【Android性能优化】Android trace文件分析

本文介绍了在分析Android性能问题过程中,常用的trace文件的分析方法。
Android trace 文件(也常被称为 Systrace 文件或 Perfetto trace 文件)是 Android 系统生成的一种包含详细性能事件数据的文件。它记录了设备在特定时间段内 CPU、线程、进程、函数调用、Binder 通信、I/O 操作、SurfaceFlinger 帧渲染等 各个层面的活动。
可以把它想象成一个高性能的“黑匣子记录仪”,它在系统运行时不断记录各种事件,当出现性能问题时,我们可以回放这些记录,了解系统当时到底发生了什么。
一般用来分析性能相关的问题:
- 识别性能瓶颈:找出导致应用卡顿、响应慢、启动慢、耗电、UI 渲染不流畅等问题的根本原因。
- 分析系统行为:深入了解应用与系统服务、框架层、硬件之间的交互。
- 优化代码逻辑:定位到具体耗时函数或线程阻塞点,从而优化算法或并行处理。
- 调试复杂问题:对于一些难以复现的性能问题,trace 文件能提供宝贵的线索。
采集方式
随着 Android 版本的迭代,trace 文件的生成和分析工具也在不断发展。
Systrace (旧版)
Systrace 是 Android 早期最常用的性能分析工具,它通过 Ftrace(Linux 内核中的一个跟踪工具)收集系统事件,并结合用户空间事件(由应用程序或系统服务通过 Trace 类或 ATrace 宏记录)生成 HTML 报告。可以配置一系列参数,如:
gfx:图形 (Graphics) 相关事件;
input:输入 (Input) 事件,例如触摸、按键等;
view:视图系统 (View System) 事件;
wm:窗口管理器 (Window Manager) 事件;
am:Activity 管理器 (Activity Manager) 事件;
audio:音频 (Audio) 事件,与音频播放和录制相关;
...
可以直接从命令行使用,无需修改代码(针对系统事件)。但是其生成的报告可视化能力有限,且没有包名,只有进程id,对大型 trace 文件分析效率不高。现在逐渐被 Perfetto 取代。
Perfetto (新版 & 推荐)
Perfetto 是 Google 开发的新一代系统级性能分析工具,它旨在替代和增强 Systrace。它是atrace的超集,除了应用层还可以抓取内核等底层的一些信息,提供了更丰富的数据源(包括 Ftrace、Perf、ftrace-events、Android events 等)。
还有更灵活的查询能力,以及更强大的 Web UI (UI 网址:ui.perfetto.dev)。
- 更全面:收集的数据类型更多,覆盖面更广。
- 更灵活:可以通过 protobuf 配置数据源。
- 更强大:Web UI 交互性强,支持 SQL 查询,方便深度分析。
- 可编程:可以通过 Python SDK 进行自动化分析。
可以使用 adb shell perfetto 命令来采集:
emu64xa:/ $ perfetto -h
Usage: perfetto
--background -d : Exits immediately and continues in the background.
Prints the PID of the bg process. The printed PID
can used to gracefully terminate the tracing
session by issuing a `kill -TERM $PRINTED_PID`.
...
比较重要的参数有:
-t <duration> :指定持续时间,例如 -t 10s 表示持续 10 秒。
-b <buffer-size> :指定缓冲区大小,单位为 MB,例如 -b 128 表示 128 MB。
-c <config> :指定配置文件,例如 -c my_config.pb 表示使用 my_config.pb 作为配置文件。
--output <file> :指定输出文件,例如 --output my_trace.pb 表示将结果输出到 my_trace.pb 文件。
可以抓取的tag配置有如下:
emu64xa:/sys/kernel/tracing/events $ ls
alarmtimer devfreq gadget irq_vectors mt76 printk spi virtio_gpu
asoc devlink gpio jbd2 mt76_usb qdisc spmi vmalloc
avc dma_fence gpu_mem kmem mt76x02 ras swiotlb vmscan
binder drm header_event kvm napi raw_syscalls synthetic vsock
block dwc3 header_page kvmmmu neigh rcu task vsyscall
bpf_test_run enable huge_memory kyber net regmap tcp watchdog
bpf_trace erofs i2c lock netlink regulator thermal wbt
bridge error_report initcall mac80211 nmi rpm thp workqueue
cfg80211 exceptions interconnect maple_tree notifier rtc timer writeback
cgroup ext4 io_uring mdio nvme sched tlb x86_fpu
cma f2fs iocost migrate oom scsi ucsi xdp
compaction fib iomap mmap page_isolation sd udp xhci-hcd
cpuhp fib6 iommu mmap_lock page_pool signal ufs
csd filelock ipi mmc pagemap skb uvcg
damon filemap irq module percpu smbus v4l2
dev ftrace irq_matrix msr power sock vb2
我们还可以在新版的perfetto网站上直接采用图形化的方式去生成配置文件的代码:
CPU信息配置界面:
抓取GPU的配置页面:
选取要抓取的信息之后,到 cmdline tab那里复制下来:
buffers {
size_kb: 65536
fill_policy: DISCARD
}
buffers {
size_kb: 4096
fill_policy: DISCARD
}
data_sources {
config {
name: "linux.ftrace"
ftrace_config {
ftrace_events: "sched/sched_process_exit"
ftrace_events: "sched/sched_process_free"
ftrace_events: "task/task_newtask"
ftrace_events: "task/task_rename"
ftrace_events: "sched/sched_switch"
ftrace_events: "power/suspend_resume"
ftrace_events: "sched/sched_blocked_reason"
ftrace_events: "sched/sched_wakeup"
ftrace_events: "sched/sched_wakeup_new"
ftrace_events: "sched/sched_waking"
ftrace_events: "sched/sched_process_exit"
ftrace_events: "sched/sched_process_free"
ftrace_events: "task/task_newtask"
ftrace_events: "task/task_rename"
ftrace_events: "power/cpu_frequency"
ftrace_events: "power/cpu_idle"
ftrace_events: "power/suspend_resume"
symbolize_ksyms: true
disable_generic_events: true
}
}
}
data_sources {
config {
name: "linux.process_stats"
process_stats_config {
scan_all_processes_on_start: true
}
}
}
data_sources {
config {
name: "linux.sys_stats"
sys_stats_config {
stat_period_ms: 250
stat_counters: STAT_CPU_TIMES
stat_counters: STAT_FORK_COUNT
cpufreq_period_ms: 250
}
}
}
duration_ms: 10000
直接粘贴到本地 txt 文档里,更名为 pbtx 后缀,推送到设备中,就可以使用命令来使用这个配置文件采集对应的trace数据。
值得注意的是 Perfetto 从 Android 9(P)开始集成,从 Android 11(R)开始默认开启。在 Android 9(P)和 Android 10(Q)上需要先确保开启 Trace 服务
adb shell setprop persist.traced.enable 1
上述从网站点选的配置内容,复制到本地 pbtx 文件之后,再通过 adb 把配置推送到手机:
adb push ~/Desktop/perfetto.pbtx /data/local/tmp/perfetto.pbtx
使用 adb 让手机以指定配置抓 Perfetto Trace:
adb shell 'cat /data/local/tmp/perfetto.pbtx | perfetto --txt -c - -o /data/misc/perfetto-traces/trace'
结束抓取:
adb shell 'perfetto --attach=perf_debug --stop'
Android Studio CPU Profiler
Android Studio 中已经自带了一个 Profiler 性能分析工具,它集成了 CPU、内存、网络和电量分析功能。其中的 CPU Profiler 实际上在幕后使用了 Perfetto 或 ART (Android Runtime) 的采样/插桩机制来生成 trace 文件。
- 集成度高:与开发环境无缝集成,操作简便。
- 可视化强:提供了图形化的界面来展示 CPU 使用率、线程状态、方法调用栈等。
- 多种记录模式:支持 Sampled (采样)、Instrumented (插桩)、System Trace (系统跟踪,即 Perfetto)。
可以直接在 Android Studio 中点击 Run -> Profile ‘your app’,然后选择 CPU Profiler 并开始录制。

Python 脚本抓取
最后介绍下使用 python 脚本来抓取trace,这个也是 Google 官方推出的一种方案。在使用 python 脚本抓取到 Trace 后,会把 Trace 文件保存到本地,也会自动在浏览器通过 Perfetto UI 直接打开 Trace 文件,我们直接进行分析。
使用 python 脚本抓取时需要满足以下几个条件:
- Android 设备通过 adb 连接到电脑。
- 把 python 脚本保存在本地,在本地运行 python 脚本。
- 把抓 Trace 的配置保存在本地,运行 python 脚本时需要指定配置文件。
python 脚本在 GitHub 上的开源地址:
https://github.com/google/perfetto/blob/main/tools/record_android_trace
现在我们把 python 脚本和抓 Trace 的配置放在桌面,命名和目录结构如下:
~/Desktop$
├── perfetto.py
├── perfetto.pbtx
此时我们手机与电脑通过 adb 连接,然后运行以下命令抓取 Trace:
python3 perfetto.py -c perfetto.pbtx -o trace_file.perfetto-trace
上述命令中,-c 是指定配置文件位置, -o 是指定 trace 文件保存位置。
运行命令后,我们开始操作 App,然后觉得抓取到目标 Trace 了,按下ctrl + c 手动结束即可,此时 Trace 文件会被放在 -o 指定的位置,且 Perfetto UI 会被自动打开,直接进行分析即可。
Trace中的重要信息
Trace记录文件,实际上就是系统提前设置好的一些打点记录,我们自己也可也可以手动调用 Trace.beginSection() 来进行标记的。
Trace.beginSection("Choreographer#doFrame");
...
Trace.endSection();
在分析 trace 文件时,通常需要关注以下几个核心信息:
- CPU 使用率 (CPU Usage):显示每个 CPU 核的负载情况,以及进程和线程在 CPU 上的调度。
- 线程状态 (Thread States):每个线程在时间轴上的状态,如 Running (运行中)、Sleeping (休眠)、Runnable (可运行,等待 CPU)、Blocked (阻塞)。这对于识别线程阻塞和死锁非常关键。
- 函数调用 (Method Calls):如果使用采样或插桩模式,可以看到函数调用栈,帮助你识别耗时函数。
- Binder Transactions:进程间通信的事件,显示 Binder 调用的发起和接收,以及耗时。这是你刚才提到的重点。
- I/O 操作 (Disk I/O):文件读写操作,过多的 I/O 会导致性能下降。
- SurfaceFlinger & VSync:显示帧的渲染过程,对于分析 UI 卡顿 (Jank) 至关重要。你可以看到 VSync 信号、应用绘制耗时、GPU 渲染耗时等。
- 内存事件 (Memory Events):虽然 CPU trace 主要关注 CPU,但有时也会包含一些内存分配/回收事件,帮你发现内存抖动。
- 自定义事件 (Custom Trace Events):你可以在自己的代码中插入
Trace.beginSection()/Trace.endSection()或ATrace宏,在 trace 文件中标记出特定代码块的执行时间,这对于追踪应用内部逻辑的耗时非常有用。
注意在采集时,选择合适的 TAG 对于生成有效且不过大的 trace 文件至关重要。你需要根据你想要分析的性能问题来选择:
- UI 卡顿 / 渲染问题:gfx, view, wm, sched,以及你的 app 类别(用于自定义事件)。
- App 启动耗时:am, dalvik (或 ART), app, sched, disk, binder_driver。
- 耗电问题:power, sched, network, audio, video, camera, disk。
- 内存抖动 / GC 问题:dalvik (或 ART), app。
- 文件 I/O 性能:disk, sched, app。
- Binder IPC 问题:binder_driver, binder_lock, app, sched。
选择的类别越多,生成的 trace 文件就越大,分析起来也可能越慢,所以建议只选择你真正需要关注的类别。
分析流程
trace文件里面记录的信息是非常详细的,但是如果直接看这些信息,可能很难分析出问题所在。所以,我们需要分析trace文件里面的信息,得到我们想要的信息。并且根据所分析的问题不同,入手的地方也都不一样。常见的需要分析trace文件的场景有以下几个。
一、冷启动分析
Perfetto在线网站比较智能了,有冷启动发生的话,在 startup 一行里就会显示出来了。
首先,可以到 system_server 进程下面,找到iq(Incoming Queue) 事件。
system_server 进程中的 iq 事件是 Binder 请求进入 system_server 传入队列的标记。它是衡量 system_server 处理 Binder 请求的负载和效率的关键指标。
再搜索 launching 事件,就可以找到应用启动的起始点。
从iq到整个launching,就是应用的整体启动耗时。
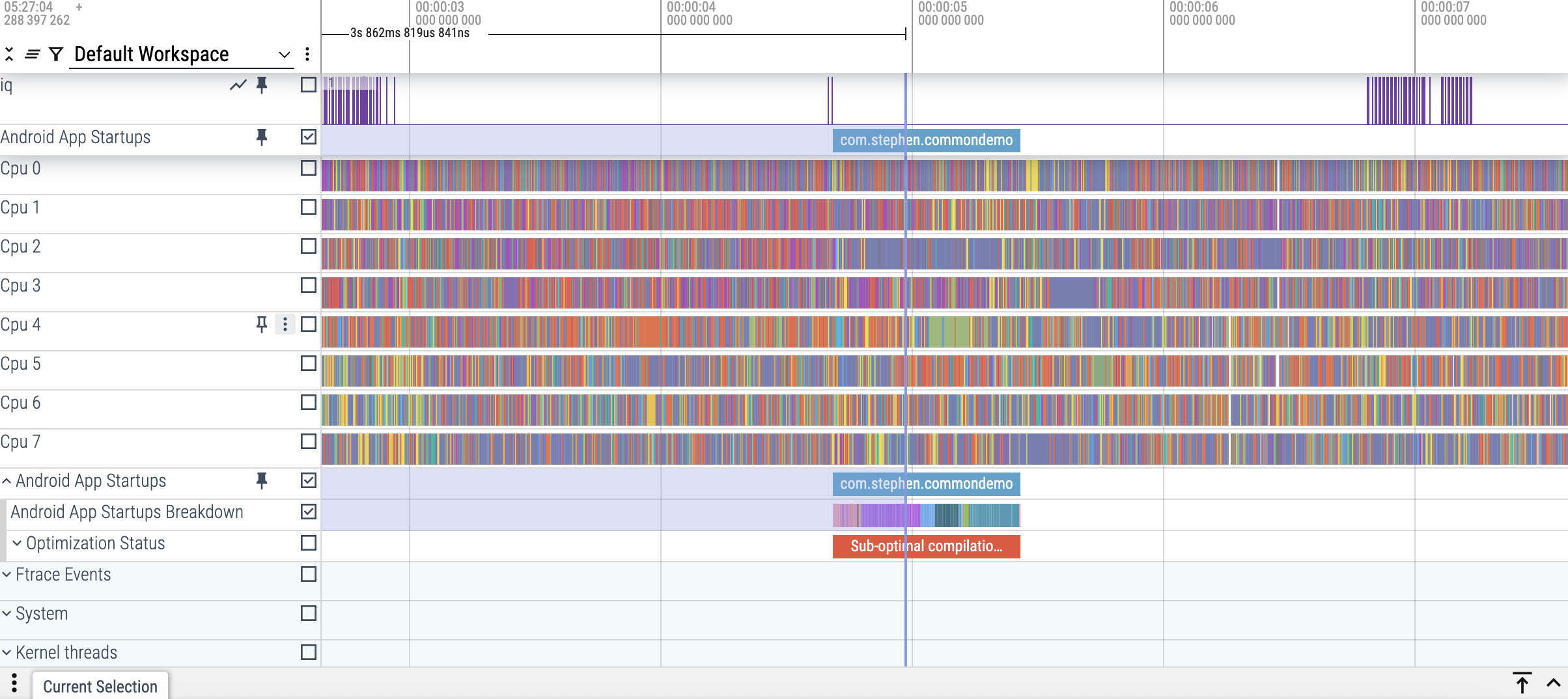
如上图,应用 com.stephen.commondemo 的启动耗时就是 760ms 。
应用内部耗时分析
确定整体的加载时长后,我们找到应用内部的 trace 切片,分析整个冷启动过程中各个阶段耗时分别是多少。
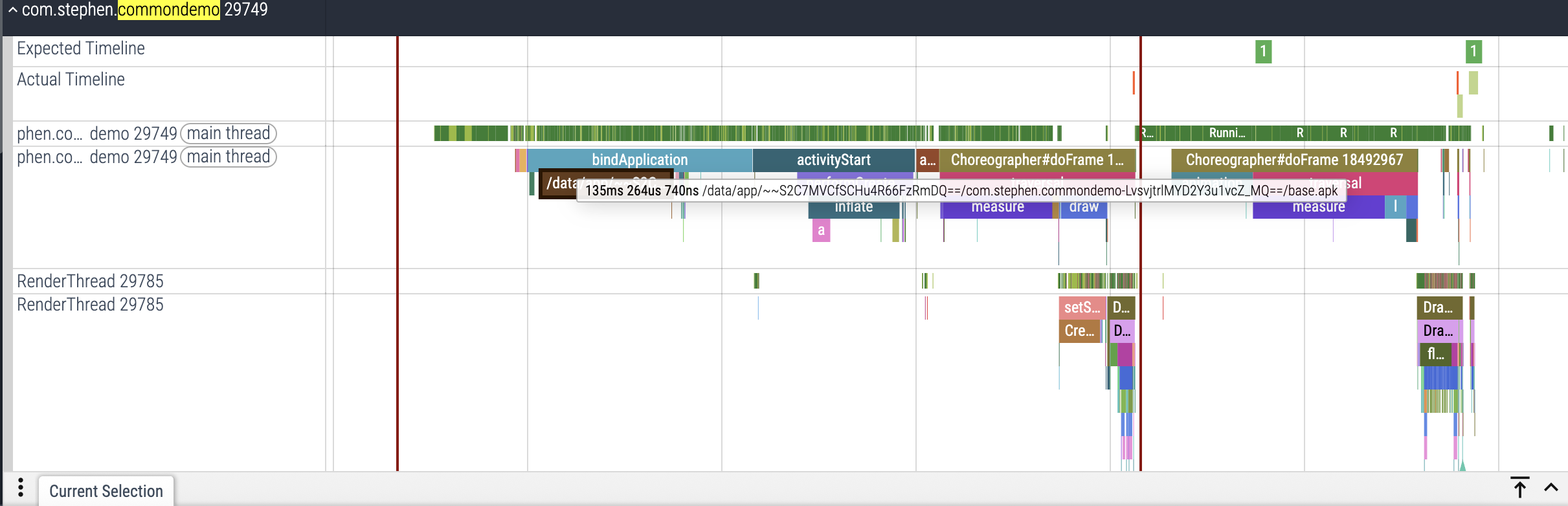
首先要看的第一个阶段,即为bindApplication 阶段,这是一个至关重要的环节。它发生在应用进程已经被系统创建之后,但在任何Activity的生命周期方法(如onCreate)被调用之前。
这个阶段的任务是确保所有基础设置都已就绪,以便你的应用可以正式开始运行。
bindApplication
具体来说,在 bindApplication 阶段会完成以下几件核心事情:
- 实例化
Application对象,系统会查找你的应用在AndroidManifest.xml文件中声明的android:name属性所指向的Application类(如果没有指定,则使用默认的android.app.Application)。然后,系统会创建这个Application类的实例。这个实例是整个应用进程的全局单例,通常用于存放应用级别的状态或进行全局初始化。 Application对象被实例化后,系统就会立即调用其onCreate()方法。开发者一般在这里执行一些全局性的、只需要执行一次的初始化操作,例如初始化第三方SDK(如统计SDK、推送SDK等);初始化全局配置管理器或数据存储(如SharedPreferences、数据库);设置全局崩溃捕获器;初始化一些单例对象。需要注意的是Application.onCreate()是在主线程(UI线程)中调用的。因此,在这个方法中执行耗时操作是导致应用冷启动慢的常见原因之一。- 系统会从设备存储中找到并加载你的应用 APK 文件。具体的会加载 APK 中的 DEX(Dalvik Executable)文件。DEX 文件包含了你的应用程序编译后的字节码。ART(Android Runtime)虚拟机需要这些字节码才能执行你的Java/Kotlin代码。这个过程包括从磁盘读取APK文件;将所需的类加载到内存中;ART可能会进行即时编译(JIT)或在安装时进行的预先编译(AOT)相关的操作,以优化代码执行效率。
- 设置应用程序的运行时环境,系统会为新创建的应用进程配置一系列运行时环境。这包括:
- 配置类加载器: 确保应用可以正确地加载和找到所有需要的类。
- 初始化资源管理器: 设置
Resources对象,以便应用可以访问其所有资源文件(如布局XML、字符串、图片等)。 - 设置默认的线程和 Looper: 为主线程(UI线程)准备好消息循环(Looper),以便处理UI事件和消息。
- 初始化上下文: 为
Application对象设置上下文(Context),使其能够访问系统服务。
activityStart
activityStart 阶段系统主要负责将一个 Activity 从其创建或重新启动的状态推进到用户可以与之交互的可见状态。标志着特定 Activity 生命周期的正式开始。 activityStart 阶段通常会执行以下任务:
Activity.onCreate()生命周期,开发者通常会在这里使用setContentView()方法加载Activity的 UI 布局 XML 文件。通过findViewById()或数据绑定/视图绑定获取对 UI 元素的引用。设置点击监听器、适配器、初始化列表、RecyclerView 等。在这里或onRestoreInstanceState()中恢复之前保存的状态。初始化与此Activity关联的ViewModel。启动一些初始化显示所需要的数据的加载。Activity.onStart()周期,这个方法表示Activity即将变得可见。开发者一般会在这里 注册广播接收器或监听器 启动需要 Activity 可见时才能进行的系统广播监听或传感器监听。启动一些与 UI 可见性相关的动画或轻量级资源加载。重新连接到一些系统服务。- 在
onStart()之后,onResume()会被调用,表示Activity已经位于 Activity 栈的顶部,并且即将与用户交互。启动或恢复与用户交互密切相关的动画。获取相机、音频焦点等需要独占的资源。确保 UI 显示的是最新数据。 - 视图树的测量、布局和绘制 (Measure, Layout, Draw),这是
activityStart阶段中非常耗时且关键的视觉准备工作。执行 测量 (Measure),布局 (Layout),绘制 (Draw) 。这个过程如果复杂或有深层次的视图嵌套,会消耗大量时间,直接影响用户看到第一个可交互画面的速度。
Choreographer#doFrame
Choreographer#doFrame 是 Android trace 文件中一个非常重要的事件,特别是在分析 UI 渲染性能时。简单来说,它表示了 Android 系统中 “编舞者”(Choreographer) 完成了一帧画面的绘制工作。
Choreographer是 Android 系统中一个核心组件,它的职责是协调和同步应用程序的动画、输入事件和 UI 绘制。它的目标是确保所有这些操作都能在 16.67 毫秒 内完成(对于 60fps 的屏幕刷新率),从而实现流畅的 60 帧每秒的用户体验。如果一帧的绘制时间超过了这个阈值,用户就会感觉到卡顿(jank)。
当 Choreographer#doFrame 事件在 trace 文件中出现时,它代表了系统为了 准备和绘制屏幕上的一帧画面 所执行的所有关键任务。它内部通常会包含以下几个主要阶段:
- 处理输入事件 (Input Handling):
- 检查并分发所有待处理的输入事件,如触摸、按键等。
- 这是确保 UI 响应用户操作的第一步。
- 处理动画 (Animation Handling):
- 更新所有正在进行的动画状态(例如,属性动画、视图动画等)。
- 根据动画的当前进度计算视图的新位置、大小、透明度等。
- 回调
View.onDraw/performTraversals/ 视图绘制 (View Drawing):- 这是
Choreographer#doFrame中最关键也是最耗时的部分之一。 - 它会触发整个视图层次结构的测量 (Measure)、布局 (Layout) 和绘制 (Draw) 过程。
- 测量 (Measure): 计算视图的尺寸。
- 布局 (Layout): 确定视图在屏幕上的位置。
- 绘制 (Draw): 将视图的内容(文本、图片、背景等)渲染到对应的
Surface上。这个过程涉及到 CPU 和 GPU 的协同工作,最终将像素数据写入帧缓冲区。
- 这是
- 同步和提交 (Sync and Submit):
- 在所有绘制命令都发出后,将这些命令提交给 GPU 进行实际渲染。
SurfaceFlinger会将各个应用程序的Surface合成到最终的屏幕缓冲区,然后显示出来。
在 trace 文件中分析 Choreographer#doFrame 事件时,
持续时间 (Duration) 应该小于 16.67 毫秒 (对于 60fps),首帧应该在200ms左右。
耗时最多的子事件是瓶颈所在。 如果 View#draw 或 performTraversals 耗时很长,说明是视图绘制复杂或视图层级过深导致的问题。如果 Input 或 Animation 耗时较长,则可能是输入处理或动画计算的问题。频繁的 GC (垃圾回收) 事件也会导致 doFrame 延迟。密集的磁盘 I/O 或网络请求(如果它们意外地发生在主线程)也可能阻塞 doFrame。
展开 Choreographer#doFrame 并查看其内部的调用栈,可以帮助你精确定位是哪个方法、哪个组件导致了耗时。 特别关注那些在 onCreate、onStart、onResume 中被调用,并且在 Choreographer#doFrame 范围内占用大量主线程时间的自定义方法或第三方 SDK 初始化。
滑动卡顿分析
滑动卡顿的本质是 UI 渲染跟不上屏幕的刷新率,导致丢帧。目标是让每帧的绘制时间保持在 16.67 毫秒 (60fps) 或更低。
抓取时,可以使用 adb shell perfetto 命令。确保包含以下关键类别:
gfx: 图形子系统事件。input: 输入事件处理。view: 视图层级的测量、布局和绘制。wm: 窗口管理器事件。am: Activity Manager 事件。sched: 调度器事件,显示 CPU 调度情况。dalvik: ART/GC 事件。memory: 内存分配。
示例命令(可能需要调整时间 -t 和输出路径 -o):
perfetto -o /data/misc/perfetto-traces/trace_log -t 120s -b 100mb -s 150mb sched freq idle am wm gfx view input dalvik memory
然后将 trace 文件拉取到电脑并导入 ui.perfetto.dev 进行分析。
分析 Trace 文件中的滑动卡顿
查找
Choreographer#doFrame事件: 在 Trace 的时间轴上,重点关注Choreographer#doFrame事件。这是衡量 UI 渲染性能的核心指标。- 正常情况: 对于 60fps,
Choreographer#doFrame的持续时间应该接近 16.67 毫秒。 - 卡顿迹象: 如果你看到
Choreographer#doFrame事件的持续时间远超 16.67 毫秒(例如 30ms, 50ms 甚至 100ms+),这表明发生了一帧的渲染超时,即掉帧,用户就会感觉到卡顿。
- 正常情况: 对于 60fps,
确定卡顿发生的时间点:
- 在时间轴上找到滑动操作开始和结束的区域。
- 在滑动过程中,特别留意那些持续时间异常长的
Choreographer#doFrame事件。这些就是卡顿发生的精确时刻。
展开耗时长的
Choreographer#doFrame: 点击这些异常长的Choreographer#doFrame事件,展开它们的内部细节。你需要深入查看是哪个子事件导致了大部分的耗时。常见的罪魁祸首包括:View#draw或ViewRootImpl#performTraversals: 如果这些事件占据了大部分时间,这通常意味着你的视图层级过于复杂,或者在绘制阶段做了大量耗时操作。- 检查 布局(Layout) 阶段:视图的测量和布局是否复杂,是否存在过度嵌套。
- 检查 绘制(Draw) 阶段:是否存在大量自定义绘制逻辑、图片加载或不必要的重绘。
Input处理: 如果输入事件处理耗时,可能你在主线程处理了复杂的触摸逻辑或手势识别。GC(Garbage Collection): 频繁或长时间的 GC 会导致主线程暂停,从而引起卡顿。这通常是由于在滑动过程中产生了大量的临时对象。- 你的应用程序代码:
- 主线程 I/O: 文件读写、数据库操作、网络请求等如果意外地发生在主线程,会严重阻塞 UI 渲染。
- 复杂计算: 任何在主线程进行的复杂数据处理、图片处理或算法计算。
- RecyclerView/ListView 适配器优化不足:
onCreateViewHolder()或onBindViewHolder()中进行了耗时操作。- 没有正确使用
ViewHolder复用机制。 - 列表项布局过于复杂。
- 图片加载没有异步处理或优化。
- 第三方 SDK 调用: 有些 SDK 可能会在不经意间在主线程执行耗时操作。
结合 CPU Profiler 的调用栈分析: 如果你使用的是 Android Studio CPU Profiler 的 “System Trace” 模式,并同时捕获了方法追踪数据(或者在 Perfetto 中启用了 CPU 采样),你可以:
- 选择
Choreographer#doFrame事件卡顿发生的时间段。 - 查看下方的 “Flame Chart” (火焰图)。火焰图会直观地显示在此期间 CPU 花费在哪些函数上。
- 识别最宽的“火焰”: 这就是 CPU 耗时最多的函数。
- 沿着调用链向上追溯: 从底层函数追溯到你的应用代码,找出是哪个方法导致了性能瓶颈。例如,你可能会看到你的
Adapter.onBindViewHolder()或一个自定义View的onDraw()方法占据了大量时间。
- 选择
针对性优化
根据 Trace 分析的结果,进行针对性优化:
- 将耗时操作移出主线程:
- 任何不涉及 UI 更新的耗时操作(网络请求、数据库查询、复杂计算、大文件读写)都应该在后台线程进行。
- 使用 Kotlin 协程、
ThreadPoolExecutor或AsyncTask(不推荐新项目) 等异步机制。
- 优化 UI 布局和绘制:
- 扁平化视图层级: 使用
ConstraintLayout减少嵌套。 - 避免过度绘制: 检查并移除不必要的背景、减少重叠视图。使用开发者选项中的 “Debug GPU Overdraw” 帮助发现。
- 优化自定义 View: 确保
onDraw()方法高效,不创建新对象,不执行复杂计算或 I/O。使用Canvas.clipRect()限制绘制区域。
- 扁平化视图层级: 使用
- 优化列表性能 (RecyclerView/ListView):
- 高效的
ViewHolder: 确保ViewHolder正确复用,并且onCreateViewHolder()和onBindViewHolder()方法执行高效,不进行耗时操作。 - 异步图片加载: 使用 Glide、Coil 或 Picasso 等库异步加载和缓存图片,避免在主线程加载大图。
- 避免复杂布局: 列表项布局尽量简洁,减少层级和复杂计算。
- 高效的
- 减少内存抖动和 GC 频率:
- 避免在循环或频繁调用的方法中创建大量临时对象。
- 使用对象池或缓存来重用对象。
- 延迟初始化:
- 对于某些组件或数据,可以考虑懒加载,即只在需要时才进行初始化。