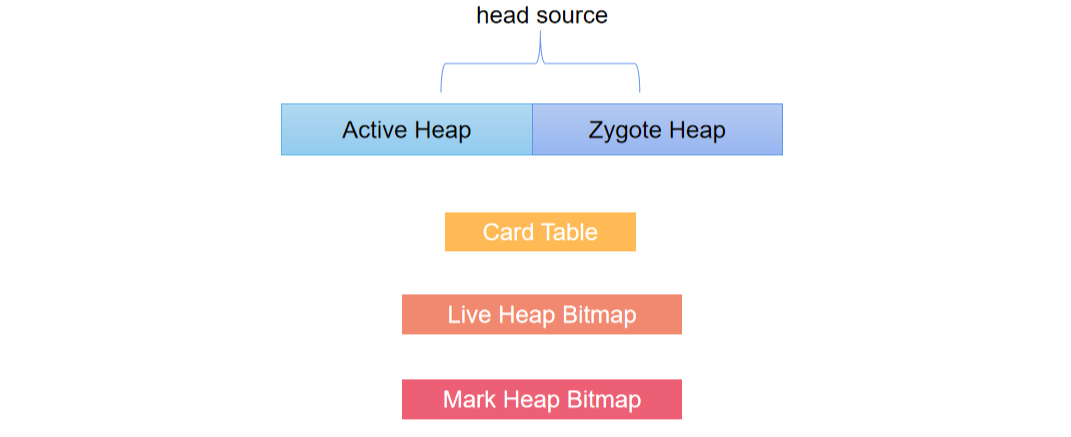
Card Table:用于 DVM Concurrtent GC,当第一次进行垃圾标记后,记录垃圾信息。 Heap Bitmap:分为两个,Live Bitmap 用来记录上次 GC 存活的对象,Mark Bitmap 用来记录这次 GC 存活的对象。 Mark Stack:在 GC 的标记阶段使用的,用来遍历存活的对象。
DVM垃圾回收
Dalvik垃圾收集主要是 mark-sweep 算法实现的。 mark-sweep 算法分为两个阶段,即mark阶段和sweep阶段。Dalvik的GC过程,可以大致归纳为如下过程:
- 整个标记开始之前,首先遍历一次堆地址空间。
- Mark阶段: 从对象的根集对象开始标记引用对象。
- Sweep阶段: 回收没有被标记的对象占用的内存。
Mark标记阶段
这里涉及到的一个核心概念就是我们怎么标记对象有没有被引用的,换句说就是通过什么数据结构来描述对象有没有被引用。
事实上,总共使用了两个bitmap, 一个是Live bitmap,一个是Mark bitmap。 这两个bitmap里的每一位对应一个对象,某个对象被引用了,就标1,没引用就标0。
Livebitmap主要用来标记上一次GC时被引用的对象,也就是那些没有被回收的对象,而markbitmap主要用来标记本轮 当前GC有被引用 的对象。因此那些 在Live bitmap中标为1,而在mark bitmap中标为0 的对象,就是需要回收的对象。mark bitmap实际上就是live bitmap的一个子集。
标记的STW现象
在mark阶段,要求除了GC线程外,其他的线程都需要停止,否则就可能不能正确的标记每个对象,因为可能刚标记完又被修改引用等等情况的发生。这种现象叫stop the world,会导致该应用程序中止执行,
在整个mark开始时,GC会先不得不中止一次程序的运行,从而对堆地址空间进行一次遍历,这次遍历可以获得每一个应用程序分配的对象,就能确认每个对象在内存堆中的大小、起始地址等等信息。 这个停顿在dalvik里是不得不做的事情 ,每次GC都会必须触发一次堆地址空间的遍历引起的停顿。
为了减少stop the world带来的负面影响,dalvik的GC采用了分阶段并行标记Concurrent的方案。分为了两个子阶段:
- 第一个阶段是标记根集对象,这个阶段是不允许GC线程之外的线程运行的。
- 第二个阶段是标记根集对象引用的对象,允许其他线程运行。
所谓根集对象,就是指在GC线程开始的时候,那些 被全局变量、栈变量和寄存器等引用的对象 。通过这些根集变量,可以顺着它们找到其余的被引用变量,其实这就是可达性分析。比如说,假如发现了一个栈变量引用一个对象,而这个对象又引用了另外一个对象,那这个被引用的对象也会被标记为正在使用。这个标记“被根集对象引用的对象”的过程就是第二个子阶段。
并行策略很容易想到的一个问题,就是在第二个阶段执行的过程中,如果某个运行的线程修改了一个对象了内容,由于很有可能引用了新的对象,所以这个对象也必须要记录起来。否则会发生被引用对象还在使用却被回收。
这种情况出现在只进行部分GC的情况,这时候 Card Table 的作用就是用来记录非GC堆对象对GC的堆对象的引用。
Dalvik的堆空间,分为zygote heap 和 active heap。前者主要存放一些在zygote时就分配的对象,后者主要用于之后新分配的空间,
Dalvik虚拟机进行部分垃圾收集时,实际上就是 只收集在Active heap上分配的对象 。Card Table就是用来记录在Zygote heap上分配的对象 在GC执行过程中 对在Active heap上分配的对象的引用。
Card table由一系列card组成,一个card实际上就是一个字节,它的值分为clean和dirty两种。如果一个Card的值是 CLEAN ,就表示与它对应的对象在Mark第二个子阶段 没有被程序修改过 。如果一个Card的值是 DIRTY ,就意味着 被程序修改过 。对于这些被修改过的对象。需要在Mark第二子阶段结束之后,再次禁止GC线程之外的其它线程执行,以便GC线程再次根据Card Table记录的信息对被修改过的对象引用的其它对象 进行重新标记 。这个二次标记的过程就是非并行的,确保本次Mark流程的标记都是准确的。
由于Mark 第二子阶段被修改的对象不会很多 ,这样就可以保证第二次子阶段结束后,再次执行标记对象的过程是很快的,因而此时对程序造成的停顿非常小。
在mark阶段,主要是标记的第二个子阶段,dalvik是采用递归的方式来遍历标记对象。但是这个递归并不是像一般的递归一样借助一个递归函数来实现,而是使用一个叫做mark stack的栈空间实现。大致过程是:一个被引用的对象在标记的过程中,先被标记,然后放在栈中,等该对象的父对象全部被标记完成后,依次弹出栈中的每一个对象,并标记其引用,然后把其引用再丢到栈中。
采用mark stack栈而不是函数递归的好处是:首先可以 采用并行的方式 来做,将栈进行分段,多个线程共同将栈中的数据递归标记。其次,可以 避免函数堆栈占用较深 。
至此,差不多介绍了dalvik的GC的mark阶段的过程。我们可以发现,在mark阶段,一共有3次停顿:
- 一次是在标记开始前遍历堆地址空间的停顿
- 一次是在标记的第一个阶段标记所有根集对象时的停顿
- 还有一次是在标记的第二个子阶段完成后处理card table时的停顿。
这3次停顿的时间直接影响了android上应用程序的表现,尤其是 卡顿现象 ,因此ART在这块有重点改进,等会介绍ART上的过程。
Sweep清除阶段
其实sweep阶段就很简单了,在mark阶段已经提到过,GC时回收的是在live bitmap里标为1而在mark bitmap里标为0的对象。
而这个mark bitmap实际上就是live bitmap的子集,因此在sweep阶段只需要处理二者的差集即可,在回收掉相应的对象后,只需要 再把live bitmap和mark bitmap的指针调换一下 ,即这次的mark bitmap作为下一次GC时的live bitmap,然后清空live bitmap,等到下一次GC流程开始,用来标记下一次的可回收对象。
Sweep的过程,在ART里没什么太大变化,而由于在android 5.0源码中已经去掉了dalvik,这环节的具体解释就在ART部分分析,但是实际上在sweep阶段dalvik和ART二者没有太大区别,因为主要只是处理相应的bitmap的对应的对象的内存,ART也没有什么优化的地方。
Art虚拟机
Art虚拟机是在Android 4.4就引入了,这个版本上留了一个开关供调试选择,其实就是一个标记位,手动开关更改这个值,重启系统之后就是使用上次选择的新的虚拟机方案。5.0版本之后,彻底移除了Dalvik虚拟机,完全使用ART虚拟机。
Dalvik之所以要被ART替代包含下面几个原因:
- Dalvik是为32位设计的,不适用于64位CPU。
- 单纯的字节码解释加JIT编译的执行方式,性能要弱于本地机器码的执行。
- 无论是解释执行还是JIT编译都是单次运行过程中发生,每运行一次都可能需要重新做这些工作,这样做太浪费资源。
- 原先的垃圾回收机制不够好,会导致卡顿。
先接上文介绍下Art的垃圾回收策略,再介绍JIT,AOT等编译流程。
垃圾回收
ART同样采用了自动GC的策略,并且同样不可避免的使用到了经典的mark-sweep算法。
Art虚拟机的标记清除垃圾回收,根据轻重程度不同,分为三类, sticky,partial,full 。可以看到,ART里的GC的改进,首先就是收集器的多样化。 而根据GC时是否暂停所有的线程分类并行和非并行两类。所以在ART中一共定义了6个mark-sweep收集器。参看art/runtime/gc/heap.cc可见。
根据不同情况,ART会选择不同的GC collector进行GC工作。其实最复杂的就是 Concurrent Mark Sweep 收集器 。如果理解了最复杂的Concurrent Mark Sweep算法,其他5种GC收集器的工作原理就也理解了。同样的,垃圾回收工作从整体上可以划分两个大的阶段:Mark 和 Sweep。
Mark阶段
最重要的提升就是这个阶段 只暂停线程一次。将dalvik的三次缩短到一次 ,得到了较大的优化。和dalvik一样,标记阶段完成的工作也是完成从根集对象出发,进行递归遍历标记被引用的对象的整个过程。用到的主要的数据结构也是同样的 live bitmap和mark bitmap,以及card table和在递归遍历标记时用到的mark stack。
一个被引用的对象在标记的过程中先被标记,然后存入mark stack中,等待该对象的父对象全部被标记完成,再依次弹出栈中每一个对象然后,标记这个对象的引用,再把引用存入mark stack,重复这个过程直至整个栈为空。这个过程对mark stack的操作使用以及递归的方法和dalvik的递归过程是一样的。
但是在dalvik小节里提到了,在标记时mark阶段划分成了两个阶段,第一小阶段是禁止其他线程执行的,在mark两个阶段完成后处理card table时也是禁止其他线程执行的。
在ART里做出了改变,即 先Concurrent标记两遍 ,也就是说两个子阶段都可以允许其他线程运行了。然后 再Non-Concurrent标记一遍 。这样就大大缩短了dalvik里的第二次停顿的带来的卡顿时间。这个改进非常重要。
allocation stack
在标记开始阶段,有别于dalvik的要暂停所有线程 进行堆地址空间的遍历 来确定所有的对象的大小,地址信息。ART去掉了这个过程,替代的是 增加了一个叫作allocation stack结构 ,所有新分配的对象的信息会记录到allocation stack。
然后在Mark的时候,再在Live Bitmap中打上live的标记。Allocation stack和live stack其实是一个工作栈和备份栈。当在GC的时候,需要处理allocation stack,那么会把两个stack互换。新分配的对象会压到备份栈中,这个时候备份栈就当作新的工作栈。之前的allocation stack就当作本轮gc的 所有堆对象的记录栈 。这样一来,dalvik在每一次GC时产生的第一次停顿就完全消除了,从而产生了巨大的性能提升。
Live Stack和Live Bitmap名称很像,但其实是完全不同的东西。Live Bitmap用于记录当前VM进程中所有存在的对象,包括未标记和已标记的对象。与Mark Bitmap配合用于确定可回收的垃圾对象。Live Stack是allocation stack的备份栈,主要用于优化GC性能,快速访问新分配对象。
关于card table,和dalvik依旧类似,每个card用一个字节来描述。ART里多了一个结构ModUnionTable,是和card table配合使用的。
前面在ConCurrent的情况下,经过了两轮的递归遍历,基本上已经标记扫描的差不多了。但由于应用程序主线程是在一直运行的,不可避免地会修改之前已经mark过的bitmap。因此,需要 第三遍扫描,这次就需要在stop the world的情况下进行遍历 ,主要过程也就是上文提到的对card table的操作等等。
这次遍历扫的时候,除了重新标记根集以外,还需要扫描card table中Dirty Card的部分。关于live bitmap和mark bitmap的使用,ART和dalvik在这一块没有多少区别。Live Bitmap记录了当前存在于VM进程中所有的未标记的对象和标记过的对象。Mark Bitmap经过了Mark 的过程,记录了当前VM进程中所有被引用的object。Live Bitmap和Mark Bitmap中间的差集,便是所有为被系统引用的object,即是可以回收的垃圾了。
经过了前面3次扫描以及Mark,我们的mark bitmap已经很完整了。但是值得注意的是,由于Sweep的操作是对应于live bitmap,即那些在live bitmap中标记过,却在mark bitmap中没有标记的对象。也就是说,mark bitmap中标记的对象是live bitmap中标记对象的子集。
但目前为止live bitmap标记的对象还不是最全,因为前文有提到过,为了消除dalvik的第一次停顿,在扫描期间,Art计入了allocation stack中的对象,还没有标记。Allocation stack先“搁置”起来不让后面的主线程使用,启用备份的的live stack。
void Heap::SwapStacks() {
allocation_stack_.swap(live_stack_);
}
即在下一次垃圾回收开始时,将allocation stack和live stack进行交换。确保本轮处理的对象信息是最新的。
Sweep阶段
在完成了mark阶段后,对应已经标好的live bitmap和mark bitmap,需要进入sweep来回收相应的垃圾。Sweep阶段就是把那些二者的差集所占用的内存回收掉。
Finish阶段
不同于Dalvik,ART中可以归纳为有一个第三个阶段,就是类似的一个finish阶段。
void MarkSweep::FinishPhase() {
base::TimingLogger::ScopedSplit split("FinishPhase", &timings_);
// Can't enqueue references if we hold the mutator lock.
Object* cleared_references = GetClearedReferences();
Heap* heap = GetHeap();
timings_.NewSplit("EnqueueClearedReferences");
heap->EnqueueClearedReferences(&cleared_references);
......
}
因为之前说过mark bitmap是live bitmap的一个子集,而mark bitmap中包含了所有的正在被引用的的非垃圾的对象,因此需要交换mark bitmap和live bitmap的指针,使mark bitmap作为下一次GC的live bitmap,并且重置新的mark bitmap。
//Clear all of the spaces' mark bitmaps.
for (const auto& space : GetHeap()->GetContinuousSpaces()) {
if (space->GetGcRetentionPolicy() != space::kGcRetentionPolicyNeverCollect) {
space->GetMarkBitmap()->Clear();
}
}
mark_stack_->Reset();
另外,需要指出的是,由于mark stack的目的是为了方便标记的递归,所以在Finish阶段,也需要把mark stack给清空,至于实现可以看以上代码行。
sticky mark sweep收集器
其实sticky mark sweep的主要步骤也是和mark sweep的过程大致一样,主要完成三次并发的mark阶段,然后进行一个stop the world的非并发进行一次对堆对象的遍历。
void StickyMarkSweep::BindBitmaps() {
PartialMarkSweep::BindBitmaps();
WriterMutexLock mu(Thread::Current(), *Locks::heap_bitmap_lock_);
// For sticky GC, we want to bind the bitmaps of all spaces as the allocation stack lets us
// know what was allocated since the last GC. A side-effect of binding the allocation space mark
// and live bitmap is that marking the objects will place them in the live bitmap.
for (const auto& space : GetHeap()->GetContinuousSpaces()) {
if (space->GetGcRetentionPolicy() == space::kGcRetentionPolicyAlwaysCollect) {
BindLiveToMarkBitmap(space);
}
}
GetHeap()->GetLargeObjectsSpace()->CopyLiveToMarked();
}
但是可以通过实现方法发现,有一个 getGcRetenionPolicy ,获取的是一个枚举。
Sticky Mark Sweep 和 Full Mark Sweep 的主要区别为,Full Mark Sweep:回收整个堆内存空间。Sticky Mark Sweep:只回收 自上次 GC 以来新分配的对象和被修改过的对象所在的区域 。
只有符合总是收集的条件的,就把live bitmap和mark bitmap绑定起来。其余的过程和full是一样的。Sticky Mark sweep只扫描自从上次GC后被修改过的堆空间,并且也只回收自从上次GC后分配的空间。Sticky是只回收kGcRetentionPolicyAlwaysCollect的space。不回收其他两个,因此sticky的回收的力度是最小的。作为最全面的full mark sweep, 上面的三个策略都是会回收的。
partial mark sweep收集器
这是mark sweep收集器里使用的最少的GC收集策略,回收部分堆空间,通常包括年轻代和部分老年代。
按照官方文档,一般是使用sticky mark sweep较多。这里有一个概念就是吞吐率,即一次GC释放的字节数和GC持续的时间(秒)的比值。由于一般是sticky mark sweep进行GC,所以当上次GC的吞吐率小于同时的partial mark sweep的吞吐率时,就会把下次GC收集器从sticky变成partial。但是在partial执行一次GC后,就仍然会恢复到stick mark sweep收集器。
阅读源码发现,partial重写了父类的成员函数。
其实分析这些可以发现,从full mark sweep到partial mark sweep到stick mark sweep,GC的力度是越来越小的,因为 可以回收的越来越少 。之所以说回收力度大,就是指可以回收的space多,比如上图的partial, 是不回收 kGcRetentionPolicyFullCollect ,但是是会回收 kGcRetentionPolicyAlwaysCollect 的space的。
kGcRetentionPolicyFullCollect 表示该内存空间只在完全(Full)垃圾回收时才会被收集。kGcRetentionPolicyAlwaysCollect 表示该内存空间在每次垃圾回收时都会被收集,无论是哪种类型的 GC。
因此partial mark sweep每次执行一次GC后,就会自动切换到sticky策略,这样才能使系统更流畅得进行GC,并减少了GC带来的消耗。。
其他区别
其实观察space目录的文件可以发现,有一个新的概念就是large object space。事实上,ART还引入了一个新的的方法就是 大对象存储空间(large object space,LOS) ,这个空间与堆是相互独立的,但是仍然是驻留在应用程序的内存空间中。方便让ART可以更好的管理较大的对象,比如android里的bitmap。在dalvik中,在对堆空间进行分段时,占用空间较大的对象会带来一些问题。例如,在堆里分配一个 bitmap大对象时,由于占用空间较大,可能引起GC的启动次数也会增加,从而增加了开销 。有了LOS,GC收集器因堆空间分段而引发调用次数将会大大降低,这样垃圾收集器就能做更加合理的内存分配,从而降低运行时开销。
实验对比证明
老罗的博客里做的一些实验对比,证明了ART的GC的性能确实比dalvik的要好。
可以看到,在dalvik模式下刚启动支付宝的几秒内,触发了28次GC事件,总共停顿耗时4657ms。而在ART模式下,可以看到一共触发了2次GC事件,共耗时231.099ms。
在dalvik模式下刚启动百度地图的几秒内,触发了26次GC事件,总共停顿耗时5371ms。而在ART模式下,可以看到一共触发了4次GC事件,共耗时497.162ms。
对比可以看到,ART下的GC的性能明显提升了,几乎可以说是 提升了十倍左右 ,这是一个数量级的提升,GC环节带来的性能提升还是非常明显。
复制算法和标记清除算法哪个更好?
在垃圾回收中,复制算法和标记-清除算法的性能优劣取决于具体场景,两者的速度差异主要与堆内存状态、对象存活率以及硬件条件相关。
复制算法,对于 对象存活率低时(如新生代垃圾回收),只需复制少量存活对象,效率极高。复制后堆空间紧凑,无碎片,分配新对象只需移动指针。适合对延迟敏感的场景(如Young GC)。主要缺点有两个,一是内存浪费,需保留一半空间作为空闲区(空间利用率50%)。二是存活率高时性能骤降,若大部分对象存活(如老年代),复制开销比较大。
标记-清除算法,在对象存活率高时,只需标记并清理少量垃圾,无需复制存活对象。内存方面,无需预留空间,适合堆内存紧张的场景。缺点就是内存碎片化,可能导致分配大对象时触发压缩。还有两次遍历开销**:标记和清除阶段需扫描整个堆,存活对象多时较慢。
实际应用
现代GC通常混合使用多种算法以平衡吞吐量、延迟和空间开销。
- 新生代:使用复制算法(如Serial、Parallel Scavenge)。
- 老年代:使用标记-清除或标记-整理(如CMS、G1)。
若堆内存充足且对象存活率低,复制算法更快。若存活率高或内存有限,标记-清除更高效。
编译流程
JIT
JIT的全称是Just In Time,即 即时编译 ,它”即时”地进行编译,而不是在程序执行前完成所有编译工作。JIT是在运行时进行字节码到本地机器码的编译,这也是为什么Java普遍被认为效率比C++差的原因。无论是解释器的解释还是运行过程中即时编译,都比C++编译出的本地机器码执行多了一个耗费时间的过程。
AOT
AOT,即Ahead of Time,即 提前编译 。当APK 在安装的时候 ,系统会通过一个名称为dex2oat的工具 将APK中的dex文件编译成包含本地机器码的oat文件存放下来 。这样做之后,在程序执行的时候,就可以直接使用已经编译好的机器码以加快效率。
下图描述了Dalvik虚拟机与(Android 5.0上的)ART虚拟机在安装APK时的区别:
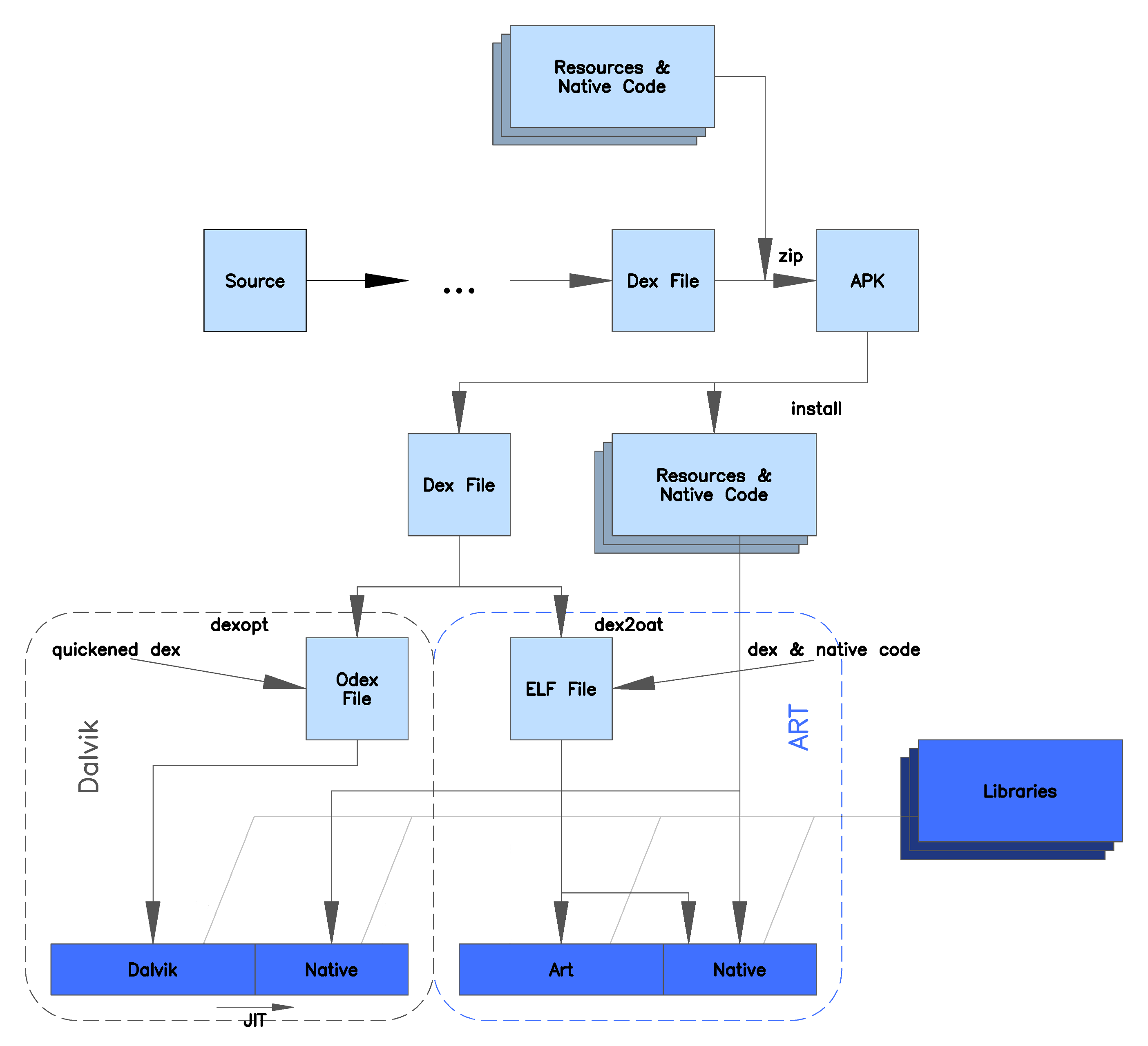
从这幅图中我们看到:
- 在Dalvik虚拟机上,APK中的Dex文件在安装时会被优化成odex文件,在运行时,会被JIT编译器编译成native代码。
- 在ART虚拟机上安装时,Dex文件会直接由dex2oat工具翻译成oat格式的文件,oat文件中既包含了dex文件中原先的内容,也包含了已经编译好的native代码。
纯 AOT 存在的问题
应用程序编译生成的OAT文件会引用Framework中的代码。一旦系统发生升级,Framework中的实现发生变化,就需要重新修正所有应用程序的OAT文件,使得它们的引用是正确的,这就需要 重新编译所有的应用 。
在应用安装的时候也是一样的问题,AOT会在安装时将应用的dex文件编译为oat文件存下来,让安装时间对比Dalvik虚拟机也更长。
第三个问题是,编译生成的Oat文件中,既包含了原先的Dex文件,又包含了编译后的机器代码。而实际上,对于用户来说,并非会用到应用程序中的所有功能,因此很多时候编译生成的机器码是一直用不到的。一份数据存在两份结果(尽管它们的格式是不一样的)显然是一种存储空间的浪费。
混合编译
在 Android 7.0 中,Google又为Android添加了即时 (JIT) 编译器。JIT和AOT的配合,是取两者之长,避两者之短:在APK安装时,并不是一次性将所有代码全部编译成机器码。而是在实际运行过程中,对代码进行分析,将热点代码编译成机器码,让它可以在应用运行时持续提升 Android 应用的性能。
JIT编译器补充了ART当前的预先(AOT)编译器的功能,有助于提高运行时性能,节省存储空间,以及加快应用及系统更新速度。相较于 AOT编译器,JIT编译器的优势也更为明显,因为它不会在应用自动更新期间或重新编译应用(在无线下载 (OTA) 更新期间)时拖慢系统速度。
尽管JIT和AOT使用相同的编译器,它们所进行的一系列优化也较为相似,但它们生成的代码可能会有所不同。JIT会利用运行时类型信息,可以更高效地进行内联,并可让堆栈替换 (On Stack Replacement) 编译成为可能,而这一切都会使其生成的代码略有不同。
APK安装阶段
系统不再像纯AOT时代那样对整个APK进行完全编译。取而代之的是,系统会进行一些轻量级的处理:
- 验证DEX文件
- 优化DEX文件(例如字节码优化)
- 生成ODEX文件(优化后的DEX)
这个阶段不会生成大量的本地机器码,从而加快了安装速度。
首次运行
应用以解释模式开始运行。 JIT编译器开始工作:
- 监控代码执行
- 识别热点代码
- 将热点代码编译成本地机器码
编译后的代码存储在JIT代码缓存中,供后续快速访问。同时,系统开始收集应用使用的配置文件信息。
持续运行阶段
JIT编译器持续工作,不断优化热点代码。系统继续收集和更新应用的使用配置文件。随着时间推移,更多的代码可能被JIT编译。
设备空闲充电时:
系统触发”编译守护进程”(compilation daemon)。基于收集的配置文件信息,对应用进行部分AOT编译。这个过程被称为”配置文件引导编译”(profile-guided compilation)。编译结果保存为本地机器码,存储在设备上。
后续运行
应用启动时,系统会加载之前AOT编译的代码。对于未编译的部分,继续使用解释执行和JIT编译。JIT编译器继续工作,可能会编译之前未被AOT编译的代码。
长期优化
系统会定期(通常在设备空闲充电时)重新评估和更新AOT编译的代码。这个过程会考虑最新的使用模式,可能会编译新的热点代码,或者放弃编译不再频繁使用的代码。
系统更新时
当系统更新时(例如Android版本升级),之前的AOT编译结果可能会被丢弃。 应用会重新经历上述过程,以适应新的系统环境。
总的来说,这种JIT和AOT的混合策略充分利用了两种方法的优点,在 安装速度、启动时间、运行性能和存储空间使用之间取得了很好的平衡 ,显著提升了Android系统的整体用户体验。