【C++】C++进阶记录

本文记录了我学习C++的一些进阶知识
本文是C++基础学习完成的进阶记录,一些高阶技法和基础补齐
前面的相关文章:
处理器
时钟频率(Clock Speed)和内核数量(Core Count)是衡量处理器性能的两个关键指标,它们对 C++ 程序的性能影响很大,但方式各不相同。理解这两者如何协同工作,能帮助你更好地优化程序。
时钟频率对C++程序性能的影响
时钟频率通常以千兆赫兹(GHz)为单位,它 决定了处理器每个内核每秒能执行多少个操作 。一个 3.0 GHz 的处理器,意味着处理器每秒有 3.0×10 9 个时钟周期(或脉冲)。
一个时钟周期并不总是对应一条指令。现代处理器为了提高效率,通常会在一个时钟周期内执行多条指令,或者一条复杂的指令会占用多个时钟周期。
IPC (Instructions Per Cycle) 也是衡量处理器效率的关键指标。IPC 表示每个时钟周期可以执行的指令数量。一个 IPC 大于 1 的处理器比 IPC 小于 1 的处理器更高效。不同的处理器架构(如 x86, ARM)、不同的指令集和不同的程序代码,IPC 值都会有很大差异。
- 单线程性能: 对于单线程的 C++ 程序,时钟频率是决定性能的最主要因素。因为程序的所有计算都集中在一个内核上,更高的时钟频率意味着每个指令的执行时间更短,程序的运行速度就越快。
- 不适合的场景: 尽管时钟频率很重要,但它并不是万能的。如果你的程序瓶颈在于 I/O 操作(比如读写文件或网络通信),或者内存访问速度,单纯提高时钟频率的效果就不那么明显了。
总结: 时钟频率直接影响 C++ 程序中串行执行部分的性能。如果你的代码大部分是顺序执行的,没有很好地利用并行化,那么提高时钟频率会带来显著的性能提升。
内核数量对C++程序性能的影响
内核数量指的是一个处理器中独立处理单元的数量。每个内核都可以独立执行任务。
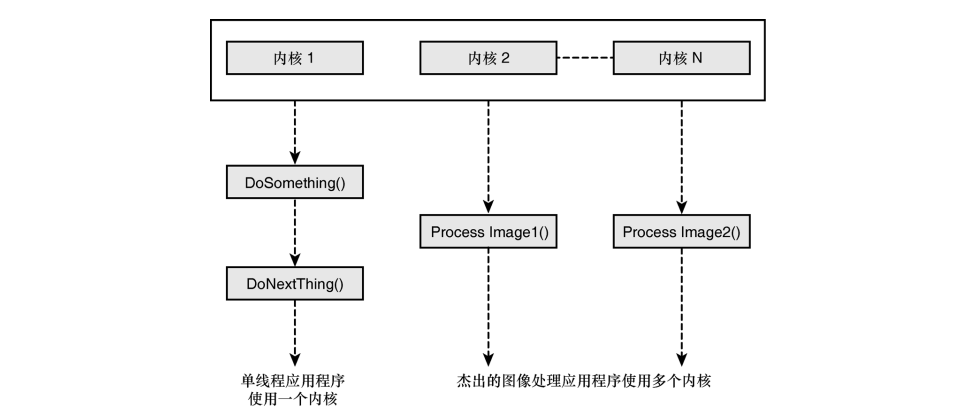
- 多线程性能: 内核数量主要影响多线程 C++ 程序的性能。如果你使用如
std::thread、OpenMP或TBB这样的技术,将任务分解成多个可以并行执行的部分,那么更多的内核就能同时处理更多的任务,从而大幅缩短总运行时间。 - 并行化是关键: 要利用多核的优势,你的程序必须是可并行化的。如果你的算法本身就是串行的(比如一个简单的循环没有依赖性),那么增加再多的内核也无济于事,因为它只能在一个内核上运行。
- 并非越多越好: 尽管多核能提升性能,但多线程编程也引入了新的挑战,比如同步(Synchronization)、锁竞争(Lock Contention)和数据共享等问题。如果处理不好,这些开销反而可能导致性能下降。例如,两个线程频繁地争抢同一个锁,它们可能会大部分时间都处于等待状态,而不是真正地执行计算。
总结: 内核数量决定了你的 C++ 程序能够并行处理任务的能力。要充分利用多核优势,你需要设计并实现能有效并行化的算法。
多线程
应用程序代码总是运行在线程中。线程是一个同步执行实体,其中的语句依次执行。可将 main( )的代码视为在应用程序的主线程中执行。在这个主线程中,可以创建并行运行的线程。如果应用程序除主线程外,还包含一个或多个并行运行的线程,则被称为多线程应用程序。
线程的创建方式由操作系统决定,您可直接调用操作系统提供的 API 来创建线程。
从 C++11 起,C++规定由线程函数负责为您调用操作系统 API,这提高了多线程应用程序的可移植性。如果您编写的应用程序将在特定操作系统上运行,请了解该操作系统提供的用于编写多线程应用程序的 API。
创建线程的方式随操作系统而异,C++在头文件<thread>中提供了 std::thread,它隐藏了与平台相关的细节。如果您针对特定平台编写应用程序,最好只使用针对该操作系统的线程函数。编写 C++应用程序时,如果您希望其中的线程是可移植的,请务必了解Boost 线程库
多线程注意事项
- 多线程应用程序常常要求线程彼此通信,这样应用程序才能成为一个整体,而不是一系列互不关心、各自为政的线程。
- 另外,顺序也很重要,您不希望用户界面线程在负责整理碎片的工作线程之前结束。在有些情况下,一个线程需要等待另一个线程。例如,读取数据库的线程应等待写入数据库的线程结束。
- 让一个线程等待另一个线程被称为线程同步。
线程的创建
C++ 11 之后添加了新的标准线程库 std::thread, std::thread 在 <thread> 头文件中声明,因此使用 std::thread 时需要包含 在 <thread> 头文件。
#include<thread>
std::thread thread_object(callable, args...);
- callable:可调用对象,可以是函数指针、函数对象、Lambda 表达式等。
- args…:传递给 callable 的参数列表。
使用函数指针创建线程
通过函数指针创建线程,这是最基本的方式:
实例
#include <iostream>
#include <thread>
void printMessage(int count) {
for (int i = 0; i < count; ++i) {
std::cout << "Hello from thread (function pointer)!\n";
}
}
int main() {
std::thread t1(printMessage, 5); // 创建线程,传递函数指针和参数
t1.join(); // 等待线程完成
return 0;
}
输出结果:
Hello from thread (function pointer)!
Hello from thread (function pointer)!
Hello from thread (function pointer)!
Hello from thread (function pointer)!
Hello from thread (function pointer)!
使用函数对象创建线程
通过类中的 operator() 方法定义函数对象来创建线程:
#include <iostream>
#include <thread>
class PrintTask {
public:
void operator()(int count) const {
for (int i = 0; i < count; ++i) {
std::cout << "Hello from thread (function object)!\n";
}
}
};
int main() {
std::thread t2(PrintTask(), 5); // 创建线程,传递函数对象和参数
t2.join(); // 等待线程完成
return 0;
}
输出结果:
Hello from thread (function object)!
Hello from thread (function object)!
Hello from thread (function object)!
Hello from thread (function object)!
Hello from thread (function object)!
使用 Lambda 表达式创建线程
Lambda 表达式可以直接内联定义线程执行的代码:
#include <iostream>
#include <thread>
int main() {
std::thread t3([](int count) {
for (int i = 0; i < count; ++i) {
std::cout << "Hello from thread (lambda)!\n";
}
}, 5); // 创建线程,传递 Lambda 表达式和参数
t3.join(); // 等待线程完成
return 0;
}
线程管理
join()
join() 用于等待线程完成执行。如果不调用 join() 或 detach() 而直接销毁线程对象,会导致程序崩溃。
t.join();
detach()
detach() 将线程与主线程分离,线程在后台独立运行,主线程不再等待它。
t.detach();
线程的传参
值传递
参数可以通过值传递给线程:
std::thread t(func, arg1, arg2);
引用传递
如果需要传递引用参数,需要使用 std::ref :
#include <iostream>
#include <thread>
void increment(int& x) {
++x;
}
int main() {
int num = 0;
std::thread t(increment, std::ref(num)); // 使用 std::ref 传递引用
t.join();
std::cout << "Value after increment: " << num << std::endl;
return 0;
}
综合实例,以下是一个完整的示例,展示了如何使用上述三种方式创建线程,并进行线程管理。
#include <iostream>
#include <thread>
using namespace std;
// 一个简单的函数,作为线程的入口函数
void foo(int Z) {
for (int i = 0; i < Z; i++) {
cout << "线程使用函数指针作为可调用参数\n";
}
}
// 可调用对象的类定义
class ThreadObj {
public:
void operator()(int x) const {
for (int i = 0; i < x; i++) {
cout << "线程使用函数对象作为可调用参数\n";
}
}
};
int main() {
cout << "线程 1 、2 、3 独立运行" << endl;
// 使用函数指针创建线程
thread th1(foo, 3);
// 使用函数对象创建线程
thread th2(ThreadObj(), 3);
// 使用 Lambda 表达式创建线程
thread th3([](int x) {
for (int i = 0; i < x; i++) {
cout << "线程使用 lambda 表达式作为可调用参数\n";
}
}, 3);
// 等待所有线程完成
th1.join(); // 等待线程 th1 完成
th2.join(); // 等待线程 th2 完成
th3.join(); // 等待线程 th3 完成
return 0;
}
以上代码的输出结果在不同平台或每次运行时可能不同,因为线程的执行顺序由操作系统的调度算法决定,多个线程会并发运行,输出可能交错,例如:
线程 1 、2 、3 独立运行
线程使用函数指针作为可调用参数
线程使用函数对象作为可调用参数
线程使用 lambda 表达式作为可调用参数
线程使用函数指针作为可调用参数
按照自己对于Java线程的理解,写出了下面这段代码,期望看到两个线程交替打印。
#include <iostream>
#include <thread>
void PrintStrings() {
for (int i = 0; i < 5; i++) {
std::cout << "Hello, World! from thread " << std::endl;
}
}
int main() {
std::thread t(PrintStrings);
t.join();
for (int i = 0; i < 5; i++) {
std::cout << "Hello, World! from main()" << std::endl;
}
return 0;
}
问题 :子线程内部打印完了才往下执行main内的打印。
原因 : t.join() 的作用是阻塞(block)主线程 main(),让它停下来,等待子线程 t 执行完毕。只有当子线程 t 中的 PrintStrings() 函数完全执行完成、线程终止后,main() 函数才会继续执行 t.join() 后面的代码,也就是你看到的第二个 for 循环。
解决思路就是弄清楚线程是什么时候开始执行的。
尝试将 join() 移到最后,但是这次是main中的打印全部完成,再开启子线程的打印。
原因 :在多线程程序中,操作系统负责在不同的线程之间切换,分配 CPU 时间片。虽然理论上主线程和子线程是并行运行的,但实际的执行顺序取决于操作系统的调度器。在更改 join() 位置后的代码中,main 线程创建子线程 t 之后,它会立即执行它自己的 for 循环。而子线程 t 什么时候真正开始运行,取决于操作系统什么时候给它分配 CPU 时间。对于一个相对简单的程序,main 线程通常会因为其优先级或调度策略的缘故,在创建子线程后立即获得 CPU 时间片,并执行自己的任务。在这个极短的时间内,main 线程的 for 循环可能已经全部执行完毕,甚至在子线程有机会开始运行之前。
解决 :两个线程的循环中插入延时, std::this_thread::sleep_for() 函数会让当前线程进入休眠,并主动放弃对 CPU 的占用。当 main 线程执行到 sleep_for 时,它会暂停一段时间,给操作系统一个机会去调度其他就绪的线程(比如你的子线程)。当主线程休眠结束后,它和子线程就会进入竞争状态,从而更有可能产生交替执行的效果。
#include <iostream>
#include <thread>
using namespace std;
void PrintStrings() {
for (int i = 0; i < 5; i++) {
cout << "Hello, World! from thread " << endl;
// 让出CPU
this_thread::sleep_for(chrono::milliseconds(10));
}
}
int main() {
thread t(PrintStrings);
for (int i = 0; i < 5; i++) {
cout << "Hello, World! from main()" << endl;
// 让出CPU
this_thread::sleep_for(chrono::milliseconds(10));
}
t.join();
return 0;
}
线程数据通信
线程可共享变量,可访问全局数据。创建线程时,可给它提供一个指向共享对象(结构或类)的指针。
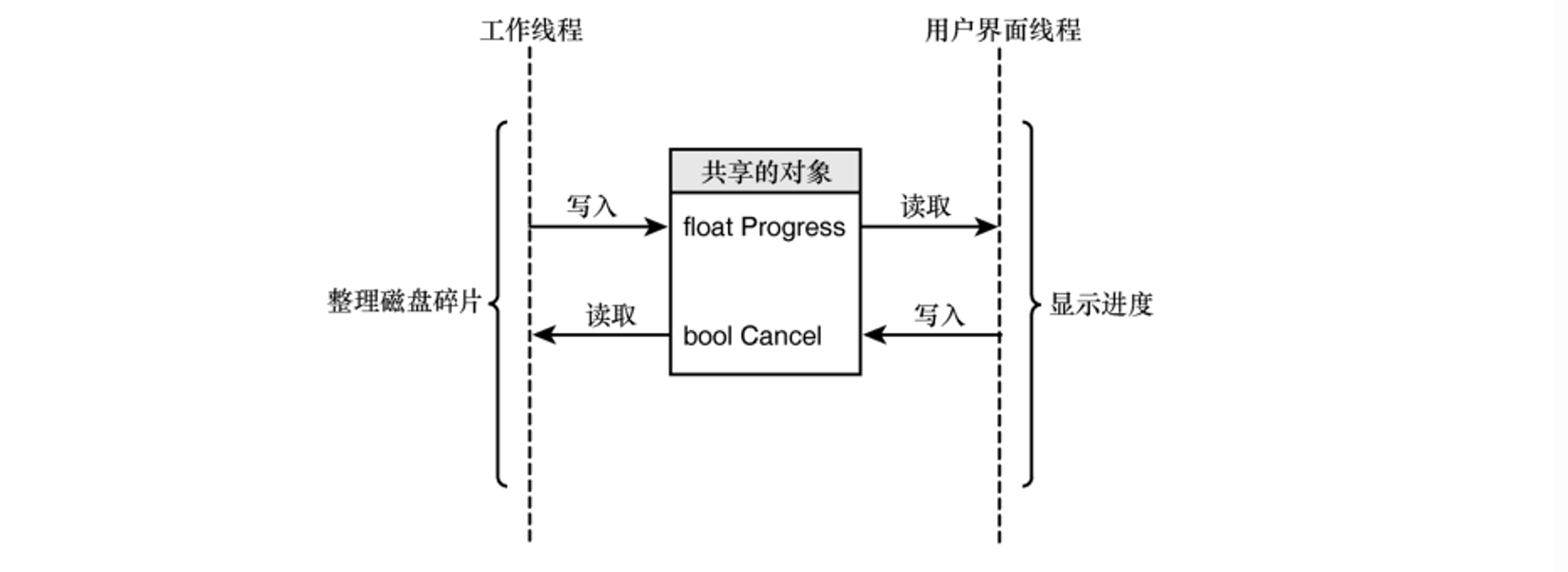
线程将数据写入其他线程能够存取的内存单元,这让线程能够共享数据,从而彼此进行通信。在磁盘碎片整理工具中,工作线程知道进度,而用户界面线程需要获悉这种信息;工作线程定期地存储进度(用整数表示的百分比),而用户界面线程可使用它来显示进度。
这种情形非常简单:一个线程创建信息,另一个线程使用它。如果多个线程读写相同的内存单元,结果将如何呢?有些线程开始读取数据时,其他线程可能还未结束写入操作,这将给数据的完整性带来威胁。这就是需要同步线程的原因所在。
使用互斥量和信号量同步线程
线程是操作系统级实体,而用来同步线程的对象也是操作系统提供的。大多数操作系统都提供了信号量(semaphore)和互斥量(mutex),供您用来同步线程。 互斥量(互斥同步对象)通常用于避免多个线程同时访问同一段代码。换句话说,互斥量指定了一段代码,其他线程要执行它,必须等待当前执行它的线程结束并释放该互斥量。接下来,下一个线程获取该互斥量,完成其工作,并释放该互斥量。从 C++11 起,C++通过类 std::mutex 提供了一种互斥量实现,这个类位于头文件 <mutex> 中。
通过使用信号量,可指定多少个线程可同时执行某个代码段。只允许一个线程访问的信号量被称为二值信号量(binary semaphore)。
互斥量(Mutex)
互斥量是一种同步原语,用于防止多个线程同时访问共享资源。当一个线程需要访问共享资源时,它首先需要锁定(lock)互斥量。如果互斥量已经被其他线程锁定,那么请求锁定的线程将被阻塞,直到互斥量被解锁(unlock)。
std::mutex:用于保护共享资源,防止数据竞争。
std::mutex mtx;
mtx.lock(); // 锁定互斥锁
// 访问共享资源
mtx.unlock(); // 释放互斥锁
std::lock_guard 和 std::unique_lock:自动管理锁的获取和释放。
std::lock_guard<std::mutex> lock(mtx); // 自动锁定和解锁
// 访问共享资源
互斥量的使用示例:
#include <mutex>
std::mutex mtx; // 全局互斥量
void safeFunction() {
mtx.lock(); // 请求锁定互斥量
// 访问或修改共享资源
mtx.unlock(); // 释放互斥量
}
int main() {
std::thread t1(safeFunction);
std::thread t2(safeFunction);
t1.join();
t2.join();
return 0;
}
锁(Locks)
C++提供了多种锁类型,用于简化互斥量的使用和管理。
常见的锁类型包括:
- std::lock_guard:作用域锁,当构造时自动锁定互斥量,当析构时自动解锁。
- std::unique_lock:与std::lock_guard类似,但提供了更多的灵活性,例如可以转移所有权和手动解锁。
锁的使用示例:
#include <mutex>
std::mutex mtx;
void safeFunctionWithLockGuard() {
std::lock_guard<std::mutex> lk(mtx);
// 访问或修改共享资源
}
void safeFunctionWithUniqueLock() {
std::unique_lock<std::mutex> ul(mtx);
// 访问或修改共享资源
// ul.unlock(); // 可选:手动解锁
// ...
}
条件变量(Condition Variable)
条件变量用于线程间的协调,允许一个或多个线程等待某个条件的发生。它通常与互斥量一起使用,以实现线程间的同步。
std::condition_variable 用于实现线程间的等待和通知机制。
std::condition_variable cv;
std::mutex mtx;
bool ready = false;
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, []{ return ready; }); // 等待条件满足
// 条件满足后执行
条件变量的使用示例:
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void workerThread() {
std::unique_lock<std::mutex> lk(mtx);
cv.wait(lk, []{ return ready; }); // 等待条件
// 当条件满足时执行工作
}
void mainThread() {
{
std::lock_guard<std::mutex> lk(mtx);
// 准备数据
ready = true;
} // 离开作用域时解锁
cv.notify_one(); // 通知一个等待的线程
}
原子操作(Atomic Operations)
原子操作确保对共享数据的访问是不可分割的,即在多线程环境下,原子操作要么完全执行,要么完全不执行,不会出现中间状态。
原子操作的使用示例:
#include <atomic>
#include <thread>
std::atomic<int> count(0);
void increment() {
count.fetch_add(1, std::memory_order_relaxed);
}
int main() {
std::thread t1(increment);
std::thread t2(increment);
t1.join();
t2.join();
return count; // 应返回2
}
线程局部存储(Thread Local Storage, TLS)
线程局部存储允许每个线程拥有自己的数据副本。这可以通过thread_local关键字实现,避免了对共享资源的争用。
线程局部存储的使用示例:
#include <iostream>
#include <thread>
thread_local int threadData = 0;
void threadFunction() {
threadData = 42; // 每个线程都有自己的threadData副本
std::cout << "Thread data: " << threadData << std::endl;
}
int main() {
std::thread t1(threadFunction);
std::thread t2(threadFunction);
t1.join();
t2.join();
return 0;
}
死锁(Deadlock)和避免策略
死锁发生在多个线程互相等待对方释放资源,但没有一个线程能够继续执行。避免死锁的策略包括:
- 总是以相同的顺序请求资源。
- 使用超时来尝试获取资源。
- 使用死锁检测算法。
线程间通信方式
std::future 和 std::promise :实现线程间的值传递。
std::promise<int> p;
std::future<int> f = p.get_future();
std::thread t([&p] {
p.set_value(10); // 设置值,触发 future
});
int result = f.get(); // 获取值
消息队列(基于 std::queue 和 std::mutex)实现简单的线程间通信。
C++17 引入了并行算法库 <algorithm>,其中部分算法支持并行执行,可以利用多核 CPU 提高性能。
#include <algorithm>
#include <vector>
#include <execution>
std::vector<int> vec = {1, 2, 3, 4, 5};
std::for_each(std::execution::par, vec.begin(), vec.end(), [](int &n) {
n *= 2;
});
多线程技术带来的问题
要使用多线程技术,必须妥善地同步线程,否则,您将有大量的无眠之夜。多线程应用程序面临的问题很多,下面是最常见的两个。
竞争状态 :多个线程试图写入同一项数据。哪个线程获胜?该对象处于什么状态? 死锁 :两个线程彼此等待对方结束,导致它们都处于“等待”状态,而应用程序被挂起。
妥善地同步可避免竞争状态。一般而言,线程被允许写入共享对象时,您必须格外小心,确保:
- 每次只能有一个线程写入;
- 在当前执行写入的线程结束前,不允许其他线程读取该对象。
通过确保任何情况下都不会有两个线程彼此等待,可避免死锁。为此,可使用主线程同步工作线程,也可在线程之间分配任务时,确保工作负荷分配明确。可以让一个线程等待另一个线程,但绝不要同时让后者也等待前者。
要学习多线程编程,可参阅大量有关该主题的在线文档,也可亲自动手实践。一旦掌握了这个主题,就能让 C++应用程序充分利用未来将发布的多核处理器。