【Kotlin】Flow全面总结

本文介绍了Kotlin异步工具Flow框架的使用总结
Kotlin的Flow这个异步工具,在项目中其实一直在使用,得空参考下郭神在CSDN上的三篇文章,再自行扩展,在使用层面的规则上,进行一个相对较为全面的总结。
Flow最常见的使用场景,就是在viewmodel里面使用StateFlow 热流,在Ui层进行collect。用法和此前的LiveData是一样的。
例如一个获取Github仓库列表的网络请求数据:
private val githubReposSate = MutableStateFlow(GithubReposState())
val githubReposListStateFlow = githubReposSate.asStateFlow()
在Composable可组合项里进行消费:
val githubReposState by viewModel.githubReposListStateFlow.collectAsState()
Column(
modifier = Modifier
.fillMaxSize()
.background(MaterialTheme.colors.background)
) {
LazyColumn(
modifier = Modifier
.fillMaxSize()
.background(MaterialTheme.colors.background)
) {
items(githubReposState.githubReposList) {
GithubRepoItem(it)
}
}
}
冷流
使用flow构造器直接创建的为冷流,只有在调用collect函数时才会开始执行往外发送数据。
val TAG = "FlowOne".apply {
Log.i(this, "init")
}
val flow = flow<Int> {
repeat(5) {
delay(500)
emit(it)
}
}
fun startCollect() {
CoroutineScope(Dispatchers.IO).launch {
delay(3000L)
Log.i(TAG,"startCollect")
flow.collect {
Log.i(TAG,"FlowOne collect $it")
}
}
}
外部测试调用:
startCollect()
打印可以看到,flow创建好之后,没有数据打印,而是在三秒后collect时,才会从头开始进行发送:
16:24:21.803 I init
16:24:24.825 I startCollect
16:24:25.328 I FlowOne collect 0
16:24:25.830 I FlowOne collect 1
16:24:26.332 I FlowOne collect 2
16:24:26.833 I FlowOne collect 3
16:24:27.334 I FlowOne collect 4
再次collect
如果我们在startCollect函数里再次调用collect。
fun startCollect() {
CoroutineScope(Dispatchers.IO).launch {
delay(3000L)
Log.i(TAG, "startCollect")
flow.collect {
Log.i(TAG, "FlowOne collect $it")
}
flow.collect {
Log.i(TAG, "FlowOne collect twice $it")
}
}
}
第一次收集完毕,延时6s,再次调用collect。打印结果如下:
19:34:57.752 I init
19:35:00.758 I startCollect
19:35:01.260 I FlowOne collect 0
19:35:01.761 I FlowOne collect 1
19:35:02.262 I FlowOne collect 2
19:35:02.765 I FlowOne collect 3
19:35:03.266 I FlowOne collect 4
19:35:03.771 I FlowOne collect twice 0
19:35:04.276 I FlowOne collect twice 1
19:35:04.779 I FlowOne collect twice 2
19:35:05.280 I FlowOne collect twice 3
19:35:05.782 I FlowOne collect twice 4
有两个值得关注的点,第一点是第二次 collect 打印开始的时间并不是紧跟着第一次,而是第一次收集所有数据完毕之后才开始。说明 collect() 函数是一个挂起的函数,只有在数据收集完毕之后,协程后面的函数恢复,才会继续往下执行。
简单来说,连续的两个 collect 操作是串行的,如果想要并行收集,就需要切换到不同的协程作用域。
第二个点是,第二次收集的数据也是从头开始打印的,说明冷流的每一次操作,都会从头开始。
collectLatest
有时候, collect 数据的地方,数据的消费逻辑没有走完,导致数据积压,会出现数据过时的情况,使用 collectLatest 可以解决这个问题。
collectLatest 函数,会在每次有新数据过来时,取消上一次还未执行完的逻辑,立即处理最新的这个数据。
例如,我们在collect函数里延时3s:
fun startCollect() {
CoroutineScope(Dispatchers.IO).launch {
delay(3000L)
Log.i(TAG, "startCollect")
flow.collectLatest {
Log.i(TAG, "FlowOne collect $it")
delay(3000L)
}
}
}
打印结果:
16:39:09.467 I init
16:39:12.494 I startCollect
16:39:12.997 I FlowOne collect 0
16:39:13.502 I FlowOne collect 1
16:39:14.007 I FlowOne collect 2
16:39:14.510 I FlowOne collect 3
16:39:15.013 I FlowOne collect 4
可以看到数据仍然是按照源头的时间间隔来发送的,并不是延时3s才打印。说明 collectLatest() 函数收集的流,会在每次有新数据过来时,取消上一次还未执行完的逻辑,立即处理最新的这个数据。
Flow常用操作符
map
map 可以理解为一个拦截转换器,将 flow 的原数据,经过拦截器处理之后,转换成另一个数据发送出去。map接受一个lambda参数,lambda函数最后一行的数据,就是经过map转换后的返回值。
这里以平方转换为例:
fun mapTest() {
CoroutineScope(Dispatchers.IO).launch {
flowOf(1, 2, 3, 4, 5).map {
it * it
}.collectLatest {
Log.i(TAG, "mapTest collect $it")
}
}
}
打印结果:
16:44:00.302 I init
16:44:00.345 I mapTest collect 1
16:44:00.353 I mapTest collect 4
16:44:00.356 I mapTest collect 9
16:44:00.357 I mapTest collect 16
16:44:00.365 I mapTest collect 25
filter
filter 函数,用于过滤数据,只将满足条件的数据发送出去。filter() 同样接受一个lambda参数,最后一行的需要返回一个Boolean类型,用于判断是否发送数据。
fun filterTest() {
CoroutineScope(Dispatchers.IO).launch {
flowOf(3, 6, 9, 11, 14).filter {
it % 3 == 0
}.collectLatest {
Log.i(TAG, "filterTest collect $it")
}
}
}
打印可以发现,只有369,即三的倍数通过了过滤器被接收。
onEach
onEach函数,用于在每次数据发送之前,执行一些操作。可以打印查看原始的数据是否符合预期。
fun onEachTest() {
CoroutineScope(Dispatchers.IO).launch {
flowOf(1, 2, 3, 4, 5).onEach {
Log.i(TAG, "onEachTest onEach $it")
}.map { it + 10 }.collect {
Log.i(TAG, "onEachTest collect $it")
}
}
}
打印结果:
16:51:51.942 I init
16:51:51.982 I onEachTest onEach 1
16:51:51.984 I onEachTest collect 11
16:51:51.984 I onEachTest onEach 2
16:51:51.984 I onEachTest collect 12
16:51:51.985 I onEachTest onEach 3
16:51:51.986 I onEachTest collect 13
16:51:51.987 I onEachTest onEach 4
16:51:51.987 I onEachTest collect 14
16:51:51.988 I onEachTest onEach 5
16:51:51.993 I onEachTest collect 15
debounce
debounce 函数,用于在一段时间内,只发送最后一次数据。两次数据的时间间隔太近,前一次的数据就会被丢弃,后一次数据,在延时这段时间后发送。类似Handler的remove和postDelayed的防抖操作。
@OptIn(FlowPreview::class)
fun debounceTest() {
CoroutineScope(Dispatchers.IO).launch {
flow {
emit(1)
delay(100)
emit(2)
delay(1000)
emit(3)
delay(100)
emit(4)
delay(100)
emit(5)
}.debounce(500).collectLatest {
Log.i(TAG, "debouneTest collect $it")
}
}
}
打印结果:
16:58:41.402 I init
16:58:42.062 I debouneTest collect 2
16:58:42.767 I debouneTest collect 5
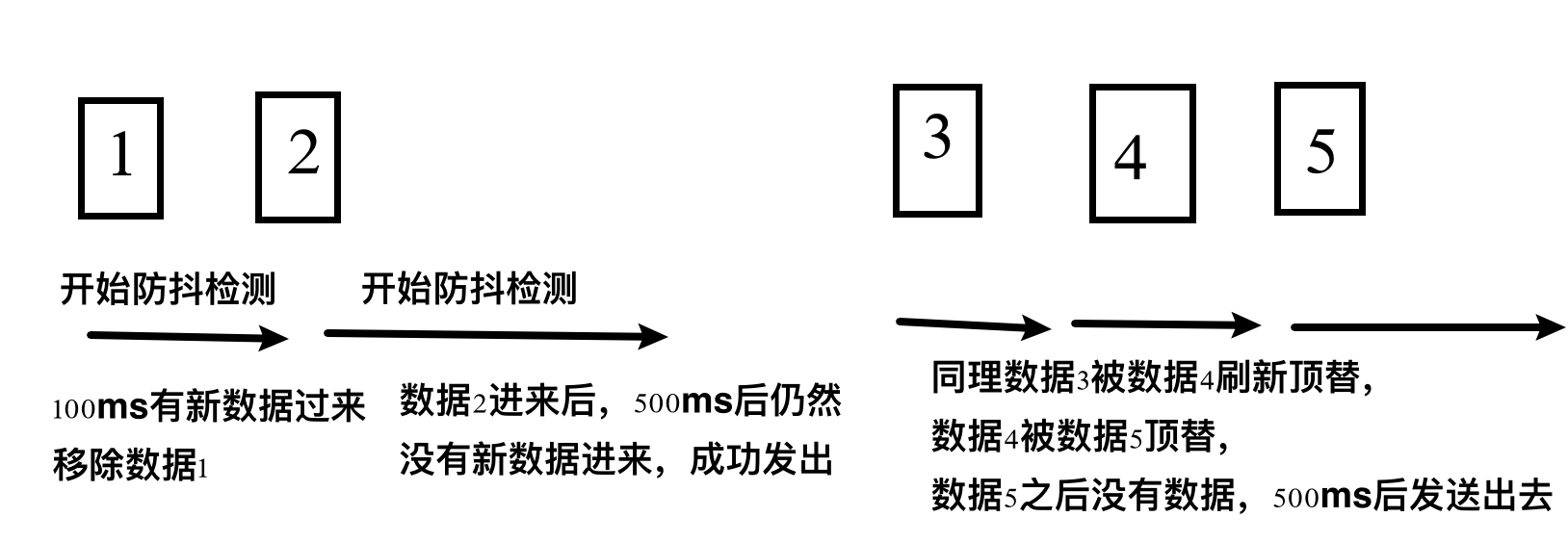
流程:
collect开始后,数据1立即发送,开始为期500ms的监测,100ms后数据2发送了,这时候数据1就被丢弃,再开始500ms监测。500ms后没有新数据来,将2发送出去。可以看到从init到第一次数据打印,就是耗时600ms。同理,2和5之间,间隔700ms。
sample
sample 函数,作用类似debounce。sample有一个采样期,采样期结束,会将采样期内最后一次数据发送出去。
@OptIn(FlowPreview::class)
fun sampleTest() {
CoroutineScope(Dispatchers.IO).launch {
flow {
emit(1)
delay(150)
emit(2)
delay(150)
emit(3)
delay(150)
emit(4)
delay(150)
emit(5)
}.sample(200).collect {
Log.i(TAG, "debouneTest collect $it")
}
}
}
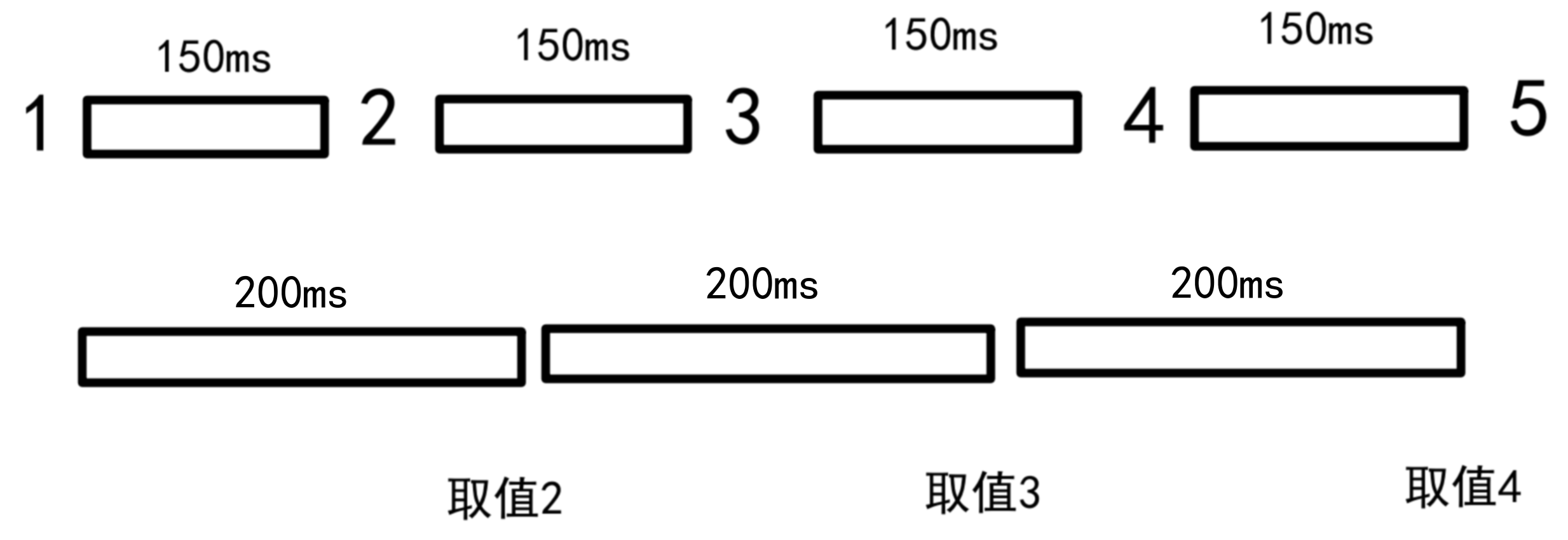
每150ms发送一次数据,采样期为200ms,所以每200ms,会将采样期内最后一次数据发送出去。打印结果:
17:13:34.656 I init
17:13:34.891 I debouneTest collect 2
17:13:35.092 I debouneTest collect 3
17:13:35.295 I debouneTest collect 4
取值的过程如下图:
reduce
reduce 函数,用于迭代操作,在上一次计算结果的基础上,拿当前的值再进行下一步计算。
例如,将1到5的数字相乘:
fun reduceTest() {
CoroutineScope(Dispatchers.IO).launch {
val totalResult =
flowOf(1, 2, 3, 4, 5)
.reduce { acc, value ->
acc * value
}
Log.i(TAG, "reduceTest collect $totalResult")
}
}
结果打印为120.
fold
fold 函数,和 reduce 基本一致,只是多了一个初始值。
fun foldTest() {
CoroutineScope(Dispatchers.IO).launch {
val totalResult =
flowOf(1, 2, 3, 4, 5)
.fold(10) { acc, value ->
acc * value
}
Log.i(TAG, "foldTest collect $totalResult")
}
}
打印结果为1200.
reduce和fold不仅可以用于数字,还可以用于字符串的拼接。
flatMapConcat
以flatMap开头的操作符函数,分别是flatMapConcat、flatMapMerge和flatMapLatest。
flatMap的核心,就是将两个flow中的数据进行映射、合并、压平成一个flow,最后再进行输出。
flatMapConcat,是将两个flow中的数据进行合并,然后再进行输出。侧重点是按顺序拼接,类比C++里面两个数组的组合遍历。
@OptIn(ExperimentalCoroutinesApi::class)
fun flatMapConcatTest() {
CoroutineScope(Dispatchers.IO).launch {
flowOf(1, 2, 3).flatMapConcat {
flowOf("a$it", "b$it")
}.collect {
Log.i(TAG, "flatMapConcatTest collect $it")
}
}
}
打印结果:
17:40:40.835 I init
17:40:40.859 I flatMapConcatTest collect a1
17:40:40.859 I flatMapConcatTest collect b1
17:40:40.859 I flatMapConcatTest collect a2
17:40:40.860 I flatMapConcatTest collect b2
17:40:40.860 I flatMapConcatTest collect a3
17:40:40.861 I flatMapConcatTest collect b3
实际应用中,例如账号登陆获取用户数据的网络请求,需要先登录获取一个token,然后再拿这个token去获取用户数据。
fun getUserInfo() {
CoroutineScope(Dispatchers.IO).launch {
sendGetTokenRequest()
.flatMapConcat { token ->
sendGetUserInfoRequest(token)
}
.flowOn(Dispatchers.IO)
.collect { userInfo ->
println(userInfo)
}
}
}
flatMapMerge
flatMapMerge,同样是将两个flow中的数据进行合并,然后再进行输出。但是他的侧重点是并行的,即flow1每个数据的操作不是串行的,而是并行的。
@OptIn(ExperimentalCoroutinesApi::class)
fun flatMapMergeTest() {
CoroutineScope(Dispatchers.IO).launch {
flowOf(300, 200, 100)
.flatMapMerge {
flow {
delay(it.toLong())
emit("a$it")
emit("b$it")
}
}
.collect {
Log.i(TAG, "flatMapMergeTest collect $it")
}
}
}
打印结果:
17:55:37.695 I init
17:55:37.864 I flatMapMergeTest collect a100
17:55:37.865 I flatMapMergeTest collect b100
17:55:37.955 I flatMapMergeTest collect a200
17:55:37.956 I flatMapMergeTest collect b200
17:55:38.055 I flatMapMergeTest collect a300
17:55:38.058 I flatMapMergeTest collect b300
可以看到flatMapMerge处理之后,优先把耗时更少的数据添加到新的flow里面去进行发送。如果这里用的是flatMapConcat,那么结果就是按照300,200,100顺序发送。
flatMapLatest
flatMapLatest,同样是将两个flow中的数据进行合并,然后再进行输出。但是他的侧重点是,只保留最新的一个数据。
@OptIn(ExperimentalCoroutinesApi::class)
fun flatMapLatestTest() {
CoroutineScope(Dispatchers.IO).launch {
flow {
emit(1)
delay(150)
emit(2)
delay(50)
emit(3)
}.flatMapLatest {
flow {
delay(100)
emit("$it")
}
}.collect {
Log.i(TAG, "flatMapLatestTest collect $it")
}
}
}
和collectLatest类似,如果使用flatMapLatest来合并多个flow,当flow1的前一个数据给到了,但是flow2没有及时合并完成,flow1的下一个数据又过来了,那么前一个数据的处理逻辑就会被掐断丢弃,直接处理最新的这个数据。
打印结果:
17:59:19.282 I init 17:59:19.444 I flatMapLatestTest collect 1 17:59:19.657 I flatMapLatestTest collect 3
zip
zip 函数和 flatMap 函数有点类似,都是作用在两个flow上的。
使用 zip 函数连接的两个flow,它们之间是并行的运行关系。而 flatMap 是一个flow中的数据流向另外一个flow,是串行的关系。
元素按照少的那个flow来决定
zip函数还有一个规则,就是 只要其中一个flow中的数据对应的数量,全部处理结束就会终止运行,剩余未处理的数据将不会得到处理。
@OptIn(ExperimentalCoroutinesApi::class)
fun zipTest() {
CoroutineScope(Dispatchers.IO).launch {
flowOf(1, 2, 3, 4, 5)
.zip(flowOf("a", "b", "c", "d")) { a, b ->
"$a+$b"
}
.collect {
Log.i(TAG, "zipTest collect $it")
}
}
}
第一个flow有5个元素,第二个flow有4个元素,按照zip函数的规则,最终只会处理4个元素,最后一个元素5不会被处理。
打印结果:
19:45:12.248 I init
19:45:12.261 I zipTest collect 1+a
19:45:12.262 I zipTest collect 2+b
19:45:12.263 I zipTest collect 3+c
19:45:12.264 I zipTest collect 4+d
运行时长按照长的那个flow来决定
下面例子中,flow1和flow2发送数据均有延时逻辑,zip是并行执行的,最终的运行时长,取决于运行时长更长的那个flow。
fun zipTest2() {
CoroutineScope(Dispatchers.IO).launch {
val start = System.currentTimeMillis()
val flow1 = flow {
delay(3000)
emit("a")
}
val flow2 = flow {
delay(2000)
emit(1)
}
flow1.zip(flow2) { a, b ->
a + b
}.collect {
val end = System.currentTimeMillis()
Log.i(TAG, "Time cost: ${end - start}ms")
}
}
}
打印结果:
19:48:24.785 I init
19:48:27.801 I Time cost: 3012ms
zip的应用场景,好几个接口的请求返回耗时时长不一致,但是需要将数据一起返回给界面,就可以通过zip的特性,在耗时最长的flow执行完毕之后,再一同发送数据。
buffer
默认情况下,flow的数据发送和collect是在同一个协程上运行的,如果collect里面有耗时逻辑,也会对flow的数据发送造成影响。
在大多数情况,这都是最好规避掉的。
fun bufferTest() {
CoroutineScope(Dispatchers.IO).launch {
flow {
emit(1)
delay(1000)
emit(2)
delay(1000)
emit(3)
}.onEach {
Log.i(TAG, "bufferTest onEach $it")
}.collect {
delay(1000)
Log.i(TAG, "bufferTest collect $it")
}
}
}
collect 和 emit 都有1s的延时,互相挂起,串行执行,所以应该每个collect就变成了2s,打印结果如下:
19:55:52.000 I init
19:55:52.004 I bufferTest onEach 1
19:55:53.006 I bufferTest collect 1
19:55:54.011 I bufferTest onEach 2
19:55:55.013 I bufferTest collect 2
19:55:56.018 I bufferTest onEach 3
19:55:57.021 I bufferTest collect 3
这时候加一个 buffer 操作符,就可以让数据发送和collect并行执行。
加 buffer() 调用之后的结果打印:
20:00:03.426 I init
20:00:03.432 I bufferTest onEach 1
20:00:04.436 I bufferTest collect 1
20:00:04.437 I bufferTest onEach 2
20:00:05.439 I bufferTest collect 2
20:00:05.439 I bufferTest onEach 3
20:00:06.443 I bufferTest collect 3
buffer 操作符有一个可选的 capacity 参数,用于指定缓冲区的大小。如果不指定 capacity,则缓冲区的大小默认为 Channel.BUFFERED,这意味着缓冲区的大小是无限制的。 然而,需要注意的是,虽然缓冲区的大小可以是无限制的,但在实际应用中,过大的缓冲区可能会导致内存占用过高,从而影响应用的性能。因此,建议根据具体的应用场景和需求来合理设置缓冲区的大小。
conflate
conflate 函数是对buffer函数的一个另选方案,它的作用是当收集器挂起之后,flow发射方把当前无法处理的数据丢弃掉,待收集器处理完逻辑,再给其发送新的值。可以解决buffer函数的问题,即当 collector 收集器过于耗时,又未指定容量,那缓存区的数据就越来越大。
与之有点相似的是 collectLatest 函数,上面展示了使用collectLatest函数,在数据发送的过程中,会取消上一次未运行完毕的收集逻辑,立即处理最新的数据。
而 conflate 函数,是在数据发送的过程中,如果本次 collect 仍然在运行,就把这个数据丢弃掉,等到 collector 收集器重新可接收数据之后,拿到的就是最新的数据。这样可以保证 collector 每次接收到数据之后,可以把当前的逻辑全部走完。
fun conflateTest() {
CoroutineScope(Dispatchers.IO).launch {
flow {
repeat(7){
delay(100)
emit(it)
}
}.conflate().collect {
Log.i(TAG, "conflateTest collect start handle $it")
delay(210)
Log.i(TAG, "conflateTest collect end handle $it")
}
}
}
打印结果:
20:17:58.356 I init
20:17:58.465 I conflateTest collect start handle 0
20:17:58.676 I conflateTest collect end handle 0
20:17:58.677 I conflateTest collect start handle 2
20:17:58.889 I conflateTest collect end handle 2
20:17:58.889 I conflateTest collect start handle 4
20:17:59.099 I conflateTest collect end handle 4
20:17:59.099 I conflateTest collect start handle 6
20:17:59.310 I conflateTest collect end handle 6
可以看到当collector挂起的时候发送的数据就丢弃掉了。
conflate和collectLatest共用的情况
conflate 函数和 collectLatest 函数,一个丢弃数据,一个丢弃逻辑,如果都用是什么效果呢?
实测是 collectLatest 函数的效果是优先的,收集器会掐断正在执行的逻辑,转而处理更新的数据。
fun conflateTest() {
CoroutineScope(Dispatchers.IO).launch {
flow {
repeat(7) {
delay(100)
emit(it)
}
}.conflate().collectLatest {
Log.i(TAG, "conflateTest collect start handle $it")
delay(210)
Log.i(TAG, "conflateTest collect end handle $it")
}
}
}
打印结果:
20:22:19.626 I init
20:22:19.736 I conflateTest collect start handle 0
20:22:19.838 I conflateTest collect start handle 1
20:22:19.938 I conflateTest collect start handle 2
20:22:20.039 I conflateTest collect start handle 3
20:22:20.140 I conflateTest collect start handle 4
20:22:20.242 I conflateTest collect start handle 5
20:22:20.342 I conflateTest collect start handle 6
20:22:20.553 I conflateTest collect end handle 6
StateFlow 和 SharedFlow
插入LiveData
在Java开发的时候,会使用LiveData来进行数据的传递。
LiveData是Android Jetpack的一部分,与常规的可观察类不同,LiveData 具有生命周期感知能力,意指它遵循其他应用组件(如 Activity、Fragment 或 Service)的生命周期。这种感知能力可确保 LiveData 仅更新处于活跃生命周期状态的应用组件观察者。
基本使用方式:
viewmodel里面维护一个私有的MutableLiveData数据,暴露一个公开的livedata变量,然后在activity中监听LiveData数据的变化。
class MainViewModel : ViewModel() {
private val _countLiveData = MutableLiveData<Int>(0)
val countLiveData: LiveData<Int>
get() = _countLiveData
suspend fun startCount() = withContext(Dispatchers.IO) {
while (true) {
delay(1000)
withContext(Dispatchers.Main) {
_countLiveData.value = _countLiveData.value?.plus(1)
}
}
}
}
Activity中监听数据变化:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Log.i("MainActivity", "onCreate")
val tvCount = findViewById<TextView>(R.id.tv_count)
mainViewModel.countLiveData.observe(this) {
Log.i("MainActivity", "observe data: $it")
tvCount.text = it.toString()
}
lifecycleScope.launch {
mainViewModel.startCount()
}
}
运行之后count数据就开始每秒加 1 了,一段时间后上滑回到桌面,日志显示activity的 onStop() 方法被调用,activity的生命周期进入后台。这时候Observer就不会处理推送过来的数据。
再过一段时间后,重新打开应用界面,日志里看到 activity 的 onResume() 方法被调用,activity的生命周期进入前台。这时候 Observer 就会继续从最新的数据开始处理推送过来的数据。
打印结果:
10:58:10.265 I onCreate
10:58:10.414 I observe data: 0
10:58:10.417 I onResume
10:58:11.391 I observe data: 1
10:58:12.395 I observe data: 2
10:58:13.397 I observe data: 3
10:58:14.401 I observe data: 4
10:58:15.404 I observe data: 5
10:58:16.406 I observe data: 6
10:58:20.866 I onStop
10:58:26.357 I observe data: 15
10:58:26.357 I onResume
10:58:26.436 I observe data: 16
10:58:27.440 I observe data: 17
10:58:28.444 I observe data: 18
10:58:29.448 I observe data: 19
LiveData 遵循观察者模式。当生命周期状态发生变化时,LiveData 会通知 Observer 对象。当界面组件处于非活跃状态时,它不会接收任何 LiveData 事件。
下面是LiveData的observe的源码,展示了这种绑定注册关系:
@MainThread
public void observe(@NonNull LifecycleOwner owner, @NonNull Observer<? super T> observer) {
assertMainThread("observe");
if (owner.getLifecycle().getCurrentState() == DESTROYED) {
// ignore
return;
}
LifecycleBoundObserver wrapper = new LifecycleBoundObserver(owner, observer);
ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper);
if (existing != null && !existing.isAttachedTo(owner)) {
throw new IllegalArgumentException("Cannot add the same observer"
+ " with different lifecycles");
}
if (existing != null) {
return;
}
owner.getLifecycle().addObserver(wrapper);
}
Activity直接收集冷流flow
类比上面LiveData的写法,直接在Activity里收集冷流,试试看是什么效果。
class MainViewModel : ViewModel() {
val countnFlow = flow<Int> {
var count = 0
while (true) {
emit(count++)
delay(1000)
}
}
}
Activity添加收集flow:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Log.i("MainActivity", "onCreate")
val tvCount = findViewById<TextView>(R.id.tv_count)
lifecycleScope.launch {
mainViewModel.countnFlow.collect {
Log.i("MainActivity", "collect data: $it")
tvCount.text = it.toString()
}
}
}
打印结果:
10:47:56.742 I onCreate
10:47:56.865 I collect data: 0
10:47:56.900 I onResume
10:47:57.872 I collect data: 1
10:47:58.875 I collect data: 2
10:47:59.876 I collect data: 3
10:48:00.878 I collect data: 4
10:48:01.051 D visibilityChanged oldVisibility=true newVisibility=false
10:48:01.084 I onStop
10:48:01.880 I collect data: 5
10:48:02.882 I collect data: 6
10:48:03.886 I collect data: 7
10:48:04.889 I collect data: 8
10:48:05.891 I collect data: 9
10:48:06.661 I onResume
10:48:06.892 I collect data: 10
10:48:07.896 I collect data: 11
10:48:08.899 I collect data: 12
10:48:09.904 I collect data: 13
可以看到,在activity进入后台之后,数据依然在不断的发送,收集器也在不断的收集处理数据。因为这种方法并没有生命周期感知的特性。
使用repeatOnLifecycle
在协程里面,可以使用 repeatOnLifecycle 来让某些任务只在特定生命周期状态内才会执行。我们可以传入 Lifecycle.State.STARTED,表示只有activity在started状态下才运行。当再次处于started状态时,任务会重新开始执行。
使用 repeatOnLifecycle 需要导入
androidx.lifecycle:lifecycle-runtime-ktx:2.4.0包。
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Log.i("MainActivity", "onCreate")
val tvCount = findViewById<TextView>(R.id.tv_count)
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
mainViewModel.countnFlow.collect {
Log.i("MainActivity", "collect data: $it")
tvCount.text = it.toString()
}
}
}
}
日志可以看到,onStop之后,数据的处理就停止了,在start之后,collect会重新调用,所以数据是从0开始的,日志打印结果:
11:08:40.925 I onCreate
11:08:41.068 I collect data: 0
11:08:41.072 I onResume
11:08:42.072 I collect data: 1
11:08:43.074 I collect data: 2
11:08:44.076 I collect data: 3
11:08:45.080 I collect data: 4
11:08:46.082 I collect data: 5
11:08:47.084 I collect data: 6
11:08:47.621 D visibilityChanged oldVisibility=true newVisibility=false
11:08:47.657 I onStop
11:09:03.861 I collect data: 0
11:09:03.862 I onResume
11:09:04.863 I collect data: 1
11:09:05.865 I collect data: 2
11:09:06.868 I collect data: 3
11:09:07.871 I collect data: 4
11:09:08.875 I collect data: 5
这样可以避免在activity处于后台的时候,数据的处理逻辑一直运行,导致资源浪费或者内存泄漏。
StateFlow
借助 repeatOnLifecycle,我们可以在activity处于started状态的时候,收集数据。使用StateFlow的效果可以说和LiveData几乎一致。
class MainViewModel : ViewModel() {
private val _stateFlow = MutableStateFlow(0)
val countStateFlow = _stateFlow.asStateFlow()
suspend fun startCount() = withContext(Dispatchers.IO) {
for (i in 0..100) {
delay(1000)
_stateFlow.value = i
}
}
}
activity里收集,注意 startCount 和 collect 均为挂起函数,两个函数需要放在不同的作用域内调用:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Log.i("MainActivity", "onCreate")
val tvCount = findViewById<TextView>(R.id.tv_count)
lifecycleScope.launch {
launch {
mainViewModel.startCount()
}
repeatOnLifecycle(Lifecycle.State.STARTED) {
mainViewModel.countStateFlow.collect {
Log.i("MainActivity", "collect data: $it")
tvCount.text = it.toString()
}
}
}
}
结果打印,退到后台,数据的处理取消,回到前台后,重新collect,同时因为stateflow是热流,收集时会直接从最新的状态开始:
11:27:57.859 I onCreate
11:27:58.028 I collect data: 0
11:27:58.030 I onResume
11:28:00.004 I collect data: 1
11:28:01.005 I collect data: 2
11:28:02.007 I collect data: 3
11:28:03.009 I collect data: 4
11:28:04.012 I collect data: 5
11:28:05.014 I collect data: 6
11:28:05.165 D visibilityChanged oldVisibility=true newVisibility=false
11:28:05.210 I onStop
11:28:11.967 I collect data: 12
11:28:11.968 I onResume
11:28:12.045 I collect data: 13
11:28:13.027 I collect data: 14
11:28:14.029 I collect data: 15
11:28:15.031 I collect data: 16
config变化导致协程取消
当屏幕方向发生变化时,activity会销毁重新创建,这时候 lifecycle 协程会被取消,然后重新启动。计时器任务也会取消重新执行。
竖屏变横屏的日志打印:
13:39:19.215 I onCreate 13:39:19.426 I collect data: 0 13:39:19.429 I onResume 13:39:21.396 I collect data: 1 13:39:22.397 I collect data: 2 13:39:23.399 I collect data: 3 13:39:24.401 I collect data: 4 13:39:25.403 I collect data: 5 13:39:26.395 I onStop 13:39:26.404 I onDestroy 13:39:26.450 I onCreate 13:39:26.479 I collect data: 5 13:39:26.487 I onResume 13:39:27.460 I collect data: 0 13:39:28.461 I collect data: 1 13:39:29.463 I collect data: 2 13:39:30.466 I collect data: 3 13:39:31.468 I collect data: 4
借助stateIn将冷流变成StateFlow
上面的config变化导致协程取消的问题,可以借助 stateIn 函数将冷流变成热流。然后把计时的操作移植到冷流中。
class MainViewModel : ViewModel() {
private val timeFlow = flow {
var time = 0
while (true) {
emit(time)
delay(1000)
time++
}
}
val countStateFlow =
timeFlow.stateIn(
viewModelScope,
SharingStarted.WhileSubscribed(5000),
0
)
}
stateIn 扩展函数,有三个参数,第一个参数是协程作用域,第三个参数是初始值。
其第二个参数是共享的策略,因为横竖屏切换通常很快就能完成,这里我们通过stateIn函数的第2个参数指定了一个5秒的超时时长,那么只要在5秒钟内横竖屏切换完成了,Flow就不会停止工作。
反过来讲,这也使得程序切到后台之后,如果5秒钟之内再回到前台,那么Flow也不会停止工作。但是如果切到后台超过了5秒钟,Flow就会全部停止了。
竖屏变横屏的日志打印:
13:47:49.368 I onCreate
13:47:49.579 I collect data: 0
13:47:49.588 I onResume
13:47:50.589 I collect data: 1
13:47:51.592 I collect data: 2
13:47:52.594 I collect data: 3
13:47:53.597 I collect data: 4
13:47:54.600 I collect data: 5
13:47:55.385 I onStop
13:47:55.388 I onDestroy
13:47:55.471 I onCreate
13:47:55.477 I collect data: 5
13:47:55.485 I onResume
13:47:55.601 I collect data: 6
13:47:56.605 I collect data: 7
13:47:57.609 I collect data: 8
13:47:58.613 I collect data: 9
13:47:59.616 I collect data: 10
SharedFlow
粘性消息的概念
LiveData 的粘性,是指当一个新的观察者开始观察 LiveData 时,它会 立即接收到 LiveData 最后一次设置的值 ,即使这个值是在观察者开始观察之前设置的。这种行为被称为粘性,因为它就像观察者“粘”在了 LiveData 的最后一个值上。
粘性的实现原理是基于 LiveData 的版本号机制。每当 LiveData 的值发生变化时,它的版本号就会增加。当一个新的观察者开始观察 LiveData 时,它会检查当前的版本号,如果版本号大于 0,说明 LiveData 已经有了一个值,那么观察者会立即接收到这个值。
粘性的优点是可以确保新的观察者不会错过 LiveData 的任何重要状态变化,即使它们在状态变化之后才开始观察。这对于一些需要实时更新的场景非常有用,例如用户界面的状态管理。
然而,粘性也可能会导致一些问题,特别是在处理事件流时。如果 LiveData 被用作事件总线,粘性可能会导致新的观察者接收到旧的事件,这可能会导致应用程序的行为不符合预期。
通过之前的例子,发现stateflow也是粘性的,开始收集时,是从上一个最新的值开始的。
SharedFlow使用
SharedFlow 和 StateFlow 的用法还是略有不同的。
首先,MutableSharedFlow 是不需要传入初始值参数的。因为非粘性的特性,它本身就 不要求观察者在观察的那一刻就能收到消息 ,所以也没有传入初始值的必要。
另外就是,SharedFlow 无法像 StateFlow 那样通过给 value 变量赋值来发送消息,而是只能像传统 Flow 那样调用 emit 函数。而 emit 函数又是一个挂起函数,所以这里需要调用 viewModelScope 的 launch 函数启动一个协程,然后再发送消息。
class MainViewModel : ViewModel() {
private val _countSharedFlow = MutableSharedFlow<Int>()
val countSharedFlow = _countSharedFlow.asSharedFlow()
init {
CoroutineScope(Dispatchers.IO).launch {
repeat(20) {
delay(1000)
_countSharedFlow.emit(it)
}
}
}
}
activity中收集代码仍然未改变:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Log.i("MainActivity", "onCreate")
val tvCount = findViewById<TextView>(R.id.tv_count)
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
mainViewModel.countSharedFlow.collect {
Log.i("MainActivity", "collect data: $it")
tvCount.text = it.toString()
}
}
}
}
SharedFlow 在运行之后的发送和收集是解耦的。这意味着发送者和接收者可以独立地进行操作,而不需要彼此之间的直接交互。
在 Kotlin 中, SharedFlow 是一个热流(hot flow),它可以在没有订阅者的情况下开始发送数据,并且可以有多个订阅者同时接收数据。这种设计使得 SharedFlow 非常适合 用于在多个组件之间共享数据 ,而不需要显式地管理订阅者的生命周期。
SharedFlow 主要关注其非粘性的特点,其实可以通过一些参数的配置来让 SharedFlow 在有观察者开始工作之前缓存一定数量的消息,甚至还可以让 SharedFlow 模拟出 StateFlow 的效果。SharedFlow 是一个非常强大的工具,特别适合处理事件总线、一次性操作和需要多个订阅者的场景。